Kylin实战—— Cube构建流程
Posted 扫地增
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kylin实战—— Cube构建流程相关的知识,希望对你有一定的参考价值。
文章目录
废话不多说我们直接上步骤:
第一步:创建中间宽表(Create Intermediate Flat Hive Table)
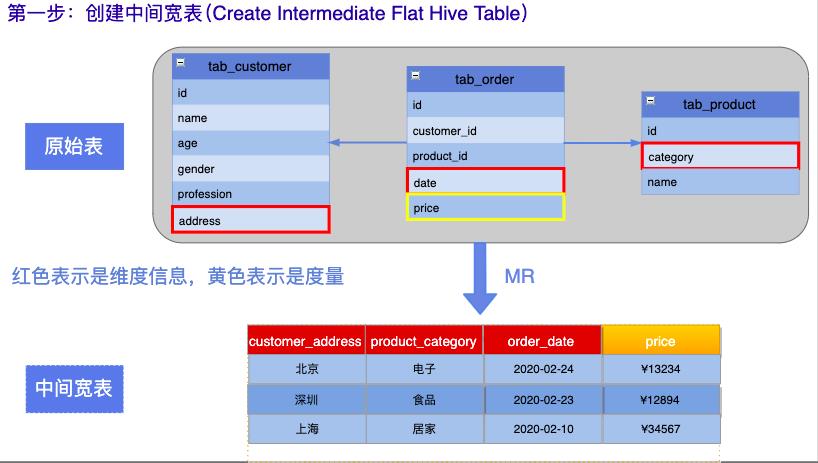
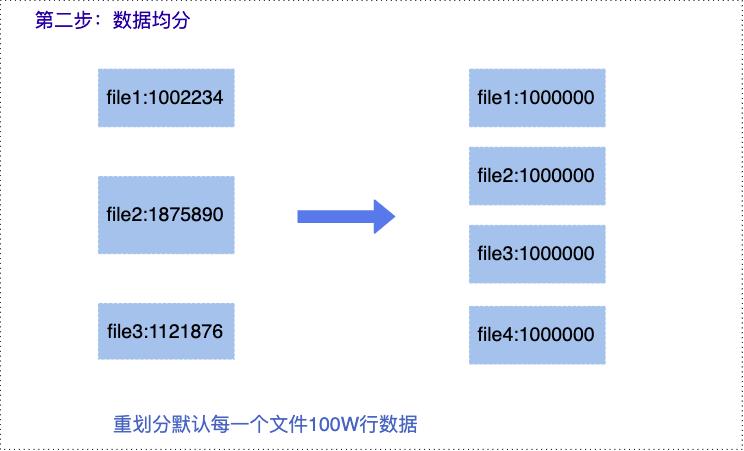
第二步:数据均分

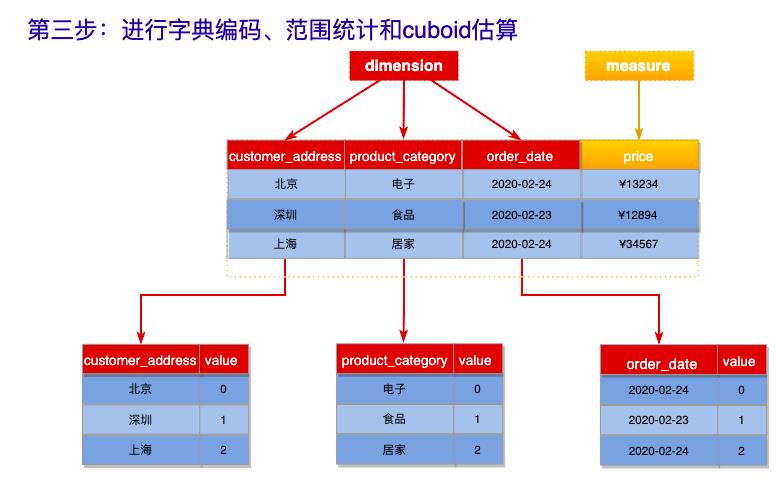
第三步:进行字典编码、范围统计和cuboid估算
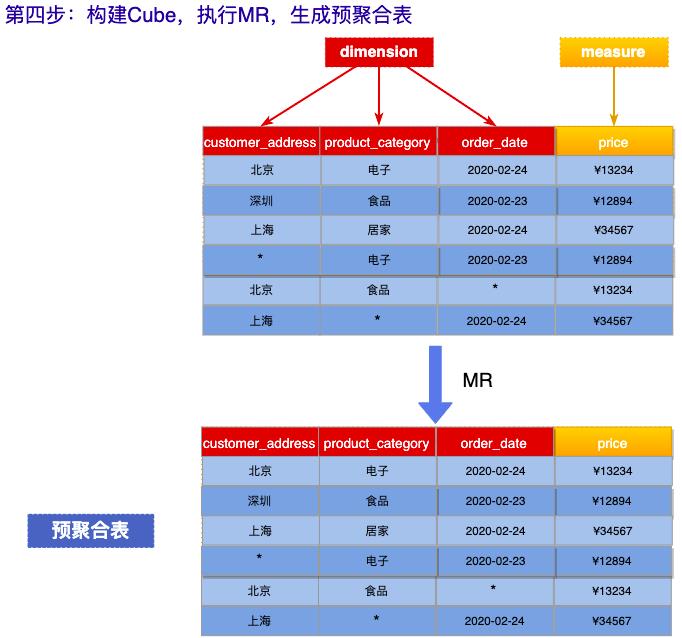
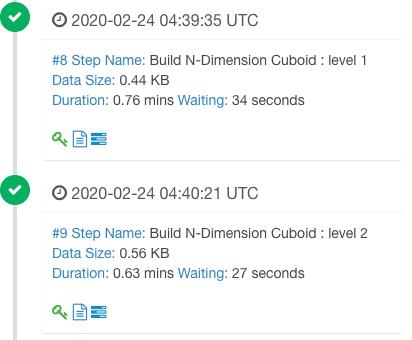
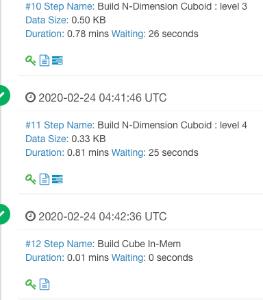
第四步:构建Cube,执行MR,生成预聚合表
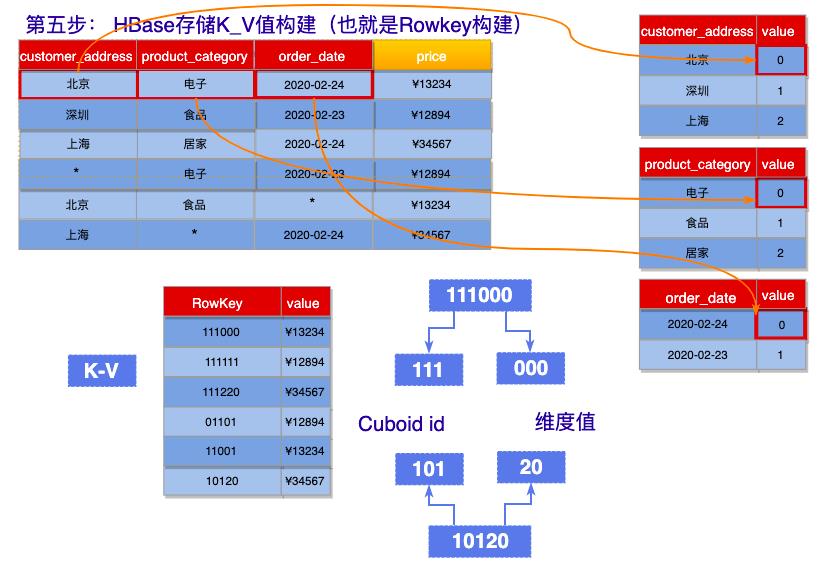
第五步: HBase存储K_V值构建(也就是Rowkey构建)
第六步:将Cube中的数据转换为HFile格式并存储到HBase中
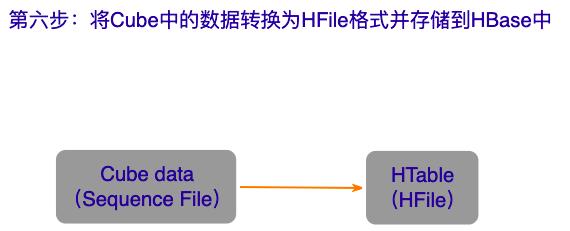
这一步会启动一个
MR任务用来将cuboid文件(顺序文件格式)转换为Hbase的HFile文件。Kylin通过cube的统计信息来计算HBase的region个数,默认每个region大小是5G。Region数越多,就会使用更多reducer。如果发现reducer的数目很少,并且性能很差,就可以“conf/kylin.properties”中增加如下配置项:
kylin.hbase.region.cut=2
kylin.hbase.hfile.size.gb=1
如果不能确定一个HBase的region该设置为多大,请联系HBase管理员。
后续步骤比较简单,大家有兴趣可以看一下官网。这里我们就不在一一赘述。
Kylin Cube构建优化以及增量构建Cube
以上是关于Kylin实战—— Cube构建流程的主要内容,如果未能解决你的问题,请参考以下文章