朴素贝叶斯算法检测DGA
Posted Neil-Yale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了朴素贝叶斯算法检测DGA相关的知识,希望对你有一定的参考价值。
僵尸网络&恶意软等程序,随着检测手段的更新(在早期,僵尸主机通产采用轮询的方法访问硬编码的C&C域名或IP来访问服务器获取域名,但是这种方式在安全人员进行逆向之后会得到有效的屏蔽),黑客们也升级了肉鸡的C&C手段;用DGA算法在终端生成大量备选域名,而攻击者与恶意软件运行同一套DGA算法,生成相同的备选域名列表。
当需要发动攻击的时候,选择其中少量进行注册,便可以建立通信,并且可以对注册的域名应用速变IP技术,快速变换IP,从而域名和IP都可以进行快速变化。目前,黑客攻击者为了防止恶意域名被发现,会使用Domain Flux或者IP Flux来快速生成大量的恶意域名。(Domain Flux是通过不断变换域名,指向同一个IP,IP Flux是只有一个域名,不断变换IP,一个域名可以使用多个IP)。
很显然,在这种方式下,传统基于黑名单的防护手段无法起作用,一方面,黑名单的更新速度远远赶不上DGA域名的生成速度,另一方面,防御者必须阻断所有的DGA域名才能阻断C2通信,因此,DGA域名的使用使得攻击容易,防守困难。
DGA(域名生成算法)是一种利用随机字符来生成C&C域名,从而逃避域名黑名单检测的技术手段。例如,一个由Cryptolocker创建的DGA生成域xeogrhxquuubt.com,如果我们的进程尝试其它建立连接,那么我们的机器就可能感染Cryptolocker勒索病毒。域名黑名单通常用于检测和阻断这些域的连接,但对于不断更新的DGA算法并不奏效,所以在本次实验中我们来学习如果使用机器学习的方法对DGA进行检测。
DGA算法由两部分构成,种子(算法输入)和算法,可以根据种子和算法对DGA域名进行分类
种子分类:
1.基于时间的种子(Time dependence)。DGA算法将会使用时间信息作为输入,如:感染主机的系统时间,http响应的时间等。
2.是否具有确定性(Determinism)。主流的DGA算法的输入是确定的,因此AGD可以被提前计算,但是也有一些DGA算法的输入是不确定的,如:Bedep[4]以欧洲中央银行每天发布的外汇参考汇率作为种子,Torpig[5]用twitter的关键词作为种子,只有在确定时间窗口内注册域名才能生效。
算法分类:
现有DGA生成算法一般可以分为如下4类:
1.基于算术。该类型算法会生成一组可用ASCII编码表示的值,从而构成DGA域名,流行度最高。
2.基于哈希。用哈希值的16进制表示产生DGA域名,被使用的哈希算法常有:MD5,SHA256。
3.基于词典。该方式会从专有词典中挑选单词进行组合,减少域名字符上的随机性,迷惑性更强,字典内嵌在恶意程序中或者从公有服务中提取。
4.基于排列组合。对一个初始域名进行字符上的排列组合。
DGA域名存活时间:
DGA域名的存活时间一般较短,大部分域名的存活时间为1-7天
接着我们学习本次实验使用的机器学习算法-朴素贝叶斯的流程:
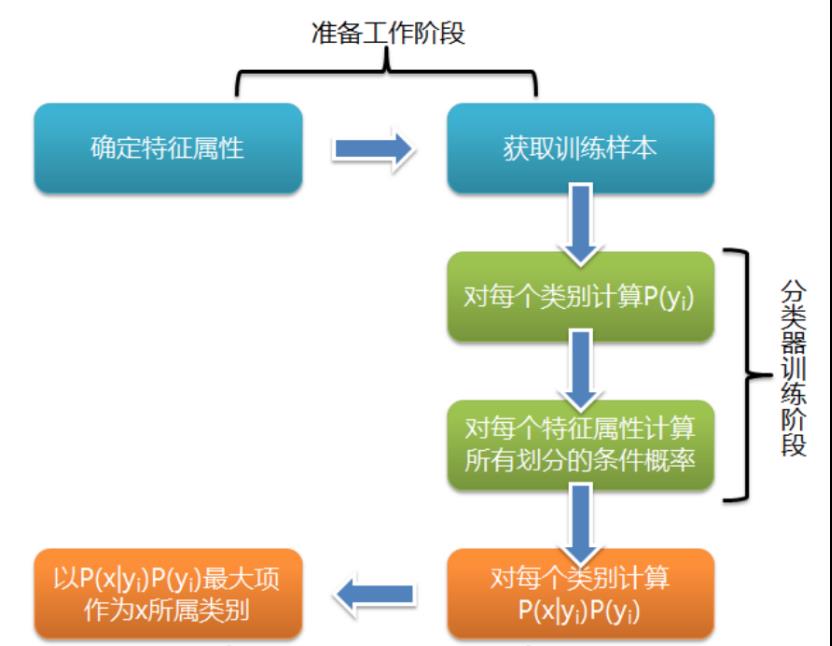
可以看到,整个朴素贝叶斯分类分为三个阶段:
第一阶段——准备工作阶段,这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
第二阶段——分类器训练阶段,这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算完成。
第三阶段——应用阶段。这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完成。
实验中会使用sklearn中封装好的朴素贝叶斯算法。在scikit-learn中,一共有3个朴素贝叶斯的分类算法类。分别是GaussianNB,MultinomialNB和BernoulliNB。其中GaussianNB就是先验为高斯分布的朴素贝叶斯,MultinomialNB就是先验为多项式分布的朴素贝叶斯,而BernoulliNB就是先验为伯努利分布的朴素贝叶斯。我们使用GaussianNB。接下来我们简单试试看
import numpy as np
from sklearn.naive_bayes import GaussianNB
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
Y = np.array([1, 1, 1, 2, 2, 2])
clf = GaussianNB()
clf.fit(X, Y)
GaussianNB(priors=None, var_smoothing=1e-09)print(clf.predict([[-0.8, -1]]))
[1]
首先导入库文件

给出数据

选择分类器并进行训练

进行预测

接下来考虑数据来源。数据的话分为白样本和黑样本
白样本我们选择来自Alexa的前1000的域名。这里简单介绍下Alexa排名。Alexa排名,是指网站的世界排名。Alexa提供包括综合排名、放量排名、页面访问量排名等多个信息,人们认为它是比较权威的网站流量评价指标。Alexa排名是每三个月公布一次。排名依据是用户链接数和页面浏览数三个月的几何平均值。
可以在这里看到数据https://www.alexa.com/topsites
写本次实验指导书时部分排名如下
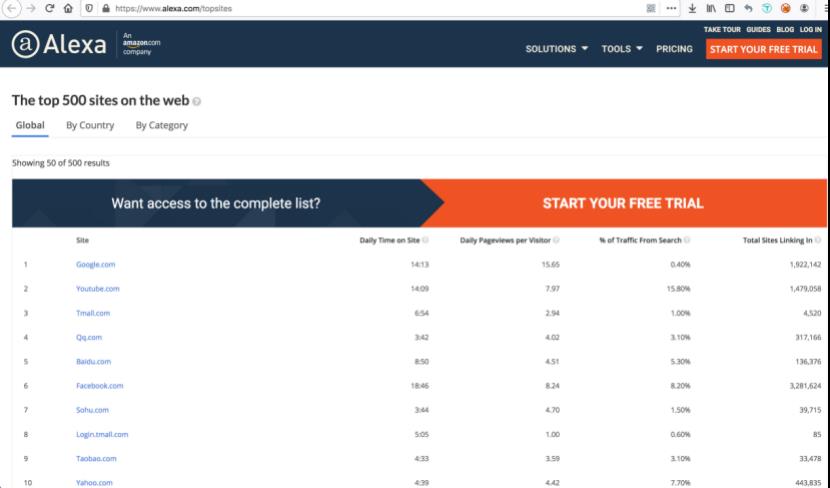
提取出前1000的域名写入top-1000.csv
再来考虑黑样本的来源,dga的来源有很多,这里用国内360 netlab的数据

在上图中可以看到有很多家族,我们这里就以选取cryptolocker和dyre进行实验
以cryptolocker为例,访问如下网址
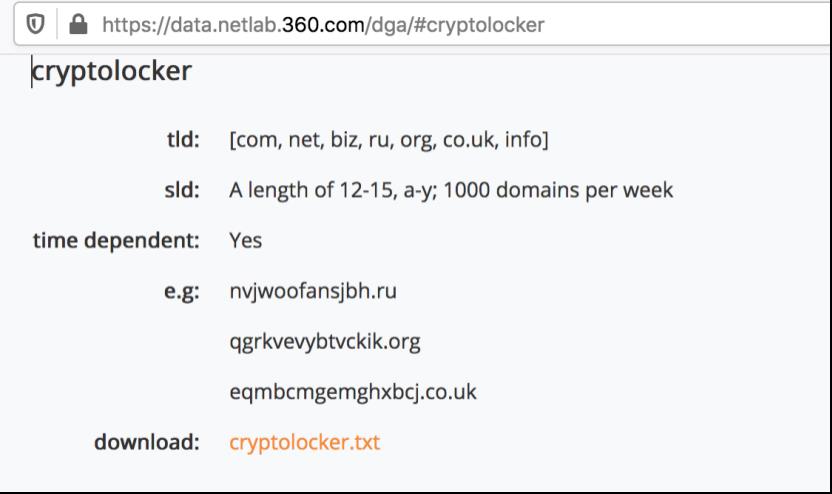
就可以下载cryptolocker.txt
里面的内容就是实时更新的dga
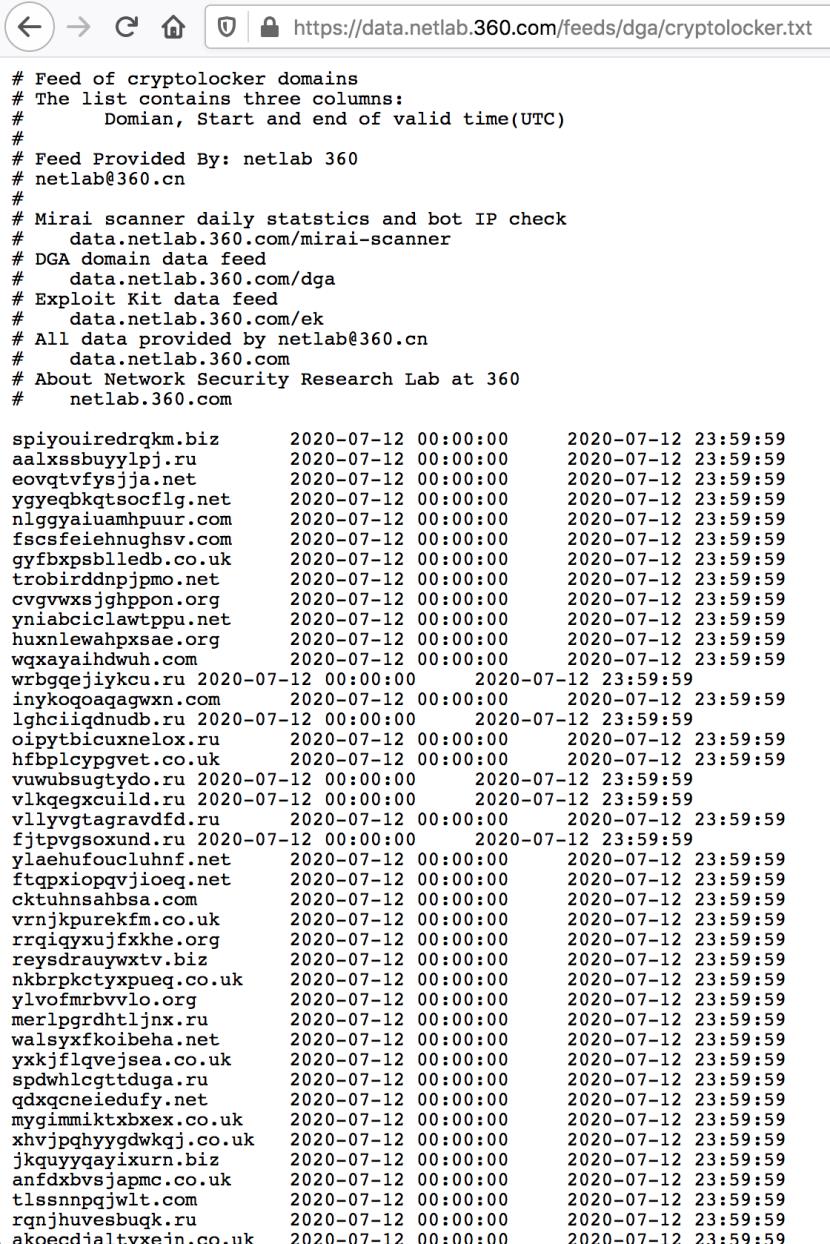
我们简单将其处理后保存为cryptolocker.txt。dyre也是同理,保存为dyre.txt
我们接下来写代码
首先加载数据集,来自alexa的数据是白样本,来自360 netlab的dga数据是黑样本
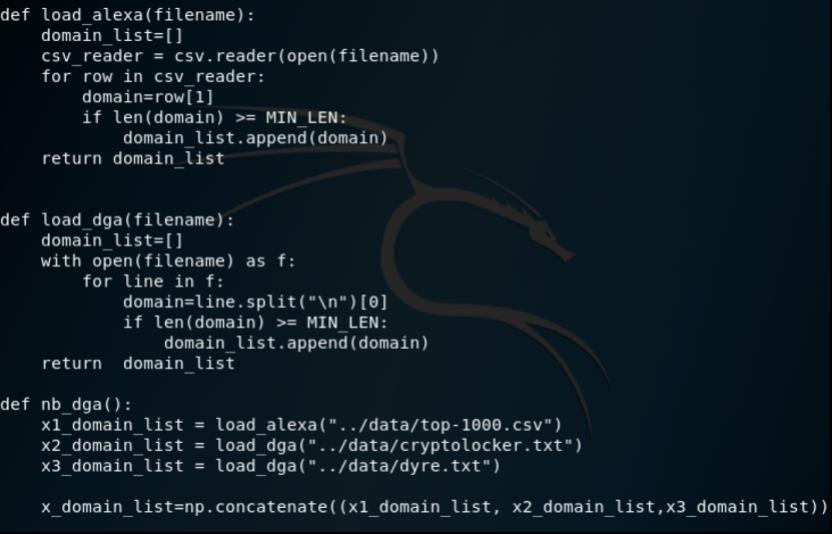
这里需要根据数据集自身的特点来写,用于将文档中的域名提取出来。代码中的MIN_LEN为最小长度,我们设为10,即提取出长度大于等于10的域名。
这里可以将load_alexa函数单独改写为alexa.py,来看看是否能成功提取
代码如下
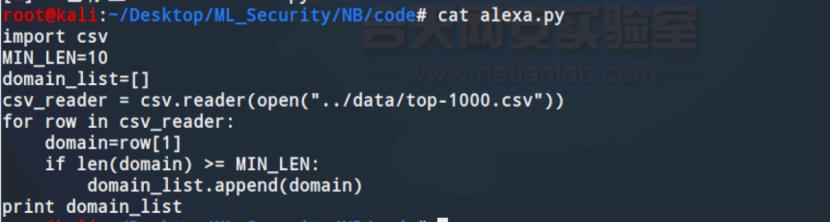
测试如下
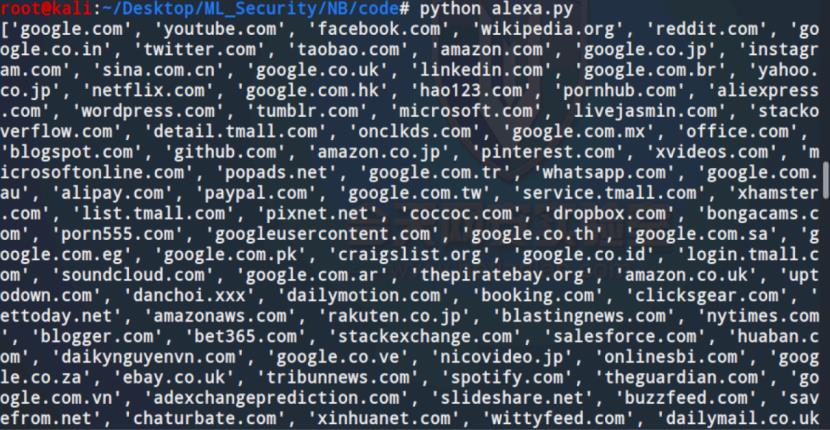
可以看到是能够提取出来的,load_dga函数的功能测试也是同理,这里不再重复
接下来就是打标签

分别标记为0,1,2
然后使用n-gram处理,这里使用2-gram
N-Gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。
每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。
该模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。
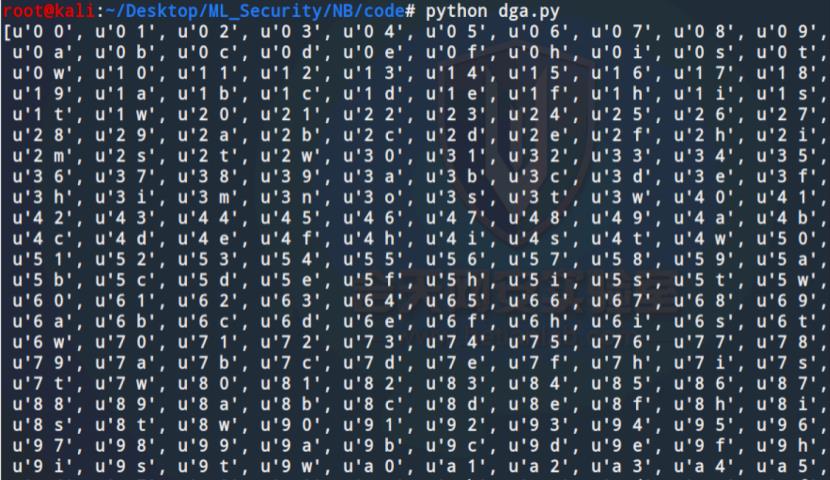
如果用的是2-gram,那么针对hetian.com,则处理之后会得到he,ei,ti,ia.an,nc,co,om
我们将2-gram处理后的结果进行映射,得到特征化的向量

可以将代码文件dga.py中的相应注释去掉,可以打印出来看看
接下来使用GaussianNB进行训练,采用10折交叉验证,并打印结果

测试结果如下

可以看到准确率达到了96%左右,还是不错的。
参考:
1.https://www.cnblogs.com/leoo2sk/archive/2010/09/17/naive-bayesian-classifier.html
2.https://zhuanlan.zhihu.com/p/32829048
3.《web安全与机器学习》
4.https://github.com/duoergun0729/1book/
以上是关于朴素贝叶斯算法检测DGA的主要内容,如果未能解决你的问题,请参考以下文章