【网络爬虫教学】虫师终极武器之Chromium定制开发系列(六)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了【网络爬虫教学】虫师终极武器之Chromium定制开发系列(六)相关的知识,希望对你有一定的参考价值。
参考技术A Hi,大家好,欢迎大家观看由IT猫之家打造的【网络爬虫教学】虫师终极武器之Chromium定制开发系列教学文章的第六篇,如果您是第一次观看本系列教程,请先移步到 这里 看完前面的文章后再回来哦!大家在学习的过程中,有任何疑问可以留言或加入我们的QQ技术交流群进行探讨: 544185435前言
前面我们已经实现了多个FP重点检测对象的接口随机化,事实上只要完成这些接口的重写就足以应付大多网站了,不过我们既然要定制就做足全套吧,在FP检测脚本中,尚且还有一些也算是较为重要的判断依据,如:系统字体检测、浏览器插件(plugins) 检测、以及非人为触发事件检测isTrusted等。
FontStyle 随机化的实现
由于每台设备的字体可能存在差异等原因使得第三方服务可以轻松的通过获取字体来判断请求的客户端是否为同一客户端,我们知道Chromium为了规避安全的风险,不对JS提供太多的可用权限,比如字体读取,JS本不具备这种检测权限,但FP巧妙的利用了字体的(长、宽、描边)等属性来精确的判断出客户端是否包含了哪些字体,最终导出一串哈希值以便于作为有力的凭证,另除了这种方式,FP还通过Flash接口来调用字体进行判断(需浏览器支持)
对于系统字体接口的随机,我们可以从传入的font-Style着手,在之前的Canvas随机方案中,我们有做过类似的操作,就直接篡改传入的Style,而对于字体我们也是可以这么干的,只需将其替换成指定的字体即可。
要想实现该接口的随机化,我们首先得要搞懂网站对这个接口的检测是如何实现的以及它是如何运作的,而最好最直接的方法就是直接从目标网站分析并找到答案,我们可以打开 browserleaks 然后在关键处下断点,从上图我们可以看到它预设了一堆的常见字体。
从上图,我们可以看到一串:mmm₹▁₺ꜽ�₸׆ẞॿmmmmmmmlli 这样的字符,在我接触过的脚本中它们都会以这种形式作为检测的基准,至于为何一定要用这给字符串,大家可以参考下这篇文章,这位大佬已经解释得很清楚: javascript/CSS Font Detector | JavaScript / CSS 字体检测器
从图中我们可以看出,它每次循环都会通过接口style.fontFamily来为当前标签设置字体并获取其宽度与高度,进而与原始的字体进行一一比对,一旦不相等则表示该字体存在,通过该方法几乎可以100%的测得准确结果,而我们要想实现该接口的随机化,可以考虑从两个点着手,首先,就像前面说的,接口每次都会通过 style.fontFamily 来设置字体,那么我们完全可以在这里进行篡改,只要保证每次传入的字体都不一致,则表示肯定会与结果有出入从而达到了随机化的目的,其二,既然它是通过字体的宽度与高度来判断是否成立的,那么我们也可以hook该接口返回随机偏移的数值,从而达到随机化的目的。
通过API查询,我们可以很方便的找到该接口的路径,我们只需按自己的需求实现随机化即可,在这,我建议大家直接修改它的头文件,因为我尝试修改cc文件并未成功,当然大家也可以自行尝试,万一是我操作姿势不对呢,啊哈哈….
plugins 接口随机化的实现
事实上,单单依赖这个插件指纹,服务端是无法判断出是否同一客户端的,也就是说只要完成前面的所有指纹伪造,基本上可以瞒天过海了,但为了满足部分强迫症的看官,我还是有必要将这个给拉出来讲解了。
我们直接在控制台中输入:navigator.plugins,来看看这个插件到底包含了什么
我们可以看到,基本上 navigator.plugins 的子项包含了:四个字段以及2个对象(事实上是一个对象),而事实上我们浏览器里的这个对象基本上都是一样的,所以我开头说可以忽略掉这个接口,我们可以查看每个子项,可以发现它的字段是一样的,同样包含了: name、 filename 、 description 、 MimeType ;那么这样就好办了,直接从以上的字段着手即可。
通过API查询,我们定位到这个 navigator.plugins 的接口位于:third_party\blink\renderer\modules\plugins目录下,我们只需对其实现随机化即可。
上图是插件随机化后的效果,经过篡改:String DOMPlugin::name()、String DOMPlugin::filename()、String DOMPlugin::description()我们可以很轻松的便实现了该接口的随机化。
接口事件触发之底层篡改大法
在FP脚本检测的过程中,还有一项作为检测最为重要的评判指标 “isTrusted”,之所以将它留到最后讲,是为了体现它的价值与其重要性,该字段通常会出现在事件被触发的时,它也是唯一的一个不可直接通过JS语法进行篡改的字段,也就是说前面介绍的所有接口其实我们都是可以通过JS去篡改的,(篡改是没问题,但不见得一定能用,因为部分网站是有针对这个进行检测的),而这个 “isTrusted ”则是例外。
我们来看看上图,我们随便定义了一个鼠标事件以及坐标的事件,然后我们可以发现,它们都携带了一个“ isTrusted ”的字段,并且它的值为false,通过上图我们可以发现,这个接口并不能重写,因为它是只读的,覆盖不了,而我也有尝试过在茫茫网海中寻找可通过JS改写的方案,最终都以失败告终,当然,也有老外告诉我,它们可以通过配合扩展插件去实现,但必须得借助debugger来实现,并且无法取消弹窗,而这方法我也尝试过,是成功了,但是及其耗资源,所以我才打算将其以基于底层的方式实现。
我们再来看看真实触发事件的情况,我们从上图中可以看出,当我们以真实鼠标去触发它, “ isTrusted ” 是为真的,而部分网站以该字段作为判断的依旧,从而判断你是否为机器人;事实上这个接口并不属于是否同一客户端的判断范畴,而是为了校验客户端是否人为发起的请求。
Event 接口的isTrusted是一个 Boolean 类型的只读属性.当事件由用户操作生成时为true,由脚本创建或修改,或通过调用 EventTarget.dispatchEvent 生成,为false;从这里我们可以看到通过脚本创建或者修改的都会返回false,从而我们可以更加肯定这个字段是肯定会被网站作为重要的判断依旧的。
通过API我们顺藤摸瓜的找到了接口的路径,并将其篡改为true,而,因为所有的事件(如:MouseEvent、PointEvent) 都是派生与event ,所以一旦在其根源修改了,所有的事件都势必会返回真,从而达到我们想要的目的。
最后,附上一张篡改后的效果图,以表示成功。
作者寄语
感谢大家一直阅读本系列文章,到本文为止,我们已经实现了FP里的大部分检测,而通过这些属性的伪造,我们已经可以在大部分网站上执行了,而由于接口都是随机的,所以网站无法确认是否为同一客户端,从而达到了真正的匿名效果;但部分网站还是采用的Cookie形式来记录的,所以,我们也可以通过隐身模式或者通过第三方扩展来屏蔽。另外,请大家不要再私下问我怎么不完全把接口暴露出来,之类的话,首先,一旦方法暴露,势必会遭到第三方网站进行特征收集,没有什么是绝对的,收集过多的数据,照样可以判断你是机器人,或者直接屏蔽你的浏览器,其二,研究是需要时间与精力的,如果大家都是抱着做伸手党的心思来讨要结果,那么您可能找错方向了,天天研究头发都白了,你伸下手就想要,有这么好的事欢迎留言告诉我,我也想要;最后如果大家有业务需求可以找我合作,JS逆向或浏览器定制均可。
爬虫实战:爬虫之 web 自动化终极杀手 ( 上)
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~
作者:陈象
导语:
最近写了好几个简单的爬虫,踩了好几个深坑,在这里总结一下,给大家在编写爬虫时候能给点思路。本次爬虫内容有:静态页面的爬取。动态页面的爬取。web自动化终极爬虫。
分析:
数据获取(主要靠爬虫)
- 静态网页爬取
- 动态网页爬取
数据存储(python excel存储)
- Python Excel操作,保存结果
数据获取实战:
百度音乐(静态网页)
分析步骤
1 . 打开百度音乐:http://music.baidu.com/
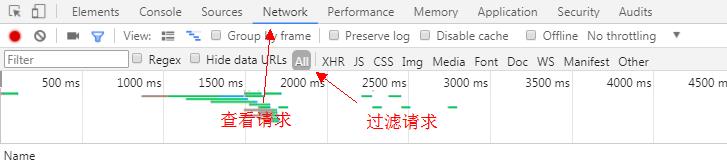
2 . 打开浏览器调试模式F12,选择Network+all模式

3 . 搜索框搜索歌曲(beat it),查看控制台

- 过滤请求:ctrl + f 输入搜索关键字
- 依照请求接口的特点,查看主请求
- 分析请求(reques headers、Query string、response)
4 .通过以上分析:获取到有效信息:
- 歌曲搜索请求接口为http://music.baidu.com/search?key=歌曲名
- 获取请求方式(post、get)百度音乐搜索歌曲为get请求
- 请求headers(伪装浏览器,避免被拒绝请求)
- 请求返回结果(html or json)百度音乐的返回结果为html。
5 .通过有效信息来设计爬虫,获取数据
- 伪装浏览器。需要导入requests库,比起urllib、urllib2等库更加方便,这里不做赘述。要点是添加请求头(User-Agent、Host等)
- 发起get请求
- 等待请求返回
- 处理返回数据。因为百度音乐才用的是html作为返回数据。因此要祭出我们的BeautifulSoup(SoupBeautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间。这可是爬虫的福音,终于不用再写那么复杂的正则表达式了—-引用,详细教程可访问SoupBeautiful Soup 教程进行学习,本次使用的方法不多,会在后边介绍。)
- 将解析到的有用数据进行保存。
代码实现
1 .View 提供准对参数url进行访问并返回结果的方法
def view(url): \'\'\' :param url: 待爬取的url链接 :return: \'\'\' # 从url中获取host protocol, s1 = urllib.splittype(url) host, s2 = urllib.splithost(s1) # 伪装浏览器,避免被kill headers = { \'Host\': host, \'User-Agent\': \'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.78 Safari/537.36\', \'Accept\': \'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\', \'Accept-Encoding\': \'gzip, deflate\', \'Accept-Language\': \'zh-CN,zh;q=0.8\', } # 代理 proxies = { "http": "dev-proxy.oa.com:8080", "https": "dev-proxy.oa.com:8080", } # 利用requests封装的get方法请求url,并添加请求头和代理,获取并返回请求结果。并进行异常处理 try: res = requests.get(url, headers=headers, proxies=proxies) res.encoding = \'utf-8\' if res.status_code == 200: # 请求成功 # 获取网页内容,并返回 content = res.text return content else: return None except requests.RequestException as e: # 异常处理 print(e) return None
2 .search_baidu_song 提供对参数song_name进行歌曲搜索并获取搜索结果
def search_baidu_song(song_name): \'\'\' 获取百度音乐搜索歌曲结果 :param song_name: 待搜索歌曲名 :return: 搜索结果 \'\'\' def analyse(): \'\'\' 静态网页分析,利用BeautifulSoup,轻松获取想要的数据。需要对html有了解。 :return: \'\'\' # 初始化BeautifulSoup对象,并指定解析器为 lxml。还有其他的解析器:html.parser、html5lib等 # 详细教程可访问:http://cuiqingcai.com/1319.html《Python爬虫利器二之Beautiful Soup的用法》 html = BeautifulSoup(content, "lxml") # beautifulsoupzui常用方法之一: find_all( name , attrs , recursive , text , **kwargs ) # find_all() 方法搜索当前tag的所有tag子节点, 并判断是否符合过滤器的条件 # tag标签名为\'div\'的并且标签类名为class_参数(可为 str、 list、 tuple), search_result_divs = html.find_all(\'div\', class_=[\'song-item clearfix \', \'song-item clearfix yyr-song\']) for div in search_result_divs: # find() 方法搜索当前tag的所有tag子节点, 并返回符合过滤器的条件的第一个结点对象 song_name_str = div.find(\'span\', class_=\'song-title\') singer = div.find(\'span\', class_=\'singer\') album = div.find(\'span\', class_=\'album-title\') # 此部分需要对html页面进行分析,一层层剥开有用数据并提取出来 if song_name_str: # 获取结点对象内容,并清洗 song_name_str = song_name.text.strip() else: song_name_str = \'\' if singer: singer = singer.text.strip() else: singer = \'\' if album: album = album.find(\'a\') if album: # 获取标签属性值 # 方法二:属性值 = album[\'属性名\'] album = album.attrs.get(\'title\') if album and album != \'\': album = album.strip() else: album = \'\' else: album = \'\' # print song_name + " | " + singer + " | " + album songInfoList.append(SongInfo(song_name_str, singer, album)) songInfoList = [] url = urls.get(\'baidu_song\') url1 = url.format(song_name=song_name, start_idx=0) content = self.view(url1) if not content: return [] analyse(content) url2 = url.format(song_name=song_name, start_idx=20) content = self.view(url2) analyse(content) return songInfoList[0:30]
就这样我们获取到了百度网页歌曲搜索结果的数据。然后就是保存数据,这个我们最后再谈谈。
网易云音乐 (动态网页)
在我们以上一种静态网页获取数据方式来获取网易云音乐的数据的时候,可能会遇到这样的问题:网页查看源代码并没有可用的数据,仅仅只有网页的骨架。数据完全找不到,可是打开开发者工具查看DOM树却能找到想要的数据,这时候我们是遇到了动态网页,数据是在动态加载进去的。无法获取网页数据。
目前解决方案有两种:
- 通过查看访问动态数据接口来获取数据。
- 通过web自动化工具来获取网页源代码以获取数据。
(目前网易云简单通过访问url已经不能获取到数据了,我们可以采用web自动化工具selenium和PhantomJS来实现网页源代码的获取)
方案一实现(通过查看访问动态数据接口来获取数据):
- 打开网易云音乐:http://music.163.com/
- 打开浏览器调试模式F12,选择Network+all模式
- 搜索框搜索歌曲(beat it),查看控制台

过滤请求为XHR,发现请求name怎么都一样,这时候我们翻看这些name,查看到Request URL里找到关键字search的请求,这个请求是一个POST请求。这个应该就是获取搜索数据的接口,通过查看response或者preview来查看请求返回结果。正是我们想要的。
我们先不要高兴的太早了,目前我们还没有搞清楚Form Data是怎么构成的。params + encSecKey到底是怎么生成的。在看过网络上有关抓取网易评论的爬虫《如何爬网易云音乐的评论数?》,得知这个网易针对api做了加密处理。由于个人道行太浅参悟不透这里的加密参数顺序和内容。因此这个方案就此作罢。实在不甘心,只好换方案二。
方案二实现:
既然方案一暂时走不通,也不能影响我们的工作进度,换个思路继续走,想到使用web自动化测试工具selenium可以实现模拟人工操纵浏览器。这样导出网页数据应该不是问题,想到立马动手。
环境配置
- 安装selenium
推荐使用python包管理工具自动: pip install -y selenium
其他方式可参考:selenium + python自动化测试环境搭建
2 .安装PhantomJS
PhantomJS是一个基于webkit的JavaScript API。它使用QtWebKit作为它核心浏览器的功能,使用webkit来编译解释执行JavaScript代码。任何你可以在基于webkit浏览器做的事情,它都能做到。它不仅是个隐形的浏览器,提供了诸如CSS选择器、支持Web标准、DOM操作、JSON、HTML5、Canvas、SVG等,同时也提供了处理文件I/O的操作,从而使你可以向操作系统读写文件等。PhantomJS的用处可谓非常广泛,诸如网络监测、网页截屏、无需浏览器的 Web 测试、页面访问自动化等。
目前官方支持三种操作系统,包括windows\\Mac OS\\Linux这三大主流的环境。你可以根据你的运行环境选择要下载的包
1.安装PhantomJS
下载完成后解压文件,可将phantomjs.exe放在pythond的目录下(C:\\Python27\\phantomjs.exe)。这样后续加载不需要指定目录。也可以放在特定目录,使用的时候指定phantomjs.exe路径即可。双击打开phantomjs.exe验证安装是否成功。如果出现下图,即安装成功了。

2.代码步骤实现:
- 初始化浏览器获取网页数据
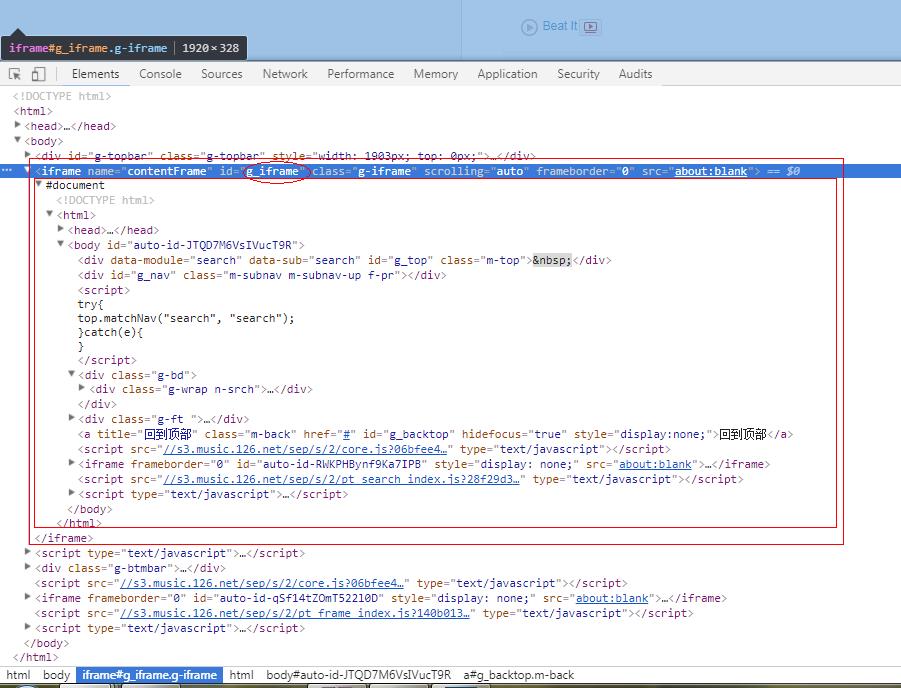
def dynamic_view(url): \'\'\' 使用自动化工具获取网页数据 :param url: 待获取网页url :return: 页面数据 \'\'\' # 初始化浏览器driver driver = webdriver.PhantomJS() # 浏览器driver访问url driver.get(url) # 坑:不同frame间的转换(网易云在数据展示中会将数据动态添加到\'g_iframe\'这个框架中,如果不切换,会报"元素不存在"错误。) driver.switch_to.frame("g_iframe") # 隐式等待5秒,可以自己调节 driver.implicitly_wait(5) # 设置10秒页面超时返回,类似于requests.get()的timeout选项,driver.get()没有timeout选项 driver.set_page_load_timeout(10) # 获取网页资源(获取到的是网页所有数据) html = driver.page_source # 坑:退出浏览器driver,必须手动退出driver。 driver.quit() # 返回网页资源 return html
- 解析网页获取数据,同百度音乐(省略)
def search_163_song(song_name):
pass
同样是通过BeautifulSoup对网页资源进行对象化,在通过对对象的筛选获取得到数据。没想到网易云音乐的数据也能这样拿到。能做到这里已经可以对付大部分网站了。
选用PhantomJS看中其不需要可视化页面,在内存占用上比较省。可是也是出现问题,各位看官请继续往下看。眼看着就要完成了。
3. spotify
- 使用搜索功能,需要登录账户(比较不好申请,申请好几次都没有成功)
- 登录成功后,天不遂愿啊,打开spotify搜索页面,竟然没办法查看网页原代码。单独通过请求搜索url: https://open.spotify.com/search/recent 也没办发获取网页数据,会报出权限问题。后边依次解决。
解决方案:
- 通过使用web自动化获取数据。
- 通过请求动态数据接口来获取数据
方案实施:
方案1:
采用web自动化工具获取数据:配置如同网易云配置,模仿用户操作浏览器进行网页打开,用户登录,进入搜索页面,获取页面数据
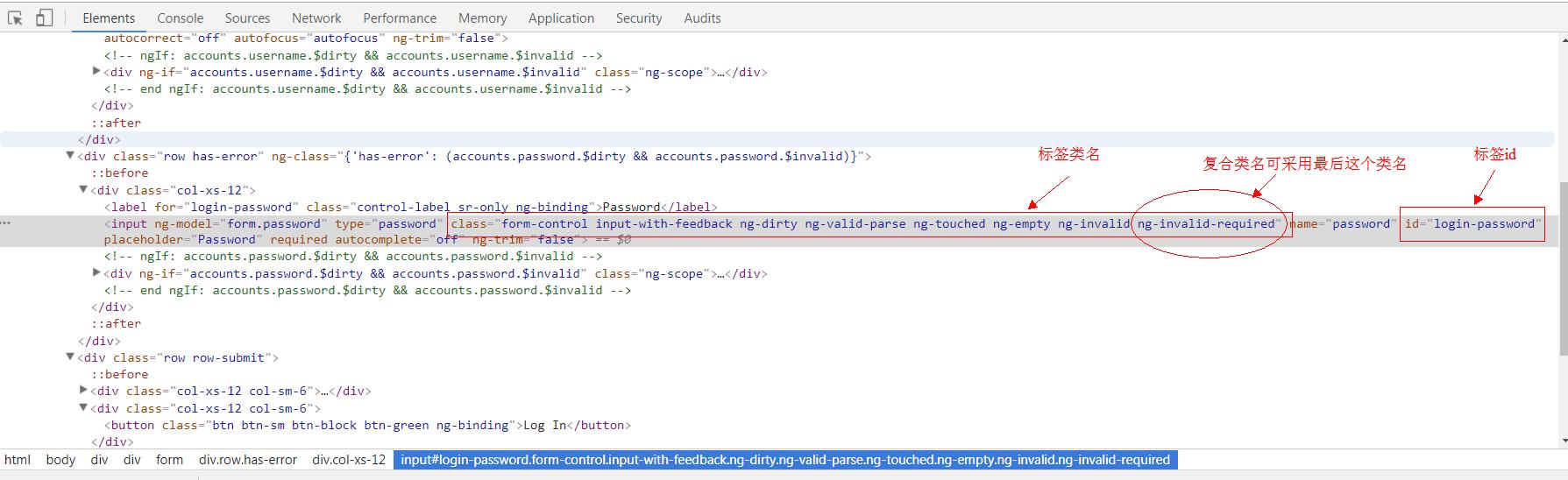
def spotify_view(url): \'\'\' 使用自动化工具获取网页数据 :param url: 待获取网页url :return: 页面数据 \'\'\' spotify_name = \'manaxiaomeimei\' spotify_pass = \'dajiagongyong\' spotify_login = \'https://accounts.spotify.com/en/login\' # 初始化浏览器driver driver = webdriver.PhantomJS() # 模拟用户登录() # 浏览器driver访问登录url driver.get(spotify_login) # 休息一下等待网页加载。(还有另一种方式:driver.implicitly_wait(3)) time.sleep(3) # 获取页面元素对象方法(本次使用如下): # find_element_by_id : 通过标签id获取元素对象 可在页面中获取到唯一一个元素,因为在html规范中。一个DOM树中标签id不能重复 # find_element_by_class_name : 通过标签类名获取元素对象,可能会重复(有坑) # find_element_by_xpath : 通过标签xpath获取元素对象,类同id,可获取唯一一个元素。 # 获取页面元素对象--用户名 username = driver.find_element_by_id(\'login-username\') # username.clear() # 坑:获取页面元素对象--密码 # 在通过类名获取标签元素中,遇到了无法定位复合样式,这时候可采用仅选取最后一个使用的样式作为参数,即可(稳定性不好不建议使用。尽量使用by_id) # password = driver.find_element_by_class_name(\'form-control input-with-feedback ng-dirty ng-valid-parse ng-touched ng-empty ng-invalid ng-invalid-required\') password = driver.find_element_by_class_name(\'ng-invalid-required\') # password.clear() # 获取页面元素对象--登录按钮 login_button = driver.find_element_by_xpath(\'/html/body/div[2]/div/form/div[3]/div[2]/button\') # 通过WebDriver API调用模拟键盘的输入用户名 username.send_keys(spotify_name) # 通过WebDriver API调用模拟键盘的输入密码 password.send_keys(spotify_pass) # 通过WebDriver API调用模拟鼠标的点击操作,进行登录 login_button.click() # 休息一下等待网页加载 driver.implicitly_wait(3) # 搜索打开歌曲url driver.get(url) time.sleep(5) # 搜索获取网页代码 html = driver.page_source return html
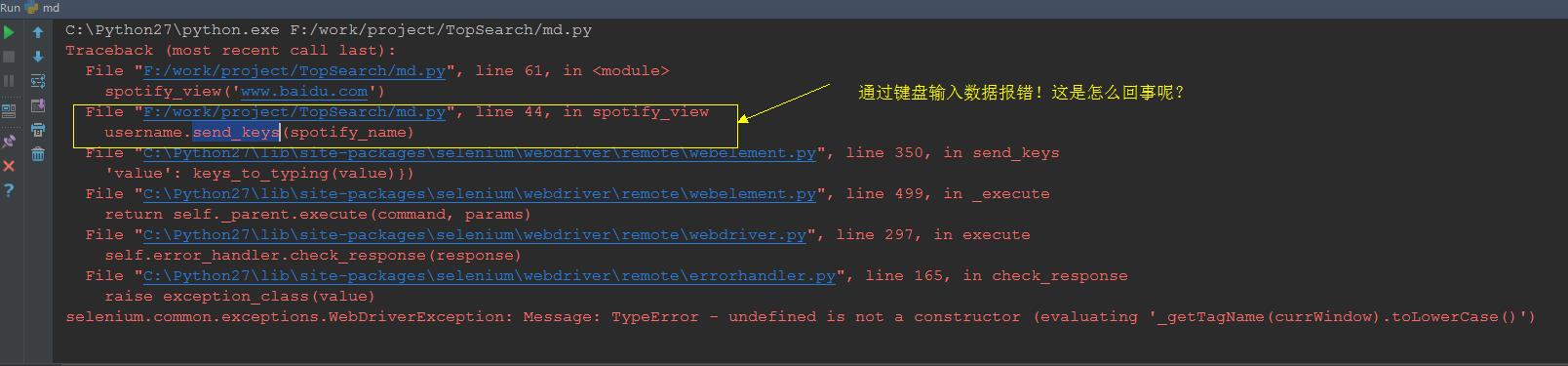
点击运行之后,一切都风平浪静。突然代码报错了(如下图)。查完资料也做了代码的修改。
网络提供方案
- 添加对待输入元素的clear(),清除原有的字符。
- 更换浏览器
方案实施:
方案1:
在获取了对象之后添加对该对象的清除方法(username.clear()、password.clear())
实施结果
方案1失败。原因不明了,多半是webdriver对PhantomJS兼容性不好。
方案2:
更换浏览器,本次选择使用chrome浏览器进行自动化操作。
安装chrome自动化控制插件。
- 下载ChromeDriver插件。
- 将WebDriver复制到python的安装目录
- 双击验证安装
- 修改代码:
-
# 初始化浏览器driver driver = webdriver.Chrome() - 再次执行代码
- 实施结果
成功打开可视化chrome页面并登录成功。
本以为这样就可以获取到数据了。燃鹅,还是没有获取到,又报错了(如下图)
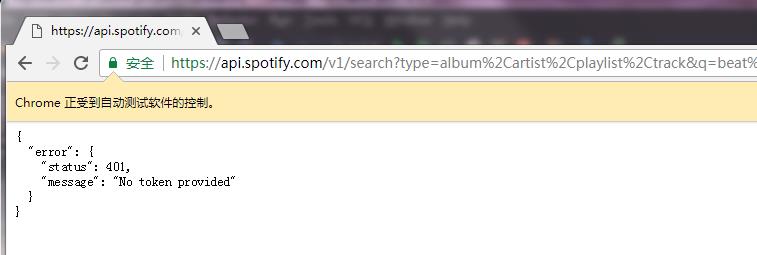
到这里:就应该查看请求了,找到token是什么。并尝试添加token到请求头中。
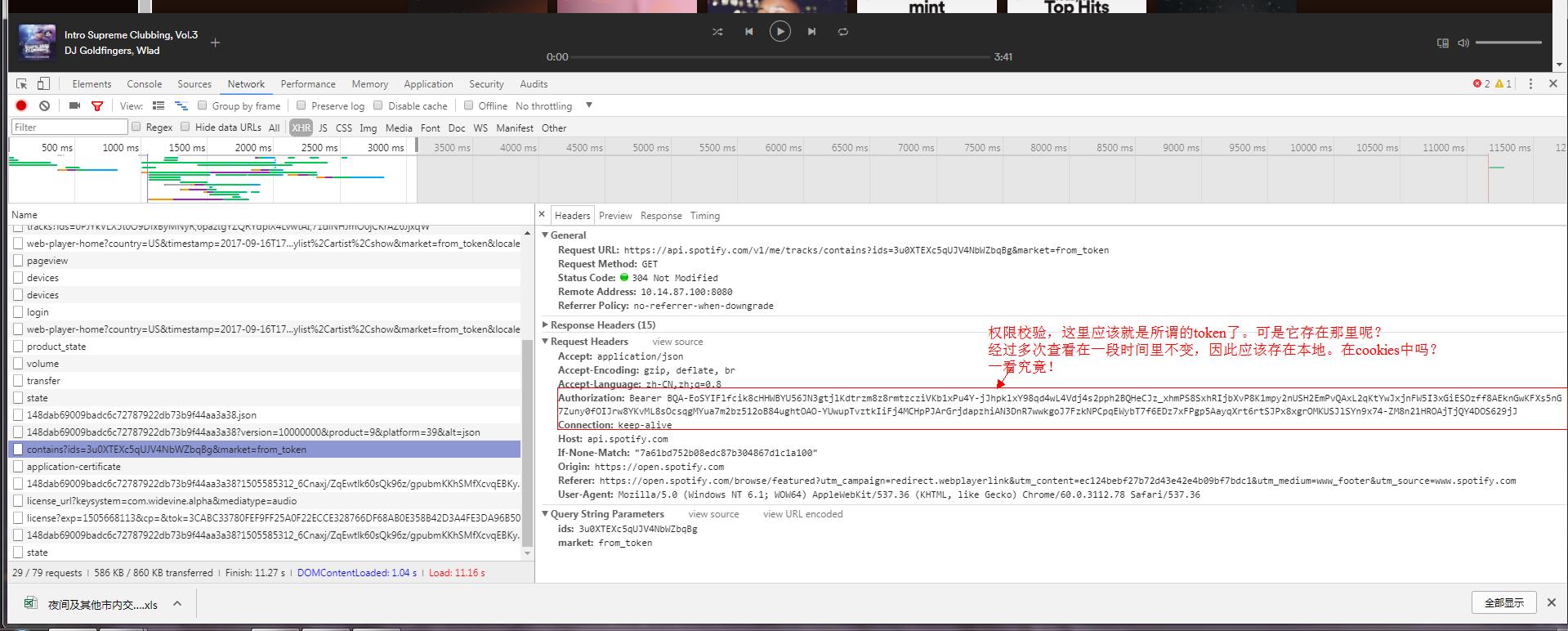
查看cookies
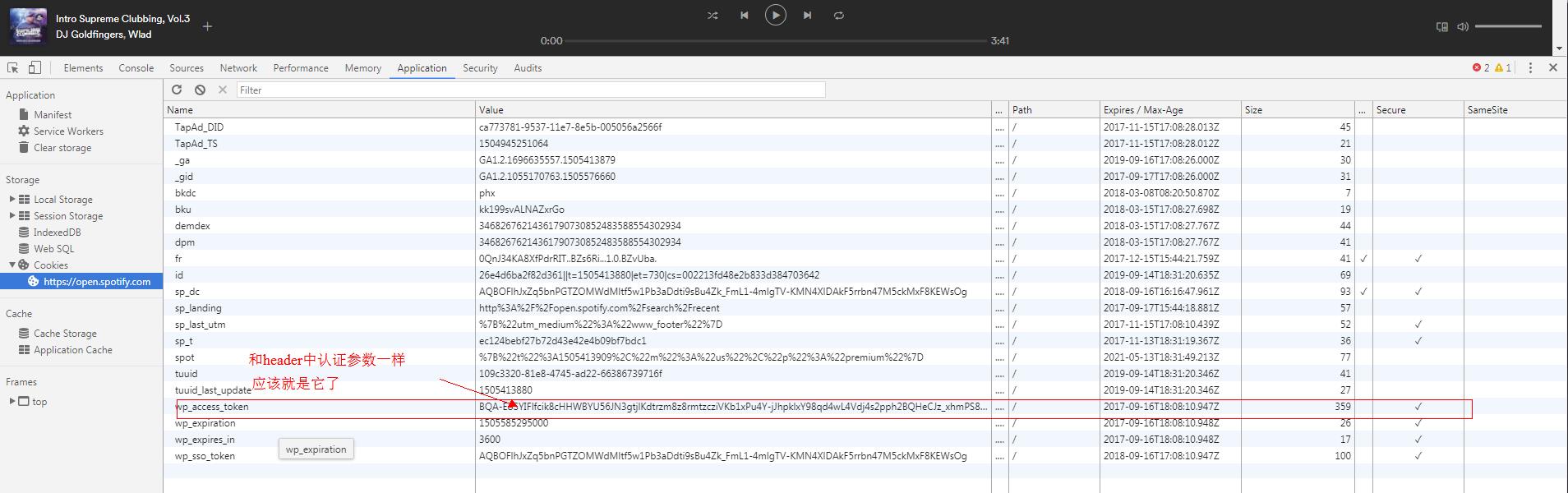
可是在我们登录后的cookies列表中却没有这个cookie!
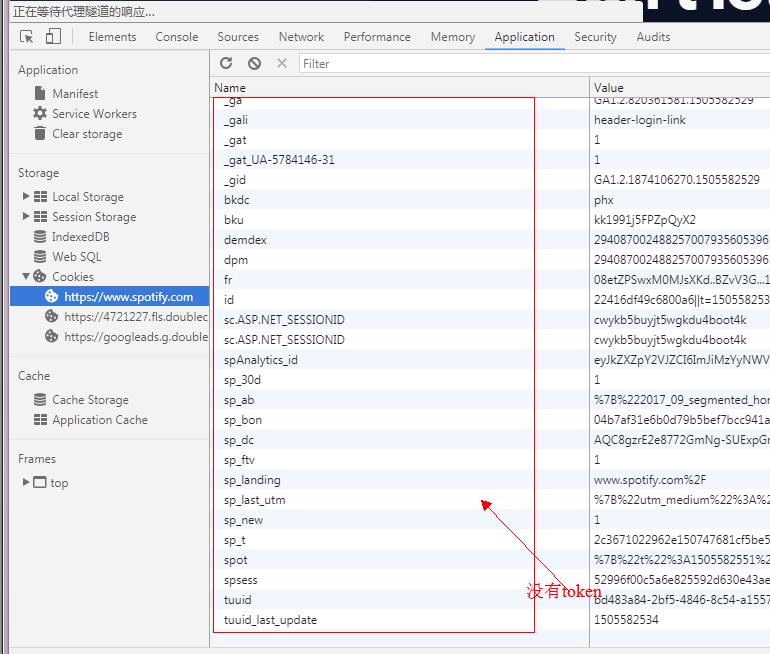
预测这个cookie应该是在web播放器加载时种下的。验证一下:
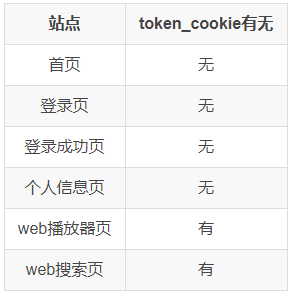
由上表可知。该token在加载播放器的时候种下的。
到这里问题,解决一大半了。
相关阅读
数据科学工具 Jupyter Notebook教程 in Python
此文已由作者授权腾讯云技术社区发布,转载请注明文章出处
原文链接:https://cloud.tencent.com/community/article/759574
以上是关于【网络爬虫教学】虫师终极武器之Chromium定制开发系列(六)的主要内容,如果未能解决你的问题,请参考以下文章