大神如何不择手段,最快最精准打击Linux网络问题?
Posted 宋宝华
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大神如何不择手段,最快最精准打击Linux网络问题?相关的知识,希望对你有一定的参考价值。
内容简介
本文是大厂著名大神Dog250在调试一些网络问题时候的实战,希望读者通过阅读本文,领悟大神们是如何“不择手段,利用手头一切的便利,最快的速度精准打击问题要害”,从而实现快速调试和解决问题的。
我们在工作中总是遇到一些需要快速解决的棘手问题,解决这类问题往往有一套可供遵循的常规思路,但是实际做起来往往非常耗时且依赖外部环境,更加棘手的是,为了按部就班地完成工作,你需要学习很多很多前置知识,比方说相关工具的使用。
我倾向于用最少的工作量来完成POC。
不会用crash/ebpf就不能debug内核了吗?不懂编程就不能优化系统了吗?并不是。
让我来展示一下县城摆摊修伞的二胡师傅和瑞士宫廷制表匠的区别吧。
本文我会举三个实际的例子。用的都是low到爆的过时玩意儿。
### 示例1:排查TCP连接僵死
netstat显示一条TCP连接的Send-Q堆积了很多数据,对端相应的Recv-Q却是0,tcpdump显示该连接持续无任何交互。
此时应该怎么办?
经过ss -it确认tcp_info信息,结论是该连接的RWND/CWND,RTT,RTO,MSS等数据均正常,网卡也无相关错误统计,但在事实上它就是僵住了,这是一个异常现象,既然Send-Q中有数据,它是无论如何都要 ***尝试*** 发送出去的。
几乎可以肯定,原因无外乎两点:
- 应用程序进入系统调用时lock住了socket并且阻塞了。
- 内核存在问题。
如何来确认?大多数人的思路倾向于使用crash工具去分析内核数据结构,但是这是一个庞大的静态分析工程。
我倾向于开着飞机修引擎,我不擅长分析死因,但我擅长做复苏。我的方法是尝试给该TCP做复苏手术。
TCP的发送一直是靠ACK时钟驱动的,事实上直到BBR开启的基于pacing的新TCP时代,也依然没有放弃ACK时钟,虽然ACK在原教旨意义上不再需要,但BBR依然使用它来计算pacing rate,假如没有ACK到来了,那么pacing rate便会逐渐跌到0,TCP也就僵住了。
***因此,TCP的复苏手术,主要是构造一个ACK去击打它!***
如果你对TCP足够了解,那么你一定会大赞我的做法。
在TCP连接显示Send-Q堆积的数据发送端构造这个ACK,需要从本机的网卡注入,为了避开路由子系统的Martian报文校验,需要另起一个net namespace来做这事。
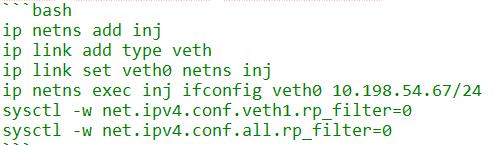
接下来我们来构造这个ACK:

为了最快速定位问题,我往往不会遵守什么编码规范,所以我会写死地址和端口,哪怕需要改的时候再编辑一下代码。
然后我们来注入:

注意,代码中的seq,ack字段我们并不知道,如何将这个ACK来精确注入这个僵死的TCP连接?
精确注入需要两步,用一个bpftrace脚本配合上述python代码获取TCP的snd_una,rcv_nxt等字段:
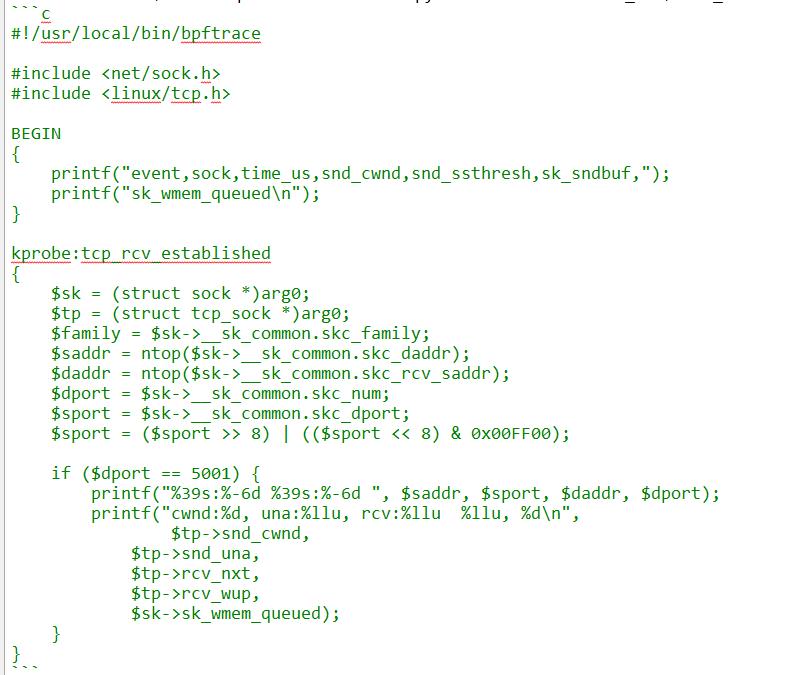
注意,我hook的是tcp_rcv_established,当我实施第一步注入的时候,没有进入这个trace,那几乎可以肯定是应用程序lock住了该连接,进而将该ACK排入了backlog以延后处理,这种情况就需要应用程序开发人员来接锅了。
如果顺利进入了该trace,那么我们便获取了TCP连接的info信息,接下来我们可以用打印出来的snd_una,rcv_nxt信息来填充python代码中的seq和ack了:
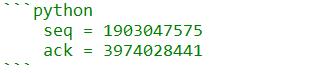
ACK构造配合bpftrace脚本,如此便可以一路跟踪到数据的发送逻辑,进而定位发送僵死的原因。核心的思路我已经给出了,本文不是case by case分析,也就没有继续的必要了。
顺便说一句,我不喜欢使用bpftrace,太麻烦且限制太多,还是systemtap顺手,特别是-g选项。bpftrace无需编译执行快并非不可或缺的优点,大家都用bpftrace更多是因为它新潮。
### 示例2:实现tun网卡的readv
最近我虽然将golang实现的tun UDP隧道的总吞吐逼近了物理网卡极限25Gbps,但是对于单流吞吐而言,却一直无法突破2~3Gbps,因此我想看看瓶颈到底在哪。
事实上,允许IP分片的情况下,我把tun的MTU设置成8000,单流吞吐可达8Gbps。然而在长传有丢包的线路,IP分片(分片丢失会造成TCP时钟卡顿)可能会使TCP的性能劣化,打乱BBR所依赖的pacing rate保真。
之前测量的结果,直连环境,通过tun UDP隧道的ping时延是物理网卡ping时延的10倍起步,那么tun和UDP socket处理的系统消耗大概要损耗10倍起步的吞吐,25Gbps下降到2~3Gbps是合理的。
因此我需要减少tun的read/write开销。
批量读写是一个合理的思路,比方说io_uring,readv/writev等。可是tun并不支持这些,怎么办?
io_uring直接抛弃,太复杂了。
如果要实现一个完备的读写数据包的readv/writev,我需要在内核和用户态均实现数据包边界的拆包组包问题,我不得不处理各种协议,以在一块整个的内存中获取数据包的长度并把它切下来,我不得不时刻当心内存的边界,把不连续的内存想办法组合成一个看上去连续的内存,以便后面的加密解密goroutine可以处理它们。
这看上去很复杂,需要对整个程序进行修改(当然了,这对于标准程序员根本不是事,但对于我,这很要命),至少也要花费一整天的时间,可作为业余的事情,每天回家都很晚了,我哪有时间折腾这些。
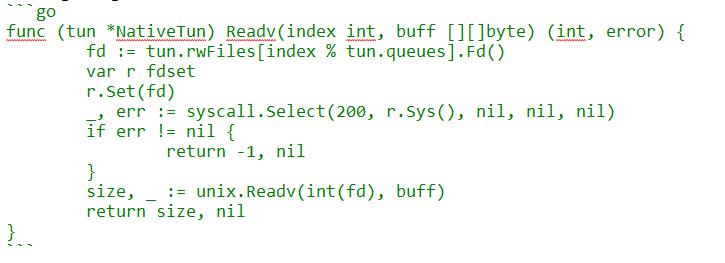
下面是我一个小时完成事情全部的做法。我改变了readv的语义:
- 每一个iovec仅存放一个skb的数据,下一个skb放在下一个iovec。
- 返回copy成功的skb的数量,而不是copy数据的总字节数。

下面是我对tun_do_read的改造:


就这么几行代码。是不是很简单。
下面是对应的golang代码:

下面是golang中的Readv:
...
### 示例3:实现松散TCP语义
来,最后一个例子,我简单说。
我想为直播业务提供一个松散TCP传输协议,如何?
什么是松散TCP?很容易理解:
- 网络状态很好或者轻微丢包时,执行完备TCP逻辑。
- 严重拥塞时不再重传,直接发后面的数据,能不能到达,听天由命。
- 接收端可以发送NAK指示发送端是否重传。
- ...
这对于直播是有意义的,体现在三个方面:
- 直播防卡顿体验要比清晰度体验更核心,严重拥塞时用户可以接受模糊但不能接受卡顿,因此可以丢帧,但不能卡住。
- 直播流量在严重拥塞时的松散非重传处理可以降低带宽成本。
- 大家都不拼命重传了,或许网络拥塞就过去了,可期待一种良性全局同步。
既能优化体验,又能降低成本,何乐而不为?那么怎么落地呢?
开会立项,确定deadline,然后大改TCP协议的实现代码吗?Linux内核中TCP的那一大脬代码能把人看疯。谁人改得动?然后可以期许的就是开会,延期,加班,哪来的快乐?
因此我用Netfilter:
- 发送端在IP层用Netfilter截获出方向的TCP段,在严重拥塞时伪造ACK回复。
- 接收端在IP层用Netfilter截获入方向的TCP段,在严重拥塞时用0填充丢包乱序造成的sequence空洞。
是不是不依赖TCP本身的实现了呢?而且实现起来很快,可以唱着歌写。先把0.1版本推上去了,业务点了赞,然后慢慢再改那脬TCP代码。
## 最后再写点儿
其实还有很多类似的例子,但是时间有限,所以只能先写几个。将上面例子抽象一下,聊点形而上的。
不管做什么事情,什么最重要?是过程?是结果?还是别的什么?
过程和结果是经理和用户最关注的,工人则需要先把活干好。
工人在没有一个理性,可行且快速,简单的方案之前,过程和结果都是奢谈。
很少有工人能给自己一个明确的定位,关注手头最要紧的事情。所以很多工人在解决问题的时候显得吃力,效率低。工人的信条就是, ***不择手段,利用手头一切的便利,最快的速度精准打击问题要害。*** 这至少是我的信条。
我擅长用火柴修雨伞,用笔帽修自行车链子,手工缠耳机实现重低音,用钉子和铜线做电容,自己缠电机,升压器,自制稳压器,用牛仔裤做提包,用椅子做桌子,自制分频器,... 所有这些玩意儿,都不需要去店里采购材料,完全利用家里废旧物什完成。
所有这些事,我关注的两点核心是:
- ***快速-快速成功要么就失败***
- ***简单-不依赖其它工具***
这思路从小时候一直持续到后来做了工人,朴素,但管用啊...
***
浙江温州皮鞋湿,下雨进水不会胖。
扫描识别二维码关注"Linux阅码场"

如果您觉得不错,请转发转发转发!
或者随手点个“在看”吧~
以上是关于大神如何不择手段,最快最精准打击Linux网络问题?的主要内容,如果未能解决你的问题,请参考以下文章