森说AI:从零开始应用paddlehub转换手写数字识别模型并完成部署:使用paddle2.xAPI简易实现手写数字识别模型
Posted 神佑我调参侠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了森说AI:从零开始应用paddlehub转换手写数字识别模型并完成部署:使用paddle2.xAPI简易实现手写数字识别模型相关的知识,希望对你有一定的参考价值。

欢迎关注我的公众号:森说plus 我以后的所有东西都会放在上面哦!
前言
AI创造营留了一个关于服务端部署的作业,我也是第一次弄这个,然后看到有个项目是那样,所以我先跑通一下流程,然后在进行创新!我用过paddleseg和paddledection,也想过去自己做一个全流程的,但是都没有机会,这次我打算去尝试一回。
开始吧!
手写数字模型制作(简单)
其实我们都知道我们在写代码的开始就要去导入各种的库,那么首先我就得知道我该导入哪些库?
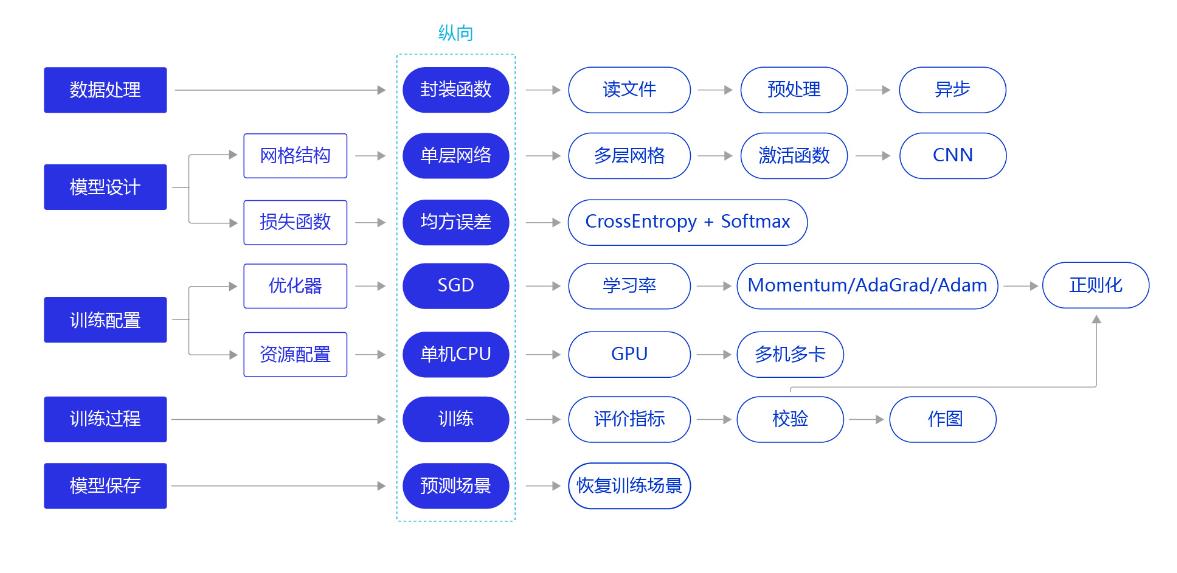
这个时整个过程,先进行的是数据处理,然后设计网络结构,训练配置,训练,模型保存
#加载飞桨和相关类库
import paddle
from paddle.nn import Linear
import paddle.nn.functional as F
import os
import numpy as np
import matplotlib.pyplot as plt
这些是官方文档的库的导入,我们来分析一下:主要就是前三个,后面几个我知道。这里一边做一边考虑
这个是官网:https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/02_paddle2.0_develop/02_data_load_cn.html
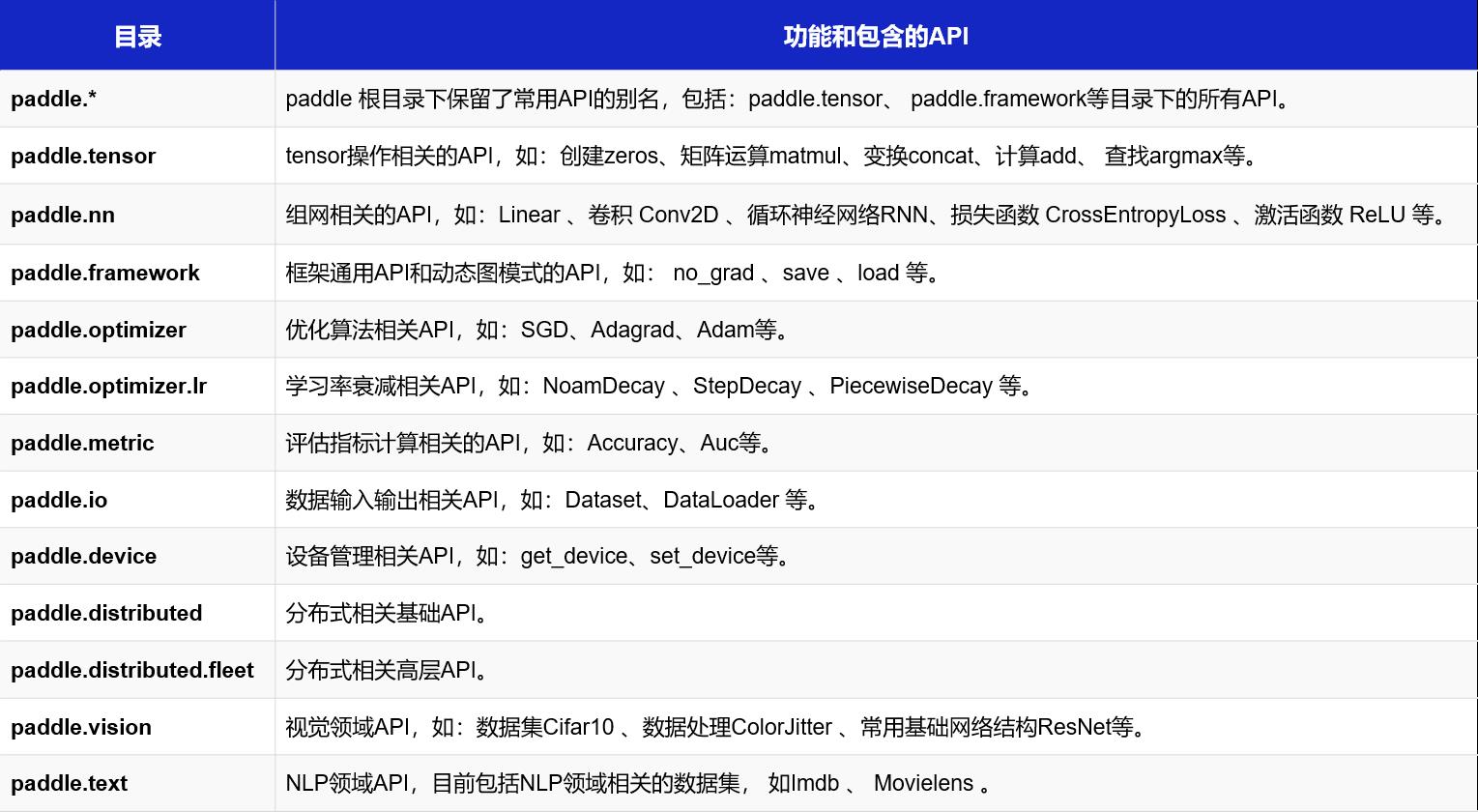
这个图很关键,我得记住。
数据处理
对于深度学习的数据有两种得到方式,第一种去使用现在已经存在的数据集,对应的话飞桨也是有对应的api可以去直接获取,第二种就是自己去获取数据集并且标注,很是浪费时间,但是有时候确实没办法,所以在考虑数据集的时候优先考虑网上是否存在数据集。
那么我们现在就去文档中找到怎么可以导入数据!
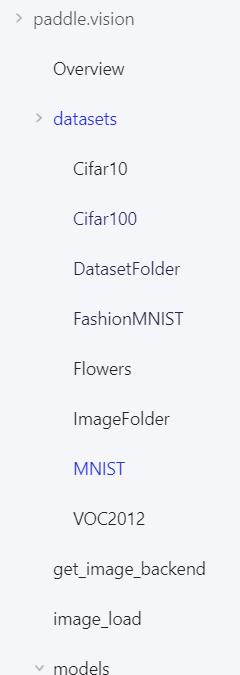
可以看到这些数据集飞桨是已经写好api了,然后我们开始加载!
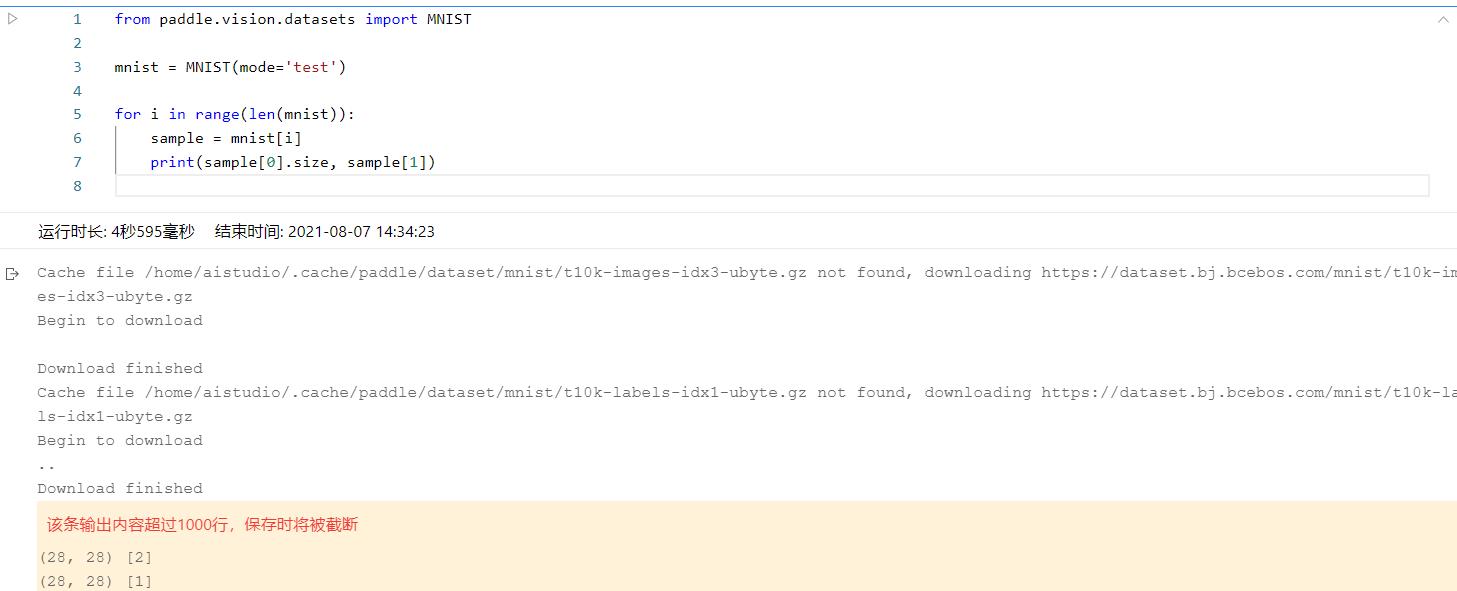
然后确实是下载成功了,但是这些图片没有保存到项目中呀,然后我看了文档是要用一个变量接受。
我们去做一下:
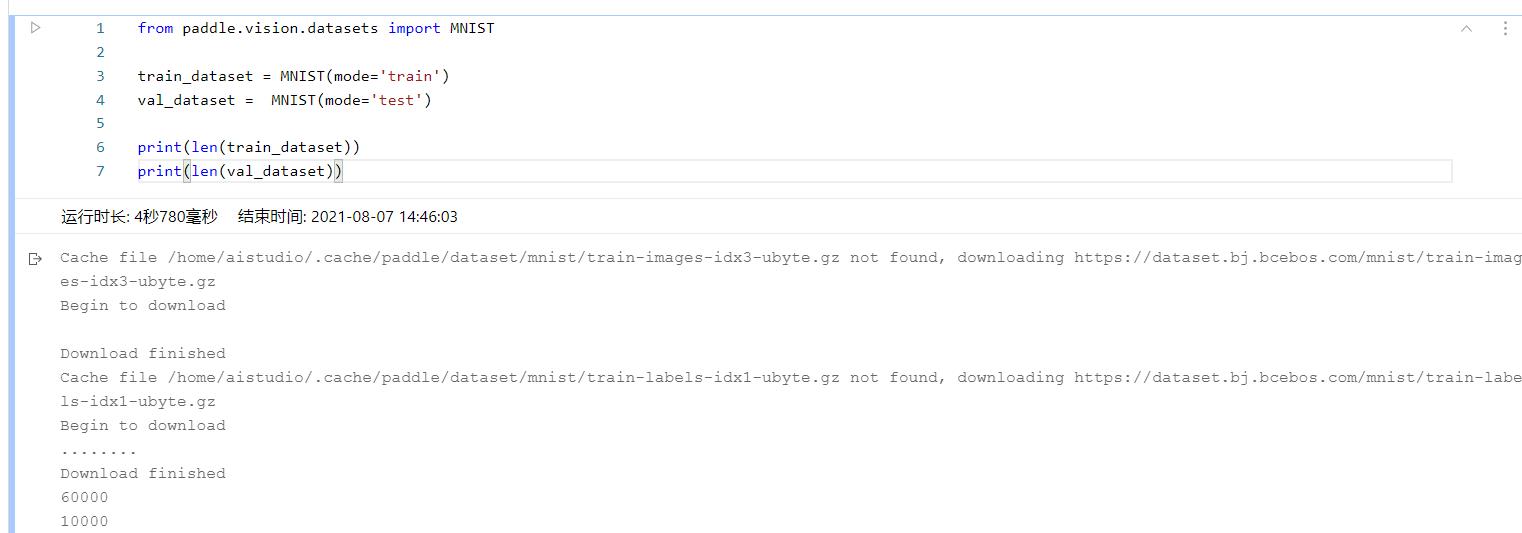
ok,现在我们已经下载好数据集了,然后我们去看一下数据!我们将第一张图片保存下来看一下(所有可执行的代码都在ai stdio上):
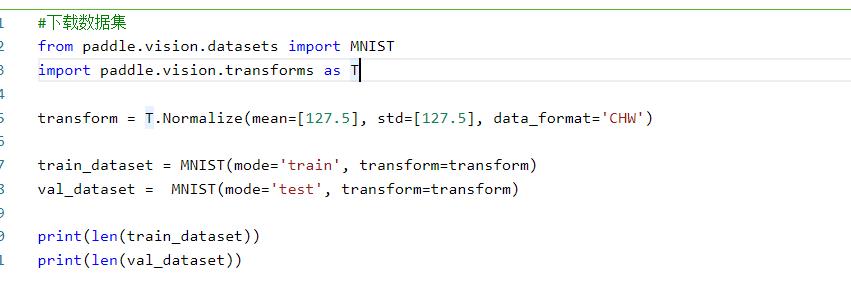
数据得到了,我就就要对数据进行预处理,这里对数据进行归一化,在文档中还有很多以后可以尝试!然后这里的话如果是内置数据集的话可以在加入数据集的同时进行预处理:

所以我们更改上面加载数据集的代码:
到这里数据已经制作完毕了,下一步搭建网络模型
模型搭建
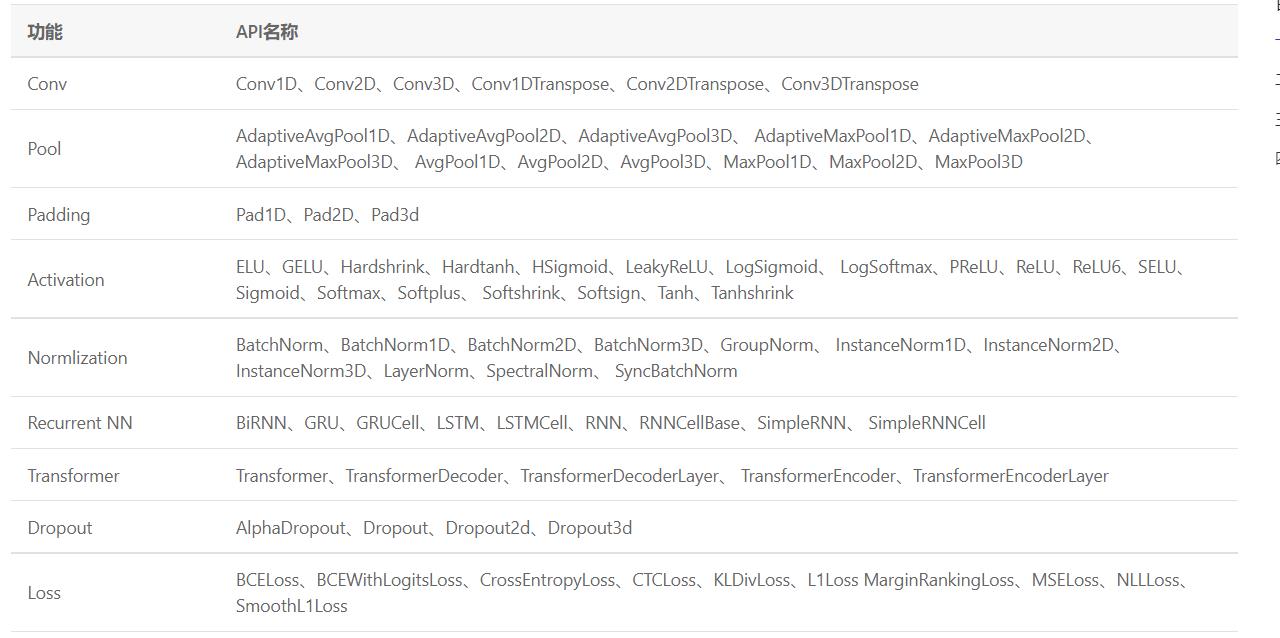
这时就不得不去了解paddle.nn这个api了。飞桨框架2.0中,组网相关的API都在paddle.nn目录下,你可以通过 Sequential 或 SubClass 的方式构建具体的模型
然后这里面虽然有两种组网方式,但是我建议使用第二种,也就是SubClass 组网,然后我们在看一下吧
使用时必须继承layer,在__init__构造函数中进行组网Layer的声明,在forward中使用声明的Layer变量进行前向计算。当然飞桨也内置了很多的模型,但是这里为了练习还是手动实现一个模型,可以先用代码去看到模型的网络结构然后再组网。这里有个细节就是我们想看一个部分的全部东西的话要用到.__all__,下面演示一下,看下这里面有哪些模型。

可以看到模型还是很多的,这里我将构建lenet模型,先看看网络结构:应用的函数为summary
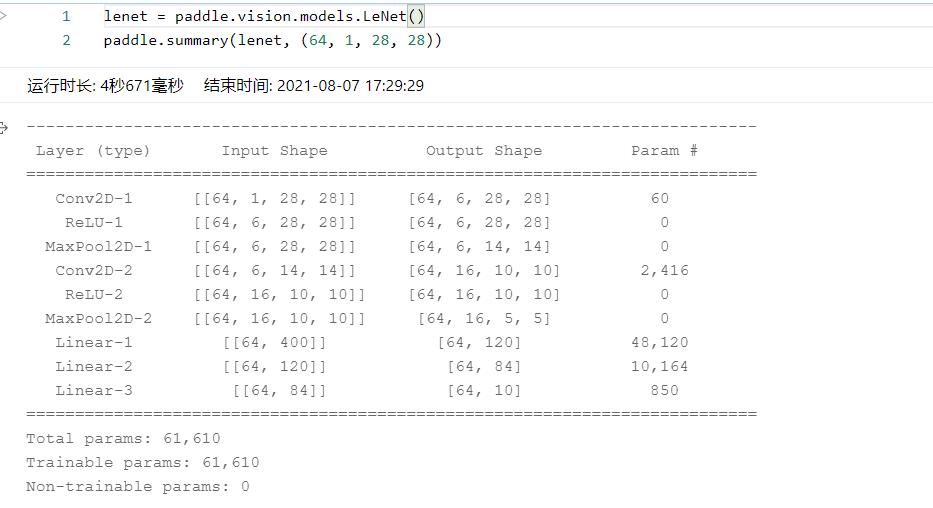
然后LeNet的网络结构我感觉并不是很难,然后我也找到了官方的网络代码,试试看,但是我也不知道怎么去搭呀,可是前几行应该是不变的,先写下来!

然后self.flatten = paddle.nn.Flatten()这个也要写上,作用为将原来维度的tensor转化为一维的tensor,我个人理解是一维的代表特征好计算,下面看这两张图片:
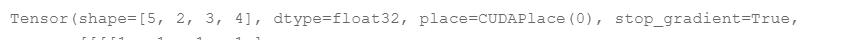

然后就是开始写层了,这时我们不得不考虑的问题就是投入的数据问题,一般都是4维的NCHW,先说说各自的含义,N就是多少个,因为我们投放数据的时候不是一个个投的,而是一下子放入batch个,c是channel的缩写通道,HW分别代表高和宽。然后我们先看一下上面的LeNet的网络结构卷积,激活,池化2遍然后是3个线性层。然后可以看到N为64,然后通道数是1,hw为28,是不是呢我去验证一下!
确实如此,所以说用这个数据结构作为我们网络的输入。然后我们先写卷积层,但是得先知道卷积层的api,这里就得先去了解一下nn.Conv2D了:

该OP是二维卷积层(convolution2d layer),根据输入、卷积核、步长(stride)、填充(padding)、空洞大小(dilations)一组参数计算输出特征层大小。卷积就是为了得到特征的,然后这里居然还有空洞的,真是好的呀。 nn.Conv2D(1, 6, 3, stride=1, padding=1)这个是官方的写法,这里我就很困惑,这些值都是哪来的。原来所有的这些数据都是根据论文来的,所以可以看看论文,然后再来理解:
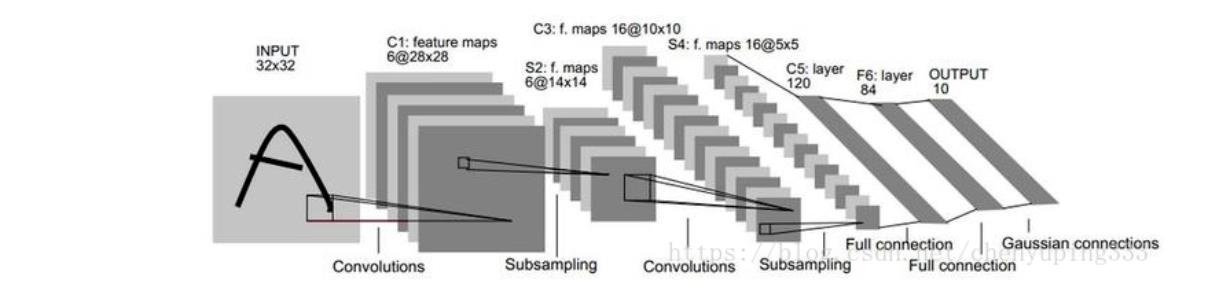
这个是论文中最重要的图了。可以看到输入进去的是3232的,但是我们这里的数据是2828的,所以开始可能不太一样,那么第一次的卷积不能改变大小,其实后面的我就很理解了,就是这个第一层的不是很理解,后面的还是可以的,那么我就先说一下后面的吧,这里是输入3232的图片,然后通过卷积得到2828的feature map这里的6是卷积核的意思,然后一个池化层也就是下采样,这里用的是最大池化,之后得到1414的,然后再一次卷积这时卷积核是16个得到55的map,最后3个全连接层,得到output,所以对我来说最重要的就是先实现第一层,因为输入的大小不一样。这里我直接投放个数据在卷积api里试试。这里面有个缺点就是我对有N的tensor就不会处理了,这里我先不带卷积了,我先简单的跑一遍,因为最主要的还是要根据自己的数据集再来做一遍,到时候我再加入卷积。
简单手写数字识别实现
那么我们这里就先搭建一个网络模型,写一下:
前几行的话比较有固定的套路
class Mnist(paddle.nn.layer):
def __init__(self):
super(Mnist,self).__init__()
然后的话我们这里就定义一个全连接层,输入为28X28=784,然后输出为1
self。fc = paddle.nn.Linear(in_features=784, out_features=1)
之后我们去写一下前向传播:
def forward(self,x):
y = self.fc(x)
return y
# 定义mnist数据识别网络结构
class MNIST(paddle.nn.Layer):
def __init__(self):
super(MNIST, self).__init__()
# 定义一层全连接层,输出维度是1
self.fc = paddle.nn.Linear(in_features=784, out_features=1)
# 定义网络结构的前向计算过程
def forward(self, inputs):
outputs = self.fc(inputs)
return outputs
然后这里说个细节就是我们这里的定义的前向传播的方法在下面模型训练的时候是不用去调用的,直接实例化对象就可以,然后框架会根据我们定义的方法自己去调用,但是前提是得声明是训练模式,然后反向传播就更简单了,因为优化器什么的直接调用api,所以我认为最难的其实是数据的处理,我刚才本来想去先下载数据集然后放到dataloader中,但是发现不好使,后来不得不在那个api中去直接放上数据,其实dataloader这个函数就是放入数据,然后它可以去将我们的数据分成batch,然后还可以去打乱我们的数据,其实就是数据的读入,然后的话就是数据处理,这里一定要归一化,我刚才没有归一化去试了一下,损失干到了6000多,加了归一化直接就2多了,归一化也很简单,就是让image/255就可以了。
训练
然后我们就简单的去实现一下模型训练的代码
在训练之前我们得把NHW变成一维的N*(H*W),并且这里要用到归一化,但是我们上面在加载数据的时候已经使用过了,所以代码如下:
def get_data(img):
assert len(img.shape) == 3
batch_size , h,w = img.shape[0],img.shape[1],img.shape[2]
img = img/255#归一化
img = paddle.reshape(img,[batch_size ,h*w])
return img
开始训练了,先实例化一个模型对象:
Mnist = Mnist()
然后训练把:
def train(model):
#开启训练模式,之后框架可以去调用各种函数
model.train()
#定义数据读取器
train_loader = paddle.io.DataLoader(paddle.vision.datasets.MNIST(model='train'),batch_size=16,shuffle=True)
#定义优化器,梯度下降
opt = paddle.optimizer.SGD(learning_rate=0.001,parameters=model.parameters())
#轮数10
EPOCH_NUM = 10
#炼丹了
for epoch in range(EPOCH_NUM):
for batch_id,data in enumerate(train_loader):
#数据
images = get_data(data[0]).astype('float')
labels = data[1].astype('float')
#前向传播,框架会自己调用forward函数
predicts = model(images)
#计算损失
loss = paddle.nn.functional.square_error_cost(predicts,labels)
avg_loss = paddle.model(loss)
#打印下结果
if batch_id %10000 == 0:
print("epoch_id={},batch_id:{},loss={}".format(epoch,batch_id,avg_loss))
#反向传播
avg_loss = model.backward()
opt.step()
opt.clear_grad()
#训练函数调用
train(MNIST)
#保存模型
paddle.save(MNIST.state_dict(),'./model.pdparams')
然后执行代码可以看到效果还可以:
但是这个只是训练了10轮并且网络结构太简单了,然后我们先总结一下:
先写网络结构,然后写一个预处理函数有归一化,然后实例化模型开始写训练函数,第一步去声明训练模式,然后的话去写数据读取器并且分好batch,然后定义优化器,在表面轮数,两个循环嵌套开始,读取数据,然后前向传播,计算损失,反向传播,最后保存模型
预测
预测的时候也是报错了,这个数据我是一直都没弄明白,好难受呀。预测的代码其实很简单,就是先声明eval模式,然后进行一次模式调用就可以了,这时框架就只会调用一会参数进行预测。我知道原因了,因为是用的框架调用嘛,所以我们不能随意的去更改函数的名字。下面来实现一下
from PIL import Image
import matplotlib as plt
def load_image(image_path):
#读取图片并且转化成灰度图
im = Image.open(image_path).covent("L")
#改变大小和纬度
im = im.resize((28,28),Image.ANTIALIAS)
im = np.array(im).reshape(1,-1).astype(np.float)
# 图像归一化,保持和数据集的数据范围一致
im = im / 255
return im
然后我们开始预测把
#实例化
model = MNIST()
#预测模式
model.eval()
#路径
params_file_path = 'mnist.pdparams'
img_path = '0.jpg'
#读取模型数据
param_dict=paddle.load(params_file_path)
model.load_dict(param_dict)
#加载数据
image = load_image(img_path)
result = model(paddle.to_tensor(image))
print('result',result)
# 预测输出取整,即为预测的数字,打印结果
print("本次预测的数字是", result.numpy().astype('int32'))

然后这里这篇文章就结束了,下篇文章会结合LeNet并且本地数据集的操作及自定义数据读取器等进行,我们下篇文章再见
以上是关于森说AI:从零开始应用paddlehub转换手写数字识别模型并完成部署:使用paddle2.xAPI简易实现手写数字识别模型的主要内容,如果未能解决你的问题,请参考以下文章