数据库SQL原理丨产品经理扫盲贴
Posted Wcof
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库SQL原理丨产品经理扫盲贴相关的知识,希望对你有一定的参考价值。
最近花了一段时间对数据库、SQL、mysql等概念给自己做了一次扫盲,也算是对自己希望了解数据库知识这桩心愿终于做了了结。
为什么想学数据库知识呢?主要有2个原因。
一是因为越来越多的高级产品经理都要求对数据库、SQL语言有所了解和涉及,这样在架构层面能更好地与程序员搭配干活,同时在运营上也能更好地对数据和指标进行深挖。
二是因为自身也希望对产品的底层架构设计有更多的了解和参与,这样一来,不仅自己在产品设计时能够提出更符合底层架构的方案,同时也能尽量避免前期架构臃肿、缺乏可扩展性,导致后期改动难度大、波及范围广的问题。
就正如DDD领域驱动设计所传递的概念:产品设计需要先从理解业务开始。产品经理本身是一个「翻译官」的角色,将用户的需求翻译成业务模型、再将业务模型转述翻译给研发,那么在这样一个多角色联动的流程中,无可避免地会存在「翻译出现误差」的情况。因此,当产品经理懂一些底层的技术模型原理,自然就能够让整个翻译理解的过程更为顺畅和还原。
最终,在历经一段时间的自学之后,最终笔者希望通过这篇扫盲贴,帮助像我一样0技术背景的产品经理了解需要懂的数据库和SQL原理,强调一点,这里以原理为主,不涉及到具体的实操,对于非技术相关的产品经理来说基本足矣。
此外,因为笔者擅长将一维文字转换为二维图像,所以本文会用大量图解的形式去讲述底层原理,让这篇扫盲贴更容易为大家所理解。话不多说,现在就开始吧。
一、数据库、SQL、MySQL之间是什么关系?
日常工作中,总是听程序员把数据库、SQL、MySQL这些词挂在嘴边,但总是分不清楚他们之间的关系。于是,这些学习之前,索性就先把这些名词和概念搞清楚再开始。
结构化查询语言Structured Query Language,适用于查询关系型数据库。
关系型数据库管理系统Relational Database Management Systerm,例如我们常见的MySQL、Oracle、SQL Server等。
这三者完全是不同维度的概念,他们的关系可以高度概括为一句话:用户使用结构化查询语言,在关系型数据库管理系统上对数据库中的数据进行增删改查的操作。
和关系型数据库相对的还有非关系型数据库NoSQL(即Not only SQL),用户对这类数据库的交互和操作与关系型数据库基本一致。后面我们会具体介绍关系型数据库与非关系型数据库的区别。
二、数据库是什么?有哪些类型?
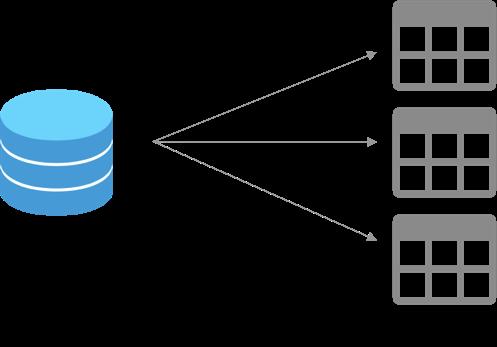
简而言之,数据「库」就像一个库房,其中存储的物品就是大量的数据;而数据在经过整理和归纳之后,就以表的形式存在在数据库里。就如下图所示:
前面提到了关系型和非关系型数据库,这也是程序员大佬们常常挂在嘴边的一些概念。数据库最常见的2种类型就是关系型和非关系型。
关系数据库:
把复杂的数据结构归结为简单的二元关系(即二维表格形式),选用由列和行构成的二维表来管理数据,整体简单易懂。
非关系型数据库:
主要是根据“非关系实体模型”的数据库,也称之为NoSQL(Not only SQL)数据库。NOSQL数据库在特殊的情景下能够充分发挥出无法想象的高效率和卓越性能。
看到这里,估计大家也和我一样好奇,具体哪一种数据库会更好一些呢?什么时候用哪类数据库呢?
整体而言,存在即合理。2类数据库没有绝对的好与坏,只有各自更为适用的场景,只要选用恰当,二者都能有较好的表现。对二者具体差异感兴趣的朋友,可以点连接去了解:
https://www.jianshu.com/p/fd7b422d5f93
,微信不能放外链,只能给具体的链接地址了。
2.1 数据库的设计
数据库从无到有,自然就需要经历一个「设计」的过程。这里我们不讲具体的设计实现,而讲一讲库表的设计理念和流程,帮助大家形成大致的框架即可。
数据库的设计流程
设计数据库需要历经6个流程:需求分析、概念结构设计、逻辑结构设计、物理结构设计等。对于产品经理来说,理解和参与前面2个已经基本足够。
数据库的存在必定是为了满足人们使用和处理数据的需求,故而这一阶段是设计数据库的起点,也是产品经理在其中起最大作用的一个阶段。
在需求分析阶段,产品经理需要尽可能抽象的提炼业务模型及业务数据,并结合中长期的业务发展走向,协助数据库设计人员设计出既符合实际需求又符合设计准则的数据库表。
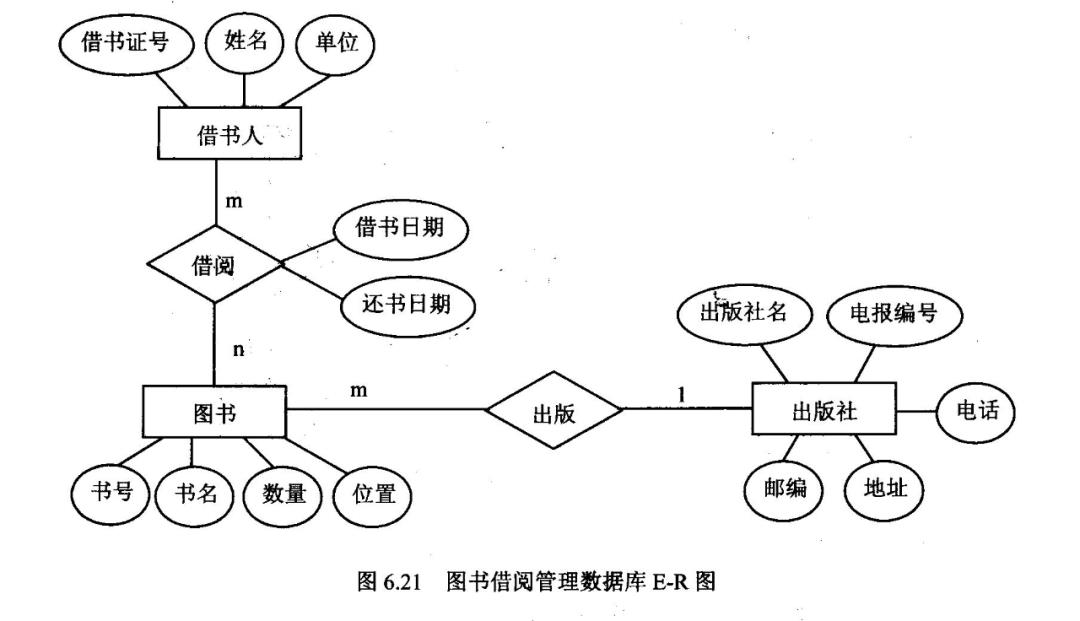
当需求分析结束后,数据库设计人员就要根据业务模型进行综合归纳与抽象,形成相应的概念模型。这里,我们常常会使用的一种工具就是E-R图(Entity-Relationship实体关系图)。
方框是实体、椭圆是属性、横线上表示联系关系,m、n、1表示了实体件是一对一、一对多还是多对多的关系。
从上图中,我们能够很清晰地识别和梳理出借书人、图书和出版社之间的关系。这里不展开讲述E-R图的绘制方法和原则,感兴趣地可以点下面链接去详细了解:
https://blog.csdn.net/chenpidaxia/article/details/62073162
在邱岳产品训练营课程中,他提出过一种观点,那就是“ 产品经理是从使用(消费)的角度去感受,从设计(生产)的角度去思考 ”。从这个角度就能很好解释为什么大厂会青睐于有技术背景的产品经理,因为技术思维能够让我们具备更强的归纳和抽象能力,至少在第二方面(从设计的角度去思考)具备一定可衡量的基础能力。
除E-R图之外,我们还可以尝试学习一些UML统一建模语言,帮助我们更好地从「设计」的角度出发,提升整个解决方案的可落地性和可扩展性。笔者此前在项目管理学习中学习过UML,但是更多是为了应试,并没有太深入的钻研和理解,期望后半年能够专门挪出一段时间来进行UML的深入学习。
三、SQL语言怎么用?
在数据库设计好后,我们就可以对数据库中的数据进行增删改查操作了,这里自然就要引入数据库查询操作语言的介绍了。数据库的查询操作语言有很多种,SQL是其中较为热门的一门语言,故而笔者选择了SQL来进行深入的学习和实操。
SQL语言操作对象的最小单位是表,放大来看,SQL可以对数据库database、视图view、数据表table、索引Index等进行增删改查的操作。这4类我们将其抽象为一个统一的对象,如下图所示:
如上所示,SQL操作主要分为增删改查4大类,其中数据库查询和修改Update的占比为10:1,即我们大部分对数据库的操作时间都集中于查询上面;同时增删改的操作本身也是建立在查询的基础上才能有所修改。
所以,我们下面重点来讲讲如何用SQL执行查询操作。
3.1 查询顺序
SQL不像其他语言是按照代码撰写顺序去执行命令的,而是有自己的一套执行顺序。为了更好地理解SQL查询,我们先来看看SQL的查询顺序是怎样的?
执行顺序:FROM>ON>JOIN>WHERE>GROUP BY>CUBE|ROLLUP>HAVING>SELECT>DISTINCT>ORDER BY>LIMIT
下述具体顺序介绍来自于掘金
SQL查询语句执行顺序详解
,我对其中一些点做了口语化的解释,便于大家更好地理解。
作用:对FROM子句中的左表和右表执行笛卡儿积(Cartesianproduct),产生虚拟表VT1
解读:如果只查一张表,那么直接就拿出这个表;如果要查多张表,那么就执行笛卡尔积,生成一张新的虚拟表VT1;
作用:对虚拟表VT1应用ON筛选,只有那些符合<join_condition>的行才被插入虚拟表VT2中
解读:对VT1中生成的新表进行ON筛选,只选出那些符合连接条件的行
作用:如果指定了OUTER JOIN(如LEFT OUTER JOIN、RIGHT OUTER JOIN),那么保留表中未匹配的行作为外部行添加到虚拟表VT2中,产生虚拟表VT3。如果FROM子句包含两个以上表,则对上一个连接生成的结果表VT3和下一个表重复执行步骤1~步骤3,直到处理完所有的表为止
解读:如果需要从多张表中拿数据,那么JOIN语法就用于将多个表联接起来
对虚拟表VT3应用WHERE过滤条件,只有符合<where_condition>的记录才被插入虚拟表VT4中
根据GROUP BY子句中的列,对VT4中记录进行分组操作,产生VT5
对表VT5进行CUBE或ROLLUP操作,产生表VT6
对虚拟表VT6应用HAVING过滤器,只有符合<having_condition>的记录才被插入虚拟表VT7中。
第二次执行SELECT操作,选择指定的列,插入到虚拟表VT8中
将虚拟表VT9中的记录按照<order_by_list>进行排序操作,产生虚拟表VT10。
取出指定行的记录,产生虚拟表VT11,并返回给查询用户
由上文可以看出共包含11个步骤,最先执行的是FROM操作,最后执行的是LIMIT操作。每个操作都会产生一张虚拟表,该虚拟表作为一个处理的输入。这些虚拟表对用户是透明的,只有最后一步生成的虚拟表才会返回给用户。
3.2 疑难点
具体查询语言中还包含TOP、LIKE、BETWEEN等等很多语法,这里不再赘述,有兴趣学习的盆友可以前往
W3School-SQL教程
中进行学习。下面,我将重点列出一些学习过程中可能容易产生困惑的一些难点,供大家学习完后回来参考。
3.2.1 WHERE和HAVING的区别是什么?
Where和Having都是通过条件筛选数据,在不对照理解的情况下很容易搞混淆。因此,在查了一些资料之后,进行了二者区别的整理,如下所述:
-
Where子句不能使用聚合函数,而Having子句可以使用聚合函数(即Aggregate function,例如AVG、COUNT、MAX等)
-
Where执行早于Having,它针对的是数据表中原有字段;而Having则在Where的基础上能够Select出来的结果做一次Having筛选
3.2.2 JOIN的连接方式
关系数据库联表查询的原理来源于集合代数,所以我们这里将用集合的方式来介绍JOIN语法。JOIN语法共分为4种:内连接、左连接、右连接和全连接。下面我们将用图示的方法进行解释(提示:上图以大致理念为主,细节并不绝对准确)。
官方描述:在表中存在至少一个匹配时,INNER JOIN 关键字返回行。
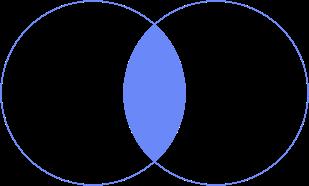
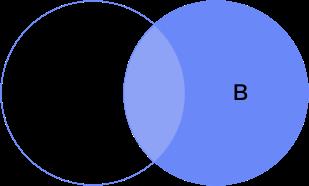
官方描述:查询的结果为两个表匹配到的数据+左表特有的数据,对 于右表中不存在的数据使⽤null填充
解读:以左侧A集合为主、右侧B为辅,找出A在B中的映射,有的话则显示、没有的话则为空
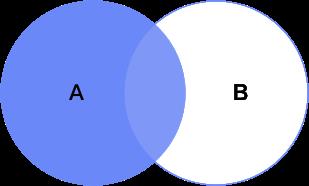
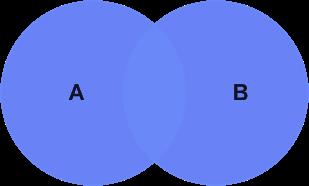
官方描述:只要其中某个表存在匹配,FULL JOIN 关键字就会返回行。
解读:只要A、B两表有字段匹配,则返回两表全部数据
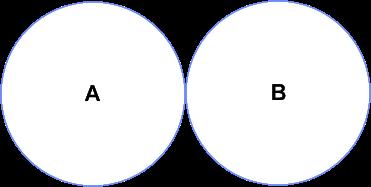
3.2.3 JOIN和UNION的区别是什么?
在学完JOIN之后,很快就来到了UNION语法,好像这个也是将两个表连起来,那么区别是什么呢?
UNION用于合并两个或多个 SELECT 语句的结果集。
UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。
连接方式:左右连接,依靠两张表中相同的字段进行表的左右连接
连接方式:上下拼接,依靠两张表中相同的数据类型进行表的上下拼接
基本要求:多个Select语句筛选出来的列及列顺序必须相同,列的数据类型也必须相似。
3.3 索引Index
最后一部分,我们来讲讲什么是索引,为什么要在表里创建索引。
数据库就像一本书,而索引就是这本书的目录。为什么将索引比喻成目录呢?是因为目录能够通过列表和页码帮助我们快速找到想看的内容,那么索引也具备同样的价值。
在学习SQL语言时,我发现定义某张表的索引基本只需要给出所需列名column_name即可,竟然不需要任何其他操作。那之前零散了解到的B+树、红黑树又是在哪里用呢?
原来数据库操作系统已经对索引算法做了一层封装和默认处理,千万数量级以下的数据库查询操作基本不需要额外进行自定义,因为即使自定义后,差距也可能不会非常明显。所以,这里的索引创建反而相对变成了一件十分简单的事情。
即使索引已经被数据库管理系统进行了封装,但是自己还是很好奇索引到底是如何优化我们的查询速度和性能的。在查了一些资料后,得出如下定义:
索引的本质就是:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
下面我们举一个B+树索引的例子来帮助大家理解。下图中,我们希望在1-100中快速找到56,那么我们先判断56是在1-50之间、还是在51-100之间,在确定56在51-100之间后,再确定56是在51-75之间等等,这样不断缩小范围来提升查询速度。否则,我们就要读取56条数据之后才能找到56这个数字。
综上,笔者为大家提供了数据库、SQL的基础扫盲内容。整体以理念和原理为主,没有展开讲太多的实操内容,对于非技术相关的产品而言,短期内应该基本够用。如果大家还有兴趣再深入了解,下面给出几个学习链接供大家享用:
https://www.icourse163.org/learn/JXNU-1206665801?tid=1450753445#/learn/announce
https://www.w3school.com.cn/sql/index.asp
以上是关于数据库SQL原理丨产品经理扫盲贴的主要内容,如果未能解决你的问题,请参考以下文章
看产品经理怎么用360实现Java垃圾回收!
程序员:大师,产品经理又欺负我......
程序员和产品经理的时间之战
产品经理常用的UML建模图形
如何让产品经理不改需求?
产品经理和Scrum Master都必须是领域专家吗?