面试三连问:你这个数据量多大?分库分表怎么做?用的哪个组件?
Posted Java面试那些事儿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面试三连问:你这个数据量多大?分库分表怎么做?用的哪个组件?相关的知识,希望对你有一定的参考价值。
来源:cnblogs.com/cjsblog/p/13154158.html
哈喽,各位新来的小伙伴们,大家好!由于公众号做了改版,为了保证公众号的资源能准时推送到你手里,大家记得将咱们的公众号 加星标置顶 ,在此真诚的表示感谢~
 正文如下:
正文如下:
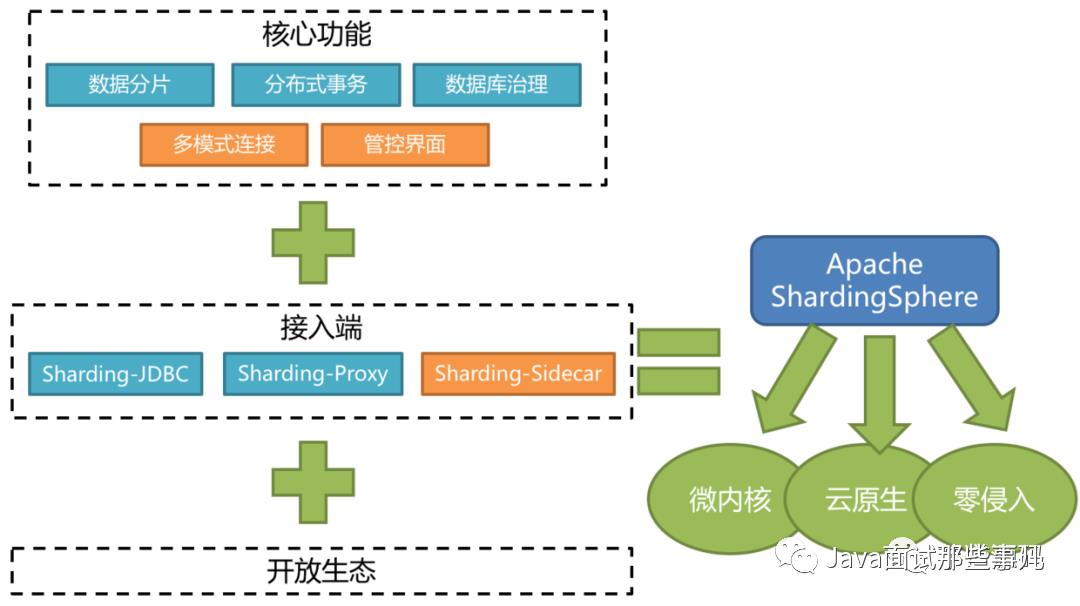
# 概述
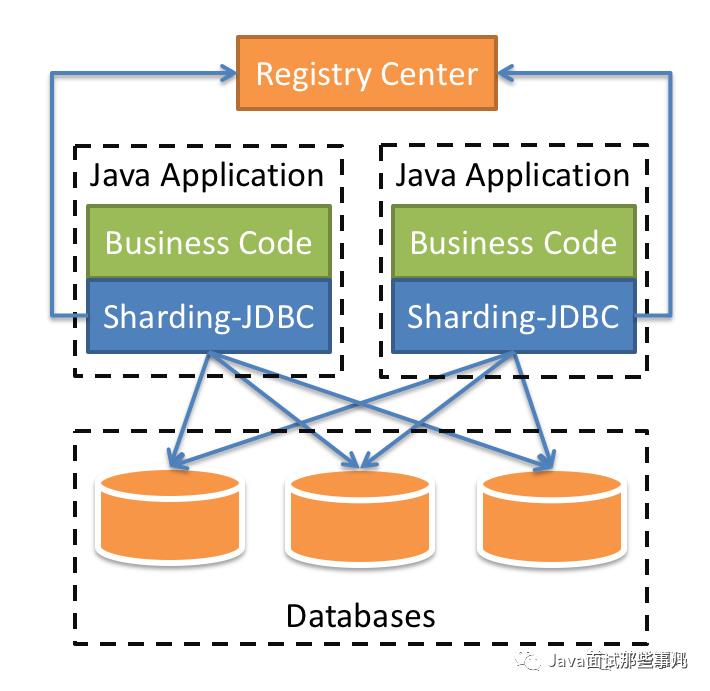
ShardingSphere-JDBC
-
适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC。 -
支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。 -
支持任意实现JDBC规范的数据库。目前支持 mysql,Oracle,SQLServer,PostgreSQL 以及任何遵循 SQL92 标准的数据库。
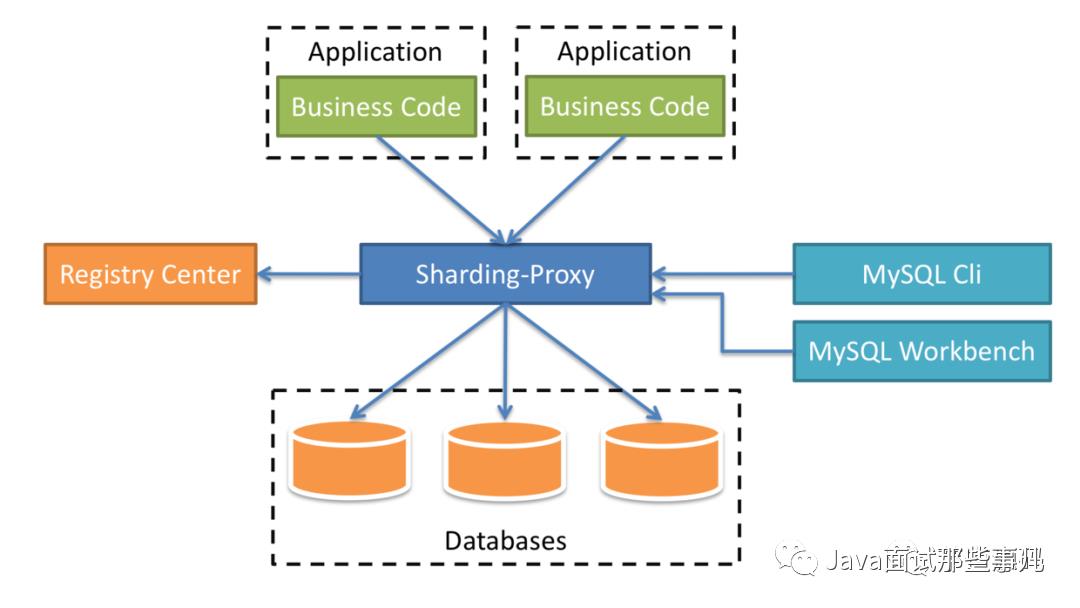
ShardingSphere-Proxy
-
向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用。 -
适用于任何兼容 MySQL/PostgreSQL 协议的的客户端。
ShardingSphere-Sidecar
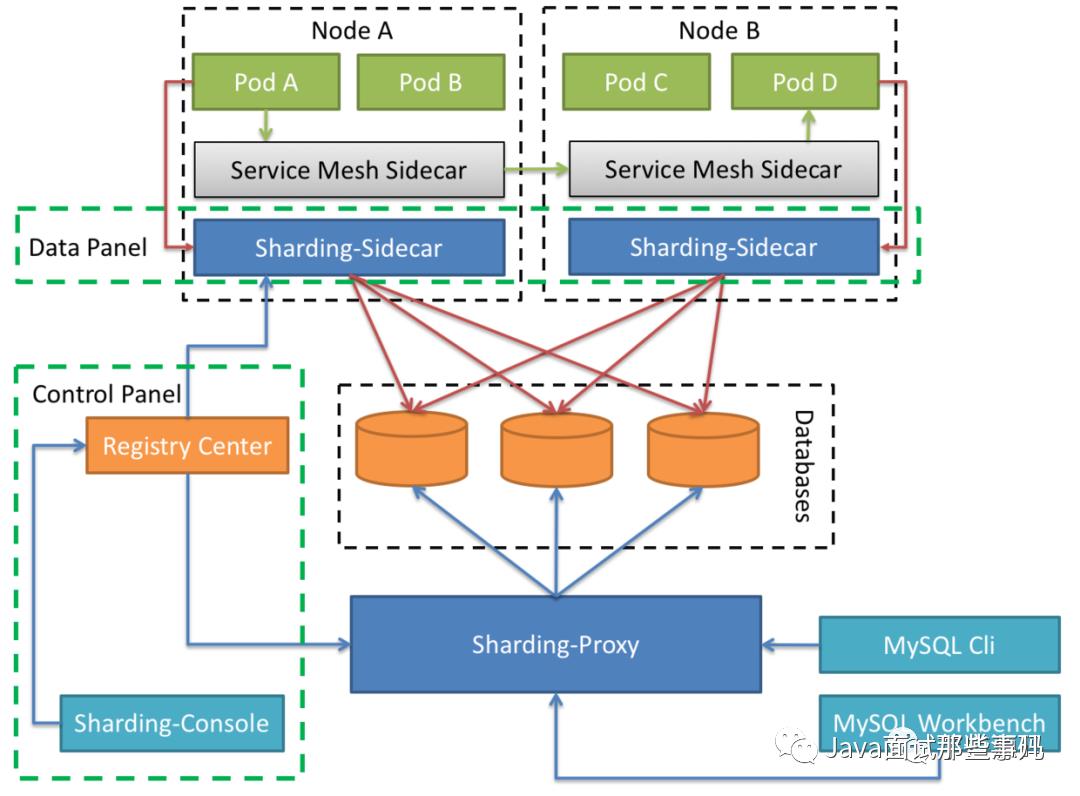
混合架构
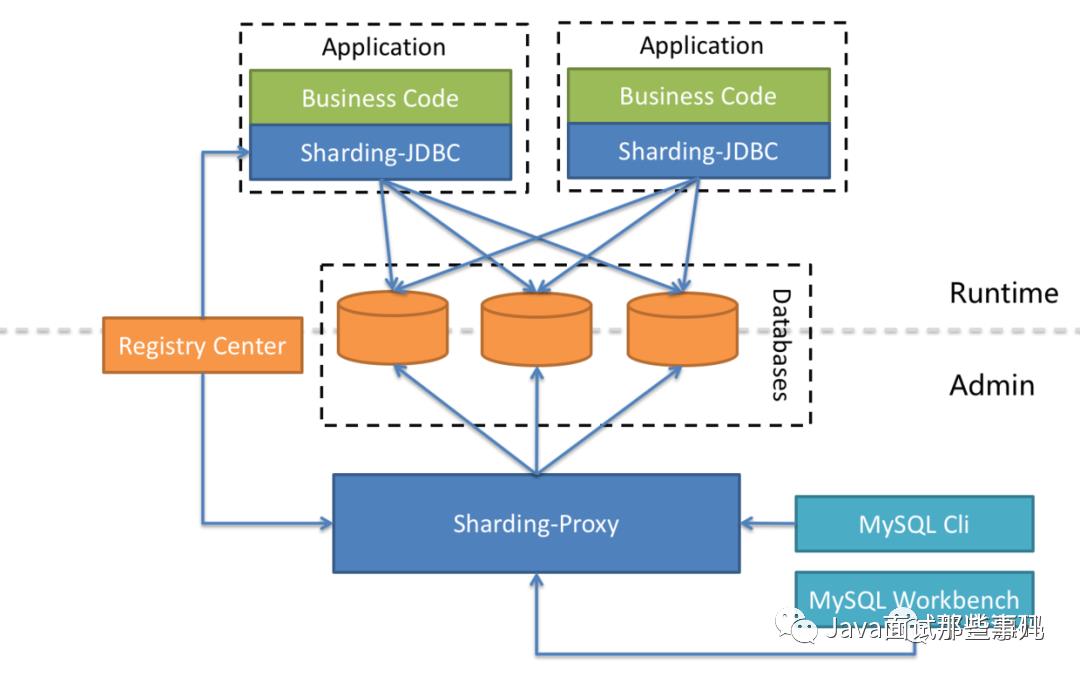
# 概念 & 功能
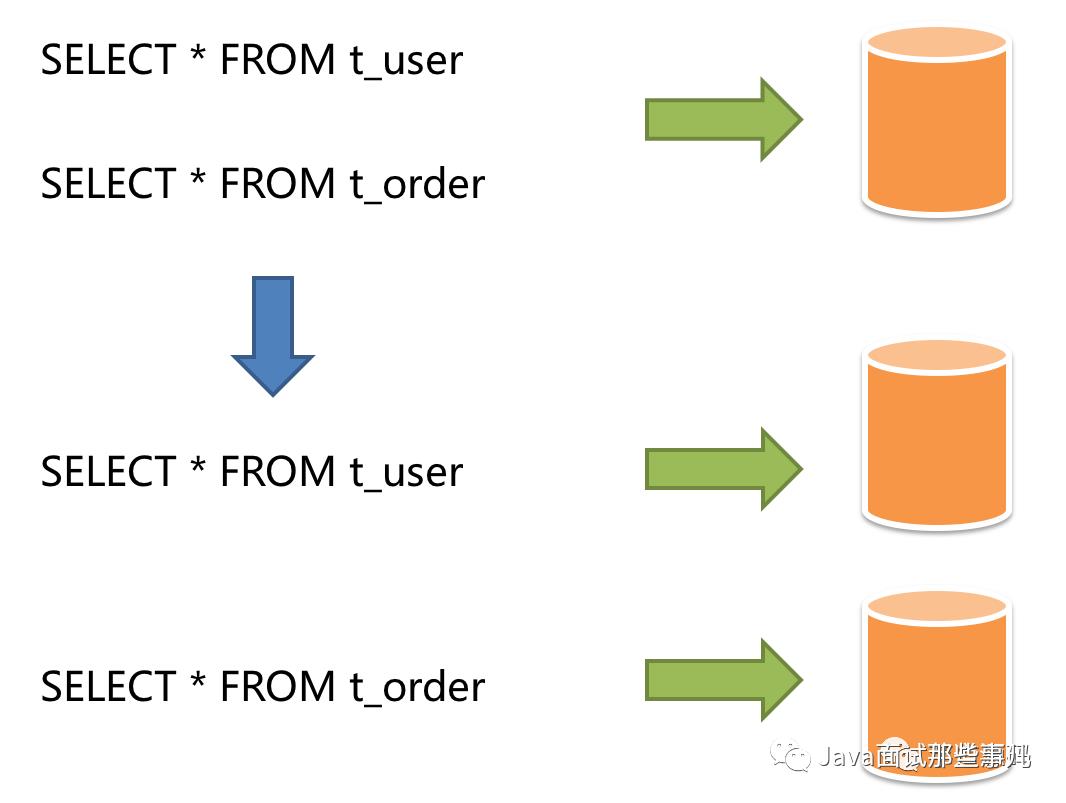
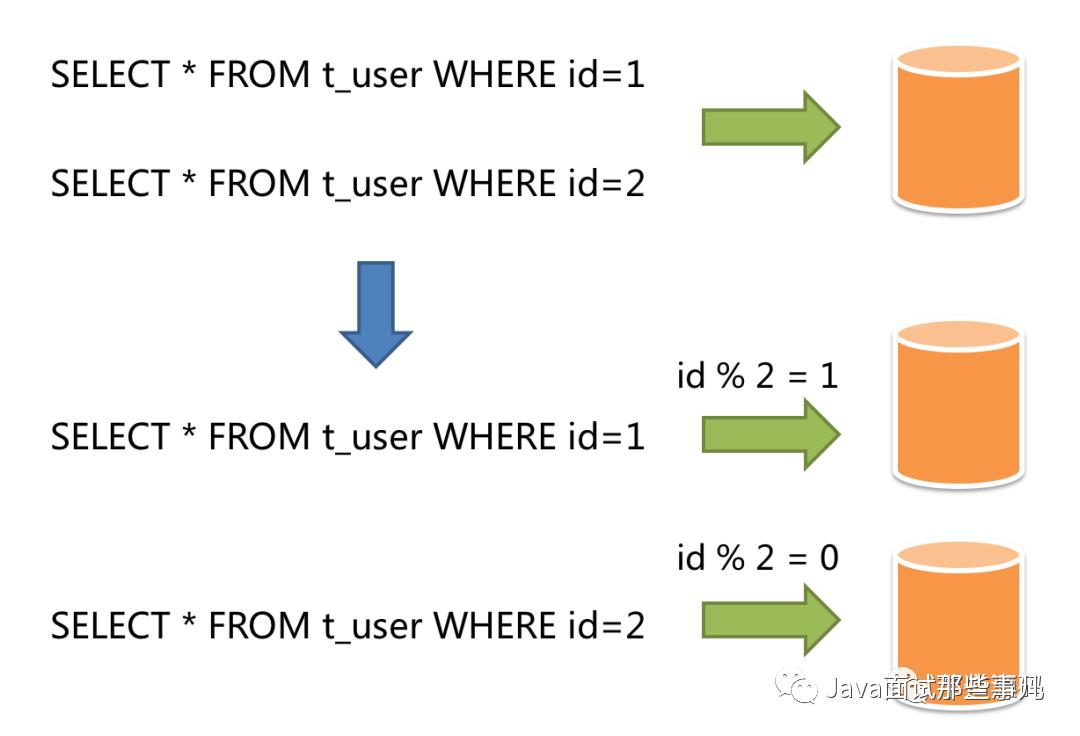
数据分片
核心概念
-
符号位(1bit)
-
时间戳位(41bit)
-
工作进程位(10bit)
-
序列号位(12bit)

使用规范
-
100%全兼容(目前仅MySQL,其他数据库完善中)
-
全面支持DML、DDL、DCL、TCL和部分DAL。支持分页、去重、排序、分组、聚合、关联查询(不支持跨库关联)。
-
不支持CASE WHEN、HAVING、UNION (ALL),有限支持子查询。
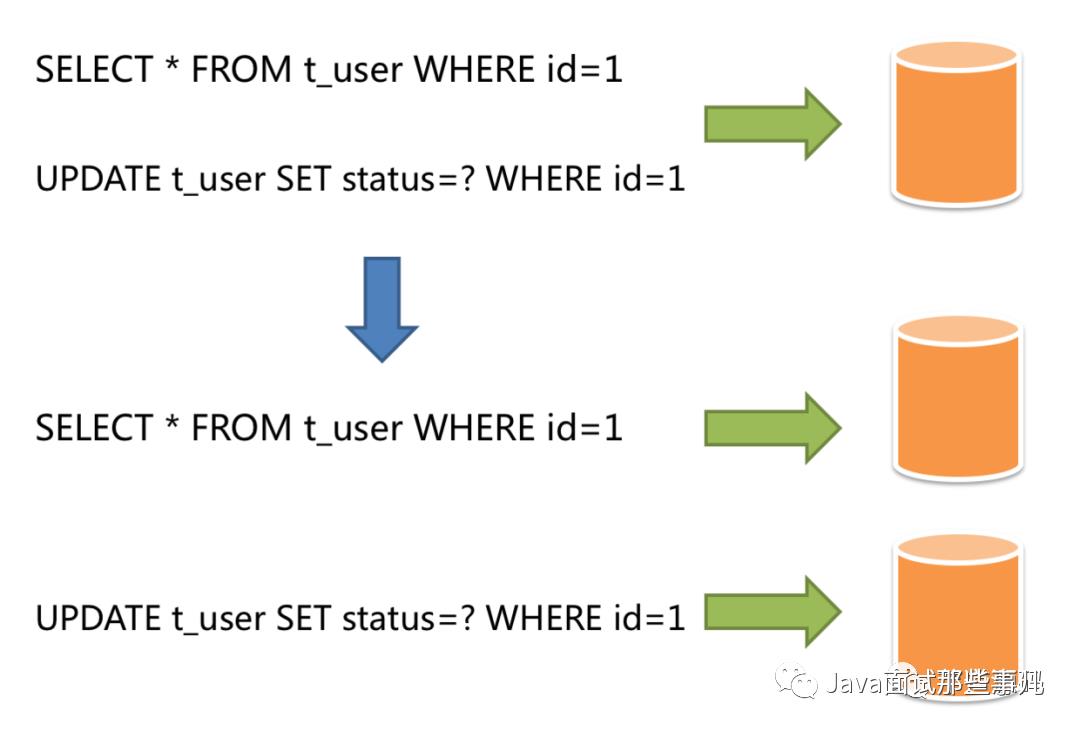
读写分离
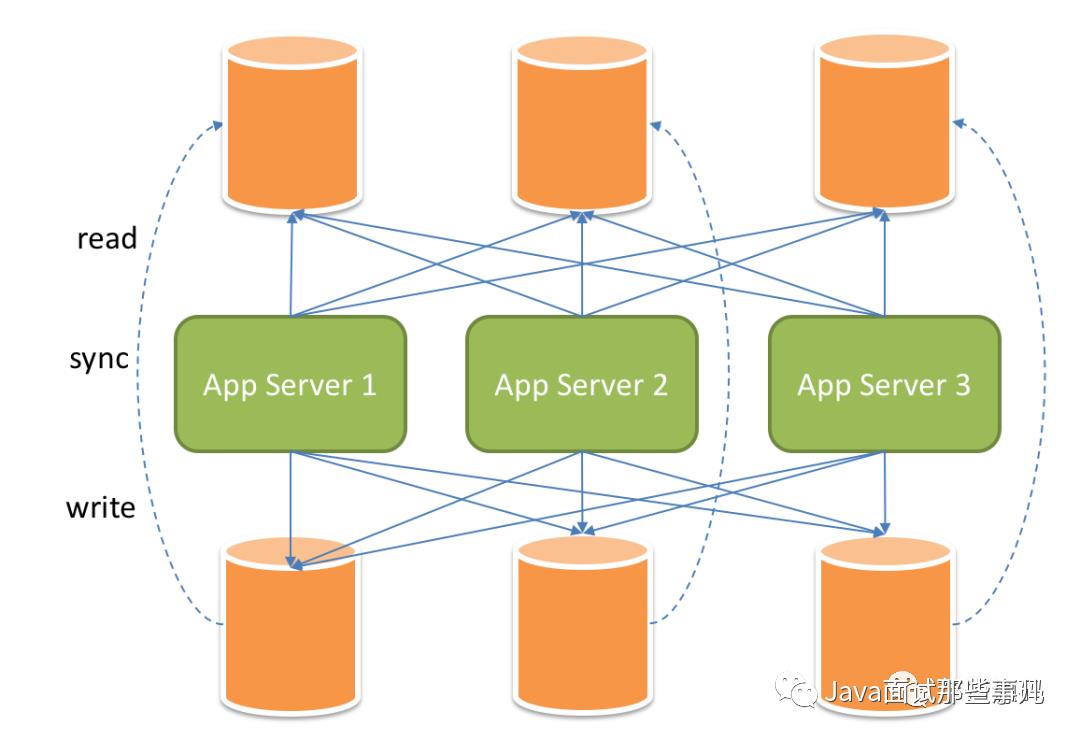
示例:水平分库分片
<dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>sharding-jdbc-core</artifactId> <version>${sharding-sphere.version}</version></dependency>
<dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>sharding-jdbc-spring-boot-starter</artifactId> <version>${shardingsphere.version}</version></dependency>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.3.1.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.cjs.example</groupId> <artifactId>sharding-jdbc-demo</artifactId> <version>0.0.1-SNAPSHOT</version> <name>sharding-jdbc-demo</name>
<properties> <java.version>1.8</java.version> </properties>
<dependencies> <!--<dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>sharding-jdbc-core</artifactId> <version>4.1.1</version> </dependency>--> <dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>sharding-jdbc-spring-boot-starter</artifactId> <version>4.1.1</version> </dependency>
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency>
<dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.22</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> <exclusions> <exclusion> <groupId>org.junit.vintage</groupId> <artifactId>junit-vintage-engine</artifactId> </exclusion> </exclusions> </dependency> </dependencies>
<build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build>
</project>
package com.cjs.example.sharding.entity;import lombok.Data;import javax.persistence.*;import java.io.Serializable;/** * @author ChengJianSheng * @date 2020-06-18 */ public class OrderEntity implements Serializable {
private Long orderId; private Integer userId; private Integer status = 1;}
package com.cjs.example.sharding.repository;import com.cjs.example.sharding.entity.OrderEntity;import org.springframework.data.jpa.repository.JpaRepository;/** * @author ChengJianSheng * @date 2020-06-18 */public interface OrderRepository extends JpaRepository<OrderEntity, Long> {}
package com.cjs.example.sharding.service;import com.cjs.example.sharding.entity.OrderEntity;import com.cjs.example.sharding.repository.OrderRepository;import org.springframework.stereotype.Service;import javax.annotation.Resource;/** * @author ChengJianSheng * @date 2020-06-18 */ public class OrderService {
private OrderRepository orderRepository; public void save(OrderEntity entity) { orderRepository.save(entity); }
}
package com.cjs.example.sharding.controller;import com.cjs.example.sharding.entity.OrderEntity;import com.cjs.example.sharding.service.OrderService;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RequestParam;import org.springframework.web.bind.annotation.RestController; /** * ChengJianSheng * 2020-06-18 */ public class OrderController {
private OrderService orderService;
public String save( Integer userId) { OrderEntity entity = new OrderEntity(); entity.setUserId(userId); orderService.save(entity); return "ok"; }}
package com.cjs.example.sharding;import org.springframework.boot.CommandLineRunner;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;import org.springframework.boot.autoconfigure.transaction.jta.JtaAutoConfiguration;import javax.annotation.Resource;import javax.sql.DataSource;/** * http://shardingsphere.apache.org/index.html * https://shardingsphere.apache.org/document/legacy/4.x/document/en/manual/sharding-jdbc/ * http://shardingsphere.apache.org/index_zh.html */ (exclude = JtaAutoConfiguration.class) public class ShardingJdbcDemoApplication implements CommandLineRunner { public static void main(String[] args) { SpringApplication.run(ShardingJdbcDemoApplication.class, args); }
private DataSource dataSource;
public void run(String... args) throws Exception { System.out.println(dataSource); }}
# https://shardingsphere.apache.org/document/legacy/4.x/document/en/manual/sharding-jdbc/
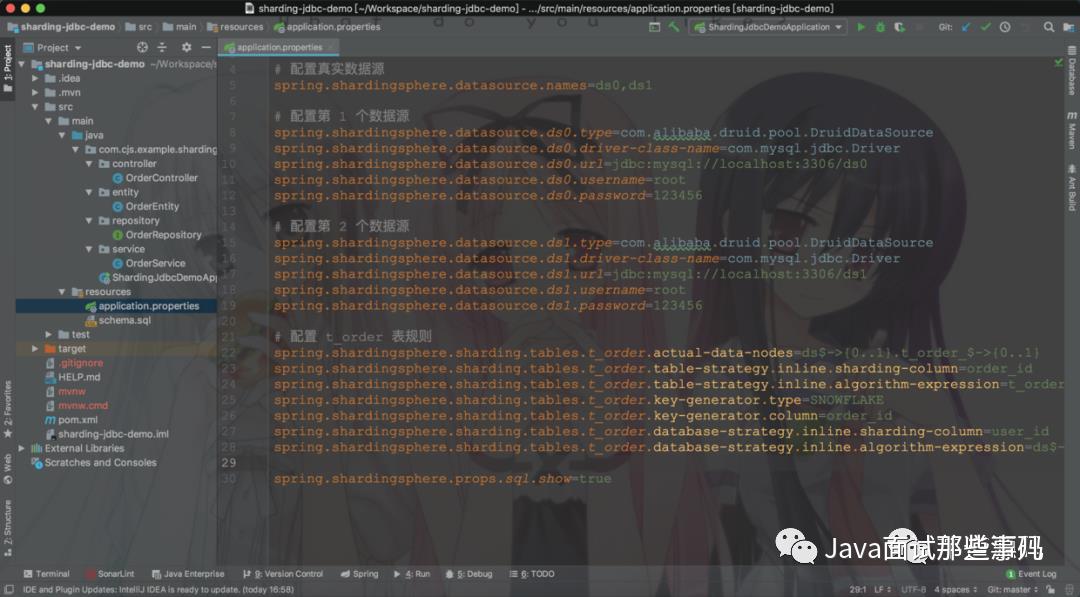
# 配置真实数据源spring.shardingsphere.datasource.names=ds0,ds1
# 配置第 1 个数据源spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSourcespring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.jdbc.Driverspring.shardingsphere.datasource.ds0.url=jdbc:mysql://localhost:3306/ds0spring.shardingsphere.datasource.ds0.username=rootspring.shardingsphere.datasource.ds0.password=123456
# 配置第 2 个数据源spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSourcespring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driverspring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/ds1spring.shardingsphere.datasource.ds1.username=rootspring.shardingsphere.datasource.ds1.password=123456
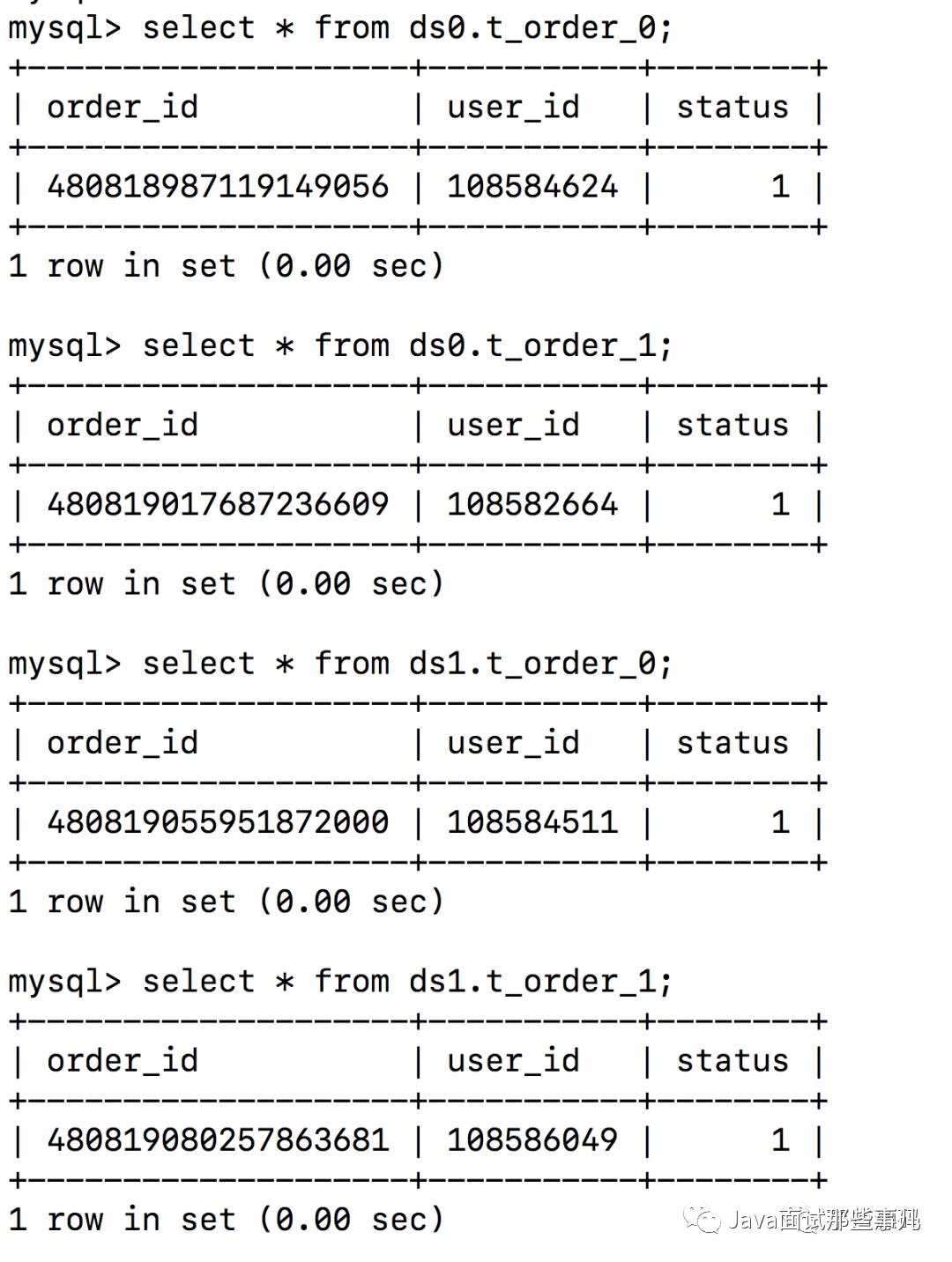
# 配置 t_order 表规则spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order_$->{0..1}spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=order_idspring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order_$->{order_id % 2}spring.shardingsphere.sharding.tables.t_order.key-generator.type=SNOWFLAKEspring.shardingsphere.sharding.tables.t_order.key-generator.column=order_idspring.shardingsphere.sharding.tables.t_order.database-strategy.inline.sharding-column=user_idspring.shardingsphere.sharding.tables.t_order.database-strategy.inline.algorithm-expression=ds$->{user_id % 2}
spring.shardingsphere.props.sql.show=true
# 写在最后
org.apache.shardingsphere.shardingjdbc.spring.boot.SpringBootConfiguration文档在这里:
https://shardingsphere.apache.org https://shardingsphere.apache.org/document/legacy/4.x/document/en/manual/sharding-jdbc http://shardingsphere.apache.org/elasticjob/
https://shardingsphere.apache.org/document/legacy/4.x/document/en/manual/sharding-jdbc/configuration/config-spring-boot/
热门推荐:

以上是关于面试三连问:你这个数据量多大?分库分表怎么做?用的哪个组件?的主要内容,如果未能解决你的问题,请参考以下文章