21 意境级讲解 共指消解的方法
Posted 炫云云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了21 意境级讲解 共指消解的方法相关的知识,希望对你有一定的参考价值。
共指消解的目标是要找出文中指代相同的代指,指的是在一短文本内多个代指都是指向现实世界中的同一个实体。
1 Coreference Resolution 共指消解
1.1 Winograd Schema Challenge 威诺格拉德模式挑战赛

Winograd Schema Challenge 威诺格拉德模式挑战赛,它的诞生是为了取代图灵测试,因为现在很多模型都声称已能够通过图灵测试骗过人类了,但其实大多数都是使用一种话术来欺骗人类的,它根本没有理解语言,只是相当于接话。在此问题下,本挑战赛诞生希望模型可以解决更复杂的任务,如共指消解。
上图所示,”这个奖杯在棕色行李箱中放不下因为它太大了。是什么太大了?“ 和 ”这个奖杯在棕色行李箱中放不下因为它太小了。是什么太小了?“,对于人类而言,这两个指代问题,很容易解决。但对于机器而言,这个共指消解任务是很困难的,甚至机器需要对这个物理世界有一定的理解才能解决这个问题。
1.2 scene 场景
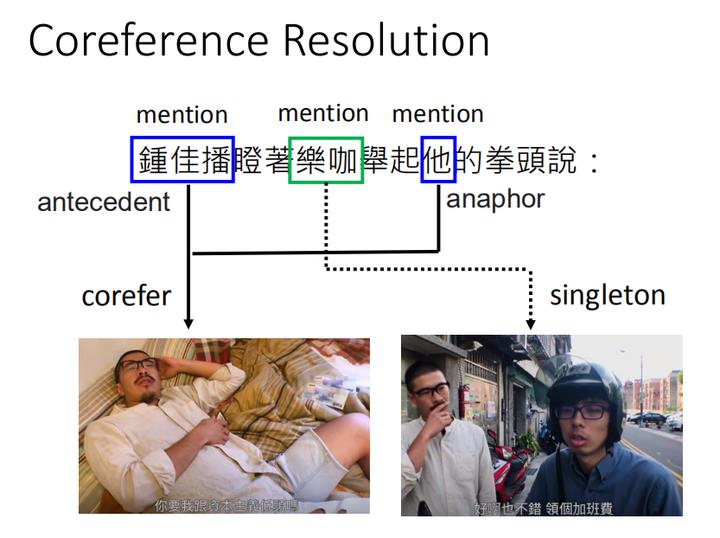
其实,对于人类而言,当我们在说一段句子的时候,而我们其实是在对方心里面建立一个场景的,会有一些文字片段去指代这个场景里的实体。
如上图,我今天对你说”钟佳播瞪着乐咖举起他的拳头说“,你会知道这个世界上有一个人叫做”钟佳播“,还有另一个人叫”乐咖“,他们之间发生了一些事请,这个构建场景的词汇就叫做mention(代指)。如果两个mention指的是同一个实体,如本例中的”钟佳播“和”他“都指的是同一个人,这种现象就叫做corefer(同指),而把这个corefer找出来的过程就叫做 Coreference Resolution。如果这个mention只出现一次,就叫singleton。有指代关系的两个词,先出现的叫做antecedent先行词,后出现的叫做anaphor 回指词。
1.3 Task Introduction 任务介绍

其实在 Coreference Resolution 指代消解任务中,是有两个任务目标的:
- 标注出全部的mentions(有时,不需要标注出singletons)
- 将mentions分组聚类,同一组的mentions指的是同一个代指
这样的训练任务是不包含在之前讲的八大类经典NLP任务,因此解法也比较不同寻常。有时 mention 的定义是比较模糊的。一般我们会有一个语料参照,要把哪些作为 mention,哪些忽略。
同学问答环节:
-
提问:如果是cluster有重叠,那该怎么打标签?就是分组会不会有重叠
回答:不会有重叠,如果今天又加了一个句子,”他们是好朋友“,这里的他们又会是一个新的组 {他们,钟佳播,乐咖}。
-
提问:找mention的过程与NER命名实体识别会有点像
回答:是也不是,如果是NER的话,只要找出所有的mention就可以了。但是没办法像上图所示,标记出mention间的覆盖关系,如图的下划线,就是”他“和”他的拳头“都是mention。
-
提问:anaphor,有指代关系的后出现的词一定是代词么
回答:不一定的,如上图的”它不锤倒高墙“改为”人民的法槌不锤倒高墙“,那么此时的第二个组Cluster 2就由{他的拳头,它,它}会变为{他的拳头,人民的法槌,它}
那我们究竟怎么通过“硬train一发”的方法来解决上述的两个任务目标呢?
2 模型框架
2.1 找出mention
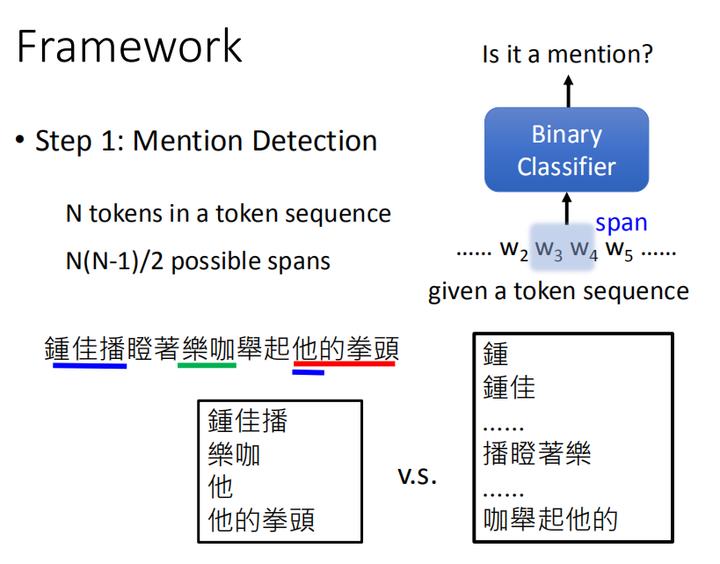
首先,先考虑任务目标1:找出所有的mention。
其实,这就是一个二分类的问题,我们将N个tokens的sequence序列,依次取其中的一小段span进行二分类检测。但请注意,我们选取的是一小段,而非一个一个的token去做二分类检测,如果仅仅使用单个token去判断是否包含在一个mention里面是不行的,因为这样就没办法考虑到mention间的叠加关系,如“他的拳头”是一个mention,而“他”也是一个mention这样的组合mention。所以我们只能判断整个span。
具体而言,对于N个tokens组成的序列,我们会进行 C n 2 C_{n}^2 Cn2 的取法,每一次取两个token作为span一小段的首尾,将这两个token间包括这两个token组成的span段进行二分类的判断是否为mention,因此需要判断 N ( N − 1 ) 2 \\frac{N(N-1)}{2} 2N(N−1) 个spans。
而在训练时,我们是已经有 有标注的数据集,知道一个序列中,有哪个token会是mention。将那些是mention的作为label标签=1的正样本,将那些不是mention的作为label标签=2的负样本进行训练。
2.2 判断哪些mention对指同一个实体
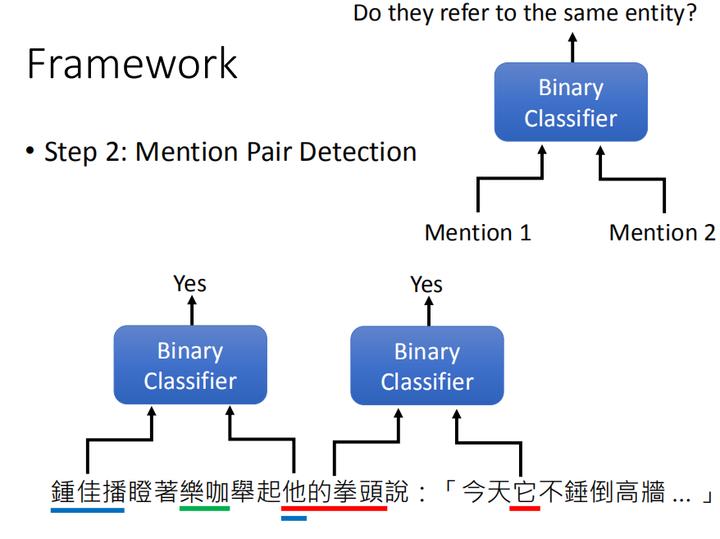
除了找出所有mention这一任务目标外,对于任务目标2:找出哪些mention是同一组的。 这一样是个二分类问题,此时二分类器的输入不再是一个,而是两个mention,去判断这两个mention是否是同一个实体,也就是说是不是该放在同一组里。
对于这句话“钟佳播瞪着乐咖举起他的拳头说:【今天它不锤倒高墙】” 例如,如上图,“钟佳播”和“乐咖”这两个mention作为输入时,将输出No。“钟佳播”和“他”这两个mention作为输入时,将输出Yes。
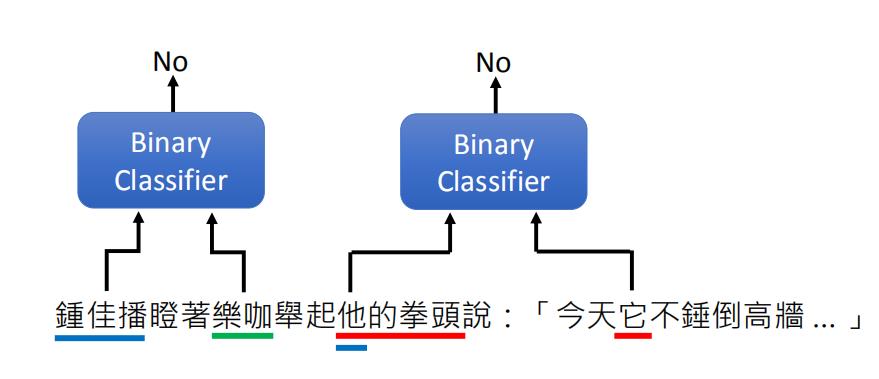
同样,如果我们从上一个训练任务中,得到了K个mentions,那么我们就需要判断 K ( K − 1 ) 2 \\frac{K(K-1)}{2} 2K(K−1) 次的二分类。
2.3 End-to-end 端到端
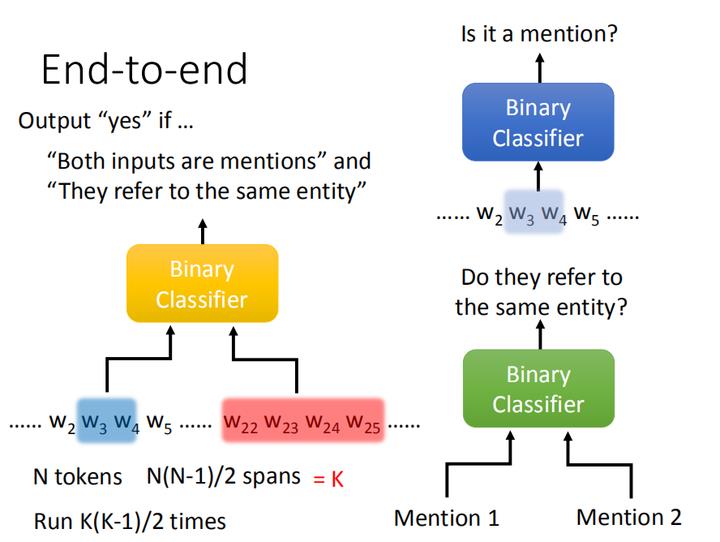
按照上面的任务目标,分成两个步骤还不能算今天的“硬train一发”的端到端模型架构。我们也要把这两个二分类器组合在一起成为一个二分类器,这样就是一个模型的训练问题了。
具体而言,这个二分类器的输入是两个span段,判断这两个span是否都是mention,这两个mention是不是指的都是同一个实体,如果这两点都满足才能输出Yes,否则No。也就是说即使这两个span都是mention但不属于同一个实体,那也是输出No的。
同样,如果我们有N个tokens,也就有 N ( N − 1 ) 2 \\frac{N(N-1)}{2} 2N(N−1) 个spans,并假设这个数值就是K。接下来,我们要在这K个span里两两抽取,会抽 C K 2 C_{K}^2 CK2 次,也就是说这个二分类器会运行 K ( K − 1 ) 2 \\frac{K(K-1)}{2} 2K(K−1) 次,时间复杂度大约是 O ( N 4 ) O(N^4) O(N4) 。
2.4 Training 训练
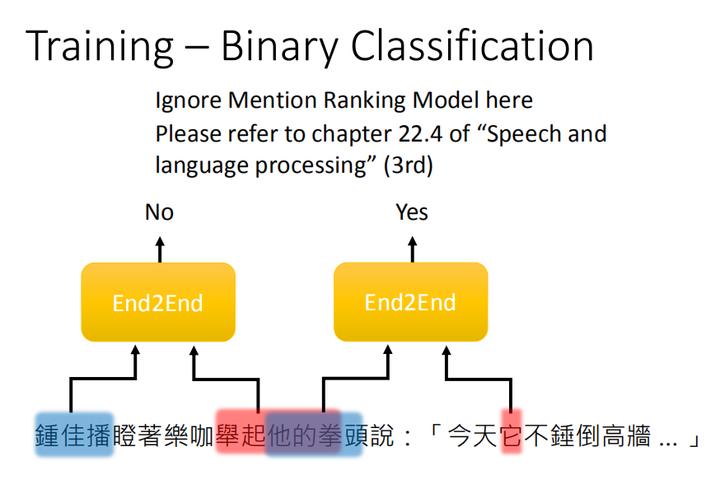
在训练时,我们只需要依次放入两个spans到二分类器中进行判断,如果这两个span都是mention且指的是同一个实体,就输出Yes。
其实,这里是省略了一个 Mention Ranking Model,如果真的像把指代消解做好的话,是不能仅仅把它当作一个二分类问题,是要把它当作一个Ranking的问题来看。但本门课的重点不是要如何得到一个最好的指代消解模型,而是如何通过深度学习“硬train一发”解决问题的过程。
2.5 Binary Classifier 二分类器
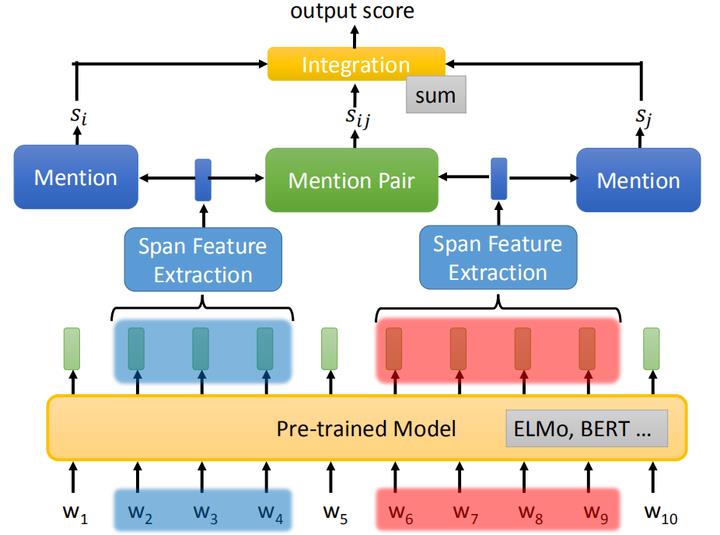
那我们刚刚一直说的二分类器究竟长什么样呢?如上图,
给一串 token 序列,起手都是先丢给一个预训练模型,如ELMo或者BERT,得到每个token的embedding表示。
接下来,再对这串embedding进行抽取span,这个抽取span的就叫Span Feature Extraction,通过这个span抽取器会把这一段embedding汇聚成一个向量表示,等下再讲这个span抽取器是什么。
然后,还会有一个模块二分类器,判断一个向量是否是一个mention,并给出这个向量是mention的可能性分数,如上图的 s i , s j s_i,s_j si,sj 。
之后,还会有一个模块(Mention Pair )判断两个spans是否是指同一个实体,并输出一个分数 s i j s_{ij} sij 。
最终,将这三个分数组合起来,这里的组合方式有很多种,可以考虑再训练一个DNN或者就直接简单的相加,这个组合起来的分数就是这个二分类器最终的输出。
如果是Mention ,并且有共指关系,着分数越大,其他分数越小。
2.6 Span Feature Extraction Span提取器
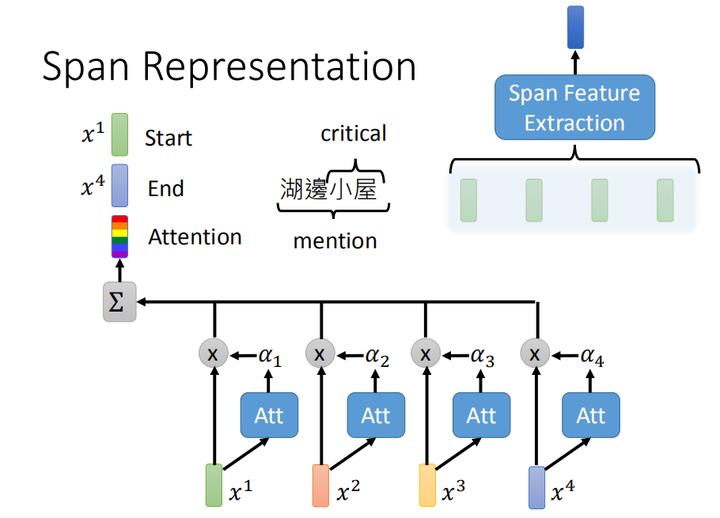
接下来,让我们看一下 Span Feature Extraction 是怎么做的,当然在实作上有各种做法,不过在指代消解任务中,常见的一种做法如上图。
假设我们有一个4个embedding组成的序列 x 1 , x 2 , x 3 , x 4 x_1,x_2,x_3,x_4 x1,x2,x3,x4 我们会将这4个embedding做加权求和,其中权重参数 α 1 , α 2 , α 3 , α 4 \\alpha_1,\\alpha_2,\\alpha_3,\\alpha_4 α1,α2,α3,α4 是根据attention训练得到的。再把首尾embedding x 1 , x 4 x_1,x_4 x1,x4 和加权求和得到的embeddiing,这三个串起来就是 Span Feature Extraction 的输出。
2.7 Practical Implementation 简化运算
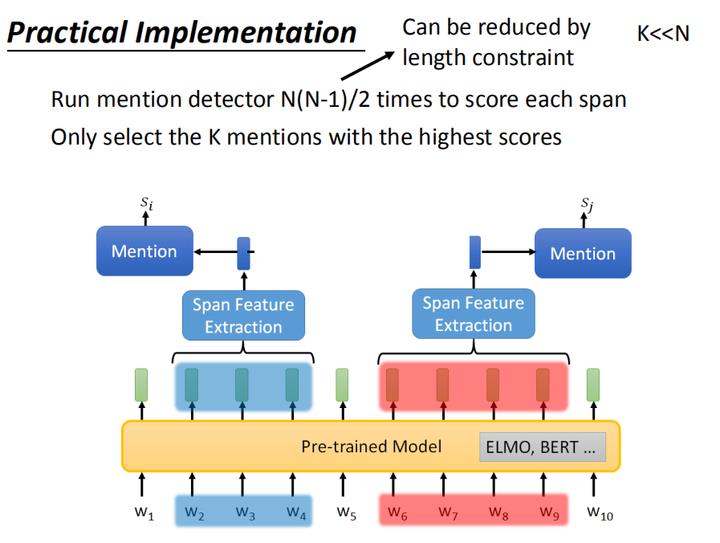
如果在实际应用中,真的按照2.3端到端模型的训练方式进行训练的话,时间复杂度大约是 O ( N 4 ) O(N^4) O(N4),是有点过大的,那我们能不能简化运算,加快训练速度呢?
其实,在训练整个端到端模型的时候,其中有一部分是mention detection Mention抽取,为了减少运算量,我们可以先做Mention的抽取,先跑 N ( N − 1 ) 2 \\frac{N(N-1)}{2} 2N(N−1) 次,并仅选取最高分K个mention(如上图所示)进行两两的判断是否指同一实体,且有K<<N,因此可以大幅减少运算量。
另外一个减少运算量的方法是限制mention的长度,假设mention长度最多不能超过10个tokens,这个时候比对两个token是否指同一个实体的时间复杂度就不是 O ( N 2 ) O(N^2) O(N2) ,而是 O ( 10 ∗ N ) O(10*N) O(10∗N) 了
3、方法
End-to-end
图1:端到端共指消解1模型的第一步,该模型计算span 的嵌入表示 (4),以便对潜在实体mention计算分数
s
m
(
i
)
s_{\\mathrm{m}}(i)
sm(i)。对得分较低的范围进行修剪,以便只考虑一定数量的范围用于共指链接对。一般来说,该模型考虑到最大宽度的所有可能的span ,但我们在这里只描述了一个小子集。
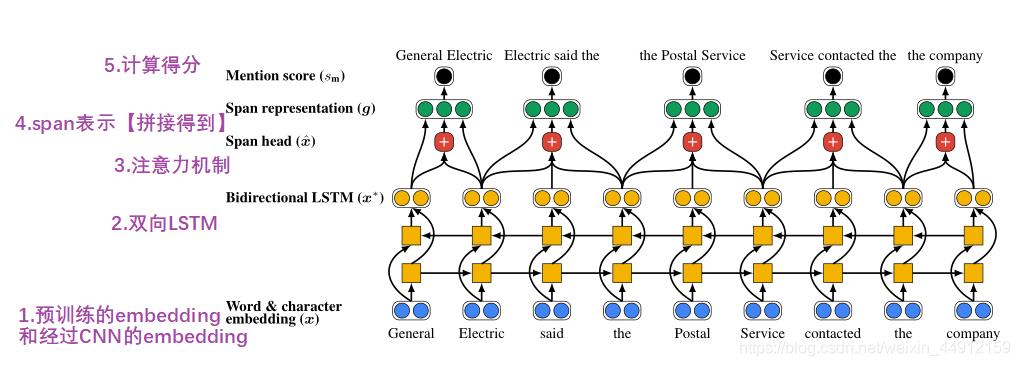
图
1
图1
图1
图2:模型的第二步。先行词分数是从对span 表示中计算出来的。通过将两个span 的mention 分数和它们的成对先行词分数
s
a
(
i
,
j
)
s_{\\mathrm{a}}(i, j)
sa(i,j) 相加,计算出一对span 的最终共指分数
s
(
i
,
j
)
s(i, j)
s(i,j)。根据最大似然估计给出消解结果。
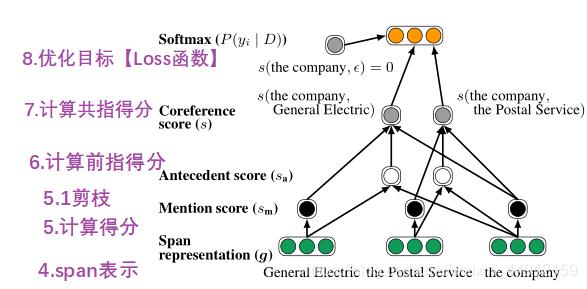
图
2
图2
图2
假设对于某个文档表示为 D,文档中有 T 个word,文档中就有N个可能的span
N
=
T
(
T
+
1
)
2
N=\\frac{T(T+1)}{2}
N=2T(T+1)。
分别用start (i)和end (i)表示跨度的开始和结束索引 1 ≤ i ≤ N 1 \\leq i \\leq N 1≤i≤N 。我们假设根据START(i)对跨度进行排序;具有相同起始索引的跨度按END(i)排序。
任务是给每个span i i i分配一个先行词 y i y_{i} yi。每个 y i y_{i} yi可能的赋值集合是 Y ( i ) = { ϵ , 1 , … , i − 1 } \\mathcal{Y}(i)=\\{\\epsilon, 1, \\ldots, i-1\\} Y(i)={ϵ,1,…,i−1},一个假的的先行词 ϵ \\epsilon ϵ和所有前面的span。span i i i 有先行词即span j j j,其中 1 ≤ j ≤ 1 \\leq j \\leq 1≤j≤ i − 1 i-1 i−1表示 i i i和 j j j之间的共指链接。假的先行词 ϵ \\epsilon ϵ表示两种可能的情况:
(1) 某个span本身不是一个实体的mention【代指】
(2) span是实体的提及,但没和之前的span形成共指
- 目标:使用条件概率分布,使得最有可能的共指簇概率最大:
P ( y 1 , … , y N ∣ D ) = ∏ i = 1 N P ( y i ∣ D ) = ∏ i = 1 N exp ( s ( i , y i ) ) ∑ y ′ ∈ Y ( i ) exp ( s ( i , y ′ ) ) (1) \\begin{aligned} P\\left(y_{1}, \\ldots, y_{N} \\mid D\\right) &=\\prod_{i=1}^{N} P\\left(y_{i} \\mid D\\right) \\\\ &=\\prod_{i=1}^{N} \\frac{\\exp \\left(s\\left(i, y_{i}\\right)\\right)}{\\sum_{y^{\\prime} \\in \\mathcal{Y}(i)} \\exp \\left(s\\left(i, y^{\\prime}\\right)\\right)} \\end{aligned}\\tag{1} P(y以上是关于21 意境级讲解 共指消解的方法的主要内容,如果未能解决你的问题,请参考以下文章