吴恩达机器学习-12-大规模机器学习和图片文字识别OCR
Posted 尤尔小屋的猫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了吴恩达机器学习-12-大规模机器学习和图片文字识别OCR相关的知识,希望对你有一定的参考价值。
出品:尤而小屋
作者:Peter
编辑:Peter
吴恩达机器学习-12-大规模机器学习和图片文字识别OCR
本周是课程的最后一周,老师主要是介绍了两个方面的内容,一个是如何进行大规模的机器学习,另一个是关于图片文字识别OCR 的案例:
- 大规模机器学习
- 图片文字识别OCR
大规模机器学习(Large Scale Machine Learning)
在低方差的模型中,增加数据集的规模可以帮助我们获取更好的结果。但是当数据集增加到100万条的大规模的时候,我们需要考虑:大规模的训练集是否真的有必要。获取1000个训练集也可以获得更好的效果,通过绘制学习曲线来进行判断。

随机梯度下降法Stochastic Gradient Descent
如果需要对大规模的数据集进行训练,可以尝试使用随机梯度下降法来代替批量梯度下降法。随机梯度下降法的代价函数是 :
Cost ( θ , ( x ( i ) , y ( i ) ) ) = 1 2 ( h θ ( x ( i ) ) − y ( i ) ) 2 \\operatorname{Cost}\\left(\\theta,\\left(x^{(i)}, y^{(i)}\\right)\\right)=\\frac{1}{2}\\left(h_{\\theta}\\left(x^{(i)}\\right)-y^{(i)}\\right)^{2} Cost(θ,(x(i),y(i)))=21(hθ(x(i))−y(i))2
具体算法的过程为:
- 先对训练集进行随机的洗牌操作,打乱数据的顺序
- 重复如下过程:
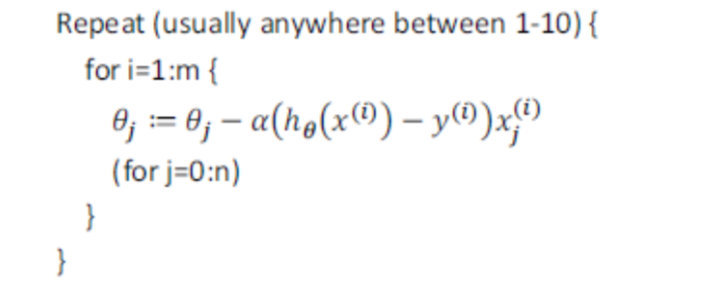
- 随机梯度下降算法是每次计算之后更新参数 θ \\theta θ,不需要现将所有的训练集求和。
算法可能存在的问题
不是每一步都是朝着”正确”的方向迈出的。因此算法虽然会逐渐走向全 局最小值的位置,但是可能无法站到那个最小值的那一点,而是在最小值点附近徘徊。

小批量梯度下降 Mini-Batch Gradient Descent
小批量梯度下降算法是介于批量梯度下降算法和梯度下降算法之间的算法。每计算常数b次训练实例,便更新一次参数 θ \\theta θ。参数b通常在2-100之间。

随机梯度下降收敛
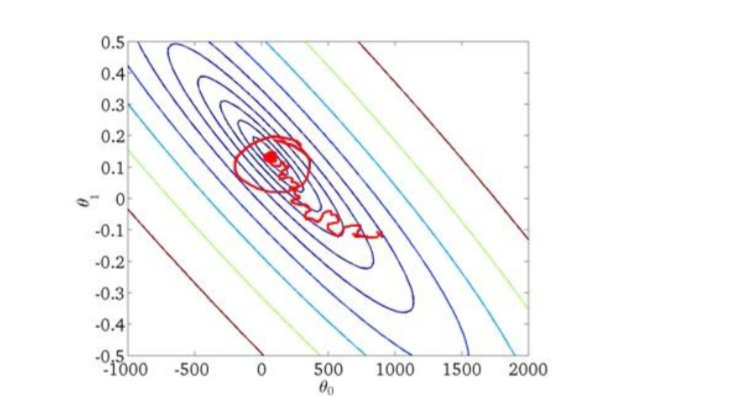
随机梯度下降算法的调试和学习率 α \\alpha α的选取
- 在批量梯度下降算法中,可以令代价函数 J J J为迭代次数的函数,绘制图表,根据图表来 判断梯度下降是否收敛;大规模的训练集情况下,此举不现实,计算代价太大
- 在随机梯度下降中,更新 θ \\theta θ之前都计算一次代价,然后迭代 X X X后求出 X X X对训练实例的计算代价的平均值,最后绘制次数 X X X和代价平均值之间的图像

随着不断地靠近全局最小值,通过减小学习率,迫使算法收敛而非在最小值最近徘徊。
映射化简和数据并行Map Reduce and Data Parallelism
映射化简和数据并行对于大规模机器学习问题而言是非常重要的概念。如果我们能够将我们的数据集分配给不多台 计算机,让每一台计算机处理数据集的一个子集,然后我们将计所的结果汇总在求和。这样 的方法叫做映射简化。
如果任何学习算法能够表达为对训练集的函数求和,那么便能将这个任务分配给多台计算机(或者同台计算机的不同CPU核心),达到加速处理的目的。比如400个训练实例,分配给4台计算机进行处理:

图片文字识别(Application Example: Photo OCR)
问题描述和流程图
图像文字识别应用所作的事是从一张给定的图片中识别文字。

基本步骤包含:
- 文字侦测(Text detection)——将图片上的文字与其他环境对象分离开来
- 字符切分(Character segmentation)——将文字分割成一个个单一的字符
- 字符分类(Characterclassification)——确定每一个字符是什么 可以用任务流程图来表
每项任务可以有不同的团队来负责处理。
 滑动窗口Sliding windows
滑动窗口Sliding windows
图片识别
滑动窗口是一项用来从图像中抽取对象的技术。看一个栗子:

如果我们需要从上面的图形中提取出来行人:
- 用许多固定尺寸的图片来训练一个能够准确识别行人的模型
- 用上面训练识别行人的模型时所采用的图片尺寸在我们要进行行人识别的图片上进行剪裁
- 剪裁得到的切片交给模型,让模型判断是否为行人
- 重复循环上述的操作步骤,直至将图片全部检测完。
文字识别
滑动窗口技术也被用于文字识别。
- 首先训练模型能够区分字符与非字符
- 然后运用滑动窗口技术识别字符
- 完成字符的识别,将识别得出的区域进行扩展
- 将重叠的区域进行合并,以宽高比作为过滤条件,过滤掉高度比宽度更大的区域

上述步骤是文字侦察阶段,接下来通过训练出一个模型来讲文字分割成一个个字符,需要的训练集由单个字符的图片和两个相连字符之间的图片来训练模型。

训练完成之后,可以通过滑动窗口技术来进行字符识别。该阶段属于字符切分阶段。

最后通过利用神经网络、支持向量机、或者逻辑回归等算法训练出一个分类器,属于是字符分类阶段。
获取大量数据和人工数据
如果我们的模型是低方差的,那么获得更多的数据用于训练模型,是能够有更好的效果。
获取大量数据的方法有
- 人工数据合成
- 手动收集、标记数据
- 众包
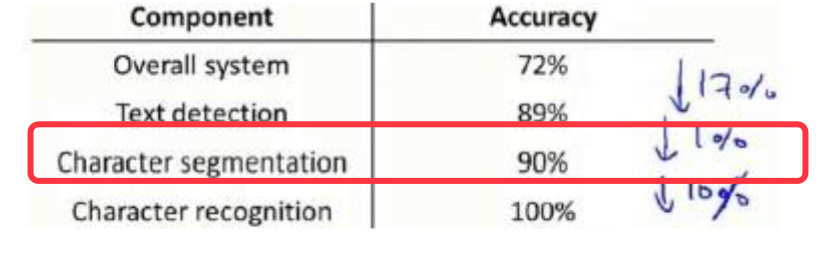
上限分析Ceiling Analysis
在机器学习的应用中,我们通常需要通过几个步骤才能进行最终的预测,我们如何能够 知道哪一部分最值得我们花时间和精力去改善呢?这个问题可以通过上限分析来回答。

回到文字识别的应用中,流程图如下:
我们发现每个部分的输出都是下个部分的输入。在上限分析中,我们选取其中的某个部分,手工提供100%争取的输出结果,然后看整体的效果提升了多少。
- 如果提升的比例比较明显,可以考虑在这个方向投入更过的时间和经历
- 如果提升的效果微乎其微,意味着某个部分已经做的足够好了
以上是关于吴恩达机器学习-12-大规模机器学习和图片文字识别OCR的主要内容,如果未能解决你的问题,请参考以下文章