论文泛读67渐进式预训练密集语料库索引用于开放域问答
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读67渐进式预训练密集语料库索引用于开放域问答相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《Progressively Pretrained Dense Corpus Index for Open-Domain Question Answering》
一、摘要
为了从大型语料库中提取答案,开放域问答系统(QA)通常依靠信息检索(IR)技术来缩小搜索空间。由于效率高,通常使用标准倒排索引方法(例如TF-IDF)。但是,它们的检索性能受到限制,因为它们仅使用浅而稀疏的词汇特征。为了打破IR瓶颈,最近的研究表明,通过预训练将段落索引到密集向量中的有效段落编码器,可以实现更强的检索性能。训练后,可以将语料库预编码为低维向量,并将其存储在索引结构中,在该索引结构中,可以将检索有效地实现为最大的内积搜索。
尽管取得了令人鼓舞的结果,但预训练这种密集的索引非常昂贵,并且通常需要非常大的批处理量。在这项工作中,我们提出了一种简单且节省资源的方法来对段落编码器进行预训练。首先,我们没有使用启发式创建的伪问题段落对进行预训练,而是利用现有的预训练序列到序列模型来构建强大的问题生成器,以创建高质量的预训练数据。其次,我们提出一种渐进式预训练算法,以确保每批样品中均存在有效阴性样品。在三个数据集中,我们的方法优于现有的密集检索方法,该方法使用7倍以上的计算资源进行预训练。
二、结论
我们提出了一种有效的预处理稠密语料库索引的方法,可以替代开放领域问答系统中传统的信息检索方法。所提出的方法由更好的数据生成策略和用于预处理的简单而有效的数据采样协议提供动力。通过仔细的微调,我们获得了比使用更多计算资源的ORQA更强的QA性能。我们希望我们的方法能够在这个方向上鼓励更节能的预处理方法,以便密集检索范例能够更广泛地应用于不同的领域。
三、model
渐进式预审方法:
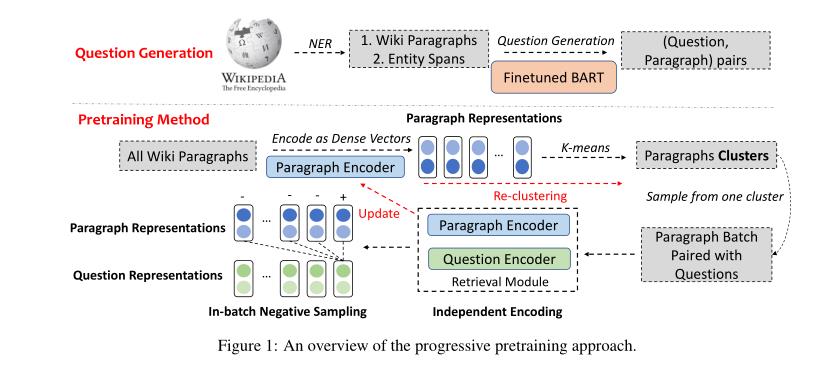
基于聚类的预处理算法:

以上是关于论文泛读67渐进式预训练密集语料库索引用于开放域问答的主要内容,如果未能解决你的问题,请参考以下文章
论文泛读180反向翻译任务自适应预训练:提高文本分类的准确性和鲁棒性
论文泛读193LICHEE:使用多粒度标记化改进语言模型预训练
论文泛读193LICHEE:使用多粒度标记化改进语言模型预训练