分布式事务,阿里为什么钟爱TCC
Posted 架构师社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式事务,阿里为什么钟爱TCC相关的知识,希望对你有一定的参考价值。
之前写过一篇文章说了TCC的很多缺点,后来我把文章删了,原因是一位阿里大佬加我好友并指正了我的观点。
太感谢了!
1 TCC概要
简单来讲,TCC模式就是将整个事务分成两个阶段来提交,try阶段进行预留资源,如果所有分支都预留成功,则进入commit阶段提交所有分支事务,否则执行cancel取消所有分支事务。
以电商系统为例,假如有订单、库存和账户3个服务,客户购买一件商品,订单服务增加订单,库存服务扣减库存,账户服务扣减金额,这三个操作必须是原子性的,要么全部成功,要么全部失败。
try阶段
如下图:
订单服务增加一个订单,库存服务冻结订单上的库存,账户服务冻结订单上的金额。
订单、库存和账户这三个服务作为整个分布式事务的分支事务,在try阶段都是要提交本地事务的。上面库存和账户说的冻结,就是说这个订单对应的库存和金额已经不能再被其他事务使用了,所以必须提交本地事务。
但这个提交并不是真正的提交全局事务,而是把资源转到中间态,这个中间态需要在try方法的业务代码中实现,比如账户扣除的金额可以先存放到一个中间账户。
如果try阶段不提交本地事务会有什么问题呢?有可能其他事务在try阶段发现用户账户里面的金额还够,但是commit的时候发现金额不够了,commit阶段扣款只能失败,这时其他两个分支事务提交成功而账户服务的分支事务提交失败,最终数据就不一致了。
commit阶段
如下图:
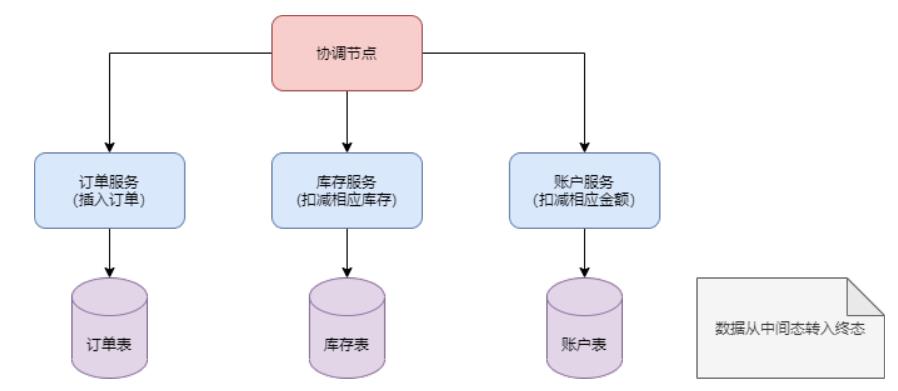
commit阶段,数据从中间态转入终态,比如订单金额从中间账户转到最终账户。
cancel阶段跟commit阶段类似,比如订单金额从中间账户退回到客户账户。
2 问题代码
下面这段代码也可以理解为TCC,是在try阶段hold住了connection,不提交分支事务,到commit阶段再提交分支事务。代码如下:我们以扣减账户为例,首先定义2个变量来hold住connection:
private Map<String, Statement> statementMap = new ConcurrentHashMap<>(100);
private Map<String, Connection> connectionMap = new ConcurrentHashMap<>(100);
try方法代码如下:
public boolean try(String xid, Long userId, BigDecimal payAmount) {
LOGGER.info("decrease, xid:{}", xid);
LOGGER.info("------->尝试扣减账户开始account");
try {
//尝试扣减账户金额,事务不提交
Connection connection = hikariDataSource.getConnection();
connection.setAutoCommit(false);
String sql = "UPDATE account SET balance = balance - ?,used = used + ? where user_id = ?";
PreparedStatement stmt = connection.prepareStatement(sql);
stmt.setBigDecimal(1, payAmount);
stmt.setBigDecimal(2, payAmount);
stmt.setLong(3, userId);
stmt.executeUpdate();
statementMap.put(xid, stmt);
connectionMap.put(xid, connection);
} catch (Exception e) {
LOGGER.error("decrease parepare failure:", e);
return false;
}
LOGGER.info("------->尝试扣减账户结束account");
return true;
}
commit方法代码如下:
public boolean commit(BusinessActionContext actionContext){
String xid = actionContext.getXid();
PreparedStatement statement = (PreparedStatement) statementMap.get(xid);
Connection connection = connectionMap.get(xid);
try {
if (null != connection){
connection.commit();
}
} catch (SQLException e) {
LOGGER.error("扣减账户失败:", e);
return false;
}finally {
try {
statementMap.remove(xid);
connectionMap.remove(xid);
if (null != statement){
statement.close();
}
if (null != connection){
connection.close();
}
} catch (SQLException e) {
LOGGER.error("扣减账户提交事务后关闭连接池失败:", e);
}
}
return true;
}
cancel方法代码如下:
public boolean rollback(BusinessActionContext actionContext){
String xid = actionContext.getXid();
PreparedStatement statement = (PreparedStatement) statementMap.get(xid);
Connection connection = connectionMap.get(xid);
try {
connection.rollback();
} catch (SQLException e) {
return false;
}finally {
try {
if (null != statement){
statement.close();
}
if (null != connection){
connection.close();
}
statementMap.remove(xid);
connectionMap.remove(xid);
} catch (SQLException e) {
LOGGER.error("扣减账户回滚事务后关闭连接池失败:", e);
}
}
return true;
}
这段代码是问题代码,不能用,不能用,不能用
这个代码存在两个问题:
2.1 阻塞等待
如果当前事务不提交,比如账户服务,那就相当于是锁定了资源,后面的事务只能等待资源释放。
2.2 服务集群
以订单服务为例,假如订单服务是一个3个机器的集群,如下图:
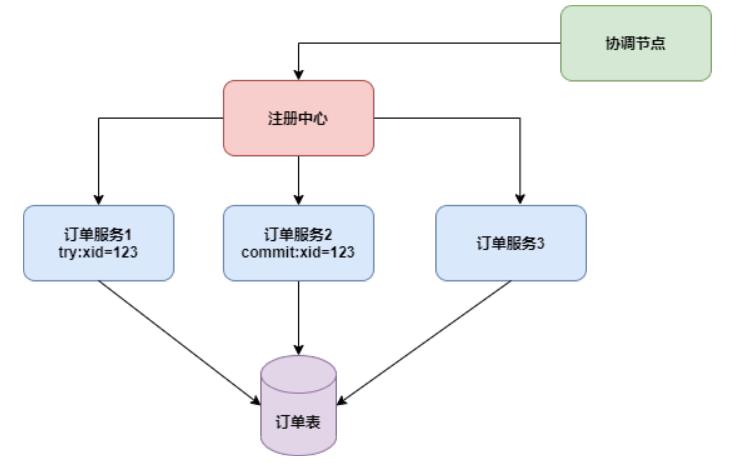
协调节点使用注册中心客户端来调用订单服务,如果try请求发送到了订单服务1,而commit请求发送到了订单服务2,那订单服务2上的connectionMap里不会有xid=123这个connection,只能提交失败。
3 TCC存在的问题
上面的问题代码就是给大家一个思路,如果真要hold住connection,也算是实现了TCC的思想,但是在系统中,我们是不可能这样做的,所以把它叫做问题代码。
3.1 空回滚
如下图,订单服务1节点故障,如果不考虑重试,try方法失败:
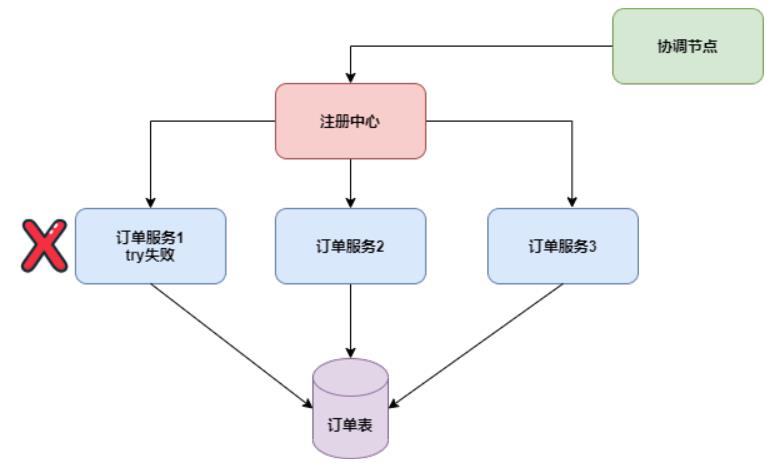
try虽然失败了,但是全局事务已经开启,框架必须要把这个全局事务推向结束状态,这就不得不调用订单服务cancel方法进行回滚,结果订单服务空跑了一次cancel方法。
解决这个问题,可以记录一张事务控制表,保存全局事务xid和分支事务branchId,try阶段会插入一条记录,表示try阶段执行了。cancel方法读取该记录,如果记录存在,正常回滚;如果该记录不存在,那就是空回滚。
3.2 幂等
幂等是指在commit/cancel阶段,因为TC没有收到分支事务的响应,需要进行重试,这就要分支事务支持幂等。以订单服务为例。如下图:
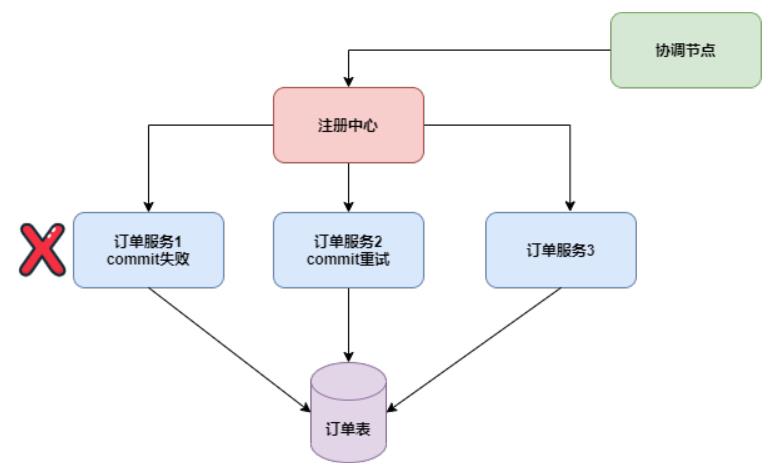
要支持幂等,可以记录一张事务控制表,保存全局事务xid和分支事务branchId,以及分支事务状态,在第二阶段commit/cancel之前先检查分支事务状态是否已经是终态,如果不是,再执行第二阶段的逻辑。
3.3 悬挂
悬挂是指事务的cancel方法比try方法先执行。上面讲了seata的使用过程中会发生空回滚,如果发生了空回滚,执行了cancel方法后全局事务结束了,但是因为网络问题,订单服务又收到了try请求,执行try方法后预留资源成功,这些资源最终不能释放了。
解决这个问题的方法就是在cancel方法中记录xid对应的分支事务回滚记录,try阶段执行的时候先判断分支事务是否已经回滚,如果存在回滚记录,则直接退出。
3.4 业务代码侵入
TCC的try/commit/cancel,对业务代码都有侵入,而且每个方法都是一个本地事务。再加上需要考虑幂等、空回滚、悬挂等,代码侵入会更高。
4.TCC优势
这里以seata实现的四种模式来比较,包括XA、SAGA、TCC、AT。
效率
使用TCC模式时,在try阶段就提交了本地事务,并不会锁定资源,所以没有其他额外的性能开销。相比之下,来看其他几种模式:
-
AT模式,需要记录undolog,性能损耗很大。 -
XA模式,执行xa start | sql | xa end之后,执行commit/rollback之前,会锁定资源,后面的事务需要等待。
saga模式
更适合长流程的业务场景。
5.性能优化
参考[1]
5.1 异步提交
优化思路是try阶段成功后,不立即执行confirm/cancel阶段,而是等系统空闲的时候异步执行。如下图:
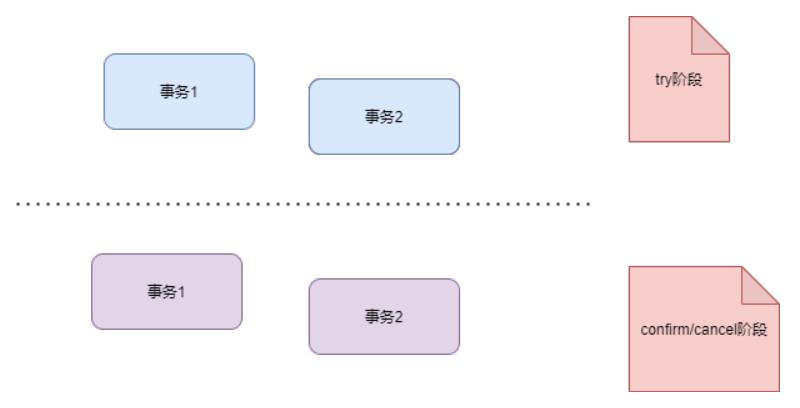
这样在try阶段结束后,就认为全局事务结束了,可以定时(比如10分钟)来异步执行第二阶段,性能大幅提升。
当然,带来的一点问题就是如果全局事务回滚,会有短暂的数据不一致。比如扣款的场景,定时10分钟执行一次异步任务,如果第二阶段是cancel,那客户会在这10分钟内不能使用这笔金额。
这个异步执行的时间也可以根据业务来决定,比如不需要及时从中间账户转移到最终账户的场景可以设置更长。
5.2 同库模式
首先回顾一下TCC中各个角色:
-
TM管理全局事务,包括开启全局事务,提交/回滚全局事务 -
RM管理分支事务 -
TC管理全局事务和分支事务的状态
先看一下优化之前的通信模型,如下图:
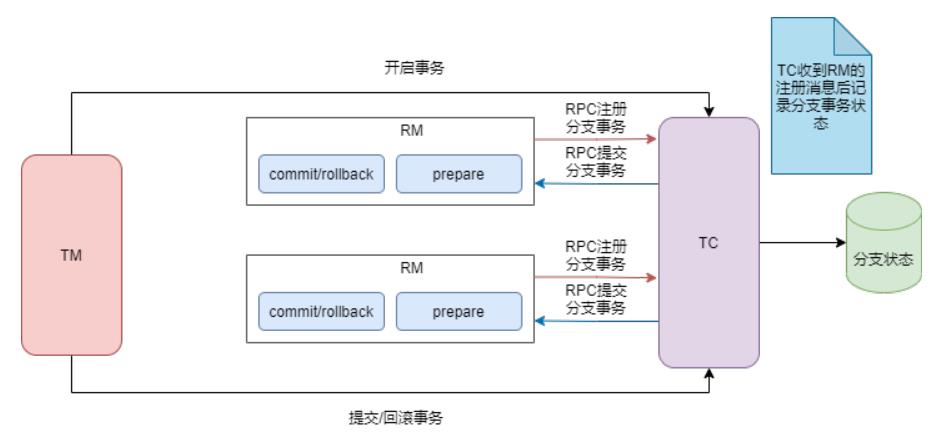
在优化之前,TM开启全局事务时,RM需要向TC发送RPC消息进行注册,TC保存分支事务的状态。TM请求提交或回滚时,TC需要向RM发送RPC消息进行提交或回滚。这样包含两个个分支事务的分布式事务中,TC和RM之间有四次RPC。
优化之后的模型如下图:
TM开启全局事务时,不再需要向TC注册分支事务,而是把分支事务状态保存在了本地。TM向TC发送提交或回滚消息时,TC保存全局事务的状态。而RM则启动异步线程检测本地记录的未提交分支事务,向TC发送RPC消息获取整体事务状态,以决定是提交还是回滚本地事务。可见,优化后的模型,RPC次数减少了50%,性能大幅提升。
6.总结
TCC的问题确实不少,但是除了侵入业务代码这一个问题,其他问题都有对应的解决方案。
阿里针对TCC做了一些优化,包括第二阶段异步提交和同库模式,性能提升很明显。
参考资料
参考: https://tech.antfin.com/community/live/462/data/736
以上是关于分布式事务,阿里为什么钟爱TCC的主要内容,如果未能解决你的问题,请参考以下文章
实战!阿里神器 Seata 实现 TCC模式 解决分布式事务,真香!