Spark作业调度中stage的划分
Posted <一蓑烟雨任平生>
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark作业调度中stage的划分相关的知识,希望对你有一定的参考价值。
Spark在接收到提交的作业后,会进行RDD依赖分析并划分成多个stage,以stage为单位生成taskset并提交调度。
(1)Spark作业调度
对RDD的操作分为transformation和action两类,真正的作业提交运行发生在action之后,调用action之后会将对原始输入数据的所有transformation操作封装成作业并向集群提交运行。这个过程大致可以如下描述:
- 由DAGScheduler对RDD之间的依赖性进行分析,通过DAG来分析各个RDD之间的转换依赖关系
- 根据DAGScheduler分析得到的RDD依赖关系将Job划分成多个stage
- 每个stage会生成一个TaskSet并提交给TaskScheduler,调度权转交给TaskScheduler,由它来负责分发task到worker执行
(2)RDD依赖关系
Spark中RDD的粗粒度操作,每一次transformation都会生成一个新的RDD,这样就会建立RDD之间的前后依赖关系,在Spark中,依赖关系被定义为两种类型,分别是窄依赖和宽依赖
- 窄依赖:父RDD的分区最多只会被子RDD的一个分区使用
- 宽依赖:父RDD的一个分区会被子RDD的多个分区使用
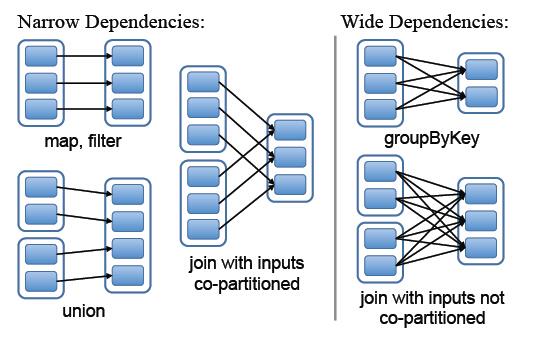
图中左边都是窄依赖关系,可以看出分区是1对1的。右边为宽依赖关系,有分区是1对多。
区分宽窄依赖,我们主要从父RDD的Partition流向来看:流向单个RDD就是窄依赖,流向多个RDD就是宽依赖。
(3)Stage的划分
Stage:
RDD在执行action操作时,会触发Job的提交,Spark会根据RDD的DAG图,将Job划分成多个阶段,每个阶段称为一个Stage。
Stage分为两种:Shuffle Map Stage和Result Stage。
- Shuffle Map Stage:Shuffle Map Stage阶段的task结果被输入到其他Stage。
- Result Stage:Result Stage阶段的task结果直接是job的结果,也就是说包含最后一个RDD的Stage就是Result Stage。
Shuffle Map Stage中的Task称为ShuffleMapTask,Result Stage中的Task称为ResultTask。
ShuffleMapTask的计算结果需要shuffle到下一个Stage,其本质上相当于MapReduce中的mapper。Result Task则相当于MapReduce中的reducer。因此整个计算过程会根据数据依赖关系自后向前建立,遇到宽依赖则形成新的Stage。
Stage的调度是由DAG Scheduler完成的。由RDD的有向无环图DAG切分出了Stage的有向无环图DAG。Stage以最后执行的Stage为根进行广度优先遍历,遍历到最开始执行的Stage执行,如果提交的Stage仍有未完成的父Stage,则Stage需要等待其父Stage执行完才能执行。
Stage的划分:
首先,需要明确的关键点是Spark Stage划分依据主要是基于Shuffle。
Shuffle是产生宽依赖RDD的算子,例如reduceByKey、reparttition、sortByKey等算子。同一个Stage内的所有Transformation算子所操作的RDD都是具有相同的Partition数量的。
stage的划分是Spark作业调度的关键一步,它基于DAG确定依赖关系,借此来划分stage,将依赖链断开,每个stage内部可以并行运行,整个作业按照stage顺序依次执行,最终完成整个Job。实际应用提交的Job中RDD依赖关系是十分复杂的,依据这些依赖关系来划分stage自然是十分困难的,Spark此时就利用了前文提到的依赖关系,调度器从DAG图末端出发,逆向遍历整个依赖关系链,遇到ShuffleDependency(宽依赖关系的一种叫法)就断开,遇到NarrowDependency就将其加入到当前stage。stage中task数目由stage末端的RDD分区个数来决定,RDD转换是基于分区的一种粗粒度计算,一个stage执行的结果就是这几个分区构成的RDD。
Spark的Job会根据RDD的依赖关系来划分Stage,划分Stage的整体逻辑是:
从最后一个RDD往前推,遇到窄依赖的父RDD时,就将这个父RDD加入子RDD所在的stage;遇到宽依赖的父RDD时就断开,父RDD被划分为新的stage。每个Stage里task的数量由Stage最后一个RDD中的分区数决定。如果Stage要生成Result,则该Stage里的Task都是ResultTask,否则是ShuffleMapTask。
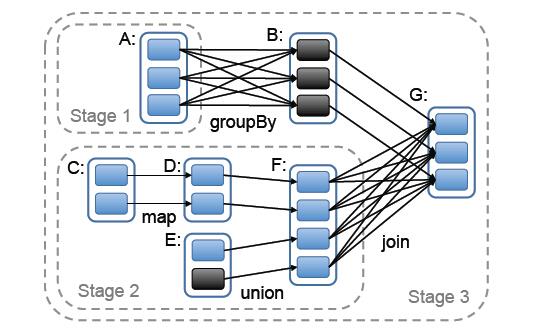
图中可以看出,在宽依赖关系处就会断开依赖链,划分stage,这里的stage1不需要计算,只需要计算stage2和stage3,就可以完成整个Job。
为什么遇到宽依赖需要切分Stage?
原因是:保证同一个Stage中的所有Task可以并行执行。
对于窄依赖,父子RDD的partition依赖关系是一对一,所以将子RDD的partition和其依赖的父RDD的partition放在同一个线程里处理,不同的线程可以并行的执行不同partition的转换处理。
而对于宽依赖,因为子RDD的每个partition都依赖父RDD的所有partition,所以子RDD的partition转换处理需要等父RDD的所有partition处理完成才能开始。所以宽依赖的父RDD不能和子RDD放在同一个Stage中。
以上内容仅供参考学习,如有侵权请联系我删除!
如果这篇文章对您有帮助,左下角的大拇指就是对博主最大的鼓励。
您的鼓励就是博主最大的动力!
以上是关于Spark作业调度中stage的划分的主要内容,如果未能解决你的问题,请参考以下文章
[Spark传奇行动] 第34课:Stage划分和Task最佳位置算法源码彻底解密