Paddle 经验分享利用PaddleHub 2.x 完成文本分类训练的坑
Posted dotNET跨平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Paddle 经验分享利用PaddleHub 2.x 完成文本分类训练的坑相关的知识,希望对你有一定的参考价值。

CSDN原文链接:https://blog.csdn.net/kinfey/article/details/117254781
基于项目选择了PaddlePaddle 作为文本分类的基础,经过一周多的使用终于有所进展,把文本分类的相关工作做了一个简单模型。
首先说说PaddlePaddle , 现在做深度学习,更多用户使用的是TensorFlow / PyTorch ,但其实还有很多类似的框架,PaddlePaddle就是其中之一。有人会说TensorFlow / PyTorch 已经这么优秀了,为何还用 PaddlePaddle 呢 ?我这里也想结合一周多的使用说说 。当初使用 Paddle Paddle框架我看中的是他在自然语言中文领域有很多现成的模型,举个例子如情感分类,如阅读理解,还有自动问答等,而且在使用上也是非常简单。我就是奔着这个去的,至于其他像内存占用小啊,API易用这些用过就知道其实是一个场景相对的工作。如果我们使用自然语言相关,我是建议使用,但在计算机视觉或者其他的都差不多。PaddlePaddle 在设计初期就兼顾了动态图和静态图,所以还是不错的。
PaddlePaddle 有不少预训练的模型,基于预训练组建了一个PaddleHub , 可以让你快速调用并完成模型的管理,你还可以基于自有的模型做迁移学习,更好地服务应用场景。这里做文本分类,我就直接用了PaddleHub 自有的 ERNIE 进行迁移学习。就这样我就开始了一段神奇之旅。

一.ERNIE
在中文领域,这是一个非常非常棒的自然语言模型,和BERT 比,采用了先知Mask机制,和随机Mask 的BERT比,能更有效对中文常用词进行判断。更多可以参考 https://github.com/PaddlePaddle/ERNIE。

二. 具体使用遇到的一些问题
PaddlePaddle 在网上搜索的例子都是有问题的,因为基于原来的例子基本是按照1.x 版本(https://aistudio.baidu.com/aistudio/projectdetail/186443)改的,只能自己碰。
1.环境问题
我现在的Cuda 环境是11.1 , 但是无论最新的2.1 还是2.0.2 其实都没有支持的,开始我自己也慌了第一步就放弃么?但我认真看了下,其实2.0.2 是支持11.0 也是可以在11.1的CUDA上跑,所以安装环境就变成了:
pip install paddlepaddle-gpu==2.0.2.post110 -f https://paddlepaddle.org.cn/whl/stable.html2.ERNIE 版本选择
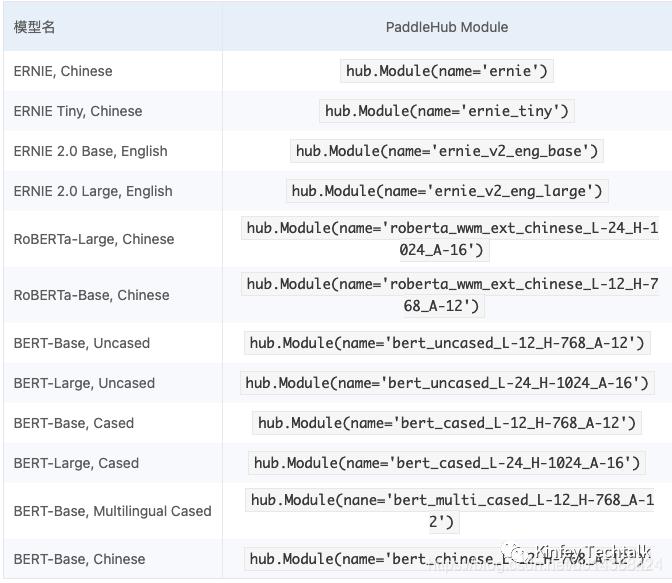
其实我本来想要ERNIE,但最后选择ERNIE-TINY是因为他更小巧,更适应我的场景, 如果你想应用其他也是可以的,他支持多种语义模型。

3.TextClassificationDataset
因为我是做迁移学习的文本分类所以这里就需要去继承原有的TextClassificationDataset,我一直觉得是一个简单活,结果花了我一堆时间,因为这里对数据格式有要求,第一列必须是Label , 而且token是一个Bert+Custom , 并且一定要做好测试集和训练集,这里我真的花了5天去找,但最后还是追看TextClassificationDataset 找到答案,主要是文档太少。

4.traindata
训练这里细节也挺多的,特别最基本的一个traindata 这里要说,我发现是要补充上learning_rate ,否则有些东西奇奇怪怪。

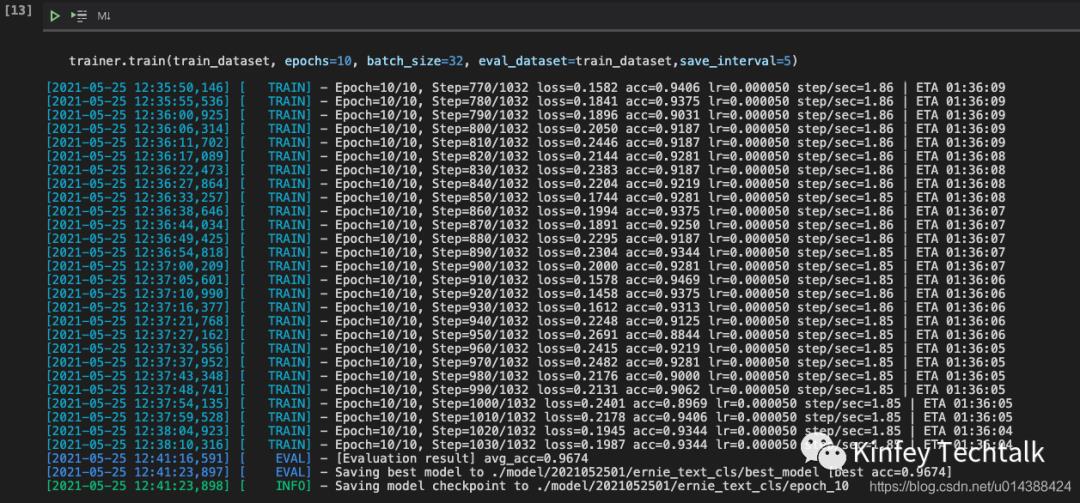
这是我训练的一些结果,还是不错,这个过程我花了5个工作日,真是痛哭流涕。

三、一些工作还是要继续的
1. 部署,其实PaddleHub建议用PaddleServing 来部署的,但由于现在模型还在调整,数据在增加,所以临时方案还是直接用PaddleHub去解释模型,这里内存在服务器占用大,要改进
2. 调优,还有很多方法,还在学习中,希望日后可以填上
3. onnx , 还是想转换为onnx ,但文档很少,还是得花时间
4. 压缩,模型压缩就是技术活了,怎么样能做到一个精度高,容量小的模型,又是我要考虑的了
学习是一步步的,经过1周多,终于有成果, PaddlePaddle是好东西,但文档,例子欠缺,我希望利用自己项目的经验分享给大家。

以上是关于Paddle 经验分享利用PaddleHub 2.x 完成文本分类训练的坑的主要内容,如果未能解决你的问题,请参考以下文章
森说AI:从零开始应用paddlehub转换手写数字识别模型并完成部署:使用paddle2.xAPI简易实现手写数字识别模型
森说AI:从零开始应用paddlehub转换手写数字识别模型并完成部署:使用paddle2.xAPI简易实现手写数字识别模型