2021前端智能化发展现状与未来展望
Posted 阿里巴巴淘系技术团队官网博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021前端智能化发展现状与未来展望相关的知识,希望对你有一定的参考价值。

前端智能化历时三年有余,从最初被误解为“用 AI 包装自己的 PPT 产品...到 imgcook.com 发布上线。从淘系技术双十一零研发战役,到赋能十余个 BU。从 QCon 十周年分享“一个前端智能化的实践”后各种质疑,到 23000+ 用户并被京东、腾讯、字节跳动……等公司模仿,平安银行等大企业请求私有化部署……。一路走来,有过太多的不眠之夜和心酸苦楚但依旧阳光快乐的我,想对过去做一个简要的总结,并对未来长期发展的方向做一个规划和展望,希望能把前端智能化是啥讲清楚。

前端智能化的起源
2017年开始提出“前端智能化”的概念,当时负责 UC 国际浏览器,从前端的场景出发,有过一些尝试:用户体验度量、UI 自动化测试、基于设计稿生成代码。直到2019年 D2 前端论坛发布了“http://www.imgcook.com”,前端智能化这个词才正式确立。
我们用智能化手段提升前端的研发效能作为第一步,借 imgcook 的设计稿生成代码作为切入点,一举彻底解决了前端切图编写 UI 代码的各种一线前端工程师的部分研发效率问题。
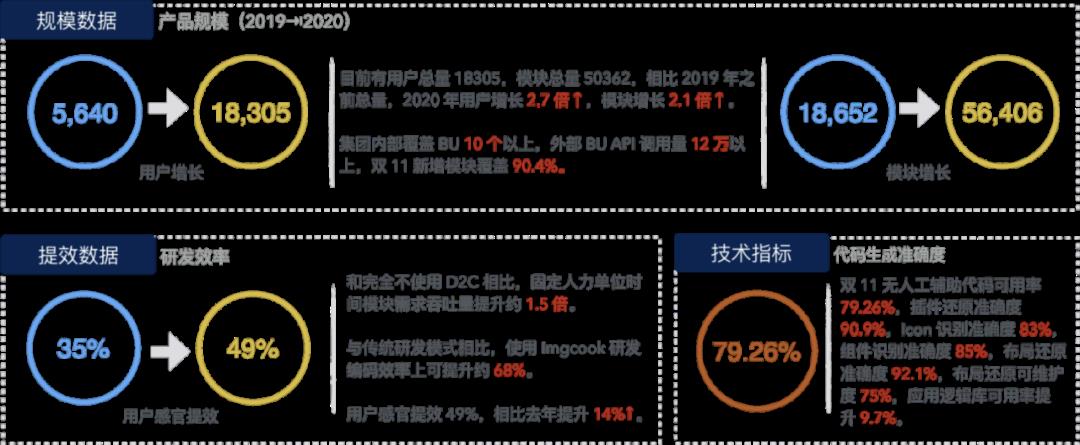
如果设计稿生成代码是基础,那么,从我们服务的用户:“前端工程师”来看,生成代码的准确性、可用性和可维护性是成败的关键。通过机器视觉识别能力和深度神经网络的理解能力、出码规则引擎的前端 UI 代码表达能力,利用机器代替前端工程师去“看”设计稿、“切图”、“生成 UI 代码”,从而,用识别、理解和表达能力的提升带来了准确性、可用性和可维护性的提升。

接下去,就要扩展和丰富使用场景提升交付效率。我们把智能化能力应用到智能 UI 上,解决了个性化 UI 带来的海量模块和组件开发工作。应用到服务端胶水层代码生成,替代服务端和 Node FaaS 在业务能力之上编写具体业务逻辑。应用到自动化 UI 测试上,显著减少了测试时间和测试投入的人力成本。
最后,向前端智能化要业务价值。我们把智能化应用到营销活动和频道导购业务上,借助智能 UI 推荐算法自动生成用户承接场景,不同程度提升业务核心指标。应用到需求生成代码平台 BizCook 上,建设了业务指标驱动的多角色协作业务研发平台,让协作在线化、编码自动化,显著提升业务试错和迭代效率。应用到素材合规审核上,解决了天猫 U 先试用的商家素材合规审核、天合计划流量宝商家广告素材合规审核,并沉淀成集团通用可配置的素材合规审核平台。
这一系列过程是 30 多前端在 52 个业务支撑下,利用业余时间和加班,打造的 研发效率、交付效率、业务试错和迭代效率 的极致生产力之路。

前端智能化的关键环节
▐ 2-3-1-5
2 个类型的业务场景:触达用户、承接用户
3 个领域:研发、交付、业务
1 个核心技术:AI 驱动的代码生成能力
5 个关键环节:RunCook(把业务场景化投放至二、三环媒体进行用户触达)、BizCook(试错、迭代敏捷创新用户承接能力)、UICook(用个性化 UI 精细化用户承接能力)、imgCook(设计生产一体化 UI 代码自动生成)、LogicCook(PaaS 业务能力注册发现为基础的逻辑代码自动生成)、ReviewCook(自动化 Codereview 保证生成代码的质量)。

“业务效率、交付效率、研发效率” 这些词看起来都很好理解,但是在阿里巴巴现在体量和场景下,这些词背后又存在着大量的难题和挑战。以 UICook 的智能场景和智能设计为例,1 个页面可能包含 10+ 模块,1 个模块可能包含 5 个左右的组件,1 个组件会设计 20+ 样式,1 个模块就存在 100 次编码、调试、测试、发布,1 个页面就有至少 10 x 100 = 1000 次页面的搭建、配置、数据绑定、投放排期工作要做,而 1 次大促至少有 1000+ 页面,而上述工作就要做 1000 x 1000 = 100w 余次……针对阿里双11、双十二、年货节……一些列营销活动场景,仅依赖工具在一些局部领域的优化是很难处理好的。所以,面对较常规放大上千倍的场景,很多的问题就质变成一个新领域的问题:智能化创造全新前端生产力 。这是阿里前端的机会,也是我们这些前端工程师的机会。
前端智能化的顶层设计和核心任务

上一张图把 UI 智能化生成到应用的环节切分开了,切完后最终我们还是要聚合的。先揉碎再消化,消化后的产物叫做“前端智能化顶层设计”,这是三年来一直在布局并稳步推进的。
我们致力于构建能够支撑阿里整个业务体系的 UI 智能化资产,这是整个设计的核心。在处理和生产 UI 的背后,要有用智能化生成和智能 UI 推荐算法、智能设计生产技术升级、BizCook 和 UICook(鲸幂) 作为直接服务业务的技术产品迭代演进作为支撑,同时我们又要把智能 UI 生成、UI 推荐算法、智能设计系统变成通用能力和基础技术去服务更多的业务,让 UI 智能化资产在各业务场景中应用的同时,以数据为载体反向传递使用指标和使用情况形成闭环,驱动前端智能化体系成熟和完善。
前端智能化的两大核心任务
▐ 持续推进 UI 智能化资产建设,构建“质量可靠、安全稳定、生产经济、消费便捷”的 UI 智能化资产体系。
其中,生产经济和消费便捷是大家比较关心的问题。借助智能化生成的 D2C 能力和 S2C 能力,构建机器生产 UI 、交互逻辑和业务逻辑的能力,降低 UI 的生产成本,是谓“生产经济”。今天整个阿里不同的业务发展的节奏不同、所处阶段不同,遇到的问题也不一样,所以便捷是相对的。就像齿轮一样,要咬合的更好,才能更好地共同往前走。对于市场探索的 X 业务,“消费便捷”的关键应放在开箱即用上,要最大程度降低接入和使用成本、提升接入和使用效果。对于市场扩张的常规业务,“消费便捷”的关键应放在客制化能力和开放上,支撑业务在满足复杂的用户和业务需求时,能够按需定制,同时,给予技术人员定制自己业务平台和技术工程体系的机会。

智能 UI 资产
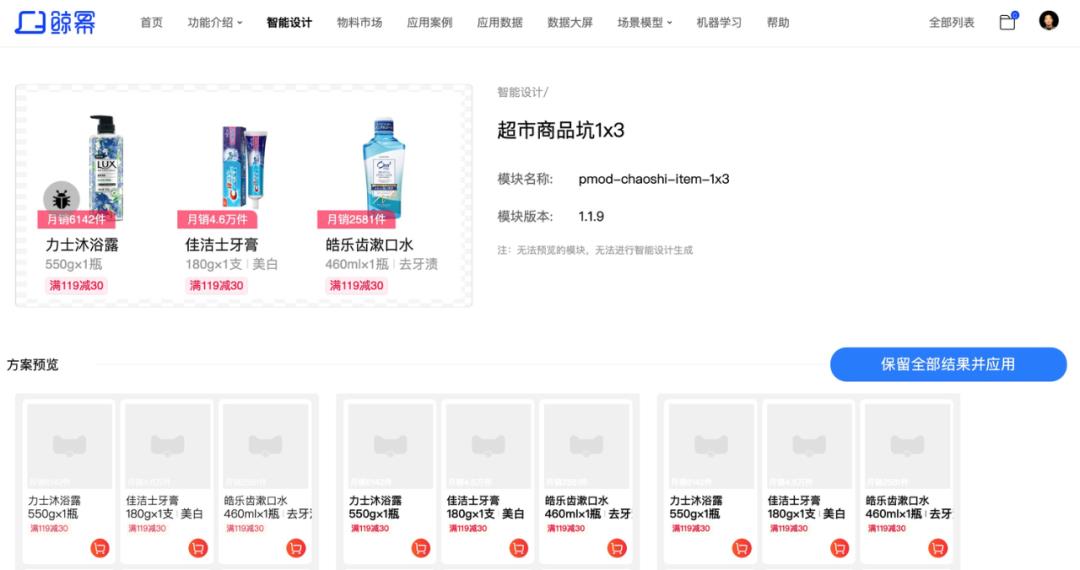
智能设计生成

智能 UI 设计模板
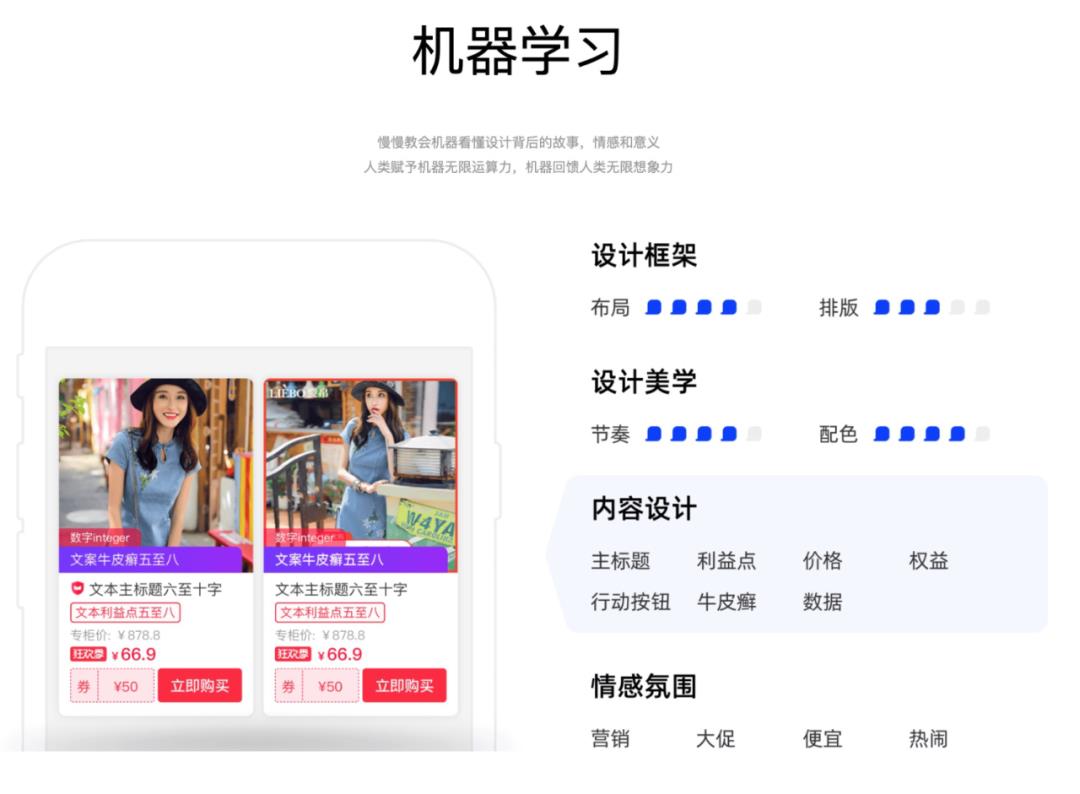
▐ 沉淀智能化技术和产品能力,赋能业务智能化到智能业务化,释放技术及组织红利,驱动业务增长。
一些客户和业务方经常会问一个非常哲学的问题——什么叫“业务智能化”以及什么叫“智能业务化”。针对这个问题事实胜于雄辩,要基于场景去解释、去获得体感。简言之,这个任务的目的是希望通过一系列的产品矩阵和技术的矩阵,能够把这些产品和技术融到业务的体系里面去,而不是单纯从技术视角去定义一些技术产品。
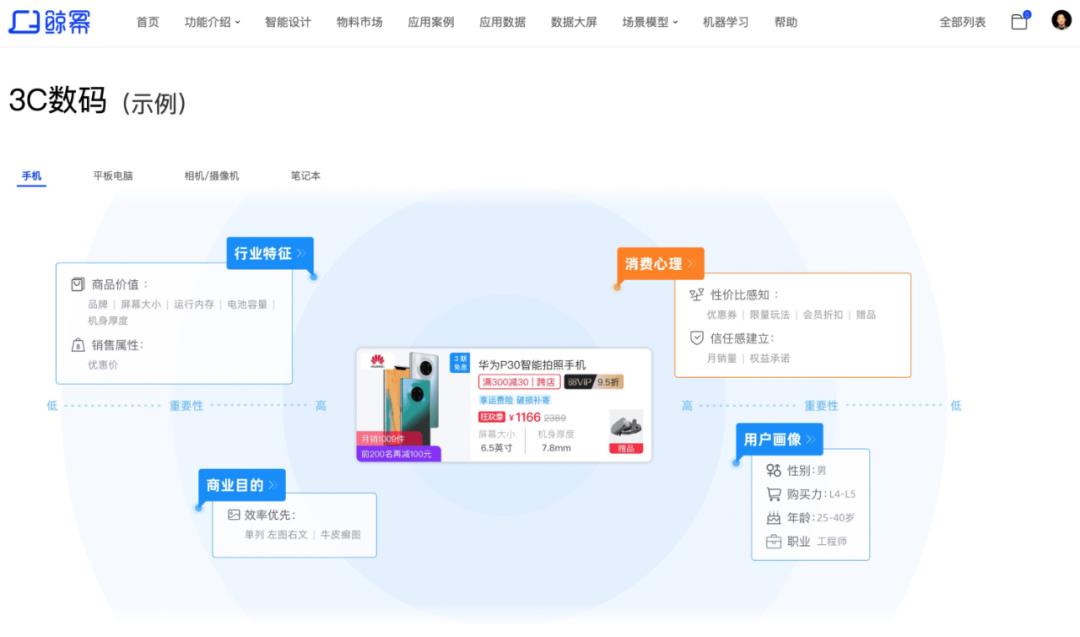
智能 UI 业务定制

智能 UI 应用

方法论+工具+组织——构建基本理念和落地公式

▐ 方法论:业务指标驱动的产品定义、技术生成、运营使用的业务研发模式
就像做开发一样,任何一套框架背后还是有一套基本的思想,思想背后有一套完善的理论体系,没有理论体系指导,我们无法在未来的复杂场景或者是在一些多变的场景中去抽象和裁剪。前端智能化技术&业务体系也一定有一套理论来支撑它:业务指标驱动(BizCook)、产品定义(BizCook & 鲸幂)、技术生成(P2C、D2C、S2C)、运营使用(小二工作台)四个部分组成。
首先,什么是业务指标驱动(BizCook)?今天阿里有淘宝、天猫、聚划算等很多业务,业务指标定义也很多样,即使指标是统一的,但是如果大家的业务场景都不一样,对用户活跃的定义理解也会不同,比如天猫 U 先的活跃要求用户领样品,而淘宝逛逛业务的活跃要求用户浏览内容和关注等。因此,业务指标的定义需要在各自业务场景中。而驱动则不然,可统一用聚焦(定义)、透明(传递)、迭代(执行)的模式。只有目标场景化、驱动统一了才能真正实现有效的业务研发模式升级,产生化学反应裂变或者衍生出更多的商业可能性。
其次,产品定义 (BizCook & 鲸幂)。产品定义是针对核心产品要素:UI 智能化资产,把各个场景里面,大家对该要素的各定义和理解抽象到一个共识的公约数:能够让每个场景中既有标准性,又能够兼顾灵活性,体验一致性上提供个性化。UI 智能化资产是数字化商业很重要的产品基础设施。就消费而言,一个产品可能会有超过二十个场景,一个场景会有数十个生活时空维度,一个维度会对应数百个圈层的用户,只有借助 UI 智能化资产,才能把产品定义好,让用户在自己兴趣偏好和习惯之下,体验到数字化商业的价值。由此,技术人员就能够和设计人员一起持续的用算法、数据资产进行融合,最终去还原我们对消费者的理解。当然,这是在安全隐私合规的前提下进行的,并且在前端智能化的端智能领域,将其规范化到统一的产品设计和定义领域去,保护用户隐私下传递抽象用户特征和场景特征的向量数据。
第三个是技术生成(P2C、D2C、S2C)。算法和数据在一起打造 UI 智能化资产,是为了 Service 。不提供服务的技术,就只有成本,也感觉不到技术的价值。UI 智能化资产的供给由服务驱动,再借助各业务的技术团队场景化、定制化落地,从而产生 UI 智能化资产的上层消费和底层供给之间的咬合。同时,从消费侧收集和回流数据,用指标驱动技术生成体系有目标且高效的迭代和成熟。
最后,是运营使用(小二工作台)。在业务指标驱动下,产品(产品力)、设计(设计力)和技术(业务力)共同协作,交付的只是产品的定义。这就像面向对象编程里,我们定义一个杯子:
交付产品定义:
class 杯子 {
init(材质、高度、直径……『运营使用的路径在这里』){
材质处理(『运营使用的结果在这里!』)
}
func 材质处理(材质){
if(材质==水晶){
1、检查水晶库存
2、测算水晶成本
3、……
……
}
}
}
运营使用:
『运营选品动作为例』
new 杯子(水晶、10cm、5cm……)『运营使用的起点在这里』
运营将产品、设计、技术围绕业务指标共同交付的产品定义:产品的可能性,例如材质可能是玻璃、也可能是水晶,运营再根据业务指标和库存、成本等状况决定,这次运营动作的具体参数是什么?
▐ 工具:产品及解决方案
有了理论之后,第二步是建立一套工具承接理论。理论很多公司都能讲,如果没有一套好的工具,去把这个理论承接,能让这个理论延续、演进和演化,这个理论是无法落地的,所以方法论背后必须有一套工具。
组织换了、业务变了、人员离职转岗了……,只有工具和技术能力的产品化,才能让我们这个体系不断地站在前人的肩膀上前进。在阿里场景里面,通过实践最后沉淀下来了一套基本的前端智能化工具矩阵,如下图:
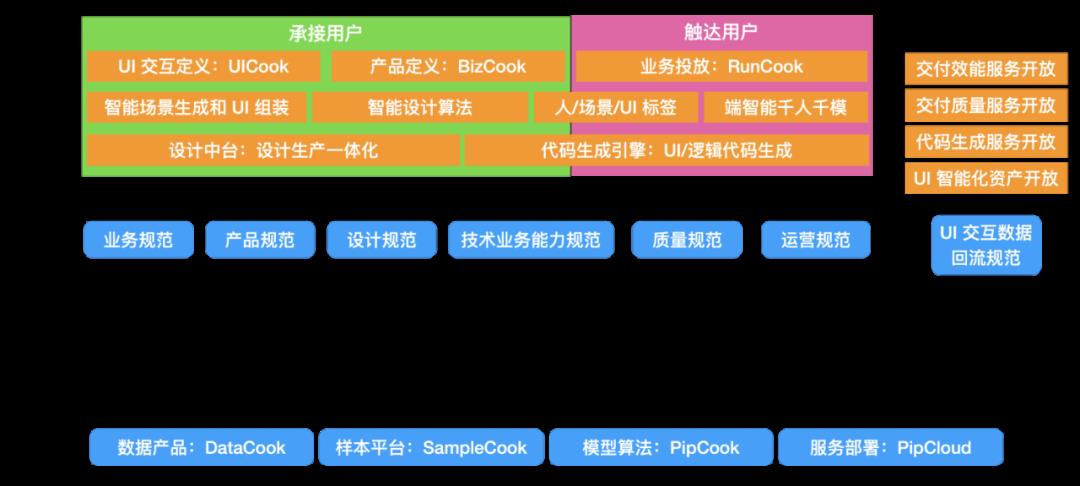
我们会用这些工具去服务阿里内部的各种业务,同时我们也会服务我们的商家和用户,为商家和 ISV 生态注入活力降低成本,为用户带来可预期、合品味、易使用的产品。
针对双十一等大促场景、营销产品和频道业务,用 UI 智能化资产统一实现“大促日常化”:降低大促的规划、设计、实施成本,统一实现“日常大促化”:用丰富的场景、人货场、个性化用户产品提高承接效率和业务效率,把日常的频道导购业务都变得像个“市集”。我们还会面向阿里巴巴集团全域 APP 矩阵进行业务投放,和流量场景深度结合,提升二环和三环媒体触达用户的频率和效果。借助 UI 智能化资产和相关的工具产品体系,打造业务敏捷创新的内功,和业务一起找到自己的方向和节奏,灵活应对市场变化和竞品威胁。
▐ 组织:让前端智能化真的运转起来
我们需要让这些工具能够和组织结合起来,能够和阿里现有的环境结合起来。举个简单的例子,就像每年双十一前都会进行的“0 研发”战役和鲸幂在智慧会场的应用,我们希望能够基于双十一这个场景,让大家熟悉这些产品、设计、生成技术和数据化运营能力的应用,从而更好的理解和消费 UI 智能化资产。通过不断学习和运用,让使用智能化高效、高质量和个性化解决问题成为大家的肌肉反应,称为工作中自然而然的一部分。
另外,在日常业务中,借助算法模型能力进行自动化概念的映射和翻译,减少新概念的引入,让业务、PD、设计师、运营小二和技术小二、质量小二都能够在自己熟悉的概念下,共同为业务指标负责。
除了方法论+工具+组织这三个结合起来,最终我们还需要一套体系机制,无论是业务体系、产品体系和设计体系,最有价值的部分往往都发生在交集,这个交集在方法论、工具和组织的支撑下,相互制约:任何局部创新都能够受全局其它体系约束,又能相互赋能:任何局部创新都能够向全局其它体系输送价值,还能孕育化学反应:跨界、跨领域、跨体系的全局性创新。
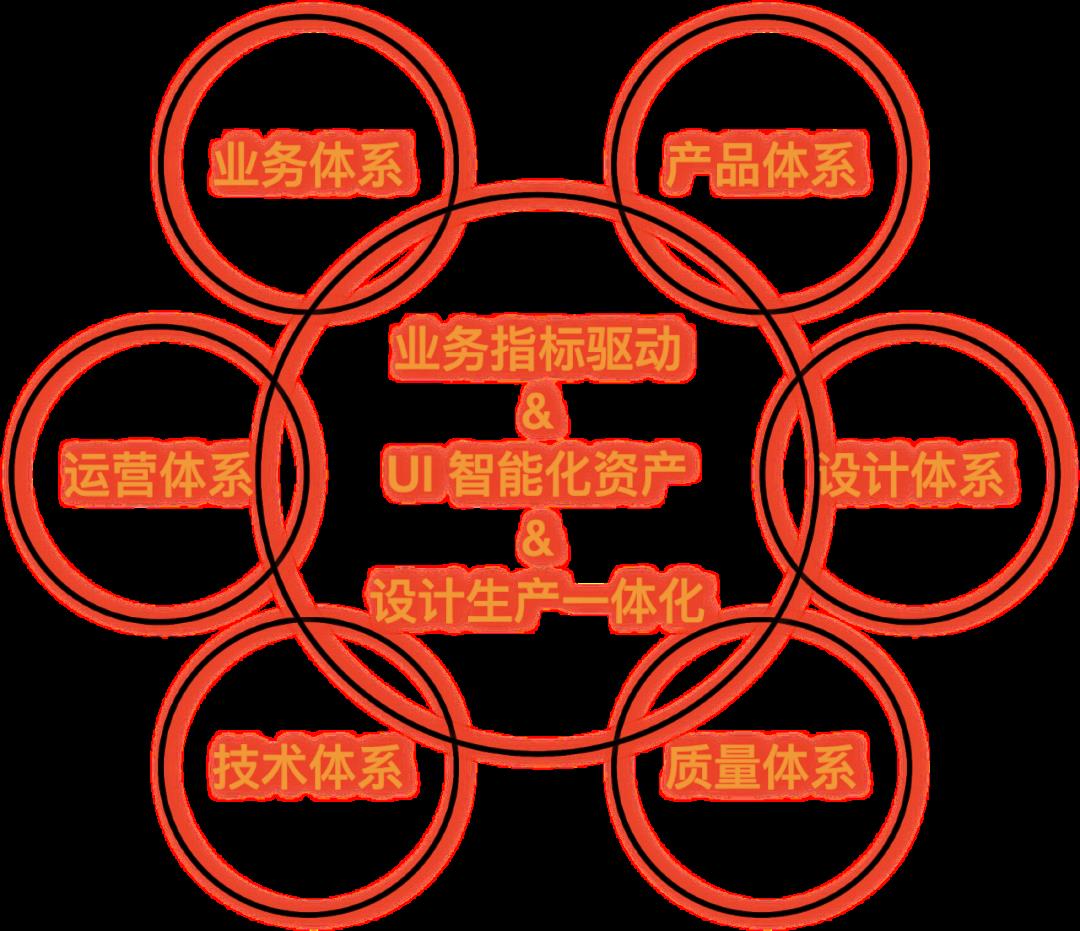
业务、产品、设计、技术——前端智能化的核心客户
做任何事情必须要有客户的视角,知道服务谁才知道要解决什么问题。前端智能化的核心客户和我们的发展阶段息息相关,在初期阶段,面向技术人员围绕“解决一线 C 端业务研发效率问题”构建“设计稿生成代码”的能力。在中后期,我们必须将技术能力赋能到业务升级为业务能力。面向业务人员围绕“解决业务缺乏用户产品抓手的问题”构建“透明、快速、直接干预业务”的能力。面向 PD 围绕“解决业务敏捷创新和快速试错的问题”构建“设计稿生成的代码之上所见即所得的需求标注即可交付上线”的能力。面向设计师围绕“解决设计规范执行难、设计创新研发成本高落地难的问题”构建“设计生产一体化”的能力。
运营使用未在我们的体系内定义成核心客户,因为,今天圆心领导的小二工作台,不仅完善的解决了招商、选品、投放……等一系列运营问题,构建了完整的数据化驱动运营的技术体系,还借助 PU 、SOP 编排的方式,帮助业务根据自己的需要进行定制,舒文领导的“诺亚”借助“方舟”在多年大促营销活动上沉淀的经验,进一步降低了小二工作台的使用成本,我们只需要在前端智能化赋能业务的过程中引入“诺亚”或其他 PU、SOP 能力即可服务好运营。
质量保障未在我们的体系内定义成核心客户,因为,今天清灵领导的质量保证体系在前端智能化初期就和我们在深度合作,从 ATS 自动化测试模块质量,到 TMQ 基于机器视觉和算法的自动化测试,都已经做得非常完善,并且,底层的技术体系和上层的开放能力都足以支撑我们“开箱即用”,保证两套体系的功能和体验的一致性,可方便的支撑好质量保障的同学进行质量验收和质量监控。
▐ 技术人员:C端业务研发效率问题
对于我们阿里来讲,技术人员是一个巨大的群体,C 端业务又是一个面向终端用户且复杂多变的场景,跨平台、需求变更、个性化是这些复杂多变场景的核心问题,他们共同要求“有一种消除重复劳动的技术”,否则,只能靠技术人员自身来填这个大坑。对于技术人员来说,跨平台、需求变更、个性化对技术而言并没有太大的挑战和创新,只是时间成本的问题:适配不同的平台、实现变更的需求、逐个开发不同的个性化承接产品,这些就是亟待消除的“重复劳动”。
只有深入研究跨平台的业务研发问题,我们才能准确的定义 RunCook 的功能,才能解决业务研发过程中对宿主环境业务能力的适配和降级问题。只有深入研究需求变更,我们才能准确定义 BizCook、imgCook、LogicCook 的功能,才能通过 NLP 的算法模型理解业务定义的指标如何被 PD 描述成需求、设计师又如何用设计语言来表达 PD 的需求、设计稿如何借助 imgCook 生成 UI和交互逻辑、UI 的内容及状态的变化如何借助 LogicCook 从 PaaS 上获取并实例化成 Node FaaS 的胶水层代码挂载在 UI 和交互逻辑之上。深入研究消费者,我们才能准确定义 UICook和鲸幂的功能,才能通过智能设计生产一体化、代码生成能力降低一线业务研发人员为不同圈层用户开发产品功能的成本,给消费者带来极致的产品体验。
▐ 业务人员
小芃在介绍数据中台的时候说:「 以观星台举例,逍遥子可以通过观星台看到全集团宏观的业务治理,这是一个最大的顶层的节点。再往下这个子节点,就是各个业务总裁和业务的矩阵,下面每个业务有自己业务数据的逻辑和数据决策的体系。再往下就是每一次的活动,或是一些节点,基本上形成了一个决策体系。我对这个观点深以为然,今天决策体系化才能让业务形成战斗力,然而,却有一些问题会阻碍这种战斗力的形成:执行。」
在技术产品里有一个生动的比喻:P9 的战略、P8 的规划、P7 的设计、P5 的执行,最后,一个好的思想和理论没有能够形成好的技术产品。为什么不能是 P9 的战略、P8 的规划、设计和执行呢?因为,信息在传递的时候会有损耗。通俗的理解就是:张大妈说你和女同学放学一起回家,李大婶说你和女同学谈恋爱,王大爷说你和女同学结婚了。信息论里研究信息的损耗,因为信号在介质中传递的时候会受到干扰,电信号在取值范围上下的波动未达到信号电压要求,从而导致信息的一些编码丢失,李大婶和王大爷自身的偏见就是导致信息损耗的干扰。下面,借助一些信息论里的知识谈谈服务业务人员过程中如何抗干扰?
优化业务指标编码
谈到信息论,就离不开编码。谈到信息论就离不开传递信息,传递信息的过程需要对信息进行编码,而如何用最少的编码表示所要传递的信息就是我们要研究的目标了。
假设两地互相通信,两地之间一直在传递A,B,C,D四类消息,那应该要选择什么样的编码方式才能尽可能少的使用资源呢?如果这四类消息的出现是等概率的,都为四分之一,那么肯定应该采用等编码方式,也就是
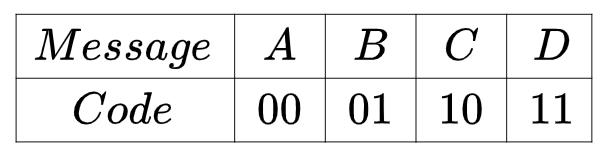
这样就能达到最优的编码方式,平均编码长度为 。
。
但是,如果四类消息出现的概率不同呢?例如 A 消息出现的概率是二分之一,B 是四分之一,C 是八分之一,D 是八分之一,那应该怎样编码呢?直觉告诉我们,为了使平均编码长度尽可能小,出现概率高的 A 消息应该使用短编码,出现概率低的C ,D 消息应该使用长编码。与等长编码相比,这样的编码方式叫做变长编码,它的效果更好,例如采用下表所示的编码(其实这是最优编码)
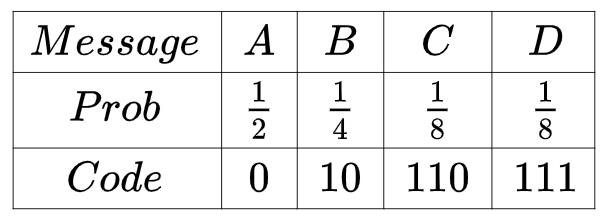
平均编码长度为

显然要优于等长编码。
业务同学决策依据的数据指标有大量的歧义和冗余,这就需要有一套编码机制有效的对业务指标进行编码,保证在决策信息传递的过程中更精确、有效,因为,信息冗余越多损耗的概率就越大,编码的有效性越差,编码的冗余信息就越多。我们在 BizCook 上重新构建 C 端业务研发的指标体系和其编码方式,对指标包含的信息进行有效编码,是决策信息有效传递的第一步。
度量业务指标损耗
若现在还有一种消息序列的概率分布满足 q 分布,但是它仍然使用 p 分布的最优编码方式,那么它的平均编码长度即为

其中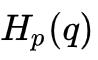 被称为 q 分布相对于 p 分布的交叉熵(Cross Entropy),它衡量了 q 分布使用 p 分布的最优编码方式时的平均编码长度。
被称为 q 分布相对于 p 分布的交叉熵(Cross Entropy),它衡量了 q 分布使用 p 分布的最优编码方式时的平均编码长度。
交叉熵不是对称的,即 。交叉熵的意义在于它给我们提供了一种衡量两个分布的不同程度的方式。两个分布 p 和 q 的差异越大,交叉熵
。交叉熵的意义在于它给我们提供了一种衡量两个分布的不同程度的方式。两个分布 p 和 q 的差异越大,交叉熵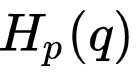 就比
就比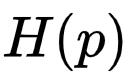 大的越多,如图
大的越多,如图

它们的不同的大小为 ,这在信息论中被称为 KL 散度(Kullback-Leibler Divergence),它满足
,这在信息论中被称为 KL 散度(Kullback-Leibler Divergence),它满足 。
。
KL散度可以看作为两个分布之间的距离,也可以说是可以衡量两个分布的不同程度。
对于业务的同学,围绕自己两三个核心目标层层拆解下去的业务指标也有 q 和 p 的分布,我们可以在 BizCook 上根据交叉熵来衡量实际:产品、设计和技术在承接这些指标时候的偏差程度,也可以在 BizCook 上利用 KL 散度来判断决策指标在承接过程中的信息损耗。
分析业务指标关联
和单变量相同,如果有两个变量 X,Y,我们可以计算它们的联合熵(Joint Entropy)

当我们事先已经知道 Y 的分布,我们可以计算条件熵(Conditional Entropy)

X 与 Y 变量之间可能共享某些信息,我们可以把信息熵想象成一个信息条,如下图:
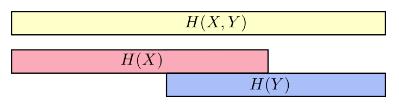
从中可以看出,单变量的信息熵H(x)(或H(Y))一般比多变量信息熵
H(X,Y)要小。如果把条件熵也放进来,那么可以从信息条更清晰的看出它们之间的关系

可以看出
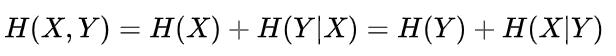
更细一点,我们把H(X)与H(Y)重叠的部分定义为 X 与 Y 的互信息(Mutual Entropy),记作I(X,Y),则 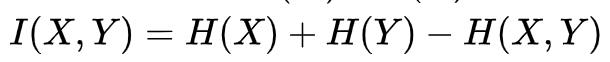 。互信息代表了 X 中包含的有关于 Y 的信息(或相反)。
。互信息代表了 X 中包含的有关于 Y 的信息(或相反)。
将 X 与 Y 不重叠的信息定义为差异信息(Variation of Information),记为
V(X,Y),则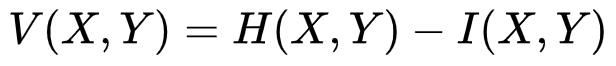
差异信息可以衡量变量 X 与 Y 的差距,若V(X,Y)为0,就意味着只要知道一个变量,就知道另一个变量的所有信息。随着V(X,Y)的增大,也就意味着 X 与 Y 更不相关。形象化的表示可以从下图看出
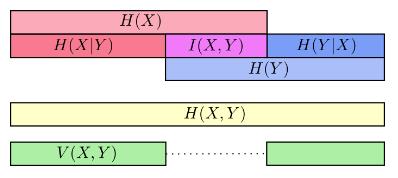
对于业务的同学来说,可以很容易通过互信息来衡量:产品、设计、技术承接自己的决策时,其指标和自己目标之间的关联度,BizCook 可以借助互信息和差异信息来进行度量,从而帮助业务同学解决目标落地执行的偏离问题。
由于业务决策被编码成业务指标,业务生产指标被编码成产品指标、设计指标、技术指标,借助前端智能化的生成技术体系,决策和执行将前所未有的统一,而不再是割裂的,由此,BizCook 解决了“张大妈说你和女同学放学一起回家,李大婶说你和女同学谈恋爱,王大爷说你和女同学结婚了。”这个信息损耗的问题。
▐ 产品和设计人员
和 B 端业务不同,在 C 端业务里,因为大部分情况设计直接决定了 UI 的视觉和交互,UI 的视觉和交互又是 C 端业务非常核心的部分,因此,产品和设计多数情况下是共同定义产品的功能的,可以放在一起说。
产品定义产品的工具是:需求文档,设计定义产品的工具是:设计稿、交互稿,这两者都是在描述:什么用户?在什么场景?看到什么?做什么?只是,需求文档在视觉方面更加抽象、功能层面更加具体,而设计稿、交互稿在视觉方面更加具体、功能层面更加抽象,结果,PD 和设计师一合计,干脆合一起吧!于是,平常在生产过程中拿到的设计稿大多是酱紫的:

这个视觉和功能二合一的描述方式,怎一个“赞”字了得?简单清晰,把设计和产品功能完美的融合在一起,一目了然。既然 PD 和设计师都喜欢这样的产品定义描述方式,我们何不在前端智能化领域吸收借鉴一下呢?于是,有了“基于设计稿生成代码所见即所得的产品定义”能力在 BizCook 上诞生,在继承了 imgCook 设计稿生成代码的基础上,扩展了 LogicCook 的业务逻辑代码生成和推荐,让 PD 和设计师在定义产品的过程中就完成了 MVP 并可以上线灰度进行小批量产品验证。
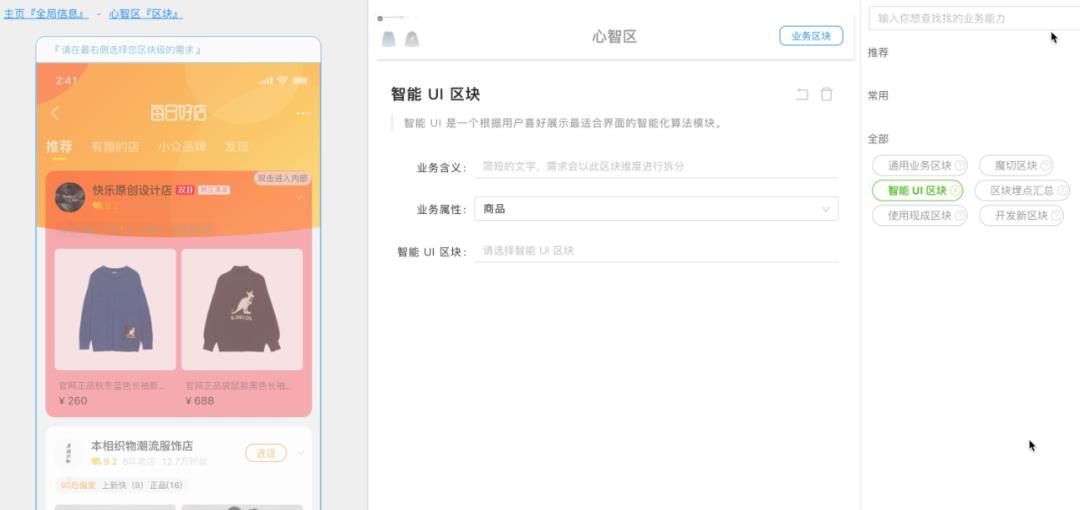
可以从上图看到,左侧预览区域的内容都是 imgCook 通过设计稿生成的,PD 可以在这个基础上选择一个区块去定义这个区块承接什么业务?完成什么关联业务指标?功能上有什么约束?要怎样提供个性化服务?……从定义业务到子业务、到页面、再到一个区块层层递进,把定义产品的过程和业务决策、业务指标无缝连接在一起。
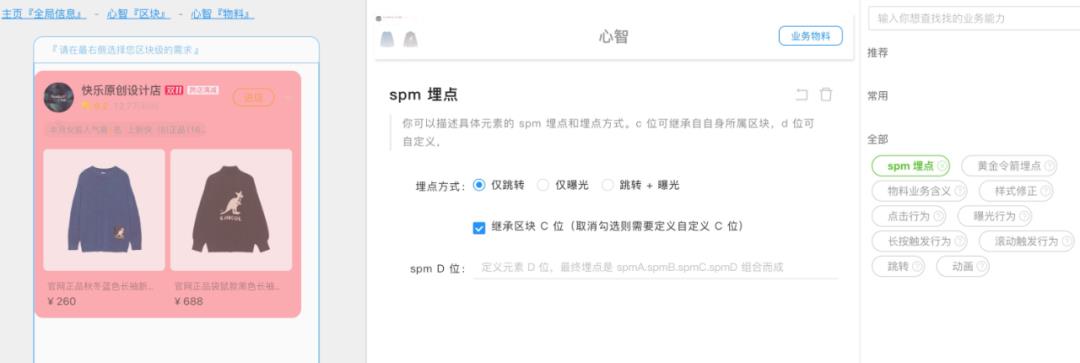
所以,BizCook 服务产品和设计这两个核心客户的时候,首要原则就是符合 PD 和设计师的工作习惯,用 PD 和设计师熟悉的概念描述产品的定义和业务的功能,不额外引入新概念,也坚决不用晦涩难懂的技术概念。这样,不仅能够让产品定义“高度保真”,还能够极大将降低 PD 和设计师理解和使用的成本。
总结和展望
从最初服务一线研发人员,到后来的服务于产品和设计人员,再到未来服务于业务人员,这个路线背后的思考是:在技术领域围绕效率创新,必须逐步过渡到生产,再进入业务领域进行升华。脱离业务、生产单纯在技术领域里兜兜转转,是制约大部分技术人向上发展的王屋和太行。
仰望星空再回到现实里脚踏实地,必须清醒认识到:技术向生产乃至业务领域过渡是一个复杂且漫长的过程。进入生产领域需要大局观和架构能力,进入业务领域需要全局观和商业能力,不去改变和提升自己,终是画虎画皮难画骨,形似而神不在。
大部分同仁,在听过、见过甚至部分实践过后,仍会觉得云里雾里,初时,觉得头头是道,做时,觉得千头万绪。总的来说,我认为缺的是内观、俯察。所谓内观,要求我们向自己找原因,真正有价值的东西是方案和成果背后的思考,是无法通过表象所感应、知觉、理解的,这就像两个音叉,敲响一个另一个谐振的原因是这两个音叉的质地一致,我们在无法跟别人的观点产生共鸣的大部分情况是自己的质地无法和别人观点背后的质地一致而已,去修炼自己即可。所谓俯察,要求我们向脚下之路找原因,不要好大喜功、好高骛远,要清楚自己迈出的每一步:轻了?重了?快了?慢了?甚至要进行逆察,不断审视过去的每一步。
今天的前端智能化,在技术上有点儿小成绩,同时也有很多问题。今天的生产领域、业务领域拓展尝试,在结果上有点儿小业务效果,同时也有很多过程上乃至源头能力上的缺失和不足。这就需要我们仰观俯察,既要看到大方向、大趋势、大战略,又要看到小闭环、小问题、小细节。从大处着眼、小处着手,把 UI 智能化资产并前端智能化易学、易用落到实处,解决一线业务研发过程中的实际问题。
为此,我们把未来的发展具象化到一些大方向、大趋势、大战略上,同时,拆解到类似“开箱即用的算法”、“业务上取得实际效果”……等一系列小闭环、小问题、小细节中去。在教授(展炎)的指导下,新财年里设立“用户体验升级”这个主题,来聚焦我们要解决的问题,把前端智能化落到实处:

由此,设定我们的 OKR (还是讨论版)去约束我们的发展方向和发展目标,给出一个清晰明确的路径:
面向场景和人群的视觉设计智能化
KR1:基于 UI 交互的场景、人群标签扩展2~3倍,准确率达到 80% 以上
KR2:基于 UI 交互的场景、人群理解算法自动化生成用户承接 UI
KR3:利用设计中台打通智能 UI 和智能设计两大体系,实现高质量方案自动化生成
人机交互方式的智能化
KR1:端侧模型和服务端算法模型能力协力实现 UI 的个性化呈现,提升用户粘性
KR2:基于算法对用户的理解,以用户任务驱动 UI 组装和交互路径决策,提升用户交互的有效性
KR3:用端侧算法模型能力开拓新的用户交互方式和用户承接场景,用新奇特智能人机交互驱动用户体量增长
降低面向上述场景下的前端应用门槛
KR1:达成智能 UI 生成能力和智能 UI 推荐算法、端智能模型优化和下发的开箱即用
KR2:用 PipCook 降低前端学习、应用、部署机器学习算法的成本
KR3:外派专家辅导和共建的方式,融合前端算法课程培训,带动集团前端应用算法在业务中创新
期望在新的一年,我们能够建设好我们的数据、标签、算法、物料…… UI 智能化资产,还能够继续把我们的生产能力进行升级,同时,借助 PipCook 降低前端应用门槛,让前端智能化对阿里集团每个前端普惠和开放。同时,也期望每个参与前端智能化的同仁,都能够在自己的业务场景中,用自己的慧眼去发现更多因机器学习、算法所带来的技术、工程乃至业务的可能性,用自己的智慧并前端智能化一起,给业务创造更多属于阿里前端的价值!共勉!
✿ 拓展阅读




作者|甄子
编辑|橙子君
出品|阿里巴巴新零售淘系技术


以上是关于2021前端智能化发展现状与未来展望的主要内容,如果未能解决你的问题,请参考以下文章