朴素贝叶斯算法总结
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了朴素贝叶斯算法总结相关的知识,希望对你有一定的参考价值。
参考技术A 目录一、贝叶斯定理
二、朴素贝叶斯分类工作原理及流程
三、总结
一、 贝叶斯定理 :是为了解决“逆向概率”问题而写的一篇文章,尝试回答在没有太多可靠证据的情况下,怎样做出更符合数学逻辑的推测。这种推测基于主观的判断的基础上,在事先不知道客观事实的情况下,同样可以先估计一个值,然后根据实际结果不断进行修正。
这个定理解决了现实生活中已知条件概率,如何得到两个事件交换后的概率 。例如:已知P(A|B)的情况下,如何求出P(B|A)的概率问题。贝叶斯定理的出现就是用来打通P(A|B)到P(B|A)之路,通用公式如下:
先验概率 :通过经验来判断事情发生的概率。
条件概率 :P(A|B)表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。其基本求解公式为:
后验概率 :发生结果之后,推断原因的概率。它属于条件概率的一种 。
二、 朴素贝叶斯分类原理及流程
朴素贝叶斯法 :是基于贝叶斯定理与特征条件独立假设的分类方法。对于给定的训练集,首先基于特征条件独立假设学习输入/输出的联合概率分布;然后基于此模型,对给定的输入x,利用贝叶斯定理求出后验概率最大的输出y。之所以朴素的思想基础是:对于给定的待分类项,求解在此项出现的特征条件下在各类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
朴素贝叶斯分类具体定义 :
a、设x= , , ,...... 为一个待分类项,而每个a为x的一个特征属性。
b、有类别集合C= , , ,..., 。
c、计算P( | x),P( | x),...,P( | x)。
d、如果P( | x)=max P( | x),P( | x),...,P( | x) ,则x
那么现在的关键是c中如何计算出各条件概率,如下:
1、找到一个已知分类的待分类项的集合,称为训练样本集。
2、统计得到各类别下各特征属性的 条件概率估计 。即:
P( | ),P( | ),...,P( | );P( | ),P( | ),...,P( | );.......,P( | ),P( | ),...,P( | )。
3、如果各特征属性是条件独立的,则根据贝叶斯公式有如下推导:
P( ) =
因为分母对所有分类均为常数(可忽略),因此我们只需将分子最大化。又因为各特征属性是条件独立的,所以有:
= ..... =
综上所述,朴素贝叶斯分类的流程图:
第一阶段 :准备工作,确定训练样本集和特征属性。
第二阶段 :分类器训练,计算先验概率和各类下各特征的条件概率。输入为样本集和特征属性,输出为分类器。
第三阶段: 分类器应用,输入为分类器和待分类项,输出为待分类项的类。
三、 总结 :
1、朴素贝叶斯法是典型的生成学习方法。生成方法由训练数据学习联合概率分布P(X,Y),然后求得后验概率分布P(Y|X)。具体来说,利用训练数据学习P(X|Y)和P(Y)的估计,得到联合概率分布:P(X,Y)=P(Y)P(X|Y)。概率估计法可以是极大似然估计或者贝叶斯估计。
2、朴素贝叶斯法的基本假设是特征属性的条件独立性,即
这是一个较强的假设,由于这一假设,模型包含的条件概率的数量大为减少,朴素贝叶斯的学习与预测大为简化,因而朴素贝叶斯法高效,且易于实现。缺点是分类的性能不一定很高。
3、朴素贝叶斯法利用贝叶斯定理与学到的联合概率模型进行分类预测。将输入的x分到后验概率最大的类y。后验概率最大等价于0-1损失函数时的期望风险最小化。
朴素贝叶斯(NB)复习总结
摘要:
1.算法概述
2.算法推导
3.算法特性及优缺点
4.注意事项
5.实现和具体例子
6.适用场合
内容:
1.算法概述
贝叶斯分类算法是统计学的一种分类方法,其分类原理就是利用贝叶斯公式根据某对象的先验概率计算出其后验概率,然后选择具有最大后验概率的类作为该对象所属的类。
之所以称之为"朴素",是因为贝叶斯分类只做最原始、最简单的假设:所有的特征之间是统计独立的(假设某样本x有a1,...,aM个属性,那么有:P(x)=P(a1,...,aM) = P(a1)*...*P(aM);)
这里给出NB的模型函数: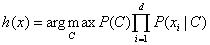
根据变量的分布不同,NB也分为以下3类:
朴素贝叶斯的伯努利模型(特征是布尔变量,符合01分布),在文本分类的情境中,特征是词是否出现
朴素贝叶斯的多项式模型(特征是离散变量,符合多项分布),在文本分类的情境中,特征是词的出现次数
朴素贝叶斯的高斯模型(特征是连续变量,符合高斯分布),在文本分类的情境中,特征是词的TFIDF值
2.算法推导
贝叶斯定理:
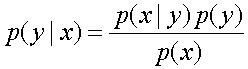
其中P(y|x)是在x发生的情况下y发生的可能性。
在贝叶斯定理中,每个名词都有约定俗成的名称:
P(y)是y的先验概率或边缘概率。之所以称为"先验"是因为它不考虑任何x方面的因素。
P(y|x)是已知x发生后y的条件概率,也由于得自x的取值而被称作y的后验概率。
P(x|y)是已知y发生后x的条件概率,也由于得自y的取值而被称作x的后验概率。
P(x)是x的先验概率或边缘概率,也作标准化常量(normalizing constant).
由贝叶斯公式和各特征相互独立的情况下,得到如下公式:

条件概率的计算方法:
1,离散分布-当特征属性为离散值时,只要统计训练样本中特征a的各个特征值在每个类别中出现的频率即可用来估计P(a(i)|y(k))。
2,连续分布-当特征属性为连续值时,通常假定a|y服从高斯分布(正态分布)。
即: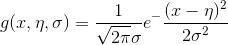 ,而
,而
3.算法特性及优缺点
优点:
1.算法简单
2.所需估计参数很少
3.对缺失数据不太敏感
4.朴素贝叶斯的条件概率计算彼此是独立的,因此特别适于分布式计算
5.朴素贝叶斯属于生成式模型,收敛速度将快于判别模型(如逻辑回归)
6.天然可以处理多分类问题
缺点:
1.因为朴素贝叶斯分类假设样本各个特征之间相互独立,这个假设在实际应用中往往是不成立的,从而影响分类正确性
2.不能学习特征间的相互作用
3.对输入数据的表达形式很敏感。
4.注意事项
4.1 取对数:
实际项目中,概率P往往是值很小的小数,连续的小数相乘容易造成下溢出使乘积为0或者得不到正确答案。一种解决办法就是对乘积取自然对数,将连乘变为连加,ln(AB)=lnA+lnB。
4.2 Laplace校准:
如果新特征出现,会导致类别的条件概率为0,最终出现0/0 未定义的情况 ;修改后的的表达式为:![clip_image071[4]](http://images.cnblogs.com/cnblogs_com/jerrylead/201103/201103052259432956.png "clip_image071[4]") 每个z=j的分子都加1,分母加k(类别的个数)。
每个z=j的分子都加1,分母加k(类别的个数)。
5.实现和具体例子
垃圾邮件过滤:吴恩达的斯坦福公开课
6.适用场合
是否支持大规模数据:支持,并且有分布式实现
特征维度:可以很高
是否有 Online 算法:有(参考自)
特征处理:支持数值型,类别型类型
以上是关于朴素贝叶斯算法总结的主要内容,如果未能解决你的问题,请参考以下文章