MYSQL 中的 LIKE 这么用不对?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MYSQL 中的 LIKE 这么用不对?相关的知识,希望对你有一定的参考价值。
我这是哪写错了?为什么是 empty set 呢?
还有 LIKE 和 REGEXP 有什么区别?
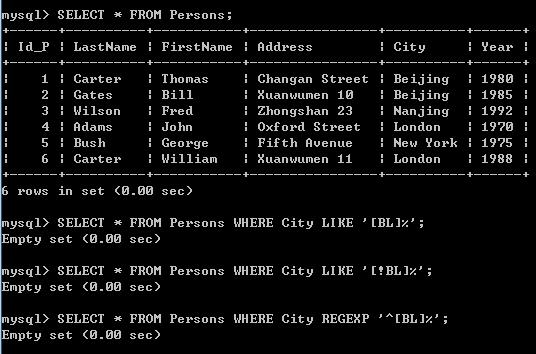
REGEXP 是正则表达式匹配。
WHERE City REGEXP '^[BL]'
就可以了。
就是满足 字母 B 或者 L 开头的, 检索出来。
因为 % 是用于 LIKE 的。 不是用于 正则表达式的。
REGEXP 和 like 在匹配上的区别
其中like要求整个数据都要匹配,而REGEXP只需要部分匹配即可。
也就是说,用Like,必须这个字段的所有内容满足条件,而REGEXP只需要有任何一个片段满足即可。 参考技术A mysql中不支持你写的like后面的这种方式 参考技术B 如果找city中含有B 或L的
select * from persons where city like '%B%' or city like '%L%'
其实 MySQL 中的 like 关键字也能用索引
上篇文章中,松哥和大家分享了索引的两个使用规则:
- 索引上不要使用函数运算。
- 使用覆盖索引避免回表。
当然,凡事有个度,用哪一种策略也要结合具体的项目来定,不能为了 SQL 优化而抛弃了业务。
今天,松哥在前文的基础上,再来和大家分享一条索引规则,一起来学习下。
我们常说,MySQL 中的 like 要慎用,因为会全表扫描,这是一件可怕的事!不过呢,也看情况,有的 like 其实也能用索引:有的时候 like 用索引效率很高,有的时候 like 虽然用了索引效率却低的可怕。
我们一起来分析下。
1. 最左匹配原则
我还是举个例子吧,假设我有如下一张表:
CREATE TABLE `user` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`birthday` date DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`address` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `username` (`username`,`age`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
username 和 age 组成了复合索引,复合索引名为 username,下文提到的 username 索引都是指该复合索引。
根据上篇文章(是时候检查一下使用索引的姿势是否正确了!)的讲解,我们知道,对于如下 SQL:
select username,age from user2 where username='javaboy' and age=99;
这个 SQL 在查询的过程中,会用到覆盖索引,避免回表,提高查询效率。
那么现在问题来了,如果我单纯的只是想通过 username 字段查询用户呢,是否需要为 username 字段单独建立一个索引?
我们来看如下一条 SQL:
select username,age from user2 where username='javaboy';
由于我的表中没有为 username 字段建立的索引,那么它会不会使用已有的复合索引呢?我们来看下执行计划:

可以看到,这里其实用到了 username 复合索引,通过 Extra 字段的值还能看到使用到了覆盖索引。
为啥会这样呢?在 B+Tree 这种索引结构中,可以利用索引的“最左匹配”来定位记录。最左匹配既可以是匹配复合索引中的前几个字段,也可以是匹配第一个字段的前几个字符,在上面的案例中,我们匹配的是复合索引中的第一个字段。
当然我们也可以匹配第一个字段的前几个字符,如下:
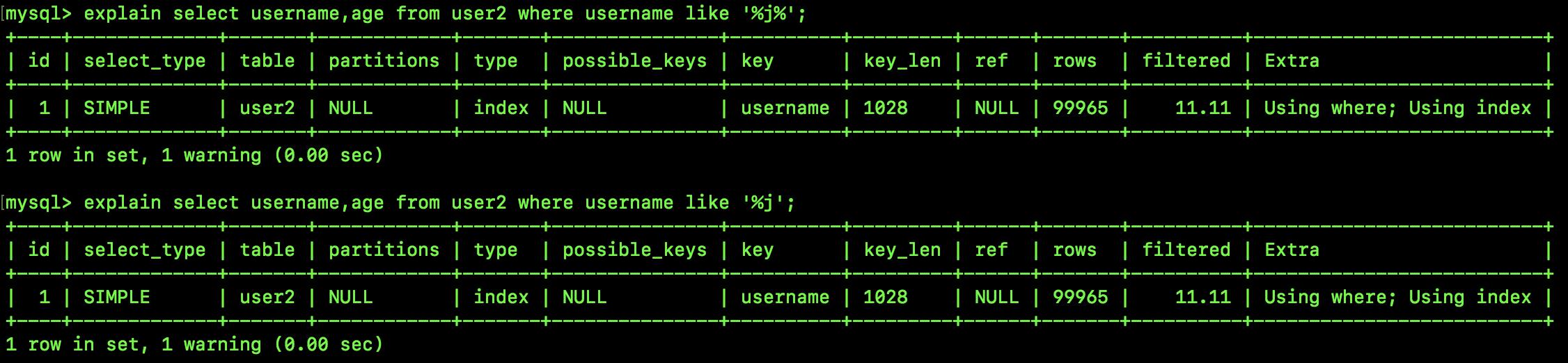
select username,age from user2 where username like 'j%';
执行计划如下:

从这执行计划中首先可以确认这个查询也用到了 username 复合索引。
不过这里的查询计划和前面的不太一样,两条 SQL 的区别在于一个是等于号一个是模糊匹配,查询计划的主要区别在于 type 和 Extra:
- 前面的 type 为 ref 表示通过索引查找数据,一般出现等值匹配的时候,type 会为 ref;后面这个 type 为 range 表示这是一个索引的范围扫描(因为是模糊匹配,而模糊匹配可以形成扫描区间)。
- 前面的 ref 为 const 表示与索引列进行等值匹配的是一个常量。
- 前面的 Extra 为
Using index表示使用到了覆盖索引;后面的 Extra 为Using where;Using index,表示用到了索引,但是还需要进行过滤。
对于第一点中加粗的字体,我再来和大家多说两句。为什么说模糊匹配就能形成扫描区间呢?因为我们是按照 username 和 age 建立的复合索引,username 在前 age 在后,具体存的时候,是按照 username 排序存储,如果 username 相同,则按照 age 排序存储,结构类似下面这样:
| username | age |
|---|---|
| a | 88 |
| b | 89 |
| c | 89 |
| c | 90 |
| c | 99 |
| d | 88 |
| d | 99 |
所以当想要搜索以 j 开头的 username 时,只需要定位到第一个以 j 开头的 username,然后利用 B+Tree 叶子结点之间的双向链表继续向后读取,读到第一个不是以 j 开头的 username 时截止,这就是扫描区间。
大家看到了,在上面的执行计划中,like 'j%' 其实也用到了索引,那么如果是 like '%j' 或者 like '%j%' 会用到索引吗?我们来看一个例子:
咦!看执行计划似乎也用上索引了!难道只要字段上有索引,like 就能用索引?
当然不是!
大家来看松哥下面这个辅助案例,看懂了就明白了。
2. 辅助案例
为了让大家更好的理解上面所说的最左匹配,松哥再来举一个例子。
还是上面的表和数据结构,但是现在假如我想按照 age 来做查询,SQL 如下:
select username from user2 where age=99;
select username from user2 where age>99;
我举了两个查询的例子,大家一起来看下这两条 SQL 的执行计划,其实没啥差异:
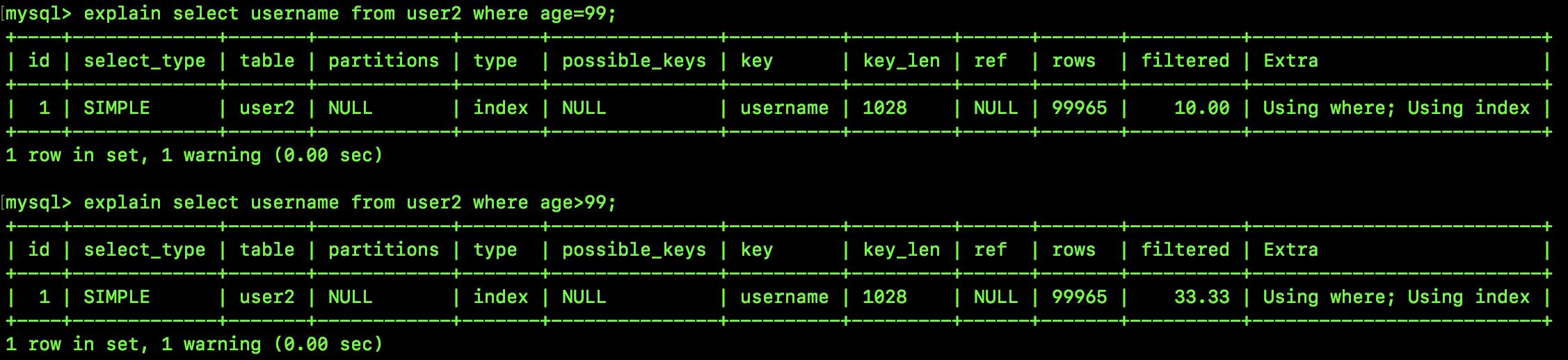
这个查询计划我们该如何解释呢?其实这两个查询计划没啥区别,我就解释一个吧。
首先大家想一下,username 和 age 建立的是复合索引,username 在前 age 在后,具体在 B+Tree 中存储的时候,首先是按照 username 排序的,当 username 相同的时候,再按照 age 来排序,所以这个复合索引最终存储的结果就是,username 是有序的,而 age 是无序的,再来回顾下这个表格:
| username | age |
|---|---|
| a | 88 |
| b | 89 |
| c | 89 |
| c | 90 |
| c | 99 |
| d | 88 |
| d | 99 |
username 是有序的,而 age 是无序的。
理解了这个,我们再来看这个执行计划就好懂了。
当我们按照 age 去搜索的时候,因为 age 在 username 索引中是无序的,所以只能遍历 username 索引,而执行计划中的 type 为 index,恰恰就表示需要扫描全部的索引记录。以第一条查询 SQL 为例,扫描全部的索引记录,然后过滤出 age 等于 99 的记录(过滤这一步是在 server 层完成的),rows 表示预估的扫描行数,从最后的 Extra 的 Using where;Using index 也能看出这一点,即用到了索引,但是也对数据进行了过滤。
回顾第一小节的最后 like '%j' 和 like '%j%' 的执行计划,不就是上面这个吗!
在前面这两条 SQL 中,因为我们查询的 username 字段已经存在于 username 索引中了,所以可以通过覆盖索引机制直接从索引中获取想要的数据并返回,不需要回表操作了。
- 如果大家不懂覆盖索引戳这里:是时候检查一下使用索引的姿势是否正确了!。
- 如果大家不懂回表戳这里:什么是 MySQL 的“回表”?。
但是如果我们查询的字段不仅仅是索引中的字段,例如如下 SQL:
select * from user2 where age=99;
查询的是所有字段,那么此时就没有必要使用索引了,为啥?且听松哥细细道来。
我们来个反证:假设现在还是使用 username 复合索引,那么就需要把 username 索引整个读一遍,然后过滤出满足条件的数据,由于索引中没有保存 address 字段的值,所以还需要回表操作,再去主键索引中找到对应的记录。。。这一路操作下来太麻烦了,光 B+Tree 都读了两棵(而且第一颗 B+Tree 还是遍历),那我们还不如直接遍历主键索引呢!主键索引里要啥有啥,遍历完了想要的数据都有了,遍历主键索引其实就是我们常说的全表扫描。
小伙伴们仔细琢磨下松哥上面这段话。
上面是我们的分析,接下来我们来看看执行计划:

可以看到,如我们所想。
type 为 All 就是我们所熟悉的全表扫描(其实就是遍历主键索引),rows 是预估扫描的行数。最后的 Extra 为 Using where 表示 MySQL 首先从数据表(存储引擎)中读取记录,返回给 MySQL 的 server 层,然后在 server 层过滤掉不满足条件的记录。
3. 小结
好啦,通过这样两个小案例,松哥和大家分享了 MySQL 索引中的最左匹配原则,也希望小伙伴们能够藉此理解索引的存储结构。
以上是关于MYSQL 中的 LIKE 这么用不对?的主要内容,如果未能解决你的问题,请参考以下文章