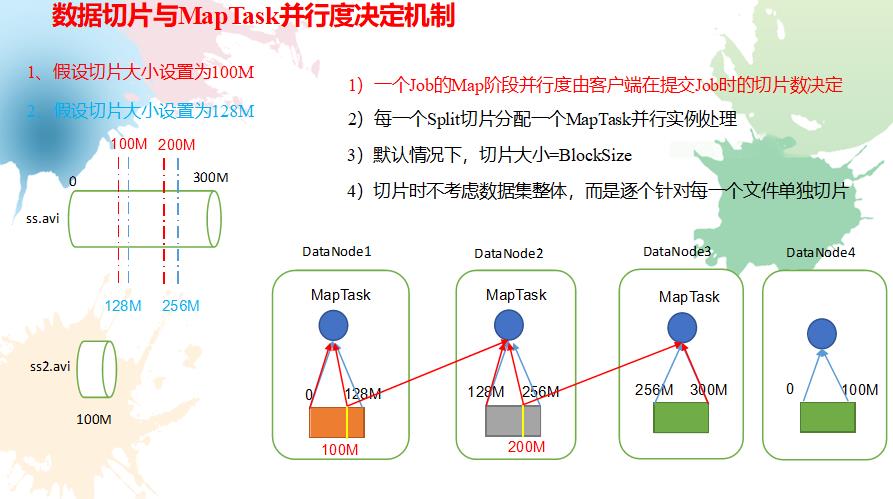
大数据之Hadoop(MapReduce):切片与MapTask并行度决定机制
Posted 浊酒南街
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据之Hadoop(MapReduce):切片与MapTask并行度决定机制相关的知识,希望对你有一定的参考价值。
以上是关于大数据之Hadoop(MapReduce):切片与MapTask并行度决定机制的主要内容,如果未能解决你的问题,请参考以下文章
大数据之Hadoop(MapReduce):切片与MapTask并行度决定机制
大数据之Hadoop(MapReduce):FileInputFormat,CombineTextInputFormat切片机制
大数据技术之_05_Hadoop学习_02_MapReduce_MapReduce框架原理+InputFormat数据输入+MapReduce工作流程(面试重点)+Shuffle机制(面试重点)(示例