用 XGBoost 开发随机森林集成
Posted Python中文社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用 XGBoost 开发随机森林集成相关的知识,希望对你有一定的参考价值。

XGBoost库提供了梯度增强的有效实现,可以将其配置为训练随机森林集成。随机森林是比梯度增强更简单的算法。XGBoost库允许以重新利用和利用库中实现的计算效率来训练随机森林模型的方式来训练模型。
在本教程中,您将发现如何使用XGBoost库来开发随机森林集成。完成本教程后,您将知道:
XGBoost提供了梯度增强的有效实现,可以将其配置为训练随机森林集成。
如何使用XGBoost API训练和评估随机森林集成模型以进行分类和回归。
如何调整XGBoost随机森林集成模型的超参数。
教程概述
本教程分为五个部分。他们是:
XGBoost的随机森林
随机森林的XGBoost API
XGBoost分类随机森林
XGBoost回归随机森林
XGBoost随机森林超参数
XGBoost的随机森林
XGBoost是一个开放源代码库,它提供了梯度增强集成算法的有效实现,该算法简称为Extreme Gradient Boosting或XGBoost。因此,XGBoost指的是项目,库和算法本身。梯度提升是分类和回归预测建模项目的首选算法,因为它通常可以实现最佳性能。梯度提升的问题在于训练模型通常非常慢,并且大型数据集激怒了这个问题。XGBoost通过引入许多技术来极大地加速模型的训练,并常常导致更好的模型整体性能,从而解决了梯度增强的速度问题。
您可以在本教程中了解有关XGBoost的更多信息:
XGBoost的实用机器学习简介
https://machinelearningmastery.com/gentle-introduction-xgboost-applied-machine-learning/
除了支持梯度增强之外,还可以将核心XGBoost算法配置为支持其他类型的树集成算法,例如随机森林。随机森林是决策树算法的集合。每个决策树都适合训练数据集的引导样本。这是训练数据集的样本,其中可以多次选择给定的示例(行),称为替换样本。重要的是,要考虑树中每个分割点的输入变量(列)的随机子集。这样可以确保添加到合奏中的每棵树都是熟练的,但是在随机方式上是不同的。在每个分割点考虑的特征数量通常只是一小部分。例如,在分类问题上,一种常见的启发式方法是选择特征数量等于特征总数的平方根,例如如果数据集具有20个输入变量,则为4。您可以在本教程中了解有关随机森林集成算法的更多信息:
如何使用Python开发随机森林集成体
https://machinelearningmastery.com/random-forest-ensemble-in-python/
使用XGBoost库训练随机森林集成的主要好处是速度。与其他实现(例如本机scikit-learn实现)相比,预期使用起来会更快。现在我们知道XGBoost提供了相对于基准性能而言是已知的。
随机森林的XGBoost API
第一步是安装XGBoost库。我建议从命令行使用以下命令来使用pip软件包管理器:
sudo pip install xgboost
安装完成后,我们可以加载该库并使用Python脚本打印版本,以确认它已正确安装。
# check xgboost version
import xgboost
# display version
print(xgboost.__version__)
运行脚本将加载XGBoost库并打印该库的版本号。
您的版本号应该相同或更高。
1.0.2
XGBoost库提供了两个包装器类,这些包装器类允许该库提供的随机森林实现与scikit-learn机器学习库一起使用。
它们分别是用于分类和回归的XGBRFClassifier和XGBRFRegressor类。
# define the model
model = XGBRFClassifier()
可以通过“ n_estimators”自变量设置集合中使用的树数,并且通常会增加该树数,直到模型未观察到性能进一步提高为止。通常使用数百或数千棵树。
# define the model
model = XGBRFClassifier(n_estimators=100)
XGBoost不支持为每个决策树绘制引导程序样本。这是库的限制。取而代之的是,可以通过“子样本”参数将训练数据集的子样本指定为0.0到1.0(训练数据集中的行的100%)之间的百分比,而无需替换。建议使用0.8或0.9的值,以确保数据集足够大以训练熟练的模型,但又足够不同以将整体引入某种多样性。
# define the model
model = XGBRFClassifier(n_estimators=100, subsample=0.9)
训练模型时,每个分割点使用的特征数量可以通过“ colsample_bynode”参数指定,并采用数据集中列数的百分比(从0.0到1.0)(训练数据集中输入行的100%)。
如果我们在训练数据集中有20个输入变量,并且分类问题的启发式是要素数量的平方根,则可以将其设置为sqrt(20)/ 20,或大约4/20或0.2。
# define the model
model = XGBRFClassifier(n_estimators=100, subsample=0.9, colsample_bynode=0.2)
您可以在此处了解更多有关如何为随机森林合奏配置XGBoost库的信息:
XGBoost中的随机森林
https://xgboost.readthedocs.io/en/latest/tutorials/rf.html
现在,我们已经熟悉了如何使用XGBoost API定义随机森林集合,让我们来看一些可行的示例。
XGBoost分类随机森林
在本节中,我们将研究为分类问题开发XGBoost随机森林集合。
首先,我们可以使用make_classification()函数创建具有1,000个示例和20个输入特征的综合二进制分类问题。
下面列出了完整的示例。
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# summarize the dataset
print(X.shape, y.shape)
运行示例将创建数据集并总结输入和输出组件的形状。
(1000, 20) (1000,)
接下来,我们可以在该数据集上评估XGBoost随机森林算法。
我们将使用重复的分层k折交叉验证(具有3个重复和10折)对模型进行评估。我们将报告所有重复和折叠中模型准确性的均值和标准差。
# evaluate xgboost random forest algorithm for classification
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from xgboost import XGBRFClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# define the model
model = XGBRFClassifier(n_estimators=100, subsample=0.9, colsample_bynode=0.2)
# define the model evaluation procedure
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# evaluate the model and collect the scores
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
# report performance
print('Mean Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))
运行示例将报告模型的均值和标准差准确性。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行该示例几次并比较平均结果。
在这种情况下,我们可以看到XGBoost随机森林集成实现了大约89.1%的分类精度。
Mean Accuracy: 0.891 (0.036)
我们还可以将XGBoost随机森林模型用作最终模型,并进行分类预测。
首先,将XGBoost随机森林集合适合所有可用数据,然后可以调用prepare()函数对新数据进行预测。
下面的示例在我们的二进制分类数据集中展示了这一点。
# make predictions using xgboost random forest for classification
from numpy import asarray
from sklearn.datasets import make_classification
from xgboost import XGBRFClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# define the model
model = XGBRFClassifier(n_estimators=100, subsample=0.9, colsample_bynode=0.2)
# fit the model on the whole dataset
model.fit(X, y)
# define a row of data
row = [0.2929949,-4.21223056,-1.288332,-2.17849815,-0.64527665,2.58097719,0.28422388,-7.1827928,-1.91211104,2.73729512,0.81395695,3.96973717,-2.66939799,3.34692332,4.19791821,0.99990998,-0.30201875,-4.43170633,-2.82646737,0.44916808]
row = asarray([row])
# make a prediction
yhat = model.predict(row)
# summarize the prediction
print('Predicted Class: %d' % yhat[0])
运行示例将XGBoost随机森林集成模型适合整个数据集,然后将其用于对新的数据行进行预测,就像我们在应用程序中使用模型时一样。
Predicted Class: 1
既然我们熟悉如何使用随机森林进行分类,那么让我们看一下用于回归的API。
XGBoost回归随机森林
在本节中,我们将研究为回归问题开发XGBoost随机森林集合。首先,我们可以使用make_regression()函数创建具有1000个示例和20个输入要素的综合回归问题。下面列出了完整的示例。
# test regression dataset
from sklearn.datasets import make_regression
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# summarize the dataset
print(X.shape, y.shape)
运行示例将创建数据集并总结输入和输出组件的形状。
(1000, 20) (1000,)
接下来,我们可以在该数据集上评估XGBoost随机森林集合。
正如我们在上一节所做的那样,我们将使用重复的k倍交叉验证(三个重复和10倍)来评估模型。
我们将报告所有重复和折叠过程中模型的平均绝对误差(MAE)。scikit-learn库使MAE变为负数,从而使其最大化而不是最小化。这意味着较大的负MAE会更好,并且理想模型的MAE为0。
下面列出了完整的示例。
# evaluate xgboost random forest ensemble for regression
from numpy import mean
from numpy import std
from sklearn.datasets import make_regression
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedKFold
from xgboost import XGBRFRegressor
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# define the model
model = XGBRFRegressor(n_estimators=100, subsample=0.9, colsample_bynode=0.2)
# define the model evaluation procedure
cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1)
# evaluate the model and collect the scores
n_scores = cross_val_score(model, X, y, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-1)
# report performance
print('MAE: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))
运行示例将报告模型的均值和标准差MAE。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行该示例几次并比较平均结果。
在这种情况下,我们可以看到具有默认超参数的随机森林集合达到了约108的MAE。
MAE: -108.290 (5.647)
我们还可以将XGBoost随机森林集合用作最终模型,并进行回归预测。
首先,将随机森林集合适合所有可用数据,然后可以调用predict()函数对新数据进行预测。
下面的示例在我们的回归数据集中展示了这一点。
# gradient xgboost random forest for making predictions for regression
from numpy import asarray
from sklearn.datasets import make_regression
from xgboost import XGBRFRegressor
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# define the model
model = XGBRFRegressor(n_estimators=100, subsample=0.9, colsample_bynode=0.2)
# fit the model on the whole dataset
model.fit(X, y)
# define a single row of data
row = [0.20543991,-0.97049844,-0.81403429,-0.23842689,-0.60704084,-0.48541492,0.53113006,2.01834338,-0.90745243,-1.85859731,-1.02334791,-0.6877744,0.60984819,-0.70630121,-1.29161497,1.32385441,1.42150747,1.26567231,2.56569098,-0.11154792]
row = asarray([row])
# make a prediction
yhat = model.predict(row)
# summarize the prediction
print('Prediction: %d' % yhat[0])
运行示例将XGBoost随机森林集成模型适合整个数据集,然后将其用于对新的数据行进行预测,就像我们在应用程序中使用模型时一样。
Prediction: 17
现在,我们已经熟悉了如何开发和评估XGBoost随机森林集成,让我们来看一下配置模型。
XGBoost随机森林超参数
在本节中,我们将仔细研究一些您应该考虑针对随机森林集合进行调优的超参数及其对模型性能的影响。
探索树木数量
树的数量是为XGBoost随机森林配置的另一个关键超参数。通常,增加树的数量,直到模型性能稳定为止。直觉可能表明,更多的树木将导致过度拟合,尽管事实并非如此。考虑到学习算法的随机性,装袋算法和随机森林算法似乎都不太适合过度拟合训练数据集。可以通过“ n_estimators”参数设置树的数量,默认为100。下面的示例探讨值在10到1,000之间的树木数量的影响。
# explore xgboost random forest number of trees effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from xgboost import XGBRFClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
# define the number of trees to consider
n_trees = [10, 50, 100, 500, 1000, 5000]
for v in n_trees:
models[str(v)] = XGBRFClassifier(n_estimators=v, subsample=0.9, colsample_bynode=0.2)
return models
# evaluate a give model using cross-validation
def evaluate_model(model, X, y):
# define the model evaluation procedure
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# evaluate the model
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
# evaluate the model and collect the results
scores = evaluate_model(model, X, y)
# store the results
results.append(scores)
names.append(name)
# summarize performance along the way
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()
首先运行示例将报告每个已配置数量的树的平均准确性。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行该示例几次并比较平均结果。
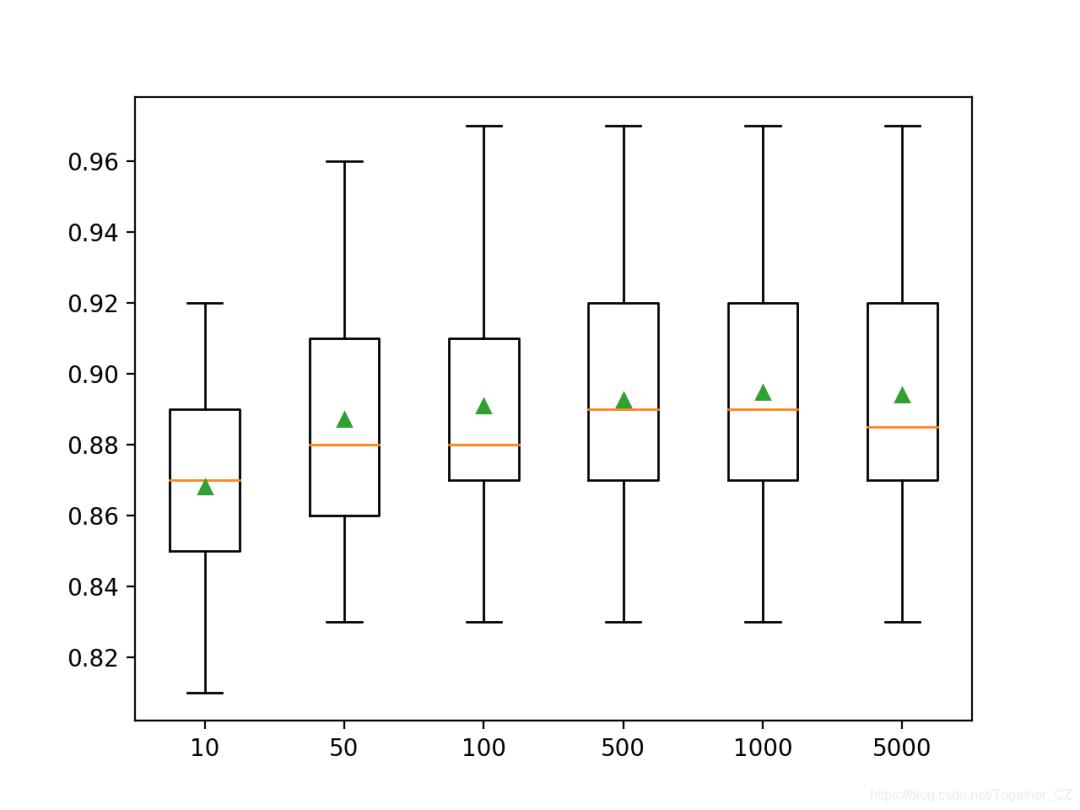
在这种情况下,我们可以看到性能在大约500棵树之后上升并保持稳定。平均准确度分数在500棵,1,000棵和5,000棵树上波动,这可能是统计噪声。
>10 0.868 (0.030)
>50 0.887 (0.034)
>100 0.891 (0.036)
>500 0.893 (0.033)
>1000 0.895 (0.035)
>5000 0.894 (0.036)
创建箱须图以分配每种配置数量的树的准确性得分。
探索特征数量
为每个分割点随机采样的要素数量可能是为随机森林配置的最重要的要素。通过“ colsample_bynode”参数进行设置,该参数占输入要素数量(从0到1)的百分比。下面的示例探讨了在每个分割点随机选择的特征数量对模型准确性的影响。我们将尝试从0.0到1.0的值以0.1的增量进行尝试,尽管我们期望低于0.2或0.3的值会产生良好或最佳的性能,因为这可以转换为输入要素数量的平方根,这是常见的 启发式。
# explore xgboost random forest number of features effect on performance
from numpy import mean
from numpy import std
from numpy import arange
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from xgboost import XGBRFClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
for v in arange(0.1, 1.1, 0.1):
key = '%.1f' % v
models[key] = XGBRFClassifier(n_estimators=100, subsample=0.9, colsample_bynode=v)
return models
# evaluate a give model using cross-validation
def evaluate_model(model, X, y):
# define the model evaluation procedure
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# evaluate the model
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
# evaluate the model and collect the results
scores = evaluate_model(model, X, y)
# store the results
results.append(scores)
names.append(name)
# summarize performance along the way
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()
首先运行示例将报告每种功能集大小的平均准确性。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行该示例几次并比较平均结果。
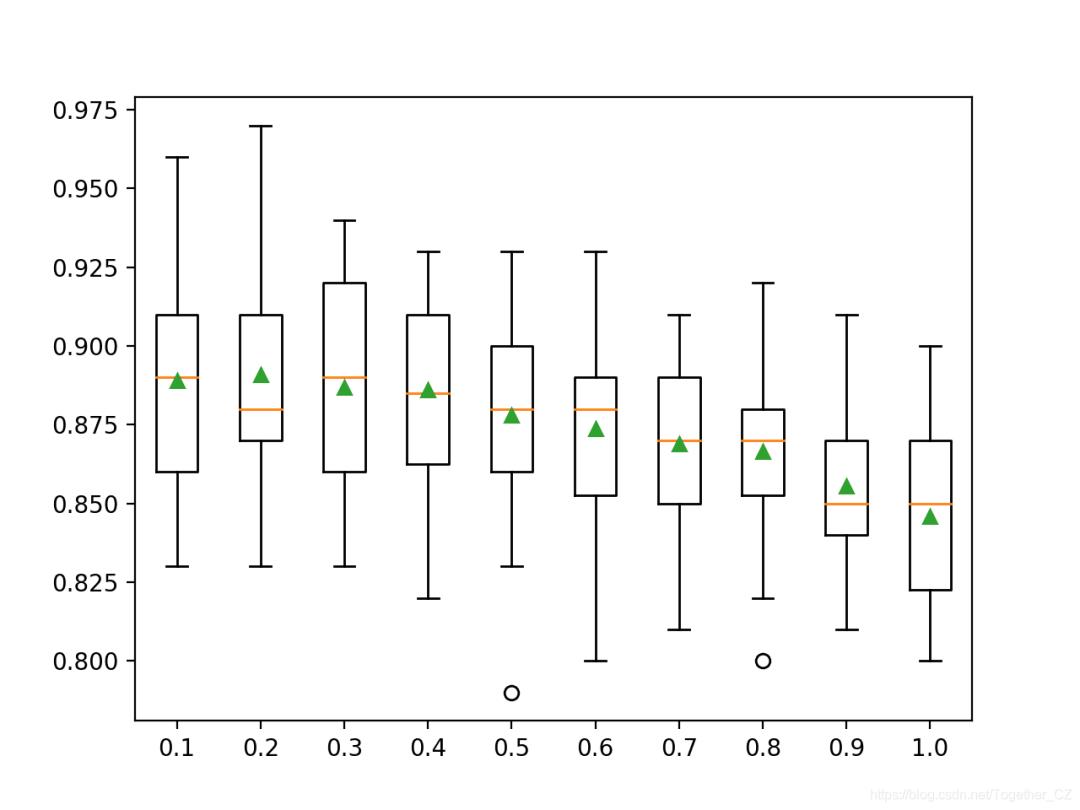
在这种情况下,随着集成成员使用更多输入功能,我们可以看到平均模型性能下降的总体趋势。
结果表明,在这种情况下,建议值为0.2将是一个不错的选择。
>0.1 0.889 (0.032)
>0.2 0.891 (0.036)
>0.3 0.887 (0.032)
>0.4 0.886 (0.030)
>0.5 0.878 (0.033)
>0.6 0.874 (0.031)
>0.7 0.869 (0.027)
>0.8 0.867 (0.027)
>0.9 0.856 (0.023)
>1.0 0.846 (0.027)
创建箱须图以分配每种功能集大小的准确性得分。
我们可以看到性能的趋势随着决策树考虑的功能数量的减少而降低。
作者:沂水寒城,CSDN博客专家,个人研究方向:机器学习、深度学习、NLP、CV
Blog: http://yishuihancheng.blog.csdn.net
赞 赏 作 者

更多阅读
特别推荐


点击下方阅读原文加入社区会员
以上是关于用 XGBoost 开发随机森林集成的主要内容,如果未能解决你的问题,请参考以下文章
面试笔试题集:集成学习,树模型,Random Forests,GBDT,XGBoost