面试笔试题集:集成学习,树模型,Random Forests,GBDT,XGBoost
Posted shiter
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面试笔试题集:集成学习,树模型,Random Forests,GBDT,XGBoost相关的知识,希望对你有一定的参考价值。
文章大纲
集成学习基本概念
集成学习(ensemble learning)是时下非常流行的机器学习算法,它本身不是一个单独的机器学习算法,而是通过在数据上构建多个模型,集成所有模型的建模结果。
集成算法会考虑多个评估器的建模结果,汇总之后得到一个综合的结果,以此来获取比单个模型更好的回归或分类表现。
多个模型集成成为的模型叫做集成评估器(ensemble estimator),组成集成评估器的每个模型都叫做基评估器(base estimator)。通常来说,有三类集成算法:装袋法(Bagging),提升法(Boosting)和stacking。

sklearn 中的继承学习类
sklearn中的集成算法模块ensemble
| 类 | 类的功能 |
|---|---|
| ensemble.AdaBoostClassifier AdaBoost | 分类 |
| ensemble.AdaBoostClassifier AdaBoost | 分类 |
| ensemble.AdaBoostRegressor Adaboost | 回归 |
| ensemble.BaggingClassifier | 装袋分类器 |
| ensemble.BaggingRegressor | 装袋回归器 |
| ensemble.ExtraTreesClassifier | Extra-trees分类(超树,极端随机树) |
| ensemble.ExtraTreesRegressor | Extra-trees回归 |
| ensemble.GradientBoostingClassifier | 梯度提升分类 |
| ensemble.GradientBoostingRegressor | 梯度提升回归 |
| ensemble.IsolationForest | 隔离森林 |
| ensemble.RandomForestClassifier | 随机森林分类 |
| ensemble.RandomForestRegressor | 随机森林回归 |
| ensemble.RandomTreesEmbedding | 完全随机树的集成 |
| ensemble.VotingClassifier | 用于不合适估算器的软投票/多数规则分类器 |
集成方法:
https://scikit-learn.org/stable/modules/classes.html#module-sklearn.ensemble
https://www.sklearncn.cn/12/
集成学习分哪几种?他们有何异同?
Boosting 提升法
Boosting方法训练基分类器时采用串行的方式,各个基分类器之间有依赖。 它的基本思路是将基分类器层层叠加,每一层在训练的时候,对前一层基分 类器分错的样本,给予更高的权重。测试时,根据各层分类器的结果的加权得到 最终结果。
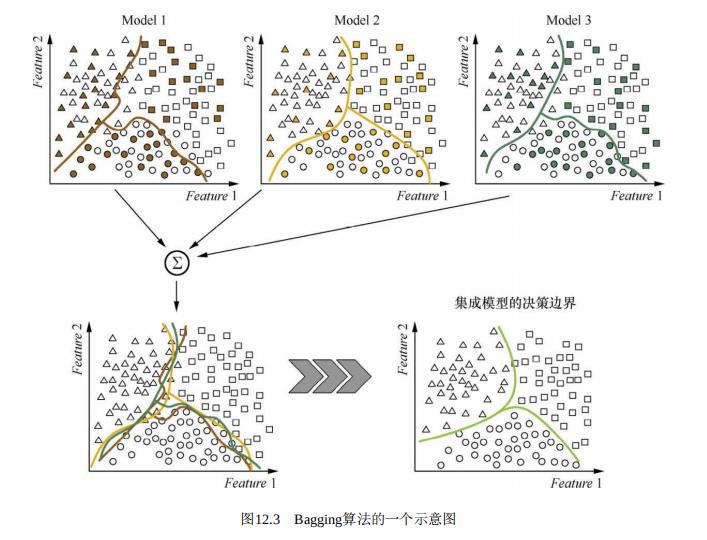
Bagging 装袋法
Bagging与Boosting的串行训练方式不同,Bagging方法在训练过程中,各基分 类器之间无强依赖,可以进行并行训练。其中很著名的算法之一是基于决策树基 分类器的随机森林(Random Forest)。为了让基分类器之间互相独立,将训练集 分为若干子集(当训练样本数量较少时,子集之间可能有交叠)。Bagging方法更 像是一个集体决策的过程,每个个体都进行单独学习,学习的内容可以相同,也 可以不同,也可以部分重叠。但由于个体之间存在差异性,最终做出的判断不会 完全一致。在最终做决策时,每个个体单独作出判断,再通过投票的方式做出最 后的集体决策
stacking 堆叠法
Stacking 是一种模型融合算法,基本思路是通过一个模型融合若干单模型的预测结果,目的是降低单模型的泛化误差。
单模型——可以称作一级模型
Stacking——可以称作二级模型或者元模型
随机森林

随机森林和GBDT 的区别
相同点:
•都是由多棵树组成,最终的结果都是由多棵树一起决定。
不同点:
•集成学习:RF属于bagging思想,而GBDT是boosting思想
•偏差•方差权衡:RF不断的降低模型的方差,而GBDT不断的降彳氐模型的偏差
•训练样本:RF每次迭代的样本是从全部训练集中有放回抽样形成的,而GBDT每次使用全部样 本
•并行性:RF的树可以并行生成,而GBDT只能顺序生成(需要等上一棵树完全生成)
•最终结果:RF最终是多棵树进行多数表决(回归问题是取平均),而GBDT是加权融合
•数据敏感性:RF对异常值不敏感,而GBDT对异常值比较敏感
•泛化能力:RF不易过拟合,而GBDT容易过拟合
对于不平衡的数据集,例如用户的购买行为,肯定是极其不平衡的,这对XGBoost的训练有很大 的影响,
XGBoost
XGBoost与GBDT有什么不同
- 基分类器:XGBoost的基分类器不仅支持CART决策树,还支持线性分类器,此时XGBoost相 当于带L1和L2正则化项的Logistic回归(分类问题)或者线性回归(回归问题)。
- 导数信息:XGBoost对损失函数做了二阶泰勒展开,GBDT只用了一阶导数信息,并且 XGBoost还支持自定义损失函数,只要损失函数一阶、二阶可导。
-正则项:XGBoost的目标函数加了正则项,相当于预剪枝,使得学习出来的模型更加不容易 过拟合。 - 列抽样:XGBoost支持列采样,与随机森林类似,用于防止过拟合。
- 缺失值处理:对树中的每个非叶子結点,XGBoost可以自动学习出它的默认分裂方向。如果 某个样本该特征值妝失,会将其划入默认分支。
- 并行化:注意不是tree维度的并行,而是特征维度的并行• XGBoost预先将每个特征按特征 值排好序,存储为块结构,分裂结点时可以采用多线程并行查找每个特征的最佳分割点,极大 提升训练速度。
XGBoost为什么使用泰勒二阶展开
•精准性:相对于GBDT的一阶泰勒展开,XGBoost采用二阶泰勒展开,可以更为精准的逼近真 实的损失函数
•可扩展性:损失函数支持自定义,只需要新的损失函数二阶可导。
XGBoost为什么可以并行训练
•XGBoost的并行,并不是说每棵树可以并行训练,XGB本质上仍然采用boosting思想,每棵 树训练前需要等前面的树训练完成才能开始训练。
•XGBoost的并行,指的是特征维度的并行:在训练之前,每个特征按特征值对样本进行预排 序,并存储为Block结构,在后面查找特征分割点时可以重复使用,而且特征已经被存储为一 个个block结构,那么在寻找每个特征的最佳分割点时,可以利用多线程对每个block并行计 算。
XGBoost为什么快
•分块并行:训练前每个特征按特征值进行排序并存储为Block结构,后面查找特征分割点时重 复使用,并且支持并行查找每个特征的分割点
•候选分位点:每个特征采用常数个分位点作为候选分割点
•CPU cache命中优化:使用缓存预取的方法,对每个线程分配一个连续的buffer,读取每个 block中样本的梯度信息并存入连续的Buffer中。
•Block处理优化:Block预先放入内存;Block按列进行解压缩;将Block划分到不同硬盘来提 高吞吐
XGBoost防止过拟合的方法
XGBoost在设计时,为了防止过拟合做了很多优化,具体如下:
•目标函数添加正则项:叶子节点个数+叶子节点权重的L2正则化
•列抽样:训练的时候只用一部分特征(不考虑剩余的block块即可)
•子采样:每轮计算可以不使用全部样本,使算法更加保守
• shrinkage:可以叫学习率或步长,为了给后面的训练留出更多的学习空间
XGBoost 与 GBDT的比较
与传统的 GBDT/GBRT 相比,XGBoost的主要优势如下。
-
引入损失函数的二阶导信息
传统的GBDT/GBRT 模型只用到了损失函数的一阶导信息(一阶泰勒展开),而XGBoost模型用到了损失函数的二阶展开,效果上更好一些。 -
支持自定义损失函数
XGBoost 支持自定义损失函数,只要满足定义的损失函数二阶可导即可,这大大增加了处理问题的灵活性。
3.加入正则化项
XGBoost 在 GBDT 的基础上加入了一个正则化项,用于控制模型的复杂度,正则化项里面包含了树的叶子节点数和各个叶子节点输出值的平方之和。从方差一偏差角度来看,正则化项可以降低模型的方差,使学习出来的模型更加简单,防止模型过拟合。 -
引入列抽样
XGBoost 模型借鉴了随机森林的做法,支持对特征进行抽样,这也可以起到降低过拟合风险和减少计算量的作用。 -
剪枝处理
当遇到一个负"增益"时,GBDT/GBRT会马上停止分裂,但 XGBoost 会一直分裂到指定的最大深度,然后回过头来剪枝。如果某个节点之后不再有负值,则会除掉这个分裂∶但是如果负值后面又出现正值,并且最后综合起来还是正值,则该分裂会被保留。 -
增加对缺失值的处理
XGBoost 对于不同节点遇到的特征缺失将采用不同的处理方式,并且会逐渐学习出处理缺失值的方式,当后面再遇到有缺失特征时就可以按学习出的处理方式进行处理,这样更加科学。 -
支持并行
XGBoost 支持并行,但是注意,XGBoost 的并行和RF 的并行不是同一类型的∶RF可以并行是因为其基学习器之间是没有关联的,每个基学习器的训练都是在总体训练样本中由放回的随机采样得到,因此可以同时训练各个基学习器;而 XGBoost 的基学习器之间具有强关联,每一个基学习器的训练都是建立在前面基学习器基础之上进行的,因此不可能直接做到各个基学习器之间的并行化处理。我们知道,决策树的学习过程最耗时的一个步骤就是对特征的值进行排序以确定最佳分割点,所以XGBoost在训练之前,预先对各特征数据进行了排序,并将其保存为 block 结构,利用这个block结构,各个特征的增益计算可以多线程进行,而且后面的迭代中可以重复地使用这个结构,从而大大减少了计算量。所以XGBoost 的并行不是在 tree粒度上,而是在特征粒度上。 -
模型训练速度更快
GBDT/GBRT 模型采用的是数值优化思维,即利用 CART 回归树去拟合损失函数的负梯度在当前模型的值,达到减小损失函数的目的;而 XGBoost 采用的是解析解思想,即对损失函数进行二阶泰勒展开,求得解析解,然后用这个解析解作为"增益"来辅助建立CART回归树,最终使得整体损失达到最优,因此XGBoost 的训练速度更快。
XGBoost和LightGBM的区别
(1)树生长策略:XGB采用level-wise的分裂策略,LGB采用leaf-wise的分裂策略。XGB对每一层所有节点做无差别分裂,但是可能有些节点增益非常小,对结果影响不大,带来不必要的开销。Leaf-wise是在所有叶子节点中选取分裂收益最大的节点进行的,但是很容易出现过拟合问题,所以需要对最大深度做限制 。
(2)分割点查找算法:XGB使用特征预排序算法,LGB使用基于直方图的切分点算法,其优势如下:
减少内存占用,比如离散为256个bin时,只需要用8位整形就可以保存一个样本被映射为哪个bin(这个bin可以说就是转换后的特征),对比预排序的exact greedy算法来说(用int_32来存储索引+ 用float_32保存特征值),可以节省7/8的空间。
计算效率提高,预排序的Exact greedy对每个特征都需要遍历一遍数据,并计算增益。而直方图算法在建立完直方图后,只需要对每个特征遍历直方图即可。
LGB还可以使用直方图做差加速,一个节点的直方图可以通过父节点的直方图减去兄弟节点的直方图得到,从而加速计算
但实际上xgboost的近似直方图算法也类似于lightgbm这里的直方图算法,为什么xgboost的近似算法比lightgbm还是慢很多呢?xgboost在每一层都动态构建直方图, 因为xgboost的直方图算法不是针对某个特定的feature,而是所有feature共享一个直方图(每个样本的权重是二阶导),所以每一层都要重新构建直方图,而lightgbm中对每个特征都有一个直方图,所以构建一次直方图就够了。
(3)支持离散变量:无法直接输入类别型变量,因此需要事先对类别型变量进行编码(例如独热编码),而LightGBM可以直接处理类别型变量。
(4)缓存命中率:XGB使用Block结构的一个缺点是取梯度的时候,是通过索引来获取的,而这些梯度的获取顺序是按照特征的大小顺序的,这将导致非连续的内存访问,可能使得CPU cache缓存命中率低,从而影响算法效率。而LGB是基于直方图分裂特征的,梯度信息都存储在一个个bin中,所以访问梯度是连续的,缓存命中率高。
(5)LightGBM 与 XGboost 的并行策略不同:
特征并行 :LGB特征并行的前提是每个worker留有一份完整的数据集,但是每个worker仅在特征子集上进行最佳切分点的寻找;worker之间需要相互通信,通过比对损失来确定最佳切分点;然后将这个最佳切分点的位置进行全局广播,每个worker进行切分即可。XGB的特征并行与LGB的最大不同在于XGB每个worker节点中仅有部分的列数据,也就是垂直切分,每个worker寻找局部最佳切分点,worker之间相互通信,然后在具有最佳切分点的worker上进行节点分裂,再由这个节点广播一下被切分到左右节点的样本索引号,其他worker才能开始分裂。二者的区别就导致了LGB中worker间通信成本明显降低,只需通信一个特征分裂点即可,而XGB中要广播样本索引。
数据并行 :当数据量很大,特征相对较少时,可采用数据并行策略。LGB中先对数据水平切分,每个worker上的数据先建立起局部的直方图,然后合并成全局的直方图,采用直方图相减的方式,先计算样本量少的节点的样本索引,然后直接相减得到另一子节点的样本索引,这个直方图算法使得worker间的通信成本降低一倍,因为只用通信以此样本量少的节点。XGB中的数据并行也是水平切分,然后单个worker建立局部直方图,再合并为全局,不同在于根据全局直方图进行各个worker上的节点分裂时会单独计算子节点的样本索引,因此效率贼慢,每个worker间的通信量也就变得很大。
投票并行(LGB):当数据量和维度都很大时,选用投票并行,该方法是数据并行的一个改进。数据并行中的合并直方图的代价相对较大,尤其是当特征维度很大时。大致思想是:每个worker首先会找到本地的一些优秀的特征,然后进行全局投票,根据投票结果,选择top的特征进行直方图的合并,再寻求全局的最优分割点。
- XGBoost中如何对树进行剪枝
在目标函数中增加了正则项:使用叶子结点的数目和叶子结点权重的L2模的平方,控制树 的复杂度。
在结点分裂时,定义了一个阈值,如果分裂后目标函数的増益小于该阈值,则不分裂。
当引入一次分裂后,重新计算新生成的左、右两个叶子结点的样本权重和。如果任一个叶 子结点的样本权重低于某一个阈值(最小样本权重和),也会放弃此次分裂。
XGBoost先从顶到底建立树直到最大深度,再从底到顶反向检查是否有不满足分裂条件的 结点,进行剪枝。
- XGBoost如何选择最佳分裂点?
XGBoost在训练前预先将特征按照特征值进行了排序,并存储为block结构,以后在结点分裂时 可以重复使用该结构。
因此,可以采用特征并行的方法利用多个线程分别计算每个特征的最佳分割点,根据每次分裂后 产生的増益,最终选择増益最大的那个特征的特征值作为最佳分裂点。
如果在计算每个特征的最佳分割点时,对每个样本都进行遍历,计算复杂度会很大,这种全局扫 描的方法并不适用大数据的场景。XGBoost还提供了一种直方图近似算法,对特征排序后仅选择 常数个候选分裂位置作为候选分裂点,极大提升了结点分裂时的计算效率。
•基分类器的scalability:弱分类器可以支持CART决策树,也可以支持LR和Linear.
•目标函数的scalability:支持自定义loss function,只需要其一阶、二阶可导。有这个特 性是因为泰勒二阶展开,得到通用的目标函数形式。
•学习方法的scalability: Block结构支持并行化,支持。ut-of-core计算。
我们采用三种方法来评判XGBoost模型中特征的重要程度:
官方文档:
(1)weight - the number of times a feature is used to split the data across all trees.
(2)gain - the average gain of the feature when it is used in trees.
(3)cover - the average coverage of the feature when it is used in trees.
•weight :该特征在所有树中被用作分割样本的特征的总次数。
•gain :该特征在其出现过的所有树中产生的平均増益。
•cover :该特征在其出现过的所有树中的平均覆盖范围。
注意:覆盖范围这里指的是一个特征用作分割点后,其影响的样本数量,即有多少样本经过 该特征分割到两个子节点。
首先需要初始化一些基本变量,例如:
•maxdepth = 5
•min_child_weight = 1
•gamma = 0
•subsample, colsample bytree = 0.8
•scale_pos_weight = 1
(1)确定learning rate和estimator的数量
learning rate可以先用0.1,用cv来寻找最优的estimators
(2)max_depth和 min_child_weight
我们调整这两个参数是因为,这两个参数对输出结果的影响很大。我们首先将这两个参数设置为 较大的数,然后通过迭代的方式不断修正,缩小范围。
max_depth,每棵子树的最大深度,check from range(3,10,2)o
min_child_weight,子节点的权重阈值,check from range(1,6,2)O
如果一个结点分裂后,它的所有子节点的权重之和都大于该I阈值,该叶子节点才可以划分。
(3)gamma
也称作最小划分损失min_split_loss , check from 0.1 to 0.5,指的是,对于一个叶子节 点,当对它采取划分之后,损失函数的降低值的阈值。
•如果大于该阈值,则该叶子节点值得继续划分
•如果小于该阈值,则该叶子节点不值得继续划分
(4)subsample, colsample_bytree
subsample是对训练的采样比例
colsample_bytree是对特征的采样比例
both check from 0.6 to 0.9
(5)正则化参数
alpha 是L1 正则化系数,try 1e-5, 1e-2, 0.1, 1, 100
lambda是L2正则化系数
(6)降低学习率
降低学习率的同时増加树的数量,通常最后设置学习率为0.01~0.1
以上是关于面试笔试题集:集成学习,树模型,Random Forests,GBDT,XGBoost的主要内容,如果未能解决你的问题,请参考以下文章