面试官三连问:分库分表了解吧?业界有哪些常用方案?可能存在什么问题?
Posted Java面试那些事儿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面试官三连问:分库分表了解吧?业界有哪些常用方案?可能存在什么问题?相关的知识,希望对你有一定的参考价值。
来源 : https://urlify.cn/JVf2ey
哈喽,各位新来的小伙伴们,大家好!由于公众号做了改版,为了保证公众号的资源能准时推送到你手里,大家记得将咱们的公众号 加星标置顶 ,在此真诚的表示感谢~
 正文如下:
正文如下:
# 数据库瓶颈
1.IO瓶颈
# 分库分表
1.水平分库
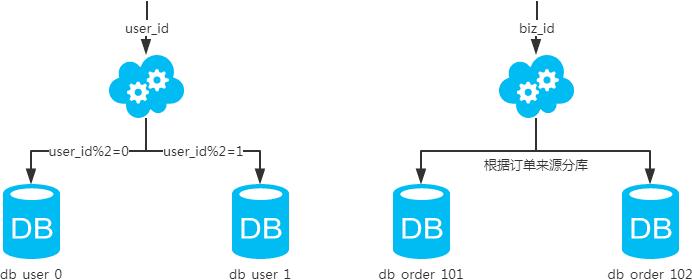
-
每个库的结构都一样; -
每个库的数据都不一样,没有交集; -
所有库的并集是全量数据;
2.水平分表
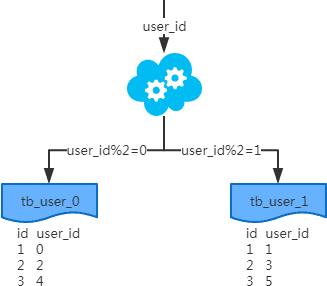
-
每个表的结构都一样; -
每个表的数据都不一样,没有交集; -
所有表的并集是全量数据;
3.垂直分库
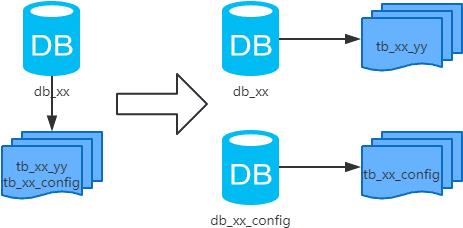
-
每个库的结构都不一样; -
每个库的数据也不一样,没有交集; -
所有库的并集是全量数据;
4.垂直分表
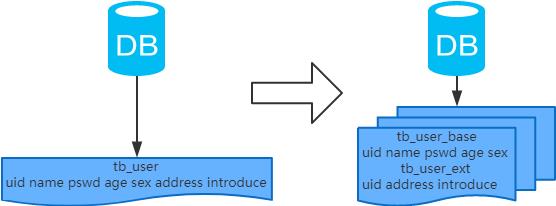
-
每个表的结构都不一样; -
每个表的数据也不一样,一般来说,每个表的字段至少有一列交集,一般是主键,用于关联数据; -
所有表的并集是全量数据;
# 分库分表工具
-
sharding-sphere:jar,前身是sharding-jdbc; -
TDDL:jar,Taobao Distribute Data Layer; -
Mycat:中间件。
# 分库分表步骤
# 分库分表问题
非partition key的查询问题
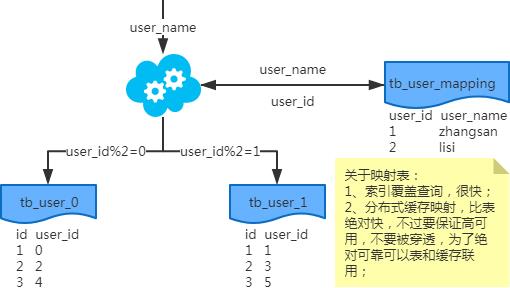
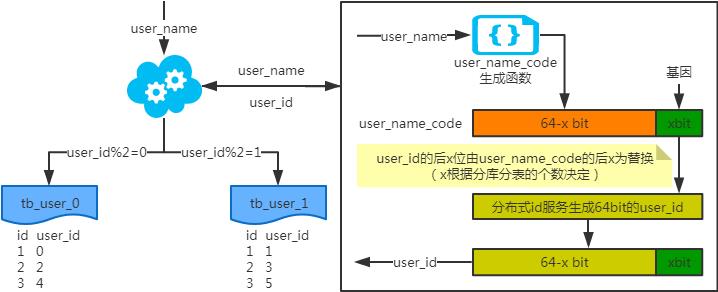
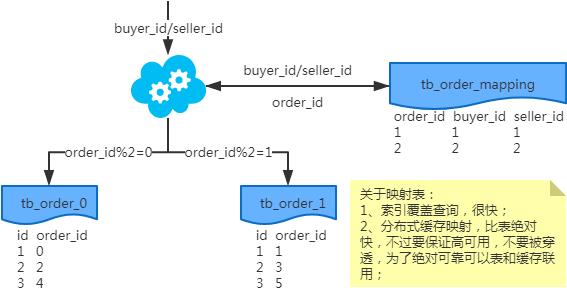
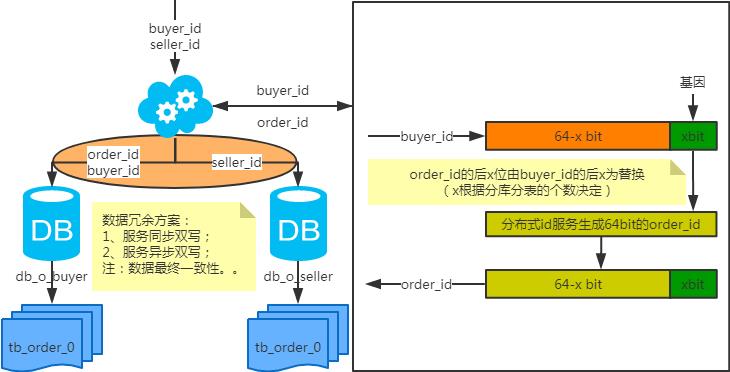
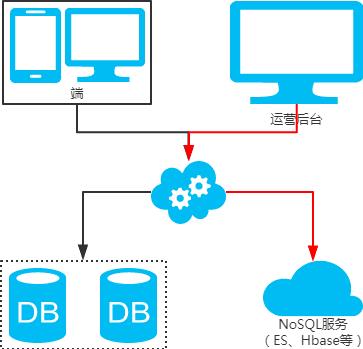
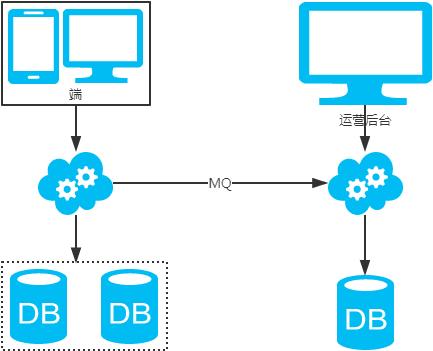
非partition key跨库跨表分页查询问题
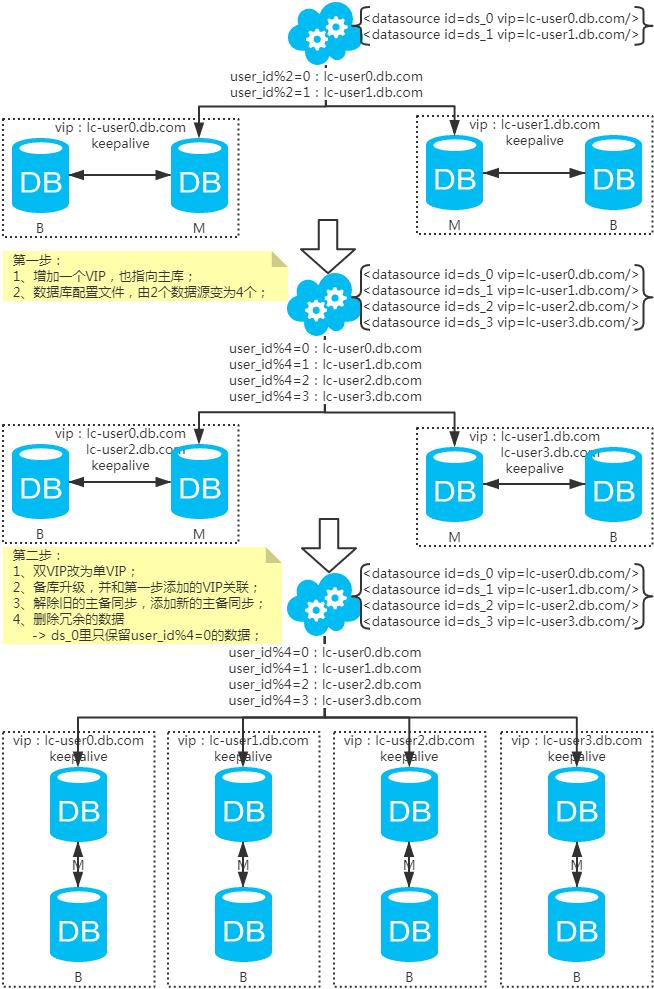
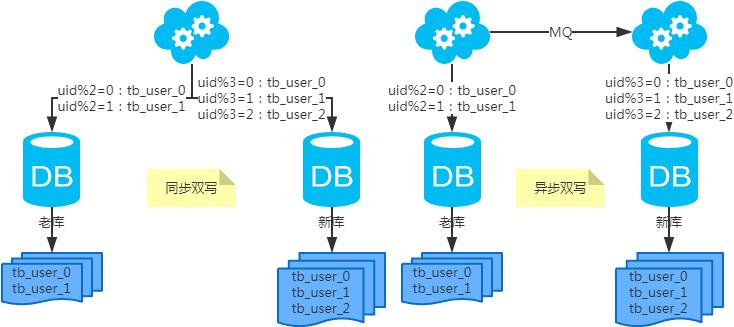
扩容问题
-
第一步:(同步双写)修改应用配置和代码,加上双写,部署; -
第二步:(同步双写)将老库中的老数据复制到新库中; -
第三步:(同步双写)以老库为准校对新库中的老数据; -
第四步:(同步双写)修改应用配置和代码,去掉双写,部署;
# 分库分表总结
以上是关于面试官三连问:分库分表了解吧?业界有哪些常用方案?可能存在什么问题?的主要内容,如果未能解决你的问题,请参考以下文章
面试官三连问:你这个数据量多大?分库分表怎么做?用的哪个组件?
面试官:兄弟,聊聊架构师级MySQL的Client和Proxy分库分表吧!