8.4 bert的压缩讲解 意境级
Posted 炫云云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了8.4 bert的压缩讲解 意境级相关的知识,希望对你有一定的参考价值。
模型压缩效果和压缩比:
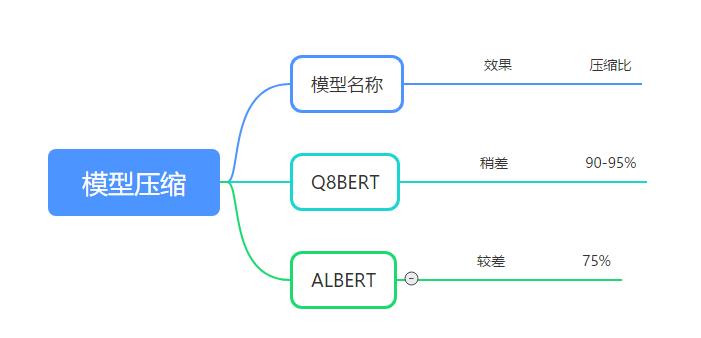
Q8BERT
论文地址 https://arxiv.org/abs/1910.06188v2
代码和模型地址 https://github.com/NVIDIA/Megatron-LM
量化是很通用的模型压缩方法,将32bit浮点压缩为8bit,甚至1bit,可以大大压缩模型体积。
在本节中,我们描述了我们使用的量化方案、线性量化和量化感知训练方法。我们之所以选择使用这种量化方案,是因为除了将模型规模减少约4个外,还可以通过使用整数算法来计算GEMM(使用专门的硬件进行整数和固定点计算)来加快推理时间。
量化方案
使用对称线性量化作为我们的量化方案,将权重和激活量化到8位整数(Int8):
Quantize
(
x
∣
S
x
,
M
)
:
=
Clamp
(
⌊
x
×
S
x
⌉
,
−
M
,
M
)
,
Clamp
(
x
,
a
,
b
)
=
min
(
max
(
x
,
a
)
,
b
)
\\begin{array}{r} \\text { Quantize }\\left(x \\mid S^{x}, M\\right):=\\operatorname{Clamp}\\left(\\left\\lfloor x \\times S^{x}\\right\\rceil,-M, M\\right), \\\\ \\operatorname{Clamp}(x, a, b)=\\min (\\max (x, a), b) \\end{array}
Quantize (x∣Sx,M):=Clamp(⌊x×Sx⌉,−M,M),Clamp(x,a,b)=min(max(x,a),b)
where
S
x
S^{x}
Sx is the quantization scaling-factor for input
x
x
x and
M
M
M is the highest quantized value when quantizing to
b
b
b number of bits:
其中
S
x
S^{x}
Sx为输入
x
x
x的量化缩放因子,
M
M
M为量化为
b
b
b比特数时的最高量化值:
M
=
2
b
−
1
−
1
M=2^{b-1}-1
M=2b−1−1
例如,量化到8位时,
M
=
127
M=127
M=127。缩放因子可以在推理期间动态确定,也可以使用训练期间收集的统计数据进行计算,也可以使用训练后在对校准集进行推理期间收集的统计数据进行计算。在我们的工作中,权重的比例因子是根据:
S
W
=
M
max
(
∣
W
∣
)
S^{W}=\\frac{M}{\\max (|W|)}
SW=max(∣W∣)M
而激活的比例因子是根据使用指数移动平均(EMA)训练时看到的值计算的:
S
x
=
M
EMA
(
max
(
∣
x
∣
)
)
S^{x}=\\frac{M}{\\operatorname{EMA}(\\max (|x|))}
Sx=EMA(max(∣x∣))M
量化感知训练
量化感知训练是一种训练神经网络(NN)在推理阶段被量化的方法,而不是训练后的量化,训练是在没有任何适应量化过程的情况下执行的。在我们的工作中,我们在训练阶段使用伪量化将量化误差引入到模型中,以便模型能够学习跨越量化误差间隙。伪量化是一种操作,模拟浮点值的舍入效果。由于舍入运算不可导出,我们使用
∂
x
q
∂
x
=
1
→
\\frac{\\partial x^{q}}{\\partial x}=\\overrightarrow{\\mathbf{1}}
∂x∂xq=1
其中
x
q
x^{q}
xq表示伪量化
x
x
x的结果。使用假量化和STE的结合,我们可以在训练期间执行量化推理,同时反向传播在完全精度,允许FP32权值克服量化错误。
剪枝
剪枝可以分为突触剪枝、神经元剪枝、权重矩阵剪枝等方法。我们介绍一篇权重矩阵剪枝的论文:Are Sixteen Heads Really Better than One?

论文信息:2019年5月,CMU,NeurIPS 2019
论文地址 https://arxiv.org/abs/1905.10650
代码和模型地址 https://github.com/pmichel31415/are-16-heads-really-better-than-1
实现方法
文章深入分析了BERT多头机制中每个头到底有多大用,结果发现很多头其实没啥卵用。他在要去掉的head上,加入mask,来做每个头的重要性分析。
作者先分析了单独去掉每层每个头,WMT任务上bleu的改变。发现,大多数head去掉后,对整体影响不大。如下图所示
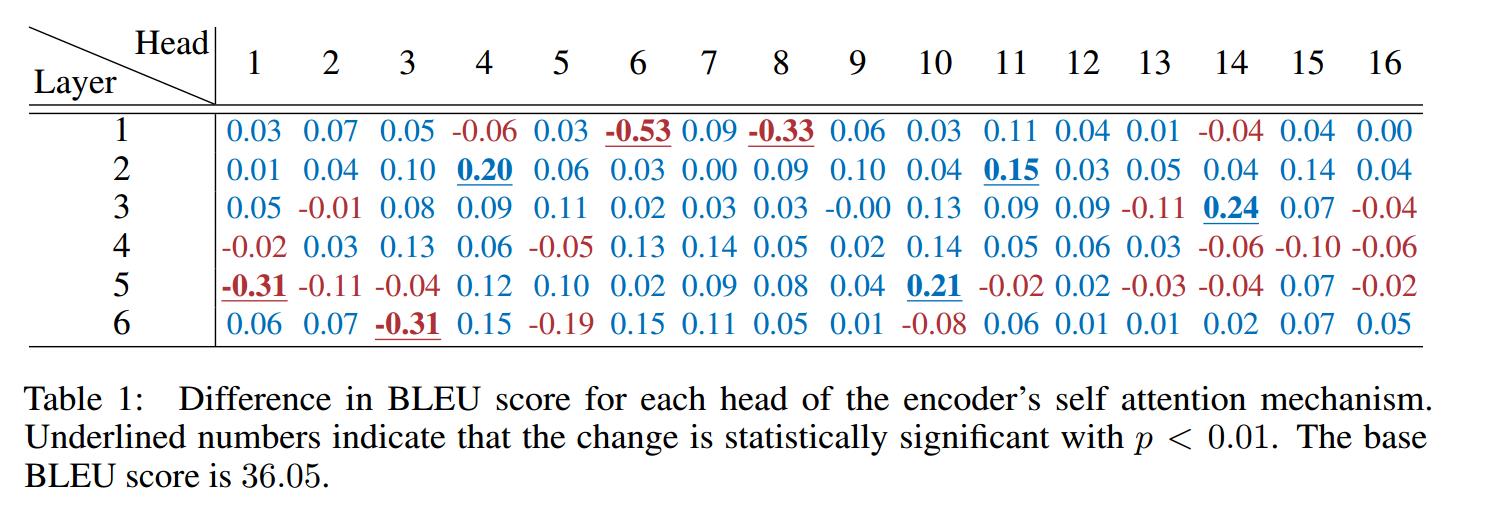
然后作者分析了,每层只保留一个最重要的head后,ACC的变化。可见很多层只保留一个head,performance影响不大。如下图所示

由此可见,直接进行权重矩阵剪枝,也是可行的方案。相比突触剪枝和神经元剪枝,压缩率要大很多。
ALBERT
参考
[模型轻量化(ALBERT、Q8BERT、DistillBERT、TinyBERT等):https://blog.csdn.net/u013510838/article/details/106986369/
Q8BERT: Quantized 8Bit BERT
Are Sixteen Heads Really Better than One?
以上是关于8.4 bert的压缩讲解 意境级的主要内容,如果未能解决你的问题,请参考以下文章