Airbnb 在搜索中应用深度学习的经验
Posted Python中文社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Airbnb 在搜索中应用深度学习的经验相关的知识,希望对你有一定的参考价值。

关于这篇论文有趣的地方在于,并不是提出一个新颖的算法或模型,而是介绍了爱彼迎在应用深度学习的过程中,发现了哪些有趣且有用的点,进而分享给大家。在此之前,作者表示一直使用 GBDT 进行搜索排序,然而已经陷入了一个瓶颈期,需要深度学习来帮助打破这个瓶颈。
接下来我们一起看看,爱彼迎在应用深度学习的过程中遇到了哪些困难和收获吧。
背景
在爱彼迎的场景中,是作为一个双边市场的交易平台:为房东出租房屋,并且为潜在的租客提供房屋。而大多数情况下,一次订房行为都是从搜索开始的。
搜索排序的第一版往往是手工构建一个打分函数,对爱彼迎而言,在此之后的下一个里程碑就是 GBDT,当 GBDT 的收益难以再进一步时,爱彼迎开始投入了深度学习的怀抱。
除了排序,对整个搜索系统而言,模型需要预测房东愿意接受租客订房的概率,需要预测租客会给 5 星好评的概率等等。
在爱彼迎中,用户往往是搜索->浏览->搜索...->订房,通过多次的搜索与浏览最终实现订房的操作,而这些行为会用来训练数据。训练好的模型再开始进行线上 A/B。
这篇文章的整体结构就是先介绍爱彼迎搜索模型的进化过程,然后是特征工程和系统工程,最后是一些工具和超参的探索。
我个人喜好这篇文章的地方也在于,不同于其它常见的 paper,都是努力讲明自己提出了一个新颖的模型,然后结构是如何,最后实验验证它很优秀。这篇文章重点是告诉大家爱彼迎在搜索上的一些探索与进步,从宏观的角度来为大家展示如何将一个工程逐渐深度化,并且这其中有哪些需要关注的细节。
模型进化
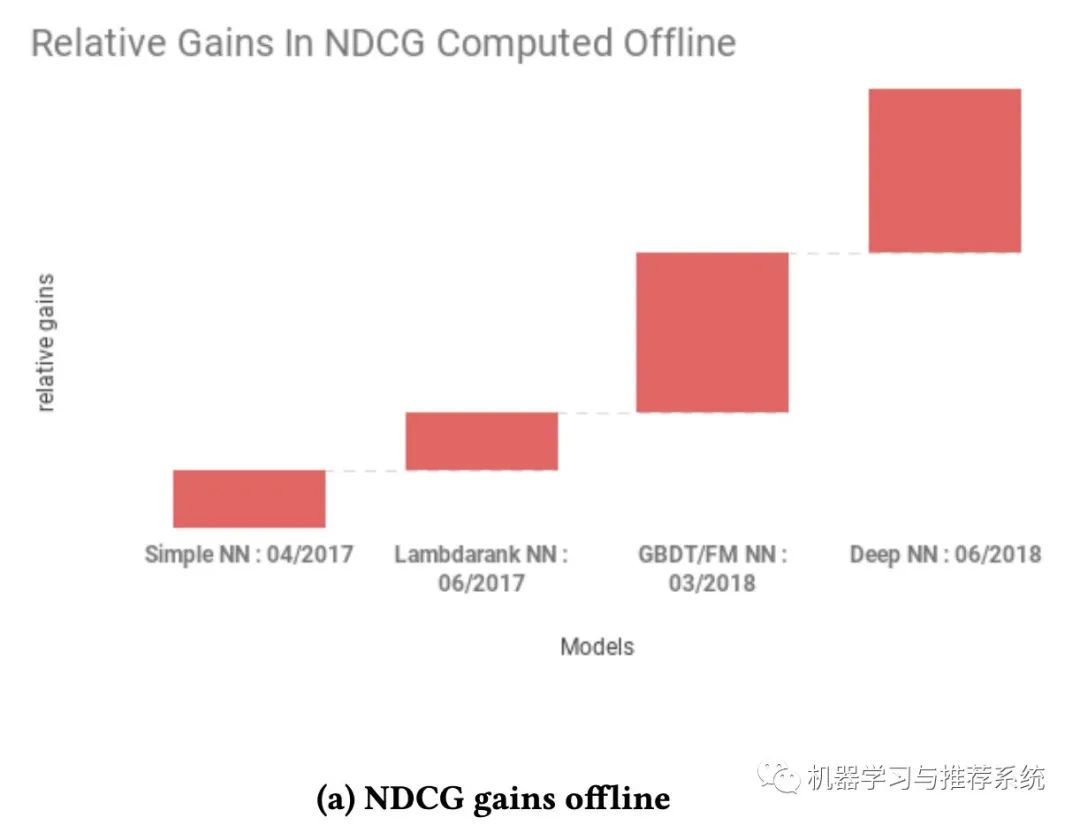
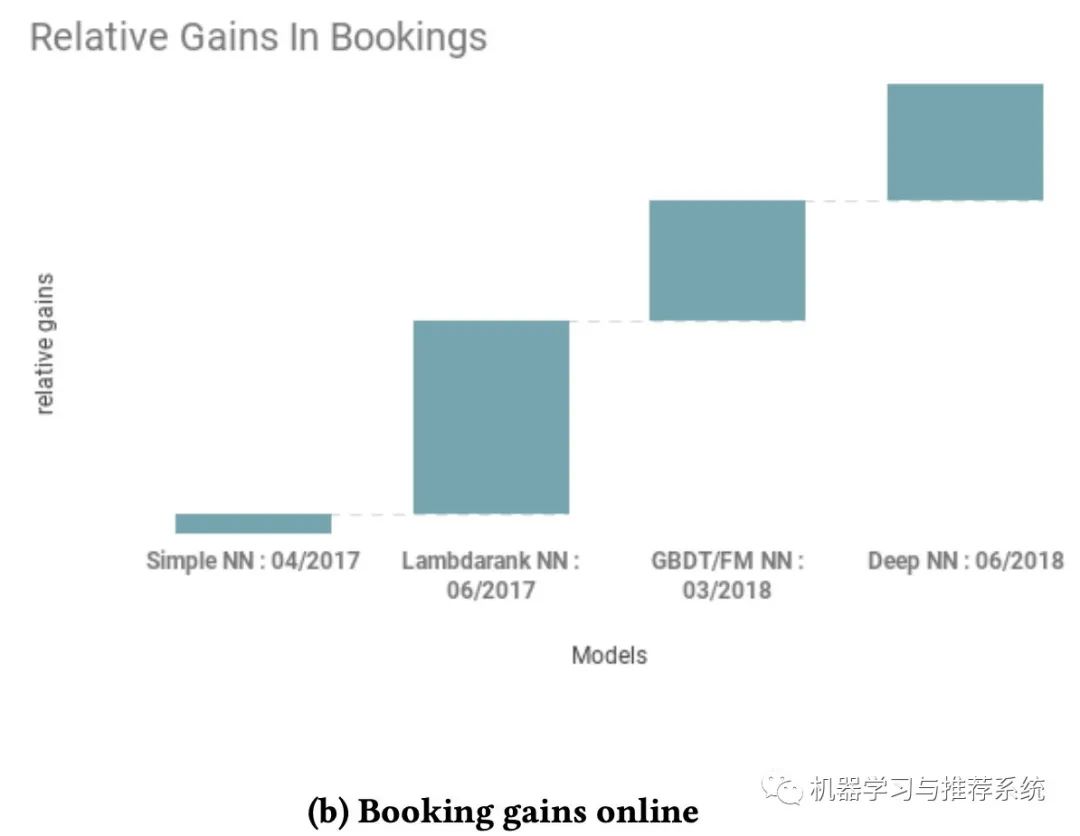
这两幅图分别展示了爱彼迎在搜索中尝试的不同模型,一个是在离线的 NDCG 表现,另外一个则是在线订房的收益。
初步的时候是一个简单的单层 NN 网络,主要是为了跑通整个 pipeline(这和我上篇文章的年度总结中提到的不谋而合)。当完成一个单层网络时,爱彼迎开始逐步优化他们的网络。因为离线指标是 NDCG,所以选择了 lambdarank。
作者在这里给出了一段简要的代码来展示他们的思路:

「Decision Tree/Factorization Machine NN」:除了 lambdaRank,作者表示他们进行了一个模型融合的尝试,将 GBDT,FM 和 NN 结合起来,结构也很直接:
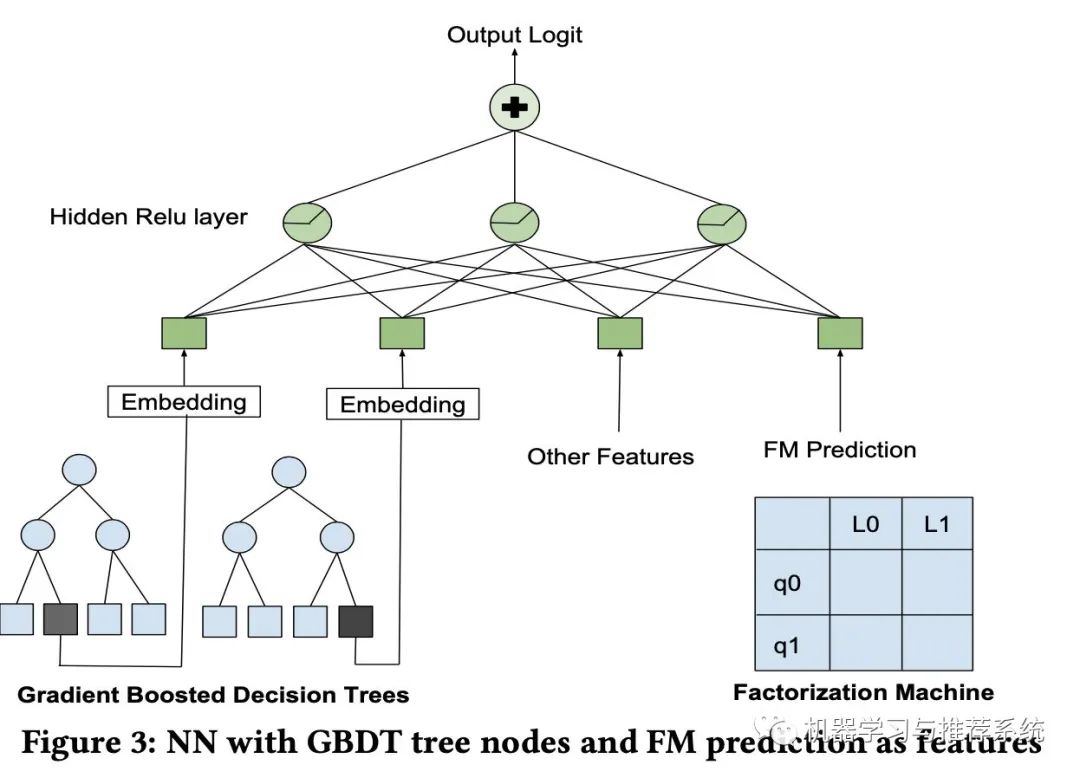
作者表示,虽然将三个模型结合在测试集的指标表现与直接使用神经网络差不多,但是最终列表的头部顺序却大不相同,因此,作者认为模型的融合结合了三类模型的各自优点,但是这里文章中并没有给出进一步的阐述。倒是给了一个参考文献,[我会展示在后面](Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017. Deep & Cross Network for Ad Click Predictions. In Proceedings of the ADKDD'17 (ADKDD'17). ACM, New York, NY, USA, Article 12, 7 pages.)。
「Deep NN」:接下来就是进入 DNN 时代,作者表示 DNN 就是好使唤。没啥好说的,就是牛逼。作者说他们的初始数据特征都是一些简单的东西,什么价格,设备情况,历史订阅数等,另外还用了两个模型的输出也作为特征喂了进去。
如下图,随着训练数据的增多,训练集和测试集之间的 gap 也逐渐消失:
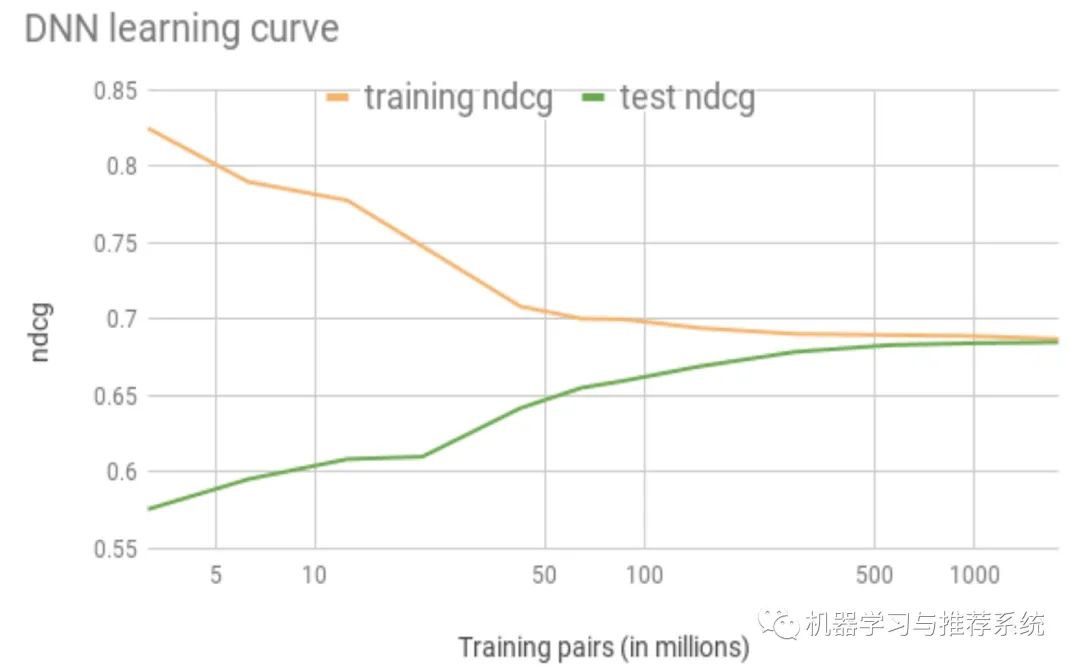
但是作者表示,不想 DNN 在 CV 领域取得的巨大成功一样(机器和人类的准确度差不多),在当前场景中,人类也无法判断哪些内容是应该正确展示的:毕竟搜索了以后,订不订房子还主要取决于用户的预算和品位风格。
在这里作者表示,要介绍一些其它时候很少有人介绍的东西:一些失败的尝试
失败的模型
成功者千篇一律,失败者却各有千秋。对模型也是有几分相似,作者表示失败的尝试太多了,挑两个经典的聊聊:
listing ID
将 item 的交互 ID list 作为特征,直接喂进模型,在搜索,推荐,nlp 等领域都是常见操作,也往往会非常有效,爱彼迎在开始前也是充满了希望。但能写到这里,可见结果肯定是大失所望。
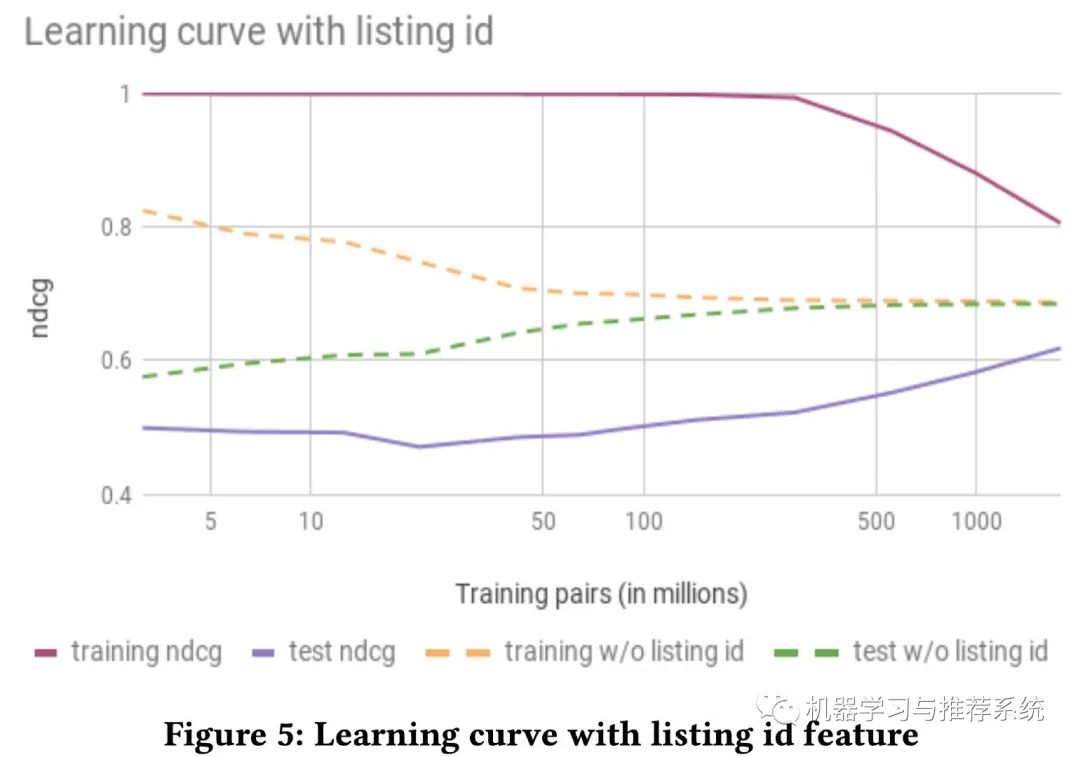
如上图所示,加了 ID 特征和不加 ID 特征,收敛速度以及程度都有很大差异,可见带了 ID 特征的,往往会陷入过拟合。
作者分析了这种现象的可能原因:由于爱彼迎特殊的业务性质导致。
因为在其它领域,比如抖音这种,一个短视频被观看的次数是不受限制;比如在淘宝,一个商品被购买的次数也是不受限制的。而将 ID 的交互记录作为一条特征,本身就需要这样大量的行为记录。但是在爱彼迎,即使最热门的房间,一年也最多被订 365 次。
所以这一条也表明,我们在选择特征时需要充分考虑自己的业务场景,而这是建立在对自己当前业务 sense 的基础上。
多任务学习
考虑到订房这一行为的限制,爱彼迎就开始考虑浏览行为是不受限制的,能不能从浏览行为入手呢?
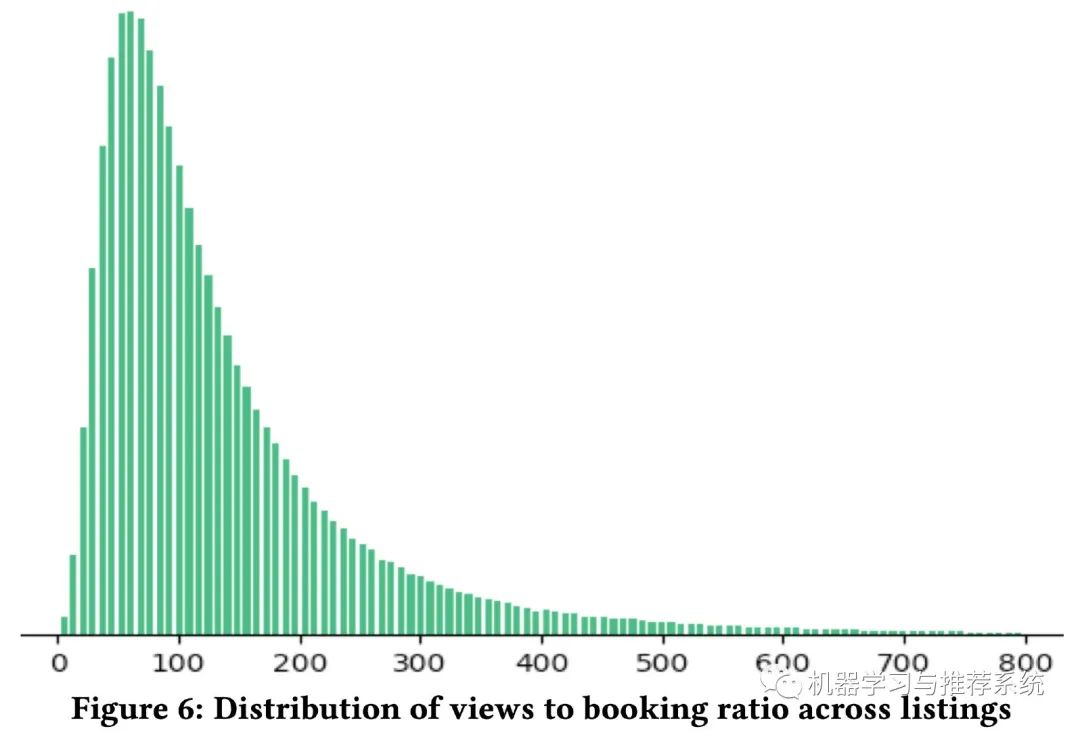
上图展示了浏览和订阅之间的比例分布,看得出订阅相比于浏览记录要稀疏很多。另一方面,越多的浏览量一般越容易带来订房行为。因此爱彼迎进行了一个多任务学习模型,将订房和浏览时长都作为优化目标。
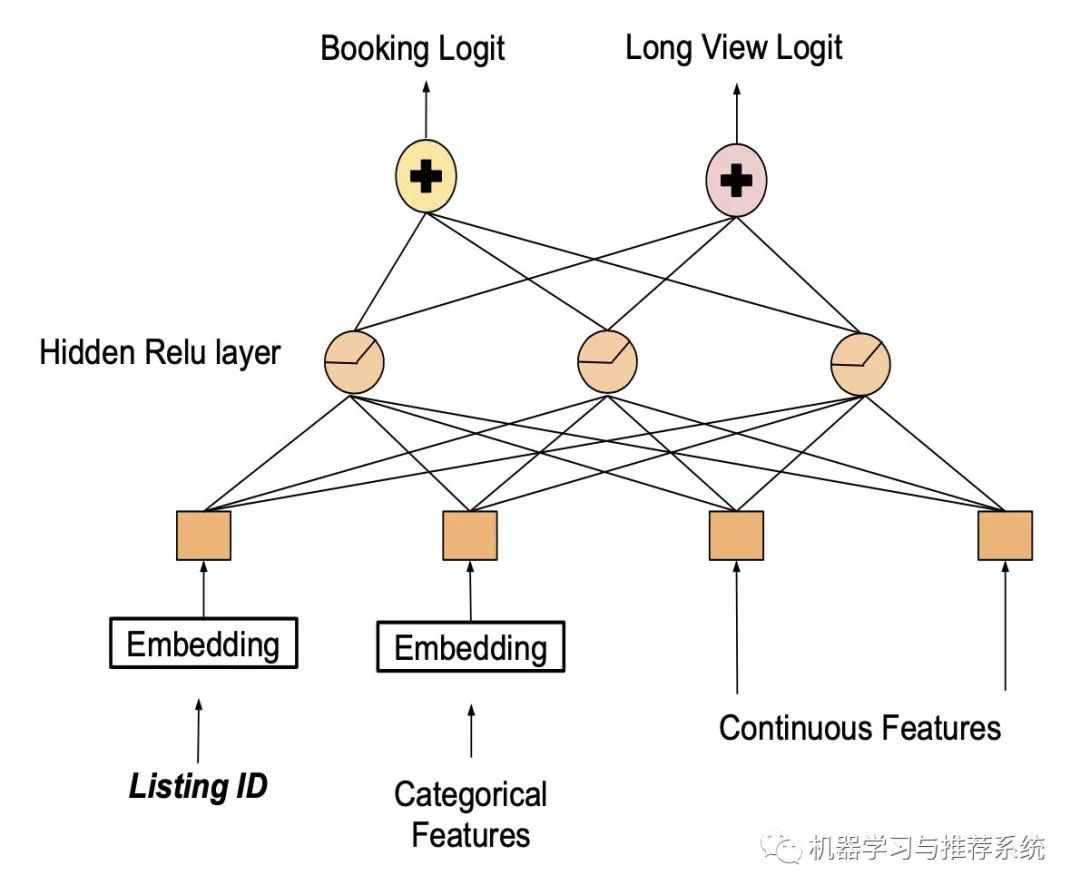
设计好模型以后,哎,现在可以用 listing ID 了吧。
最后一看,结果不妙,好家伙,这模型净给人展示那些特别贵,或者特个性的房间了,用户的确爱看,浏览时长也的确增加,但是对订房本身的指标没太大帮助呀。
特征工程
这里爱彼迎提出了一些思路,对特征进行处理使其满足某些属性,帮助神经网络可以有效的进行数学运算。
特征正则化
在一开始,作者直接使用了他们以前在 GBDT 中的特征,但是效果不好。追述原因后发现,GBDT 对特征的具体数值不是很关心,主要是关心特征数值之间的相对顺序。但是神经网络对数值是很敏感的。
如果不是同一类的特征,数值范围差异很大,会导致梯度传播误差过大。比如某些太大的值直接使得 ReLU 函数失效,产生梯度消失。
所以对输入的特征,最理想的就是让他们的范围集中在 -1 到 1 之间,且均值为 0。
为此,作者提出了两个正则化的方法:
对服从正态分布的特征,通过 (feature_val − μ)/σ 来转换其分布;
对服从幂律分布的特征,通过 log((1+feature_val) / (1+median)) 来转换其分布。
特征分布
通过上一步可以将特征的分布平滑,可是为什么要做平滑这件事呢?
排查 bug
首先就是样本中的异常特征值,通常是很难直接观察出来的。但是如果样本的特征是平滑的,这个时候做一个分布图出来,就可以很容易看到那些异常的样本特征值。
比如某个地区的房价作为一个特征,如果某条样本误将过去一个月的订房价当做了一天的订房间,那么在特征的分布图中,这个值就会很明显的突起。
有利于模型的泛化能力
神经网络相比于其它机器学习方法,优势之一就是出色的泛化能力,从这个角度,作者进行了分析,提出了特征分布平滑的作用。
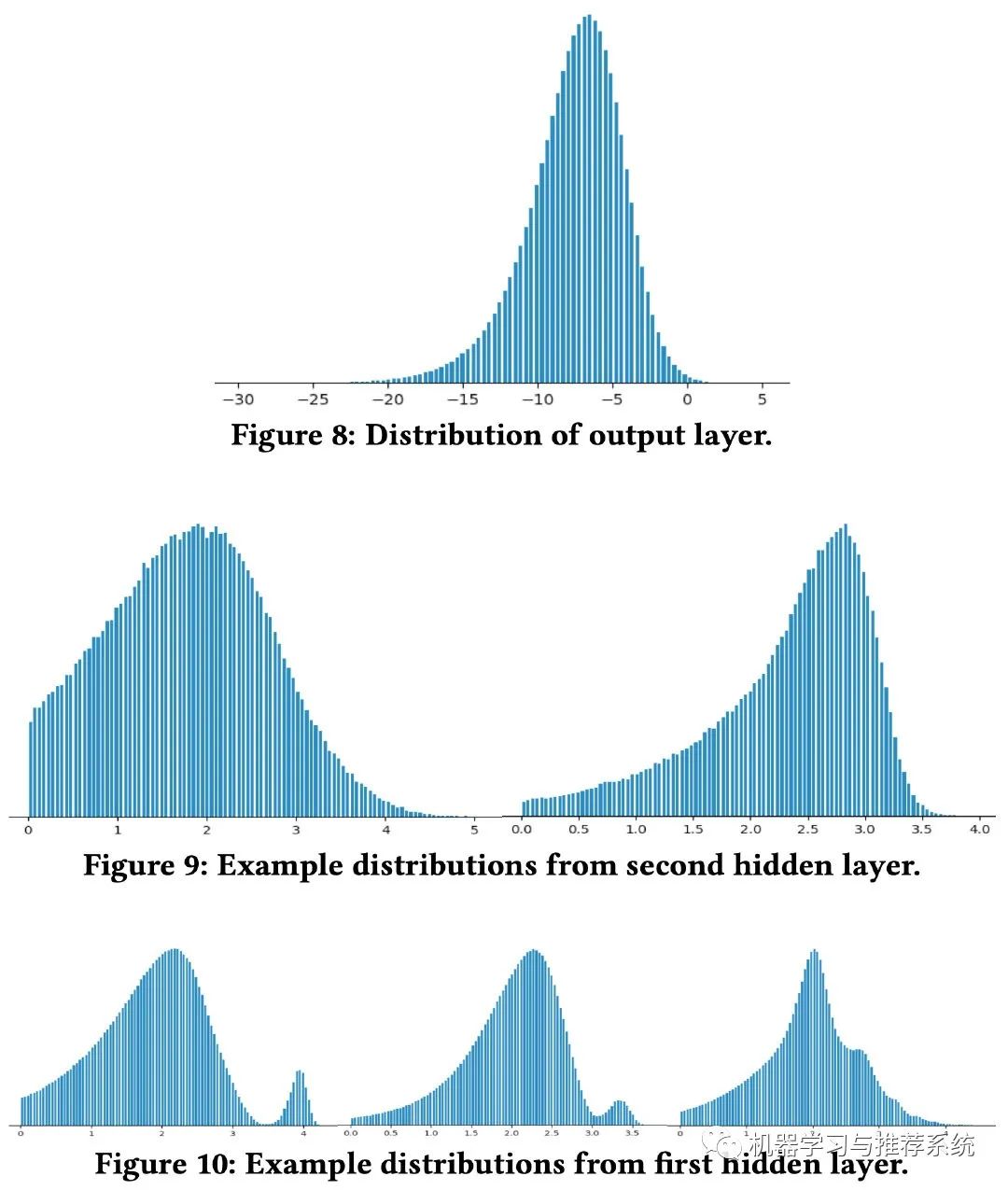
上面这幅图分别展示了神经网络的每一层输出的分布情况,可以观察到,最终的输出层分布最为平滑。而且是从输入层开始逐渐越来越平滑。这是不是神经网络具有优秀泛化能力的原因呢?
作者表示,在实际应用中,模型都是通过训练数据来学习一个高维特征空间中的分布。但是在训练的时候,不可能所有的特征组合都被观察到,所以模型训练的过程就是从不平滑的分布中去逐渐插值学习。
这样也可以理解,下层分布越平滑,上层就越可能对看不到的特征进行插值。而最底层自然就是输入层。
另一方面为了验证泛化能力,作者尝试了将所有的价格都 x2,x3,x4等等,结果最终的 NDCG 都是出奇的稳定。
一般来讲,特征平滑是很容易做到的。稍微进行处理就可以轻松的将特征分布迁移到合适且平滑的形式,但是有时候针对某些特征,爱彼迎还是做了一些专门的特征工程去让它们的分布平滑起来。
其中一个例子就是针对用户搜索后展示房子的地理位置,下面这幅图记录了整个过程:一开始是经纬度的分布,明显很不平滑;后面改为距离用户搜索地图中心的距离,再后来又加上了对数函数;最终就得到了一个满足要求的特征分布。
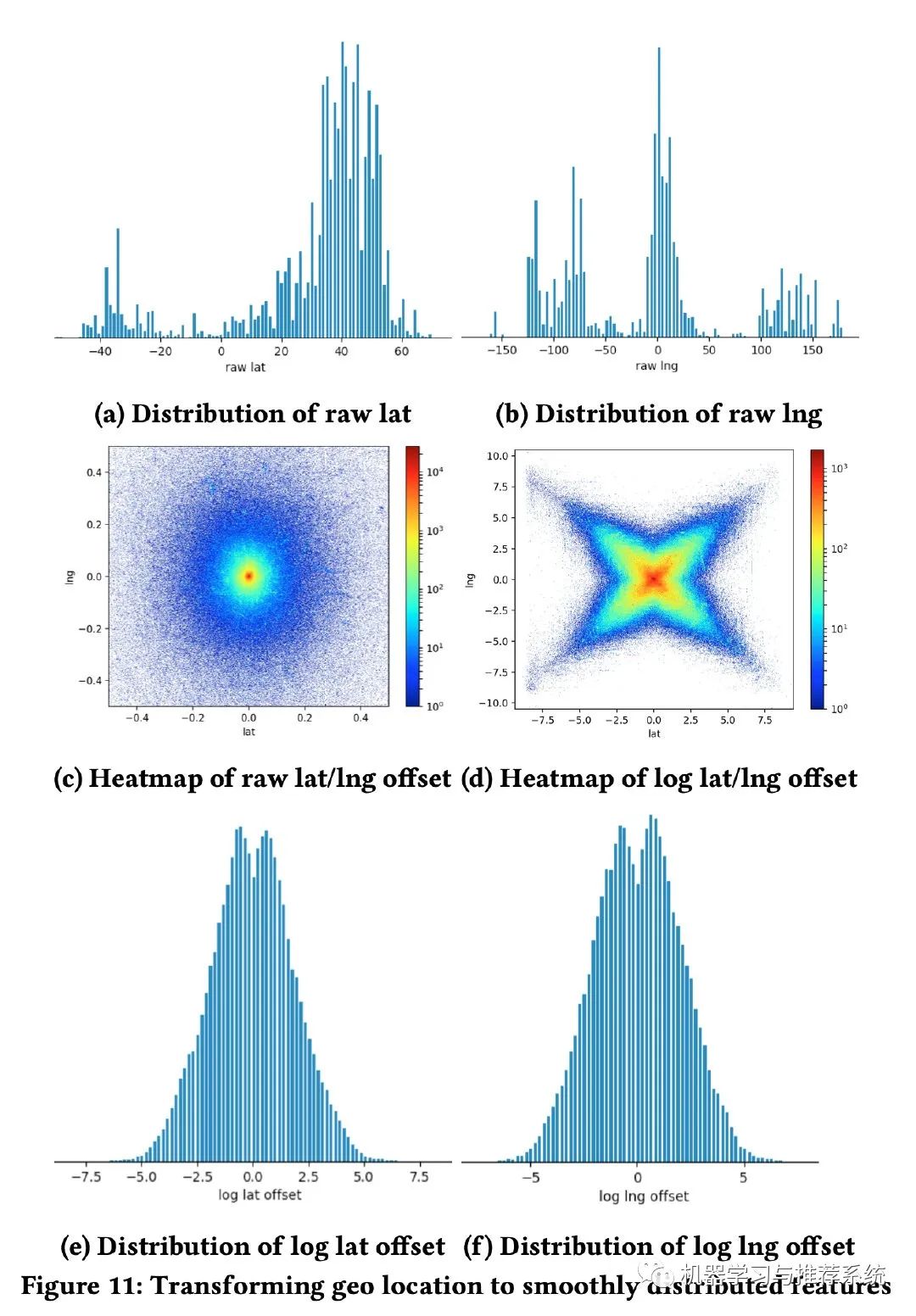
检查特征的完整性
特征的分布如果不平滑,有可能会帮助我们检查特征的完整性(其实某种程度上,我觉得也可以和前面的排查 bug 有些类似)。
作者在这里举了一个例子是用房子的入住天数作为特征,结果发现分布不平滑,如下左图。究其原因是部分房源要求入住的最短时长不同,有的甚至要求最少几个月。
所以作者利用平均入住天数做了一个平滑,就形成了右图的幂律分布。

高基特征
前面尝试过 listing ID,但是效果不好。那么爱彼迎还在哪些方面尝试过高基分类特征呢?
这里举了一个例子,就是地理位置,直接利用了谷歌的 s2 地图库。通过将地名和 s2 地图库结合起来,做一个哈希函数,然后得到的哈希值作为一个特征向量,喂进神经网络进行学习。
例如 {”San Francisco”, 539058204} → 71829521
最终的一个应用例子如下:
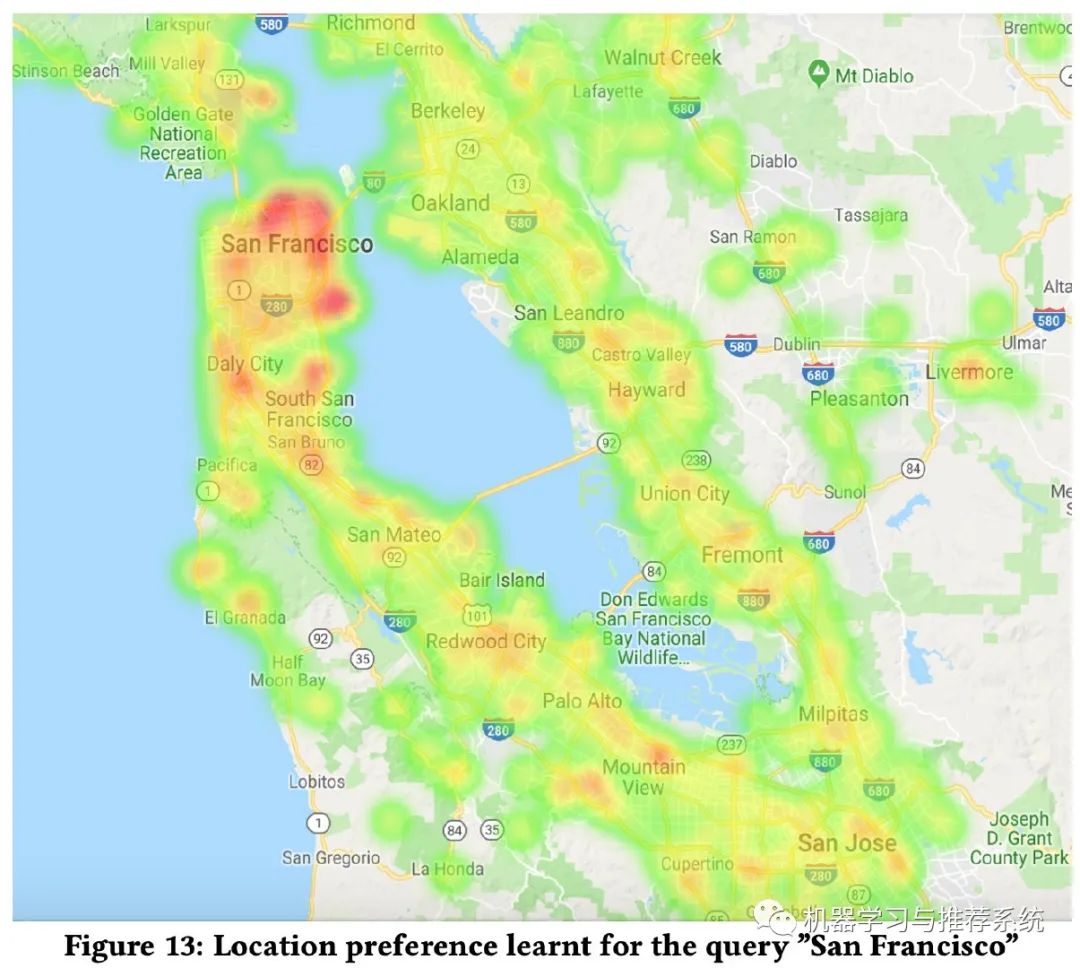
可以看到这个热力图,当搜索 San Francisco 时,并不是单纯的以这里为热力图中心,直接线性距离发散热度。明显 San Francisco 下方的陆地比旁边的水域邻居更具有热度。
系统工程
这里整体流程可能和大家是比较相似的,线上服务是一个 Java 服务。处理数据用 spark,训练模型用 TensorFlow,数据分析用 Scala 和 Java 等。
这里作者提到几个 trick,可能会对我们有帮助:
protobufs 和数据集
在之前他们用的是 GBDT,数据是 CSV 文件,开始神经网络以后,他们沿用了这套数据格式,将 CSV 转化成 feed_dict 喂进网络。但是发现 GPU 利用率只有 25%。
后来他们使用 protobufs 和数据集,避免了训练时对数据的格式转换,这一步大约带来 17X 的训练加速,并且 GPU 利用率达到 90%。
静态特征
对爱彼迎这种业务而言,一套房子的硬性特征是不会改变的(至少轻易不会改变),比如房子的地理位置,房子的结构,公共设施等。每条训练数据的这些特征不断的加载,是很大的 IO 消耗。
所以爱彼迎直接使用房子的 ID 作为特征,来取代掉这些静态特征,只有当这些信息发生变化时,才会加载进训练。
Java 神经网络库
这里就是简单介绍了一下,他们自己开发了一个 Java 神经网络库。
超参
这一部分也没啥内容 ==!
爱彼迎的结果就是 dropout 效果不明显,作者觉得原因是 dropout 适合那些数据噪音比较大的情况。
再就是初始化权重,他们觉得在 -1 到 1 之间随机,比全部设 0 好。
学习率和 batch size 没调出来啥东西~~~
特征的重要性
这里作者也做了一些分析,我们简单的概括出来就是:
得分拆解
如何知道哪些特征比较重要,哪些特征可以省略呢?作者想到了从最后的得分进行拆解,但是后来得出一个结论,凡是经过了非线性激活函数的特征,根本无法分离出其对最终得分的真正影响,所以这样的拆解都是没有意义的~~
AB 测试
这个显然易见,每次少一个特征,然后去观察性能变化。但是作者说,每次去掉一个特征的影响,甚至都无法和训练中的数据噪音区分出来。
重新排列一部分特征
另外一个思路就是将某类特征的值全部随机化,再来判断性能。这样子这些特征依然生效,但是打乱值后看看它是否会对模型构成影响。这样子的确可以观察到一些特征的重要性。
但是作者提出了几点需要注意的地方:第一,观察的特征需要与其它特征独立,这往往是很难实现的;第二,由于打乱了特征值,所以可能会对模型最终的结果构成影响(比如构建出一些现实生活中不存在的特征组合),进而误导我们的方向。
####结果的特征分析
这里的思路是利用测试集上的结果,将结果排序,分析头部和尾部的特征分布,就可以知道模型在不同的取值范围如何应用这些特征。
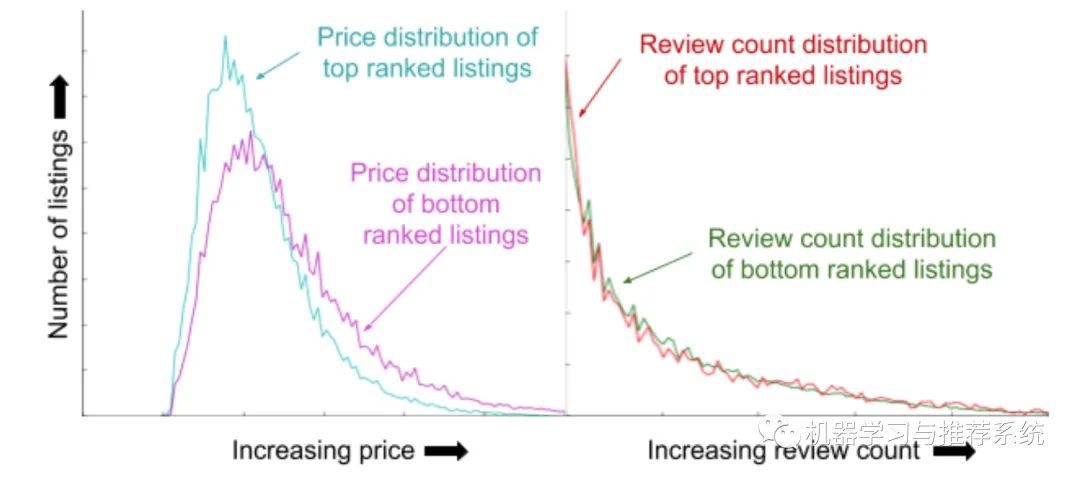
考虑了价钱所以头部和尾部的结果对价钱的分布就有所不同,但是浏览时长的特征没有被考虑,分布就很接近。这也是一个去分析特征重要性的方法。
总结
正如文章最后说的一样,他们感觉自己对深度学习在搜索的应用才刚刚开始。
将某项业务从非深度学习模式切换到神经网络上来,并不是直接喂到模型里就完事儿的,需要前期逐步的稳扎稳打,当整个 pipeline 打通,数据,特征工程,系统工程等等都完备了,才是你开始探索模型的时候。
而这个探索的过程,本质上其实考验的还是你对业务的熟悉和理解。
我自己最近也在迁移一项搜索工程,准备将其整个 NN 的链路打通,这篇文章带给我的启发还是多的。不过最主要的核心,其实还是对业务的理解,可以看到上面很多内容,都是可以从爱彼迎本身的业务角度阐释的。
更多阅读
特别推荐


点击下方阅读原文加入社区会员
以上是关于Airbnb 在搜索中应用深度学习的经验的主要内容,如果未能解决你的问题,请参考以下文章
深度学习与图神经网络核心技术实践应用高级研修班-Day4深度强化学习(Deep Q-learning)
本周学习计划 | 微服务搜索引擎架构Hbase源码剖析深度学习……
从手淘搜索到优酷短视频,阿里巴巴是如何在搜索推荐领域下应用深度学习的?