Kylin实战—— Kylin Cube构建算法
Posted 扫地增
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kylin实战—— Kylin Cube构建算法相关的知识,希望对你有一定的参考价值。
Cube物理模型:
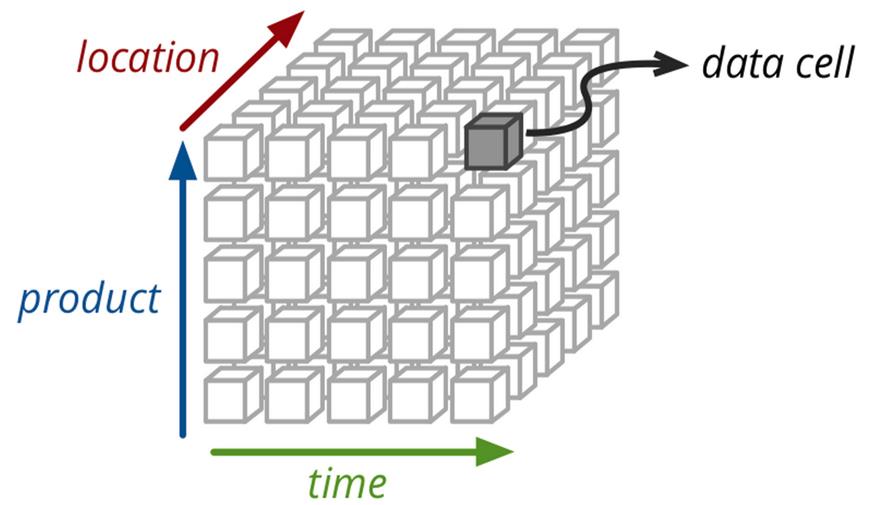
Kylin Cube构建算法主要分为两种一种是逐层构建算法,另一种是快速构建算法。
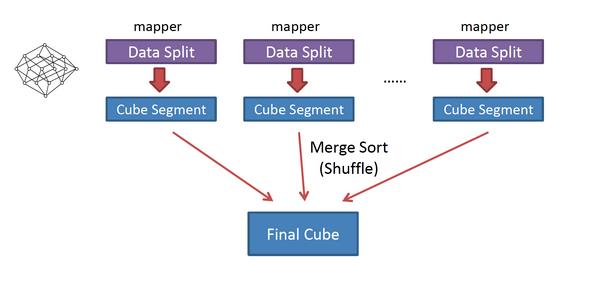
逐层构建算法:
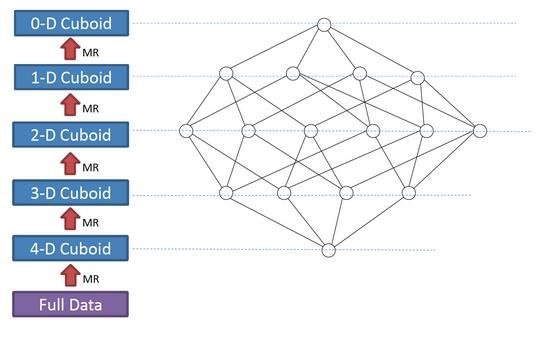
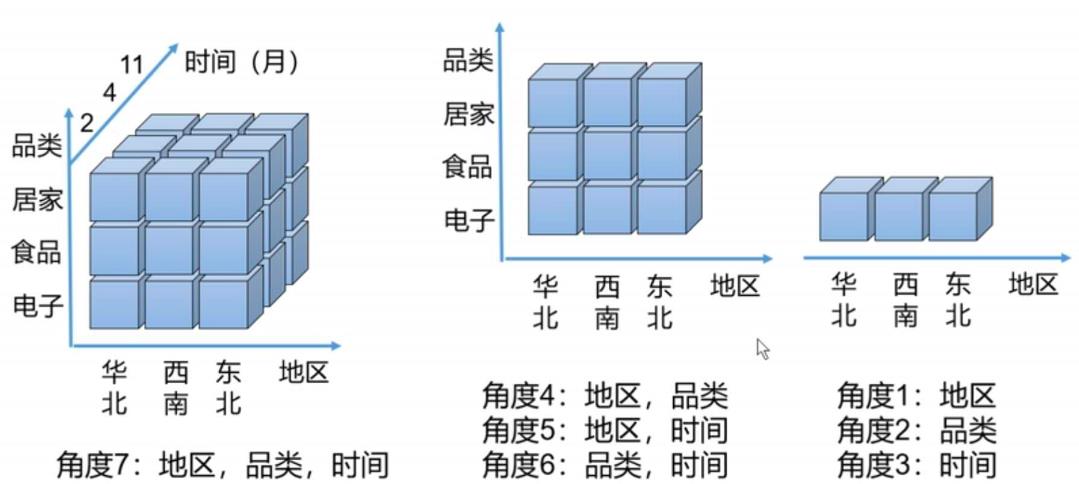
从模型理解
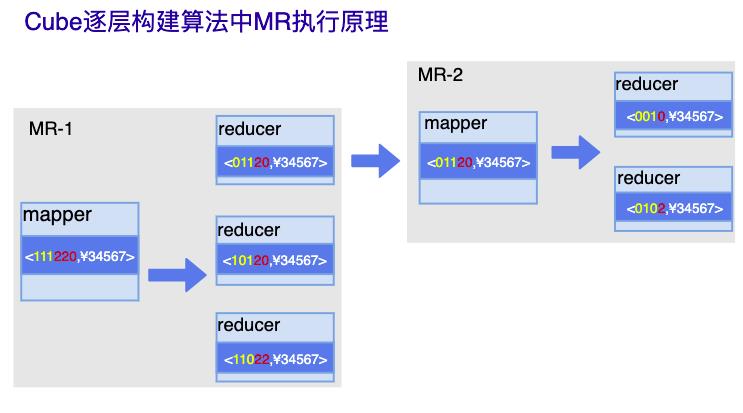
从MR任务来看:
优点
官网提供的算法的优点:
1)此算法充分利用了MapReduce的能力,处理了中间复杂的排序和洗牌工作,故而算法代码清晰简单,易于维护;
2)受益于Hadoop的日趋成熟,此算法对集群要求低,运行稳定;在内部维护Kylin的过程中,很少遇到在这几步出错的情况;即便是在Hadoop集群比较繁忙的时候,任务也能完成。
个人觉得这是hadoop的优点和它没多大关系
缺点:
(综合官网仅仅表达一下个人的看法)
1)算法在执行时每一层都需要一个
MR任务,我们知道MR任务的Shuffle是超慢的,假设有n个维度那么我们就会有n+1个MR任务,这么多的MR任务也使得预计算时间相当的长,我们可以想象Cube在复杂维度下,MR任务也会相应的增加,我们知道执行MR任务Hadoop在调度时肯定要消耗额外的资源,特别是在集群庞大的时候,如此反复的递交任务也会较为庞大的开销。
2)由于在逐层构建算法中在mapper逻辑中并没有聚合操作,都是放在Reduce中进行聚合操作,也就是没有在map端使用CombineFileInputFormat,这使得任务在shuffle过程的效率十分低下。
3)这种上一次的MR结果作为下次MR任务的数据。会对HDFS的读写操作过于频繁,造成了频繁的读写IO,大数据场景下这是很恐怖的,我们知道大数据的瓶颈就是磁盘IO,频繁的HDFS读写势必会产生磁盘读写IO
总的来说,就是在逐层构建算法中,MR任务过多,造成算法效率很低,特别是在Cube维度十分复杂的时候,简直就是灾难。
快速构建算法(inmemory):
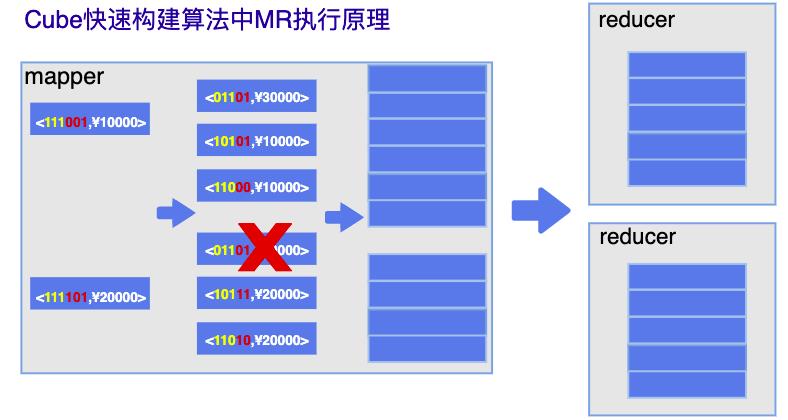
两种算法的不同点
1)在快速构建算法中
mapper端会利用内存做预聚合,算出所有Cuboid,每个Cuboid的key是不一样的,这样简单化了shffle过程。减少了在reduce端的工作量
2)只有一轮MR便会完成所有层次的计算,减少yarn任务的调度,节约了资源
3)利用内存不再频繁的读写磁盘,打破了磁盘IO禁锢。
选择与使用
那么我们在选择算法的时候选择哪一个呢?
- (一)、 如果我们了解集群,并且
- 集群配置好的话我们当然使用快速构建算法
inmem- 集群配置一般还是使用逐层构建算法,
layer
- (二)、如果对集群配置不了解,
kylin提供了自动选择算法的auto,这也是默认选项
官网是这样解说的:
预计算过程是Kylin从Hive中读取原始数据,按照我们选定的维度进行计算,并将结果集保存到Hbase中,默认的计算引擎为MapReduce,可以选择Spark作为计算引擎。一次build的结果,我们称为一个Segment。构建过程中会涉及多个Cuboid的创建,具体创建过程由kylin.Cube.algorithm参数决定,参数值可选auto,layer和inmem, 默认值为auto,即Kylin会通过采集数据动态地选择一个算法(layer or inmem),如果用户很了解 Kylin 和自身的数据、集群,可以直接设置喜欢的算法。
最后我们来演示一下, REST API演示和Kylin_JDBC演示代码
以上是关于Kylin实战—— Kylin Cube构建算法的主要内容,如果未能解决你的问题,请参考以下文章