如何用12小时,搞定1个通用可扩展的日志监控?| 大厂实践
Posted 老张说架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用12小时,搞定1个通用可扩展的日志监控?| 大厂实践相关的知识,希望对你有一定的参考价值。
菜鸟级:没有日志。
入门级:有日志,只有用户反馈系统挂了,或者有bug的时候,才会登录到系统看看日志,大部分日志打印得随心所欲,缺乏组织性和系统性;
大虾级:有日志规范,系统性地组织和收集了日志;
画外音:你所在的团队处于哪一级呢?
日志,是系统重要的组成部分,对日志进行监控,可以先于用户发现系统的故障,实时告警
今天我们就聊聊:创业型公司怎样用半天的时间,搞定一个通用的、可扩展的日志监控框架

日志的监控,一般有这么几类需求:
(1)某种级别的日志(例如FATAL或ERROR级别的日志)一旦出现,或者出现次数超过一定频率,就告警;
(2)包含某些异常关键字(例如OutOfMemory等)的日志,一旦出现,或者出现次数超过一定频率,就告警;
(3)包含某些特殊含义的关键字(例如Login,Click等)的正常日志,一旦一定时间周期没有出现,就告警;
为了避免抖动引起误报,我们一般是到达一定频率才会告警。
日志规范
日志规范化是日志监控的前提,常用的日志规范有:
(1)日志分级规范:不同级别的日志打到不同的文件中。
(2)日志切分规范:日志按天或者小时切分,避免出现超大的日志文件,影响查询效率。
(3)日志格式规范:统一格式输出。
日志监控,主要有集中式监控和分散式监控两类思路。
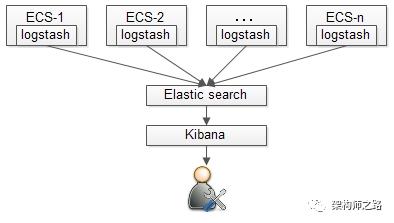
什么是集中式日志监控?
集中式的日志监控,最流行的莫过于ELK了:
(1)各个机器节点上部署logstash,收集日志;
(2)收集的日志汇总到ES;
(3)通过Kibana做统一分析和展现;
什么是分散式日志监控?
ELK有点重,三套系统搭建与运维起来比较麻烦。对于早期的创业型公司,可以采用分散式日志监控。
分散式监控并不统一收集日志,在各个机器上实施日志监控,如果触发监控策略,立刻发起告警

言归正传,如何半天搞定一个简单的,可扩展的日志监控框架呢?
框架设计大致分为三个部分:
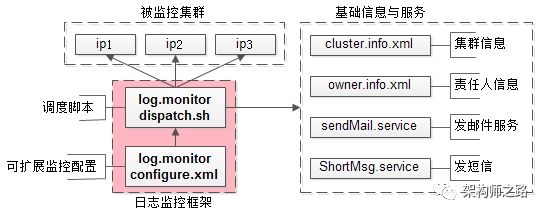
1、被监控集群
因为我们不统一收集日志,所有日志分散在各个机器中
2、基础信息与服务
我们把需要监控的集群信息和告警发送人信息,写在配置文件里。
集群信息配置文件:
[user_cluster]
ip.list : ip1, ip2, ip3
log.path: /xxx/xxx/log/user/
owner.list: 小白, 老张
[xxx_cluster]
.....
告警责任人配置文件
[小白]
email: xxx@xx.com
phone: 137*******
[老张]
.....
当需要告警时,我们调用基础的mail.service、SM.service发送通知。
3、日志监控框架
分为两部分:
(1)配置文件log.monitor.conf,保存需要监控的日志项。示例:
[log.monitor.item]
cluster.name : user_cluster
# error日志监控,每分钟超过此阈值告警
error.log. threshold : 10
# 异常关键字监控,出现这些关键字告警
exception.key : timeout | coredump
# 正常关键字,每分钟不出现这些关键字告警
good.key : login | click
[log.monitor.item]
cluster.name : xxx_cluster
.....
(2)核心监控程序
差不多200行代码就可以搞定了。伪代码:
遍历所有监控项 {
取出集群名,要监控的项目信息;
由集群名得到集群IP列表,负责人信息;
对于每一个IP实例 {
登录到这一台机器;
检查最近一分钟的日志;
若日志不正常 {
向负责人告警;
}
}
}

思路比结论重要!

完
如果你觉得这篇文章有价值
▼ 长按二维码关注【老张说架构】
分享接地气的架构之道
版权所有,转载请联系
以上是关于如何用12小时,搞定1个通用可扩展的日志监控?| 大厂实践的主要内容,如果未能解决你的问题,请参考以下文章