什么样的程度才是“熟练掌握sql” -- MySQL进阶版
Posted BudingCode
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么样的程度才是“熟练掌握sql” -- MySQL进阶版相关的知识,希望对你有一定的参考价值。
数据库以及sql入门知识基础版:
多个岗位需要的sql语言 你掌握了吗?简单例子+详细代码带你一文掌握
带你熟练掌握 – 进阶版:
什么样的程度才是“熟练掌握sql” – MySQL进阶版
第一章 数据完整性
1.1 数据库的完整性
用来保证存放到数据库中的数据是有效的,即数据的有效性和准确性
确保数据的完整性 = 在创建表时给表中添加约束
完整性的分类:
- 实体完整性(行完整性)
- 域完整性(列完整性)
- 引用完整性(关联表完整性):
主键约束:primary key
唯一约束:unique [key]
非空约束:not null
默认约束:default
自动增长:auto_increment
外键约束: foreign key
注意⚠️ :
建议这些约束应该在创建表的时候设置,多个约束条件之间使用空格间隔
实例:
create table student(
studentno int primary key auto_increment,
loginPwd varchar(20) not null default '123456',
studentname varchar(50) not null,
sex char(2) not null,
gradeid int not null,
phone varchar(255) not null,
address varchar(255) default '学生宿舍', borndate datetime,
email varchar(50)
);
1.2 实体完整性
实体: 即表中的一行(一条记录)代表一个实体(entity)
实体完整性的作用: 标识每一行数据不重复。
约束类型:
- 主键约束(primary key)
- 唯一约束 (unique)
- 自动增长列 (auto_increment)
1.2.1 主键约束(primary key)
注: 每个表中要有一个主键。
特点: 数据唯一,且不能为null
示例
第一种添加方式
CREATE TABLE student( id int primary key, name varchar(50) );
第二种添加方式,此种方式优势在于,可以创建联合主键
CREATE TABLE student( id int, name varchar(50), primary key(id) );
CREATE TABLE student( classid int, stuid int, name varchar(50), primary
key(classid,stuid) );
第三种添加方式
CREATE TABLE student( id int, name varchar(50) );
ALTER TABLE student ADD PRIMARY KEY (id);
1.2.2 唯一约束(unique)
特点:数据不能重复
CREATE TABLE student( Id int primary key, Name varchar(50) unique );
1.2.3 自动增长列(auto_increment)
sql server数据库 (identity-标识列)
oracle数据库(sequence-序列)
给主键添加自动增长的数值,列只能是整数类型
CREATE TABLE student( Id int primary key auto_increment, Name varchar(50) );
INSERT INTO student(name) values(‘tom’);
1.3 域完整性
域完整性的作用:限制此单元格的数据正确,不对照此列的其它单元格比较 (域代表当前单元格)
域完整性约束:
| 数据类型 |
|---|
| -非空约束(not null) |
| 默认值约束(default) |
| check约束(mysql不支持) |
| check(sex=‘男’ or sex=‘女’) |
1.3.1 数据类型
数值类型
| 类型 | 大小 | 范围(有符号 | 范围(无符号) | 用途 |
|---|---|---|---|---|
| tinyint | 1 字节 | (-128,127) | (0,255) | 小整数值 |
| smallint | 2 字节 | (-32 768,32 767) | (0,65 535) | 大整数值 |
| mediumint | 3 字节 | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
| INT | 4 字节 | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| bigint | 8 字节 073 709 551 615) | (-9 233 372 036 854 775 808,9 223 372 036 854 775 807) | (0,18 446 744073 709 551 615) | 极大整数值 |
| float | 4 字节 | (-3.402 823 466 E+38,-1.175 494 351 E-38),0, (-1.175 494 351 E-38,3.402 823 466 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 双精度浮点数值 |
| double | 8 字节 | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0, (2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度浮点数值 |
日期类型
表示时间值的日期和时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR。 每个时间类型有一个有效值范围和一个"零"值,当指定不合法的MySQL不能表示的值时使用"零"值。 TIMESTAMP类型有专有的自动更新特性
| 类型 | 大小(字节) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | ‘-838:59:59’/‘838:59:59’ | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2038 结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 ,当更新数据的时候自动添加更新时间 |
字符串类型
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255字节 | 定长字符串 |
| VARCHAR | 0-65535 字节 | TINYBLOB |
| TINYBLOB | 0-255字节 | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-65 535字节 | 短文本字符串 |
| BLOB | 0-65 535字节 | 二进制形式的长文本数据 |
| TEXT | 0-65 535字节 | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215字节 | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215字节 | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295字节 | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295字节 | 极大文本数据 |
注:
- CHAR和VARCHAR类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等 方面也不同。在存储或检索过程中不进行大小写转换。
- BINARY和VARBINARY类类似于CHAR和VARCHAR,不同的是它们包含二进制字符串而不要非二进制字 符串。也就是说,它们包含字节字符串而不是字符字符串。这说明它们没有字符集,并且排序和比较基 于列值字节的数值值。
- BLOB是一个二进制大对象,可以容纳可变数量的数据。有4种BLOB类型:TINYBLOB、BLOB、 MEDIUMBLOB和LONGBLOB。它们只是可容纳值的最大长度不同。
- 有4种TEXT类型:TINYTEXT、TEXT、MEDIUMTEXT和LONGTEXT。这些对应4种BLOB类型,有相同的 最大长度和存储需求。
1.3.2 非空约束
not null
CREATE TABLE student( Id int primary key, Name varchar(50) not null, Sexvarchar(10) );
INSERT INTO student values(1,’tom’,null);
1.3.3 默认值约束
default
CREATE TABLE student( Id int primary key, Name varchar(50) not null, Sex varchar(10) default '男' );
insert intostudent1 values(1,'tom','女');
insert intostudent1 values(2,'jerry',default);
1.4 引用完整性
外键约束:FOREIGN KEY
示例:
CREATE TABLE student(id int primary key, name varchar(50) not null, sex varchar(10) default '男' );
create table score(
id int primary key,
score int,
sid int ,
constraint fk_score_sid foreign key(sid) references student(id) );
constraint 自定义外键名称 foreign key(外键列名) references 主键表名(主键列名)
外键列的数据类型一定要与主键的类型一致
第二种添加外键方式。
ALTER TABLEscore1 ADD CONSTRAINT fk_stu_score FOREIGN KEY(sid) REFERENCES stu(id);
第二章 多表查询
多个表之间是有关系的,那么关系靠谁来维护?
多表约束:外键列
2.1 多表的关系
2.1.1 一对多/多对一关系
客户和订单,分类和商品,部门和员工.
一对多建表原则: 在多的一方创建一个字段,字段作为外键指向一的一方的主键.
2.1.2 多对多关系
学生和课程
多对多关系建表原则:需要创建第三张表,中间表中至少两个字段,这两个字段分别作为外键指向各自一 方的主键.
2.1.3 一对一关系
在实际的开发中应用不多.因为一对一可以创建成一张表.
两种建表原则:
- 唯一外键对应
假设一对一是一个一对多的关系,在多的一方创建一个外键指向一的一方的主键,将外键设置为unique. - 主键对应
让一对一的双方的主键进行建立关系.
2.2 多表查询
合并结果集
- UNION
- UNION ALL
连接查询
- 内连接 [INNER] JOIN ON
- 外连接 OUTER JOIN ON
左外连接 LEFT [OUTER] JOIN
右外连接 RIGHT [OUTER] JOIN
全外连接(MySQL不支持)FULL JOIN
自然连接
- NATURAL JOIN
2.2.1 合并结果集
作用
合并结果集就是把两个select语句的查询结果合并到一起
合并结果集有两种方式:
- UNION:去除重复记录
例如:SELECT* FROM t1 UNION SELECT * FROM t2; - UNION ALL:不去除重复记录
例如:SELECT * FROM t1 UNION ALL SELECT * FROM t2。
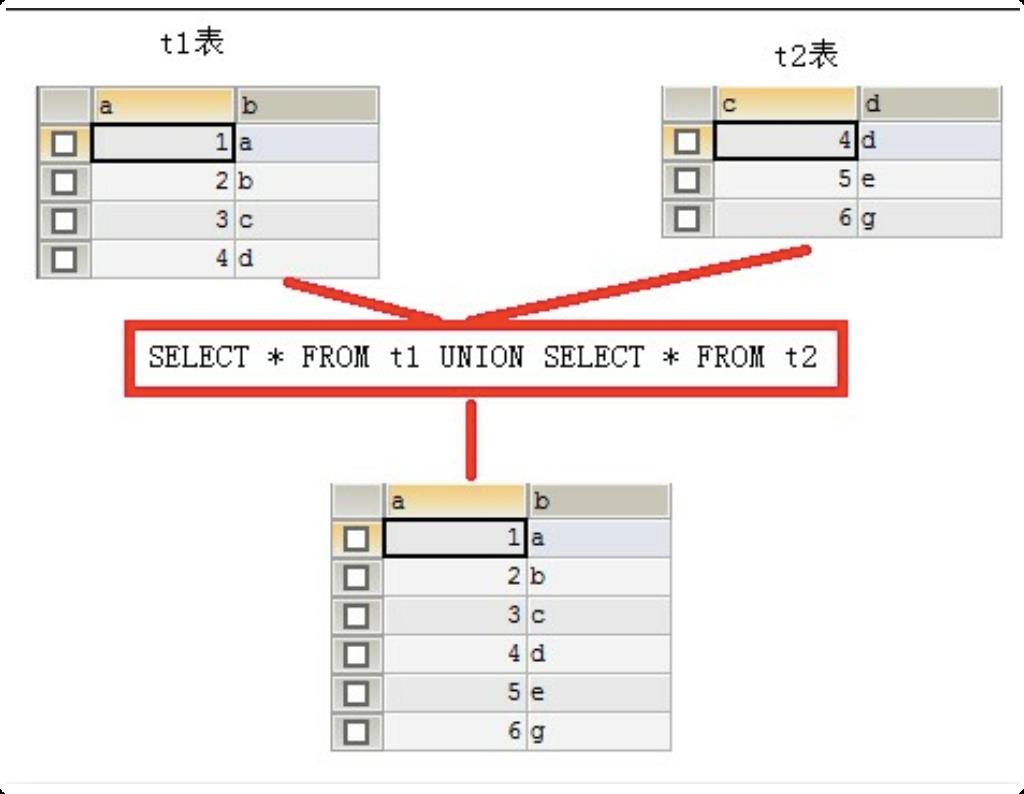
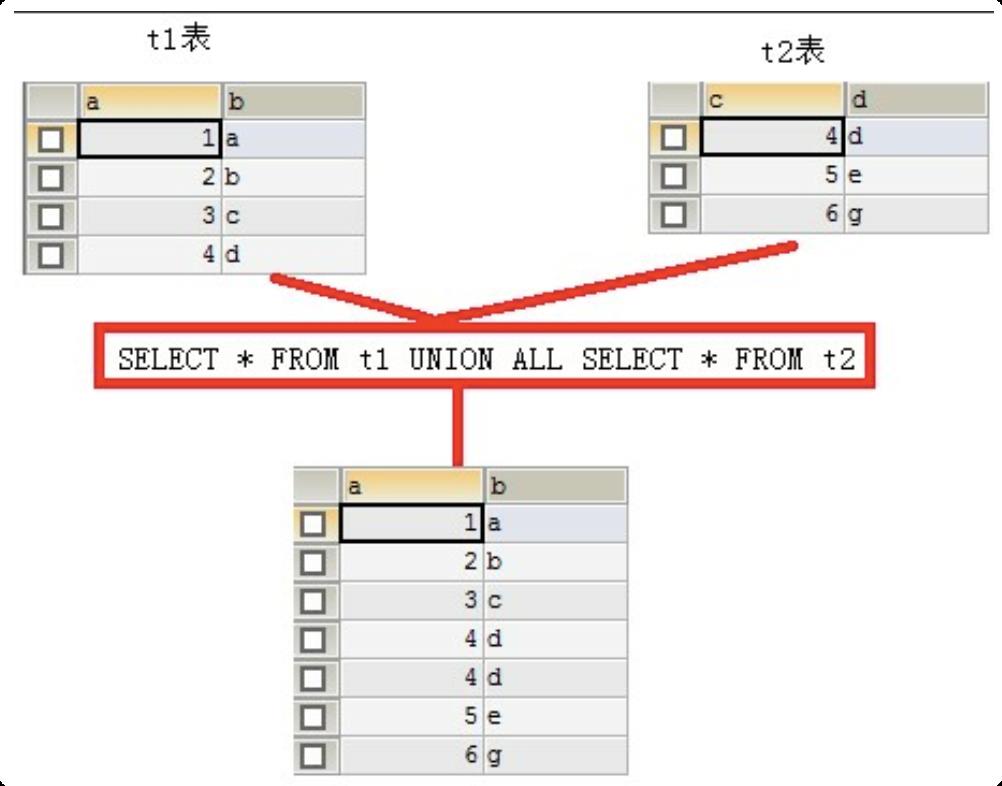
注意⚠️
被合并的两个结果,列数、列类型必须相同。
2.2.2
连接查询 连接查询就是求出多个表的乘积,例如t1连接t2,那么查询出的结果就是t1*t2。
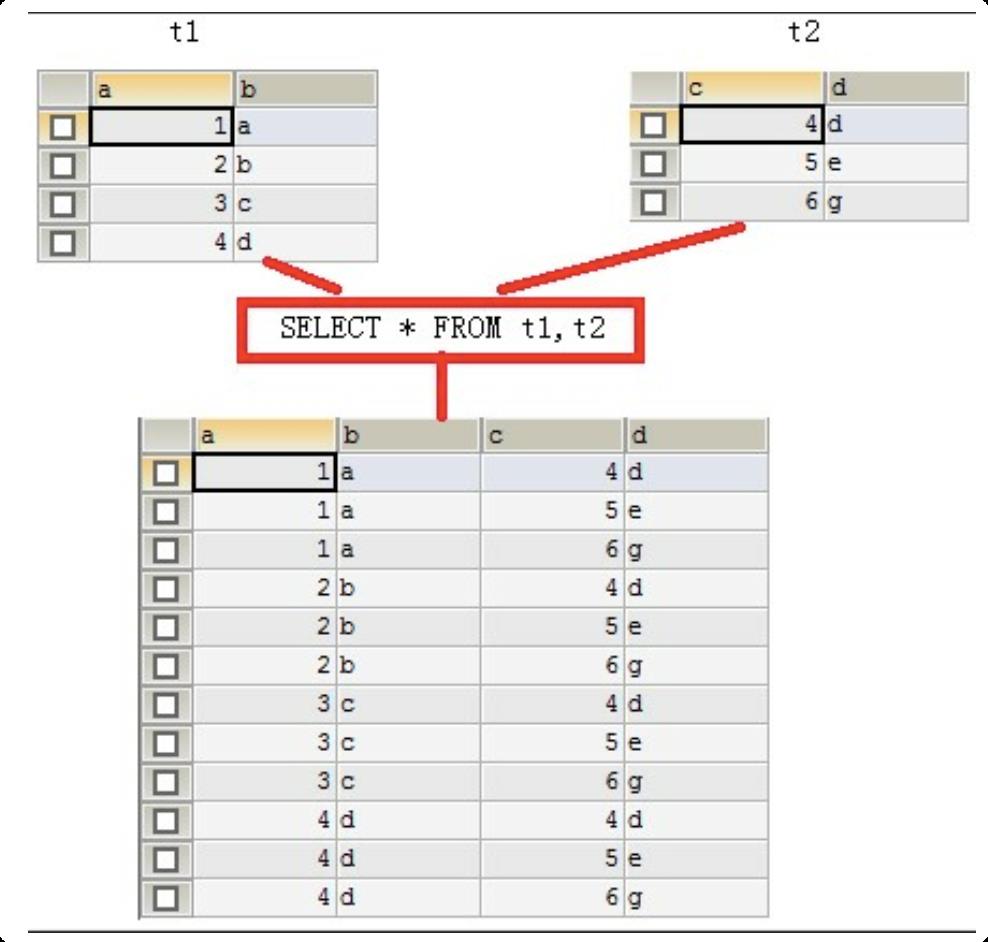
连接查询会产生笛卡尔积,假设集合A={a,b},集合B={0,1,2},则两个集合的笛卡尔积为{(a,0),(a,1), (a,2),(b,0),(b,1),(b,2)}。可以扩展到多个集合的情况。
那么多表查询产生这样的结果并不是我们想要的,那么怎么去除重复的,不想要的记录呢,当然是通过条件过滤。通常要查询的多个表之间都存在关联关系,那么就通过关联关系去除笛卡尔积。
示例 1:
现有两张表 emp-员工表,dept-部门表
CREATE TABLE dept1(
deptno
dname
loc
int primary key,
varchar(14),
varchar(13)
);
insert into dept1 values(10,'服务部','北京'); insert into dept1 values(20,'研发部','北京'); insert into dept1 values(30,'销售部','北京'); insert into dept1 values(40,'主管部','北京'); CREATE TABLE emp1(
empno int,
ename varchar(50),
job varchar(50),
mgr int,
hiredate date,
sal double,
common double,
deptno int
);
insert into emp1 values(1001,'张三','文员',1006,'2019-1-1',1000,2010,10);
insert into emp1 values(1002,'李四','程序员',1006,'2019-2-1',1100,2000,20);
insert into emp1 values(1003,'王五','程序员',1006,'2019-3-1',1020,2011,20);
insert into emp1 values(1004,'赵六','销售',1006,'2019-4-1',1010,2002,30);
insert into emp1 values(1005,'张猛','销售',1006,'2019-5-1',1001,2003,30);
insert into emp1 values(1006,'谢娜','主管',1006,'2019-6-1',1011,2004,40);
select * from emp,dept;
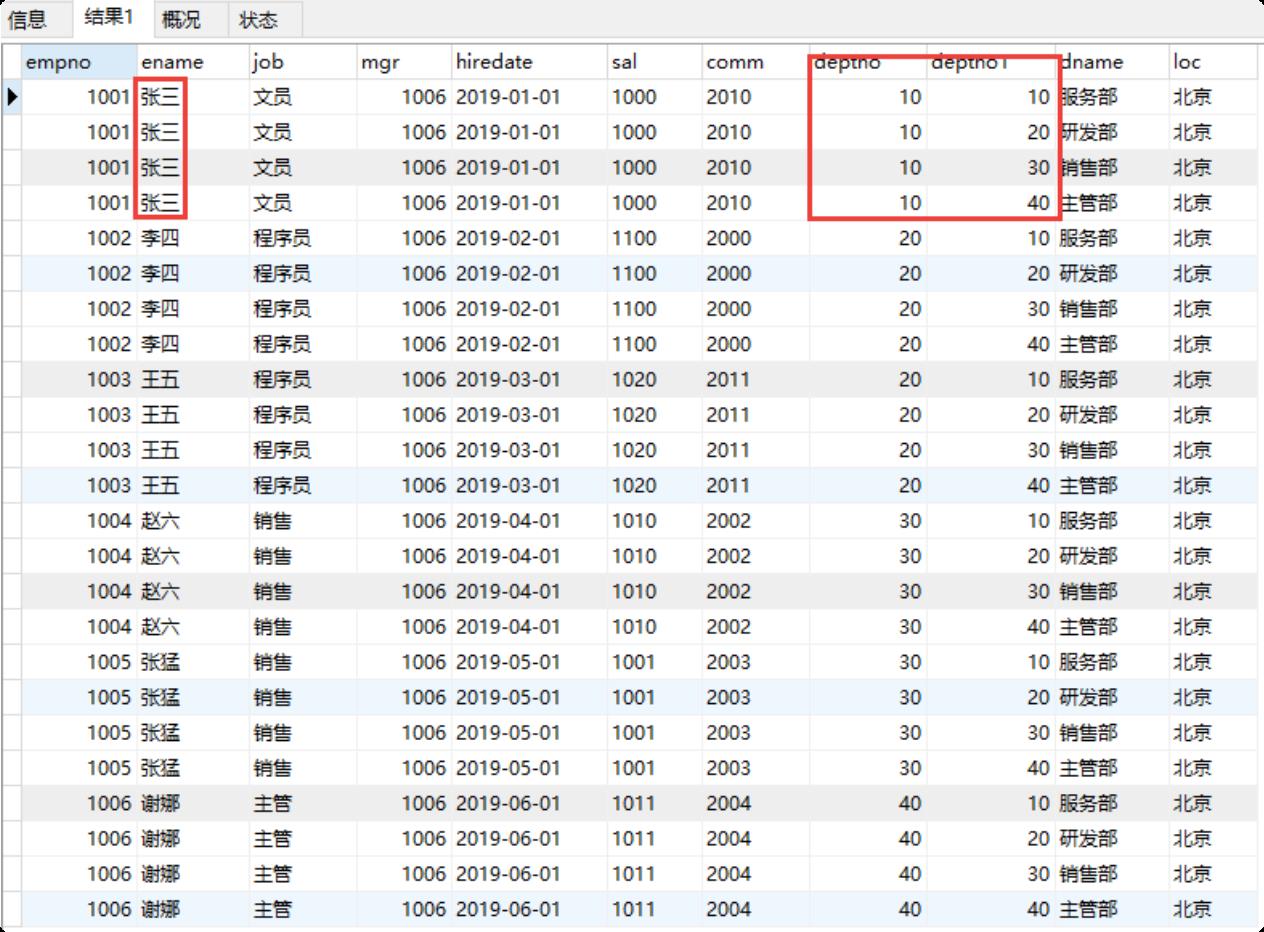
使用主外键关系做为条件来去除无用信息
SELECT * FROM emp,dept WHERE emp.deptno=dept.deptno;
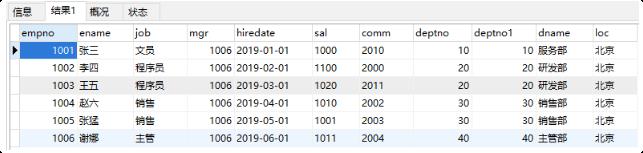
上面查询结果会把两张表的所有列都查询出来,也许你不需要那么多列,这时就可以指定要查询的列了。
SELECT emp.ename,emp.sal,emp.comm,dept.dname
FROM emp,dept
WHERE emp.deptno=dept.deptno;
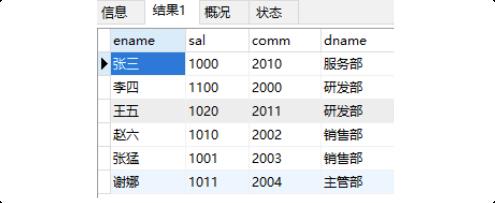
一.内连接
上面的连接语句就是内连接,但它不是SQL标准中的查询方式,可以理解为方言
语法:
select 列名
from 表1
inner join 表2
on 表1.列名=表2.列名 //外键列的关系
where.....
等价于
select 列名
from 表1,表2
where 表1.列名=表2.列名 and ...(其他条件)
注:
- 表1和表2的顺序可以互换
- 找两张表的等值关系时,找表示相同含义的列作为等值关系
- 点操作符表示“的”,格式:表名.列名
- 可以使用as,给表名起别名,注意定义别名之后,统一使用别名
示例:
//查询学生表中的学生姓名和分数表中的分数
select name,score
from student as s
inner join scores as c
on s.studentid=c.stuid
等价于:
select name,score
from student as s,scores as c
where s.studentid=c.stuid
三表联查
语法:
select 列名 from 表1
inner join 表2 on 表1.列名=表2.列名
inner join 表3 on 表1或表2.列名=表3.列名 where
等价于:
select 列名 from 表1,表2,表3
where 表1.列名=表2.列名 and 表1/表2.列名=表3.列名
SQL标准的内连接为
SELECT *
FROM emp e
INNER JOIN dept d
ON e.deptno=d.deptno;
内连接的特点:查询结果必须满足条件。
二.外连接
包括左外连接和右外连接,外连接的特点:查询出的结果存在不满足条件的可能。
- 显示还没有员工的部门名称?
- 外联查询
- 左外联 :select 列名 from 主表 left join 次表 on 主表.列名=次表.列名
– 1.主表数据全部显示,次表数据匹配显示,能匹配到的显示数据,匹配不成功的显示null
– 2.主表和次表不能随意调换位置 - 使用场景:一般会作为子查询的语句使用
select depname,name from
(select e.*,d.depname from department d left join employee e
on e.depid=d.depid
) aa where aa.name is null;
- 右外联:select 列名 from 次表 right join 主表 on 主表.列名=次表.列名
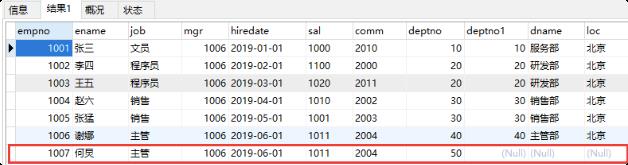
a.左外连接
SELECT * FROM emp e
LEFT OUTER JOIN dept d
ON e.deptno=d.deptno;
左连接是先查询出左表(即以左表为主),然后查询右表,右表中满足条件的显示出来,不满足条件的 显示NULL。
insert into emp values(1007,'何炅','主管',1006,'2019-6-1',1011,2004,50);
我们还是用上面的例子来说明。其中emp表中“张三”这条记录中,部门编号为50,而dept表中不存在部 门编号为50的记录,所以“张三”这条记录,不能满足e.deptno=d.deptno这条件。但在左连接中,因为 emp表是左表,所以左表中的记录都会查询出来,即“张三”这条记录也会查出,但相应的右表部分显示 NULL。
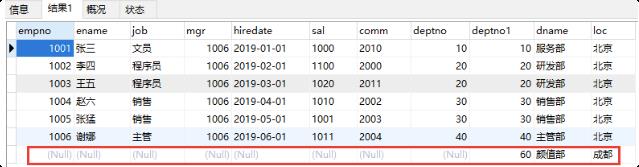
b.右外连接
右连接就是先把右表中所有记录都查询出来,然后左表满足条件的显示,不满足显示NULL。例如在 dept表中的40部门并不存在员工,但在右连接中,如果dept表为右表,那么还是会查出40部门,但相 应的员工信息为NULL。
insert into dept values(60,'颜值部','成都');
SELECT * FROM emp e
RIGHT OUTER JOIN dept d
ON e.deptno=d.deptno;
连接查询心得:
连接不限与两张表,连接查询也可以是三张、四张,甚至N张表的连接查询。通常连接查询不可能需要 整个笛卡尔积,而只是需要其中一部分,那么这时就需要使用条件来去除不需要的记录。这个条件大多 数情况下都是使用主外键关系去除。
两张表的连接查询一定有一个主外键关系,三张表的连接查询就一定有两个主外键关系,所以在大家不是很熟悉连接查询时,首先要学会去除无用笛卡尔积,那么就是用主外键关系作为条件来处理。如果两张表的查询,那么至少有一个主外键条件,三张表连接至少有两个主外键条件。
三.自然连接
自然连接(NATURAL INNER JOIN):自然连接是一种特殊的等值连接,他要求两个关系表中进行连 接的必须是相同的属性列(名字相同),无须添加连接条件,并且在结果中消除重复的属性列。
select * from emp e natural join dept d;
2.2.3 子查询
一个select语句中包含另一个完整的select语句。
子查询就是嵌套查询,即SELECT中包含SELECT,如果一条语句中存在两个,或两个以上SELECT,那么 就是子查询语句了。
- 子查询出现的位置:
a. where后,作为条为被查询的一条件的一部分;
b. from后,作表; - 当子查询出现在where后作为条件时,还可以使用如下关键字:
a. any
b. all - 子查询结果集的形式:
a. 单行单列(用于条件)
b. 单行多列(用于条件)
c. 多行单列(用于条件)
d. 多行多列(用于表)
示例:
1.工资高于JONES的员工。
分析: 查询条件:工资>JONES工资,其中JONES工资需要一条子查询。
第一步:查询JONES的工资
SELECT sal FROM emp WHERE ename='JONES';
第二步:查询高于甘宁工资的员工
SELECT * FROM emp WHERE sal > (第一步结果);
结果:
SELECT * FROM emp WHERE sal > (SELECT sal FROM emp WHERE ename='JONES');
2.查询与SCOTT同一个部门的员工。
- 子查询作为条件
- 子查询形式为单行单列
分析:
查询条件:部门=SCOTT的部门编号,其中SCOTT 的部门编号需要一条子查询。
第一步:查询SCOTT的部门编号
SELECT deptno FROM emp WHERE ename='SCOTT';
第二步:查询部门编号等于SCOTT的部门编号的员工
SELECT * FROM emp WHERE deptno = (SELECT deptno FROM emp WHERE ename='SCOTT');
3.工资高于30号部门所有人的员工信息
- 子查询作为条件
- 子查询形式为多行单列(当子查询结果集形式为多行单列时可以使用ALL或ANY关键字)
分析:
SELECT * FROMemp WHERE sal>(SELECT MAX(sal) FROM emp WHERE deptno=30);
查询条件:工资高于30部门所有人工资,其中30部门所有人工资是子查询。高于所有需要使用all关键字。
第一步:查询30部门所有人工资
SELECT sal FROM emp WHERE deptno=30;
第二步:查询高于30部门所有人工资的员工信息
SELECT * FROM emp WHERE sal > ALL (第一步)
第四章:扩展
4.1 多行新增
insert into 表名(列名) values (列值),(列值),(列值);
4.2 多表更新
(1)update 表1,表2 set 列名=列值 where 表1.列名=表2.列名 and 其他限定条件
(2)update 表1
inner join 表2 on 表1.列名=表2.列名
set 列名=列值
where 限定条件
示例:
update employee e,salary s
set title='助工',salary=1000
where e.empid=s.empid and name='李四'
4.3 多表删除
语法:
delete 被删除数据的表 from 删除操作中使用的表 where 限定条件
注:多张表之间使用逗号间隔
示例:
//删除人事部的信息
delete d,e,s from department d,employee e,salary s
where d.depid=e.depid and s.empid=e.empid and depname='人事部'
4.4 日期运算函数
- now() 获得当前系统时间
- year(日期值) 获得日期值中的年份
- date_add(日期,interval 计算值 计算的字段);
注
计算值大于0表示往后推日期,小于0表示往前推日期
示例:
date_add(now(),interval -40 year);//40年前的日期
第五章:数据库优化
1.对查询进行优化,要尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引
2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
最好不要给数据库留NULL,尽可能的使用 NOT NULL填充数据库.
备注、描述、评论之类的可以设置为 NULL,其他的,最好不要使用NULL。
3.应尽量避免在 where 子句中使用 != 或 <> 操作符,否则引擎将放弃使用索引而进行全表扫描。
4.应尽量避免在 where 子句中使用 or 来连接条件,如果一个字段有索引,一个字段没有索引,将导致 引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or Name = 'admin'
可以这样查询:
select id from t where num = 10
union all
select id from t where Name = 'admin'
5.in 和 not in 也要慎用,否则会导致全表扫描,如:
select id from t where num in(1,2,3)
对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
很多时候用 exists 代替 in 是一个好的选择
以上是关于什么样的程度才是“熟练掌握sql” -- MySQL进阶版的主要内容,如果未能解决你的问题,请参考以下文章
多个岗位需要的sql语言 你掌握了吗?简单例子+详细代码带你一文掌握
多个岗位需要的sql语言 你掌握了吗?简单例子+详细代码带你一文掌握