90行代码,搞定日志监控框架
Posted 架构师之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了90行代码,搞定日志监控框架相关的知识,希望对你有一定的参考价值。
上一篇《》介绍了通用+可扩展的http监控平台的架构:
监控平台层:调度监控项,通过后台管理监控项
信息管理层:通过服务和后台维护集群,告警接收人,告警策略等信息
告警发送层:通过接口发送邮件,短信,微信等消息
创业型公司,如果没有上述完善的基础设施,可以简化为一个通用+可扩展的http监控框架:
调度器:100行的伪代码,简述了调度器的原理
可扩展配置:通过配置文件来维护监控项、集群、告警人信息,同时保持扩展性
不少同学留言问,这个框架日志监控覆盖不了,RPC接口监控覆盖不了,xxoo监控覆盖不了。额,都说了是http监控了,其他类型的监控,听楼主娓娓道来。
今天,要聊的是日志监控。
一、什么是日志监控
关于日志,不同公司,情况不同:
A类公司:没有日志
B类公司:有日志,只有用户说系统挂了,或者有bug的时候,才会登录到系统看看日志,大部分日志打印得对心所欲,缺乏组织性和系统性
画外音:额,很多时候,追查bug发现日志信息不全,要先上线一个有日志的版本,以帮助定位bug,你遇到过么?
C类公司:有日志,有日志规范,系统性的组织和收集了日志
对日志进行监控,先于用户发现系统的故障,实时告警,就是今天要讨论的日志监控问题。
二、日志监控需求分析
对于日志的监控,一般有这么几类需求:
某种级别的日志(例如FATAL级别,或者ERROR级别的日志)一旦出现,或者超过一定频率,就告警
包含某些特殊含义关键字(例如OutOfMemory,或者Exception)的异常日志,一旦出现,或者超过一定频率,就告警
包含某些特殊含义关键字(例如Login,或者Click)的正常日志,一旦一定时间周期没有出现,就告警
其中,前两类需求,属于异常日志监控范畴,出现异常,实施告警。
第三类需求,属于正常日志监控范畴,一定的时间没有出现“正常”,就默认异常,实施告警。
为什么不是一出现异常日志就告警呢?
避免抖动引起的误报,一般到达一定频率才会告警,这属于告警策略的一部分。
画外音:关于人性化的告警策略,详见《》。
三、目录与日志的规范化
这是一个线上模块的目录示例:
有源代码:hello.c
有可执行文件:a.out
有配置文件:hello.conf
有备份日志:hello.log.2018012812
有日志:hello.log
有临时文件:tmp
体会一下,运维同学看到这样的线上文件部署,是什么感受?
画外音:没见过源代码直接部署到线上的?
三点一、目录规范
目录规范化不但对日志监控,对自动化运维都极为重要,要是线上目录都瞎搞,几乎没有办法实现自动化运维。
常见的目录规范有两类:模块优先类目录规范,功能优先类目录规范。
什么是模块优先的目录规范?
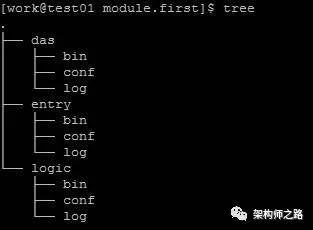
如上图,以模块名为优先组织目录:
根目录下,有das,entry,logic三个模块目录
在模块目录下,又分别有存放可执行文件,配置文件,日志文件的bin目录,conf目录,以及log目录
什么是功能优先的目录规范?
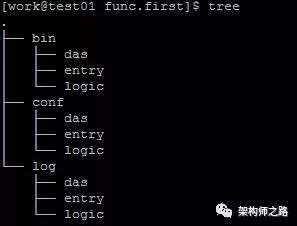
如上图,以功能为优先组织目录:
根目录下,二进制目录bin,配置文件目录conf,日志目录log
功能目录下,有das,entry,logic等不同模块的目录
楼主旗帜鲜明的推荐第二种,功能优先的目录规范,对二进制备份,配置备份,日志清理都非常方便。
三点二、日志规范
日志规范化不但对日志监控,对大数据体系建设都极为重要,需要考虑规范:
日志分级规范:不同级别的日志理应打到不同的文件中,例如FATAL级,ERROR级,WARM级,LOG级,INFO级,DEBUG级
fatal.log
error.log
info.log
debug.log
…
日志切分规范:运维应该提供自动化的日志切分工具,支持小时级别,或者天级别的日志切分,曾经看过一个120G的access日志,从日志中grep出某个uid的日志,是极其低效的
daojia.log.2018012800
daojia.log.2018012801
…
daojia.log.2018012823
日志格式规范:日志格式规范是一个可展开的话题,必要性很强,挖个坑下回细说
画外音:是不是有小伙伴在思考,ca,自己怎么没有这三类规范呢?
四、通用可扩展日志监控平台/框架思路
制订了目录规范,日志规范之后,要建立日志监控平台/框架,实施异常与正常的日志监控,就简单多了,主要有集中式监控,分散式监控两类思路。
四点一、集中式
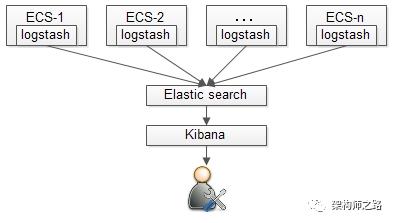
集中式的日志监控,最流行的莫过于ELK:
各个机器节点上部署logstash,收集日志
收集的日志汇总到ES
通过Kibana做统一分析和展现
运维的同学对这一套集中式日志监控系统非常熟悉。
四点二、分散式
ELK有点重,三套系统搭建与运维起来比较麻烦,如果只是为了实现ERROR日志的监控,异常关键字监控,正常关键字监控,有点杀鸡用牛刀了。
与集中式的日志监控相比,分散式的日志监控,就显得轻量级许多,非常适用与早期的创业型公司,其思路为:
通过日志监控后台,对不同集群,进行ERROR日志阈值设置,进行异常关键字设置,正常关键字设置
日志监控中心,进行统一调度,将配置分发到不同机器的agent节点上
agent节点,并不统一收集日志,而是接收到监控中心分发的log监控配置,在各个机器上实施日志监控,如果触发日志监控策略,立刻发起告警
与ELK相比,这个日志平台会简单的多,而且扩展性非常好。
额,创业型公司没有时间和人员研发agent,没有资源研发日志监控中心服务,没有人力研发日志监控后台,还有没有更简洁但可扩展的方案呢?
和《》的思路一样,没有服务,没有后台,没有agent,初期完全可以用配置文件来替代。
五、100行搞定日志监控平台
整个框架设计如上,大致分为三个部分:
被监控集群
基础信息与服务
cluster.info.xml:存储集群信息
owner.info.xml:存储集群责任人信息
mail.service/SM.service:发邮件,发短信的基础服务
日志监控框架
集群信息与负责人信息,与前文描述的一样。
集群配置cluster.info.conf
[daojia_main]
ip.list : ip1, ip2, ip3
log.path : /home/work/log/daojia_main/
owner.list : shenjian, zhangsan
[daojia_user]
ip.list : ip4, ip5, ip6
log.path : /home/work/log/daojia_user/
owner.list : shenjian
责任人配置owner.info.conf
[shenjian]
email : XX@XX.com
phone :15912345678
[zhangsan]
email : YY@YY.com
phone :18611220099
日志监控框架又分为两个模块:
可扩展监控配置文件log.monitor.conf
[log.monitor.item]
cluster.name : daojia_main
# error日志监控,每分钟超过此阈值就告警
error.log. threshold : 10
# 异常关键字监控,日志出现这些关键字就告警
bad.key : exeption | timeout | coredump
# 正常关键字监控,日志每分钟不出现这些关键字就告警
good.key : login | user | click
[log.monitor.item]
cluster.name : daojia_user
error.log.threshold : 10
日志监控调度框架,这里需要编码啦,100行的伪代码如下:
Array[log-monitor] A1= Parse(log.monitor.config);
Array[cluster-info] A2= Parse(cluster.info.config);
Array[owner-info] A3= Parse(owner.info.config);
// 遍历所有监控项
for(each item in A1){
//取出监控项的集群名,阈值,异常/正常关键词
clusterName= item.clusterName;
threshold= item.threshold;
badKey= item.badkey;
goodKey= item.goodkey;
//由集群名,获取集群信息
clusterInfo= A2[clusterName];
//获取日志目录,集群ip列表,集群负责人列表
logPath= clusterInfo.path;
List<String>ips = clusterInfo.ip;
List<String>owners = clusterinfo.owner;
//集群内的每一个ip实例,都需要日志监控
for(eachip in ips){
//登录到这一台机器
ssh $ip
//跳到相关的目录下
cd $logPath
//查看近一分钟error日志数量
$count= `grep $time error.log | wc -l`
//查看badkey与goodkey
$boolBad= `grep $badkey *`
$boolGood= `grep $goodkey *`
if($count< threshold &&
$boolBad==NO &&
$boolGood==YES){
//正常,继续监控
continue;
}
// 否则,对所有集群负责人发送告警
for(each owner in owners){
// 略…
}
}
}
就是一个简单的调度框架,看明白了吗?
六、调研
调研一、对于日志,你的感触是
ca,啥是日志,什么是grep
日志不全,查问题的时候需要加日志再发布系统
日志全,但查问题的时候才上去grep一把
日志成体系,日志有监控,有后台不需要grep
调研二、对于日志切分,你的感触是
ca,啥是日志切分,就一个access.log呀
额,研发自己切分,没有规范
不同团队切分规范不同
运维提供工具统一规范切分
调研三、对于日志监控,你的感触是
ca,啥是日志监控,没有哇
ELK,集中式
日志监控平台,分散式
日志监控框架,分散式
调研四:你见过120G的日志文件么?
嗯,有点道理,得转发一下。
以上是关于90行代码,搞定日志监控框架的主要内容,如果未能解决你的问题,请参考以下文章