常见性能工具一览
Posted zuozewei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了常见性能工具一览相关的知识,希望对你有一定的参考价值。
文章目录
一、前言
今天写了一个调试工具的文章,就有人说起工具到底要会哪些。既然提到这儿了,那就多写几句吧。
二、测试工具
只说几个典型的。
1、开源工具
-
Jmeter:这个工具现在应该是互联网压力测试的最常用工具了。用的人多,基本上取代了 loadrunner 的地位。apache 的项目都是牛B项目,不得不赞。现在说是做性能测试的,这个工具不会用,那是没要被鄙视的。由于它也是需要一些开发功底,所以比较符合现在要求测试开发的潮流。但是在一些不差钱的企业中,毕竟开源工具得不到支持。老板们想找个替死鬼也找不到,所以在用外包做性能测试的领域中的市场占有率还有待提高。
现在云测试也都吹得风风火火,基本上也是各种的封装。自己写一套多麻烦。直接搭上一套,再写几个界面封装下,现在出去也能一个场景卖上几千块钱了。所以在线的云测试工具中以它为基础的还是不少。 -
Grinder:我看这个工具最新的更新日期是 2012 年。这个工具其实在 Jmeter 出现之前,可惜的是没赶上好时候,我记得老早以前就看过这个工具的开发团队出现分歧,导致工具发展缓慢。在一些早期的互联网人里面,还有对它进行改造并形成自己的测试平台的。国内某大互联网厂商就是如此。这个工具和 Jmeter 的重合度比较高,所以对初学者,我不建议同时学 Jmeter 和Grinder。
也有以它为基础改编成云测试版本的。
2、商业工具
-
LoadRunner:这个工具不得不说,在哥刚做性能测试的时候,这工具简直是独步天下的。那市场占有率,在售前的 PPT 里,有写 85 %的,还有写 95 %的。自豪得连自己会不会都不知道了。在 Mercury 时代的时候,确实一切都良好。市场稳步往上升。但是风高天黑的 2006 年 7 月 26 日惠普以 45 亿美元收购了 Mercury 公司之后,就越来越笨重。直从 600 多M升级到 4 G左右。并且 HP 的市场做得出其不意的烂。之前一个笔记本装上之后,还能跑得欢快。后来想运行起来就不堪重负了。一个好好的工具,因为时代的原因,再加上 HP 的市场做得如此之烂,最后也不得不慢慢被开源工具占具市场。一个工具卖几十万、上百万。在国内这样的商业环境下,你这定价就是在考验自己的存活时长呀。除了一些要拿商业工具做替罪羊的企业买 100、200 的l icense 放在那里生锈、然后接着用 65536 全协议的盗版之外,似乎现在已经没有什么出路了。
-
SilkPerformer: 不得不说,这个工具现在还存活着完全和中国市场没有关系。在 borland 也是在 2006 年以 1 亿买了 segua 公司,之后在国内市场上就是半死不活的样子。后来 2009 年
Micro Focus宣布以 7500 万美元收购 Borland。这个老牌的软件企业,在欧美还是比较吃得开。可是在国内,从压力工具的市场上来说,就那几个不温不火在外企里养老的销售也干不出什么特色来。 -
以上商业工具的底层实现是从 socket 层抓起,所以从实现上来说,这是绝对的优势。前面提到的开源工具基本上是从应用层抓起,所以在 init 部分会稍微慢一些。不过一个 4 G的工具和一个 100 多M的工具比起来,是不是想想就觉得 4 G用起来好累了?
基于现在云架构的应用,这些商业工具基本上没有什么优势。其实从大的实现的架构上来说,这些工具可是说是没什么区别。看好,我说的是实现的架构,不是实现的内部逻辑。都是控制器、负载机、分布式、多线程、共享资源池之类的思路。
所以压力工具要学习,就学 Jmeter 和 LoadRunner 就好了,据我所知,现在一些知名的互联网企业中,仍然有用 LoadRunner破解版的。65535 vusers 呀,估计 Jmeter 要是实现这么多,自己都撑不住了。 -
另外,还有些工具像:QAload/webload/openSTA/httpperf/loadUI/ab/siege 等之类的也是类似的特性。
3、小结
再次强调,不要纠结于工具,只要选择适合的就好。关键是看好自己想实现的目的。从最低的成本和最长久的发展来考虑,选择自己需要的。
性能测试工具永远不会告诉你瓶颈在哪儿,它只能告诉你,有瓶颈了。
三、监控工具
对于监控工具,可以说是五花八门。
我经常会说,监控工具的选择思路是:先全局监控,后定向定量监控。
大概说一下监控工具,基本上收费的,我都尽量不提。以免有打广告的嫌疑。
对于现在用到的主流环境:linux/tomcat/mysql/nginx/redis 这一套东西。如果有人问到其他的,也可以在评论中说出来。
1、Linux
基本上对于性能分析工程师来说,如果是单机的话,命令就已经足够。uptime/top/vmstat/mpstat/pidstat/dstat/nethogs/iostat/sar…多的列不完。如果说想保存历史数据的话,建议用 prometheus 之类的工具,像这样的工具有很多种,像 casti/ Nagios 也是比较不错的。现在很多企业都基于开源的工具做了自己的监控平台,从思路上来说大同小异。还有些比较强的团队完全开发自己的监控平台。其实这个代价已经不像以前那么高了,毕竟有开源的可以做参考;要改造也有明确的方向。
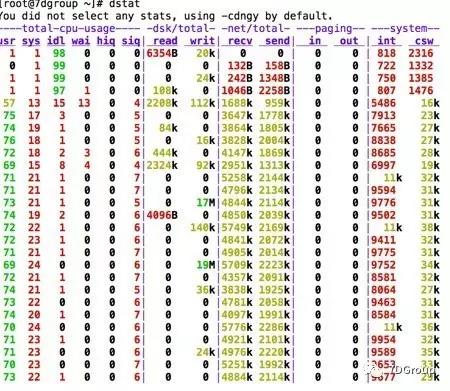
2、tomcat
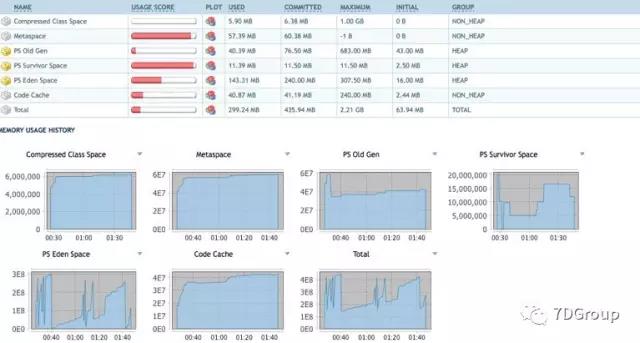
除了自己的 manager 页面,probe 也是个不错的选择。当然对多个节点也是可以用上面提到的 prometheus 系列的监控工具。
3、mysql
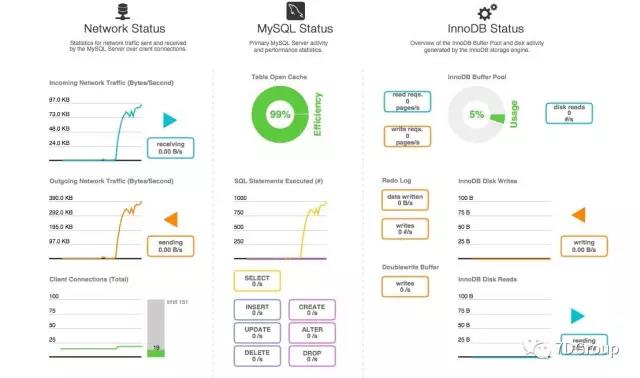
我基本上不用复杂的工具监控 mysql。如果节点不多,我觉得直接写 SQL 也基本上够用。show status+slowlog 之类的。另外,mysql 有 information schema 和 performance schema,基本上像 oracle 里的各种$视图了。有一些工具中也带监控功能,像 mysqlworkbench。
4、redis
除了 info 之外,还有些 GUI 的监控工具,commands/misses 之类的都能看到(因为我服务器上没装,就不截图了,网上找图不像话)。当然刚才提到的 prometheus 也可以做到。
5、nginx
其实没几个参数可以监控的。但是它的日志很有用。建议有条件的一定要装个日志分析工具,实时或半实时地分析下nginx的日志。在配置中,也有 $request_time 和 $upstream_response_time 两个参数可以用(个人推荐用前者)。
6、小结
如果想有报警的机制,就得用监控平台像 prometheus 这样的来配置了。如果是做运维的,这是必须的。
其实监控工具呢,可以给出的是数据是什么样的。对于性能分析工程师来说,不管是用商业的还是开源的还是黑市淘来的监控工具,最重要的是要知道那些值的大小各有什么区别,并且要理清数据之间的关联关系。这才是重点。
四、代码级剖析工具
不管怎么吹,代码级剖析工具对性能本身的损耗都是存在的。
并且损耗还不小。即使是在偏底层做,也照样有很大的损耗。20-30% 损耗都是正常的。
要找好代码级工具的切入点,一开始就用肯定是不理智。只要分析到了某一个具体的进程或线程,或者已经有了可疑代码的具体方法,再上代码级剖析工具就更有目的性了。
1、JAVA 方向
对 JAVA 来说,代码级的剖析工具有好多。自带的就有不少,像现在 SUN JDK 中的 jvirtualVM 就可以实时看 CPU 和内存在一个方法和对象上的消耗。还有 jstack/jmap 等工具可辅助。如果不想实时看,做下 dump 也可以看内存的占用。但是要想看方法调用时间就比较费劲一点。不过现在有不少的商业工具,比如说 jprofiler,这工具直到现在还是我所见到的在 java 剖析中功能最全面的工具(它是商业的)。
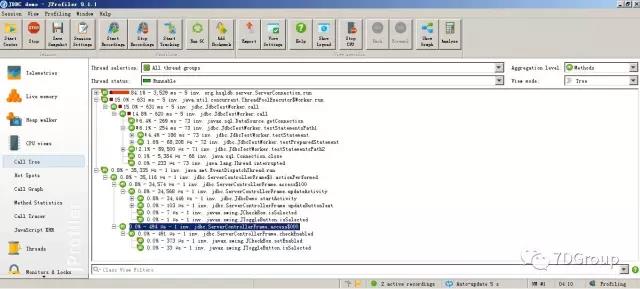
不仅有树结构,还有调用图。
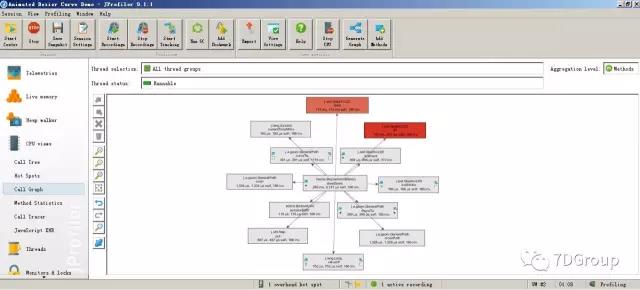
建议大家尽量找到可替代的适合的开源工具。
2、C/C++ 方向
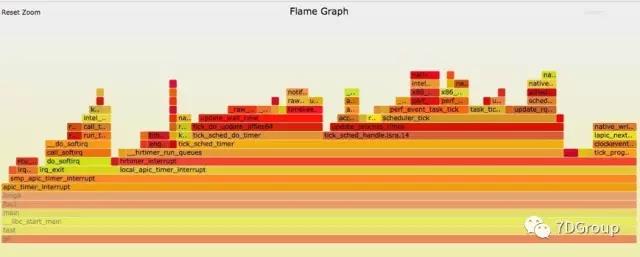
在这个方向上,其实不止有专门的代码级剖析工具,像 valgrind, google perftools。也有系统级的调试工具可以用。各种的 trace工具,像 perf/systemtap/oprofile 之类的也都可用,并且内核级工具损耗要小一些。在 solaris 上有 Dtrace,那本《性能之颠》的书里几乎全是 Dtrace 工具的例子。 并且这些工具还能生成火焰图、热力图之类的。
3、其他
在其他语言上也有相应的剖析工具可用。
- 像 php 有 Xdebug、xhprof;
- python 有cprofile、memoryprofiler、lineprofiler;
- .net有CLR profiler;
- Go语言有pprof(这个是移植过来的,google perf 中的工具更多)。
不管是什么语言,几乎类似的工具都存在的。有了这些工具,再加上系统级的调试工具,找到代码级性能问题就是分分钟的事。
五、Linux 内核调试工具
这里也把工具的使用稍提一下。这里以 perf 为例,其他工具如果有感兴趣的,也可以来探讨,像 systemstap 之类的。GDB 最近就不打算整了,毕竟有点老,并且使用上感觉不是顺藤摸瓜型。
perf 是大部分 linux 上都带了的工具。一些前提条件就不提了,就是在编译内核的时候要各个选择什么的,琐碎得很。遇到这样的问题,我一般都扔给另一个兄弟去处理了。哈哈。
拿 CPU 消耗为例。这里最好带上 -g 的参数,这样可以看到类似下面这样的调用关系。这里可以看到符号表那一列有 [k] 或者 [.],这里 [k] 的意思是内核态的;[.] 的意思是用户态的。看你想看什么内容。
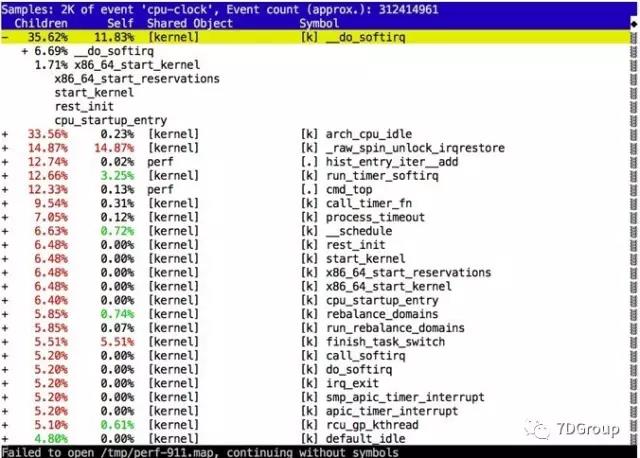
如果这里跟踪自己的应用程序,就可以直接去根据函数名找到了。
并且可以生成火焰图,如下所示,三步就可以生成。
perf script -i perf.data &> perf.unfold
perl stackcollapse-perf.pl perf.unfold &> perf.folded
perl flamegraph.pl perf.folded >perf.svg
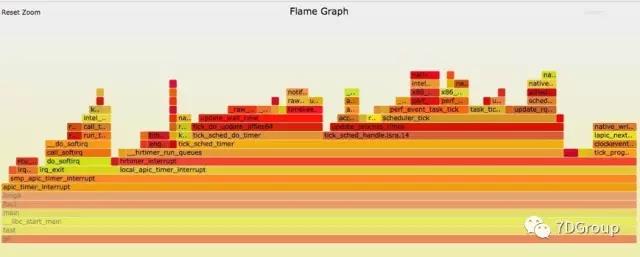
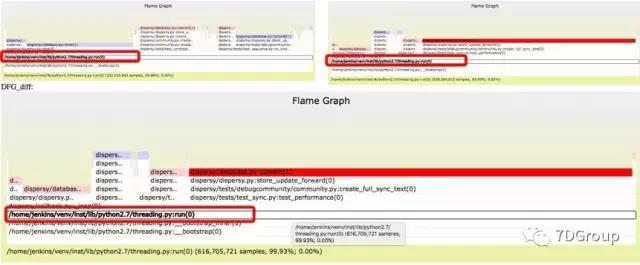
通过 Brendan Gregg 的写好的工具(stackcollapse-perf.pl ,flamegraph.pl),基本上可以满足大部分的要求。有兴趣和有能力的也可以自己写一下。Cor-Paul Bezemer 也写过一个差分火焰图的工具 flamegraphdiff,一个页面显示三个屏,点函数名时,其他图上也会高亮显示。如下所示:
六、前端工具
先以我所有的知识,说明一下前端的展现过程。
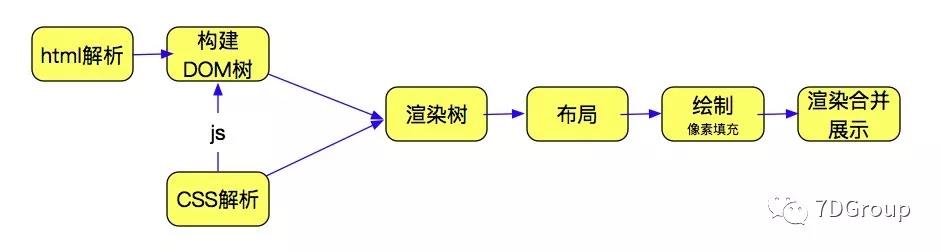
大致过程如上,在实际的展示过程中,有些是可以并行的。比如 html、css下载。这就涉及到 http1.1 协议的下载局限和浏览器支持的并发数量了。
为了能让人尽快看到页面的内容,浏览器也不会等所有的都干完了再展示,而是逐渐展示。
有的人可能看到页面是一次展示出来的,那就是前端设计的太差了。
另外,不同的浏览器用的内核不一样,所以展示的过程会有细微的差别。
还是回到工具上。
1、charlesproxy
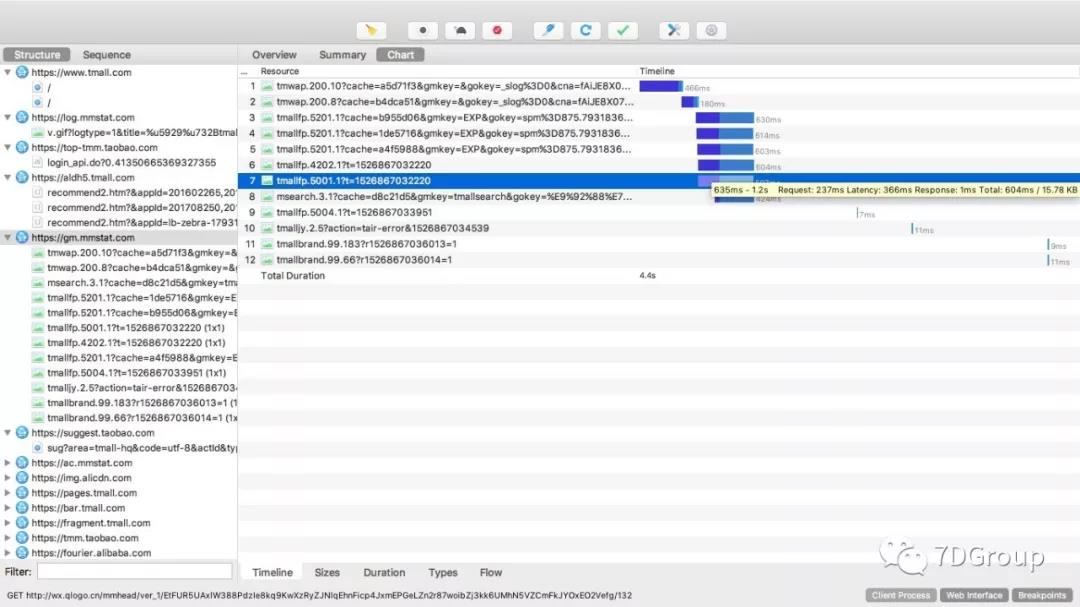
上图展示了一个请求的时间树,可以在性能分析中判断出哪个元素是比较耗时的。
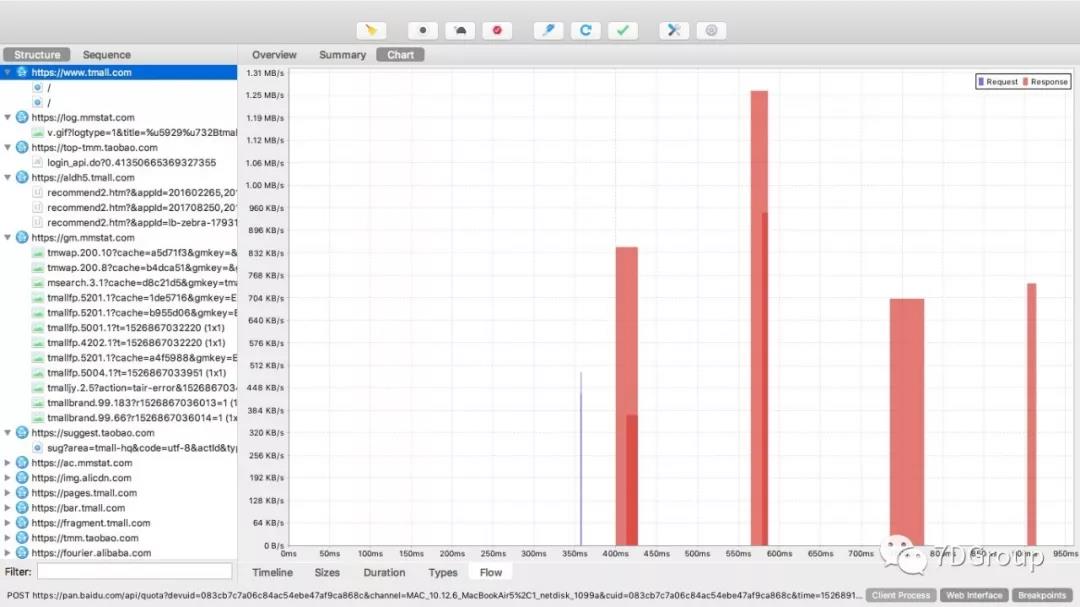
flow 视图展示时间。
这个工具要说好呢,也还是不错的,但是要收费,如果和开源的其他工具一比较,这个收费就感觉不值了。
2、httpwatch
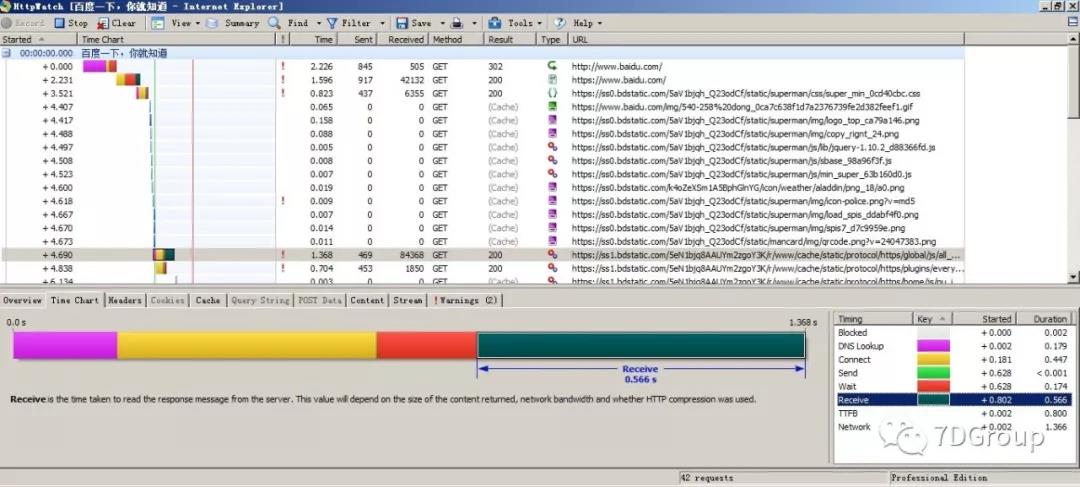
经典的视图,看着就觉得舒服。这个瀑布视图是我觉得前端性能分析工具中做的最好看的。
各元素的响应时间一目了然。并且也把时间细分的非常好。
但可惜的是它只能支持 windows,ipad,iphone。不知道这个工具开发者是怎么想的。
并且这个工具的专业版也收费。
3、safari 开发者工具
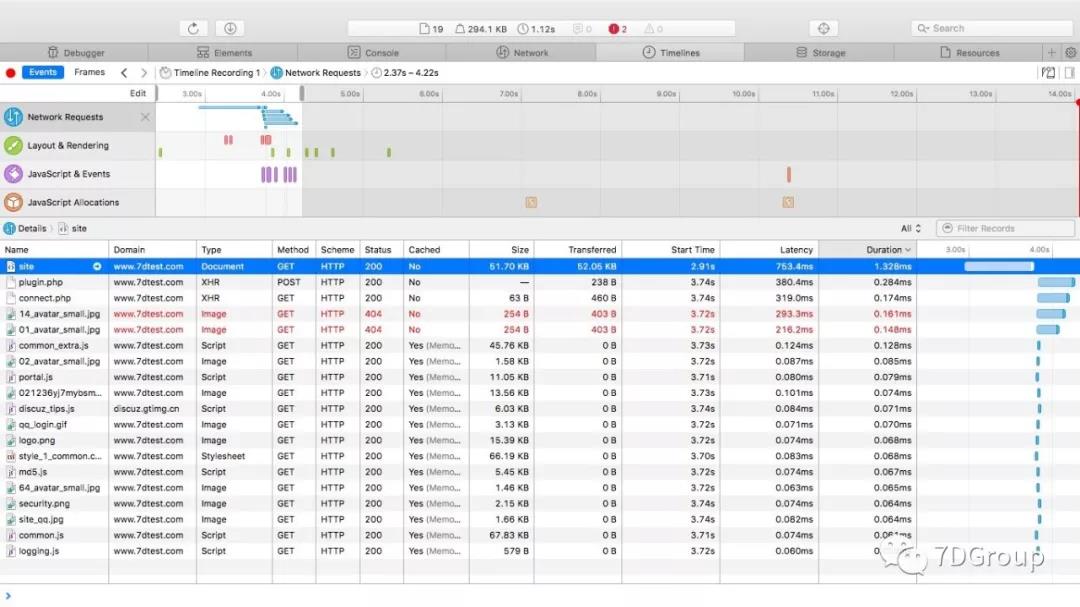
如果是喜欢简洁的人,这个工具必然是首选。一如既往的 mac 风格(想想苹果把 mac 团队拆到 iphone 就很担心以后的 mac 电脑的 os 升级都有可能慢很多呀)。
并且,把几段时间给拆分开在上面也看的很清楚,网络、js、内存、图层渲染。
又免费功能也不少。
4、chrome 开发者工具
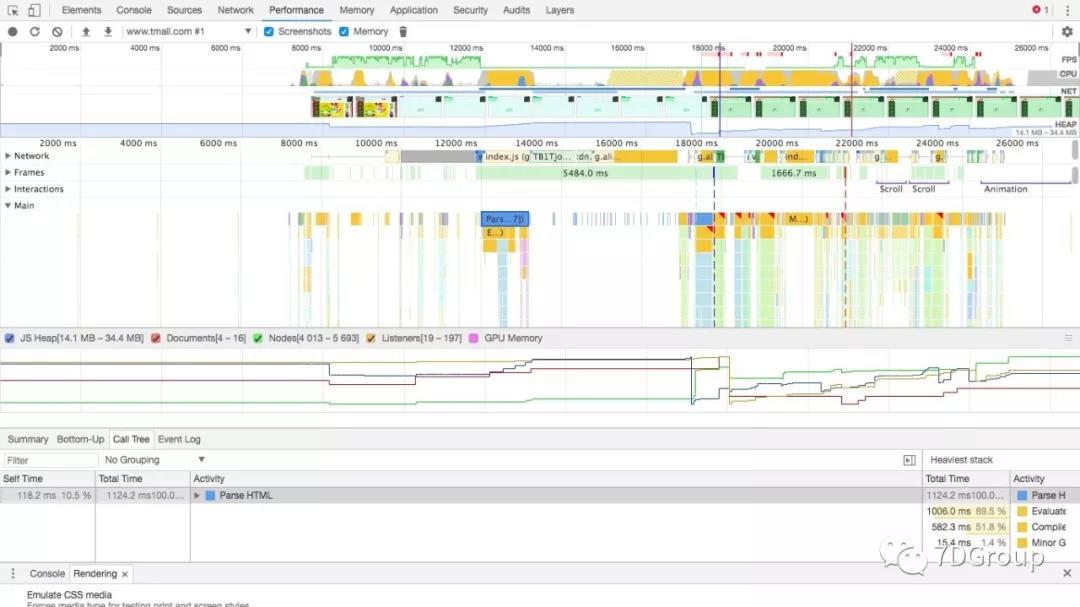
不仅有 safari 中的分层展示,还有倒着的火焰图,你说说,真是啥都给你想到了,只需要你睁眼看它就行。
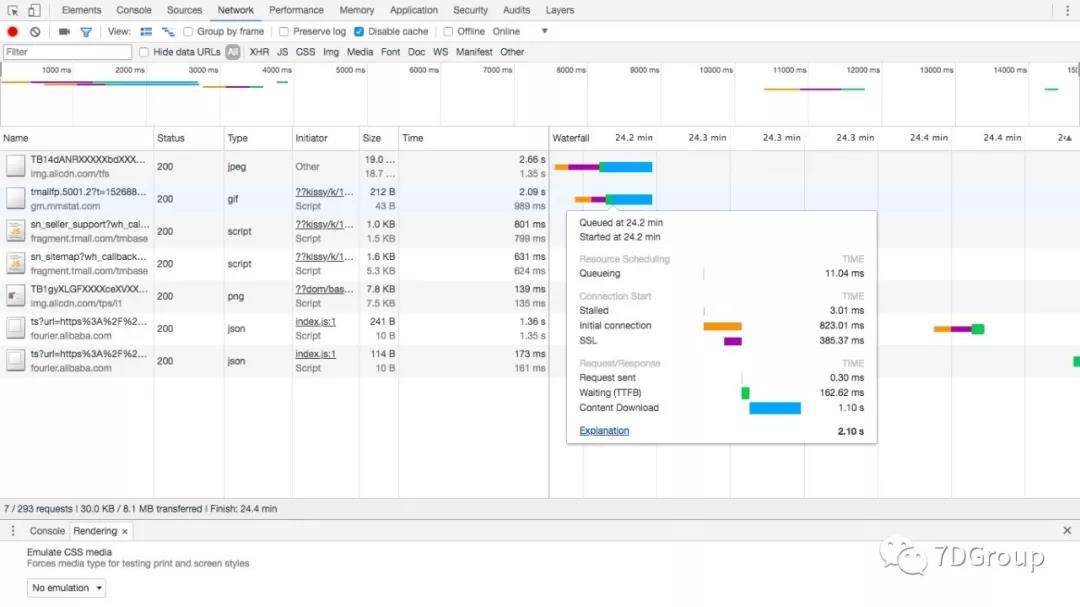
它的网络部分,也是可以明确看到哪个地方浪费了时间的。
又免费又好用。
5、firefox 开发者工具
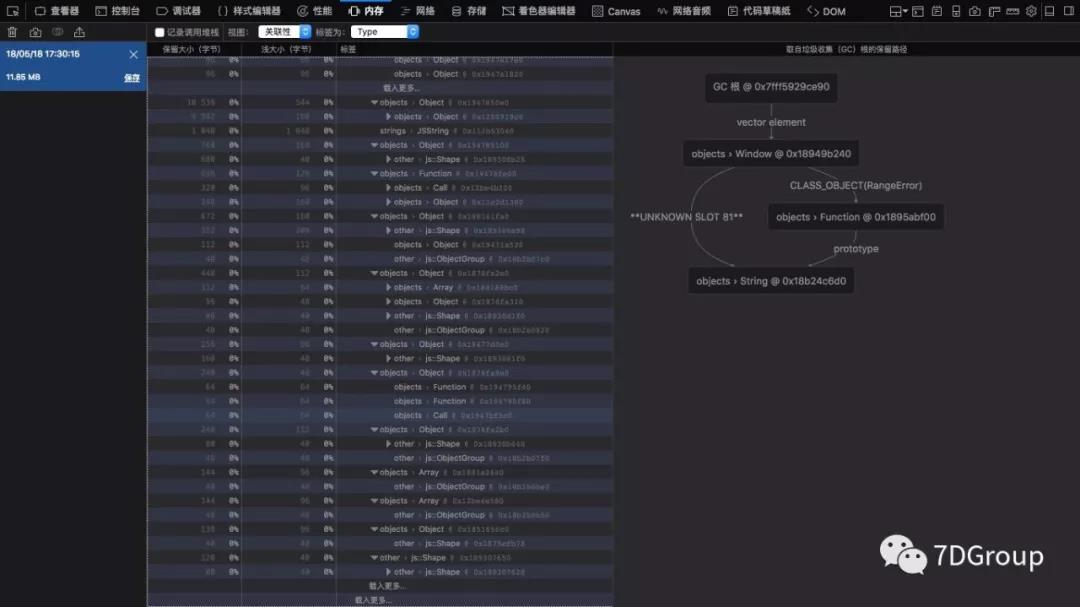
js调用关系图。
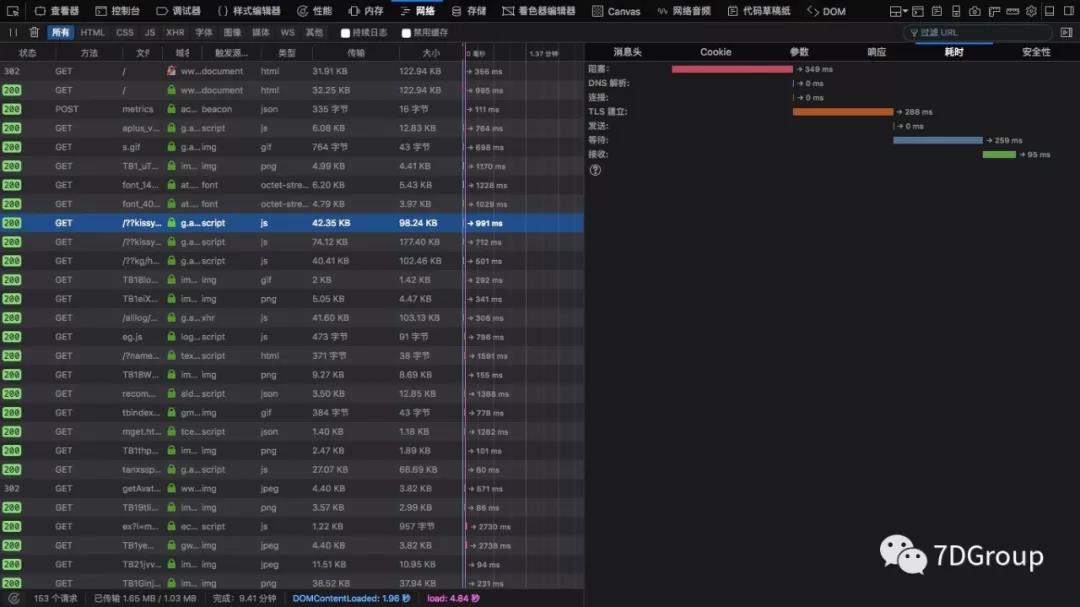
网络的瀑布视图也不错,细分也有,dns解析、SSL、发送、接收、缓冲之类的,要啥有啥。
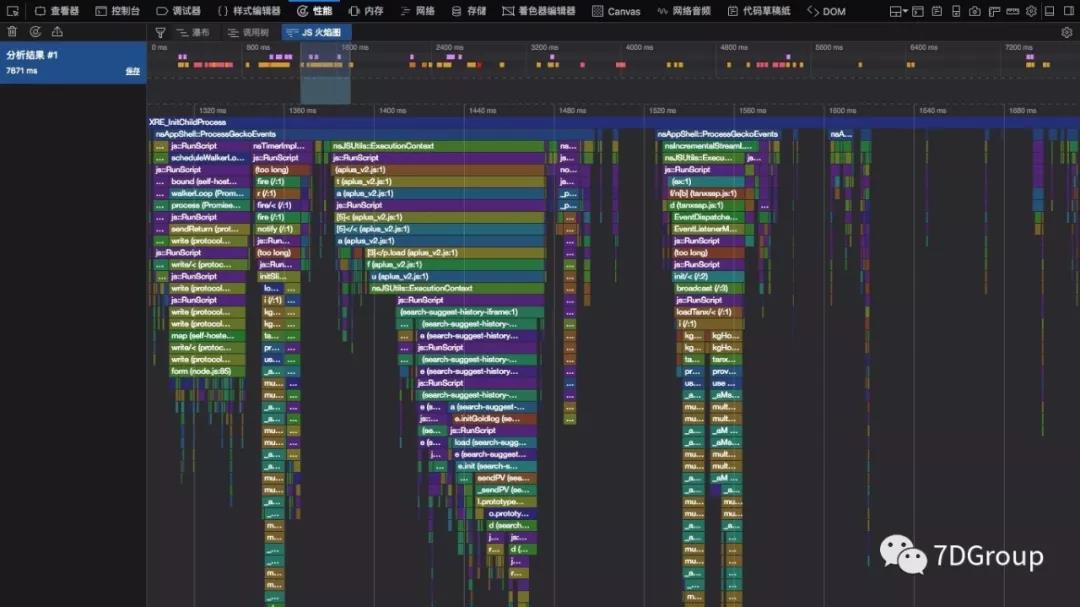
js火焰图也是有的,并且还挺炫丽。
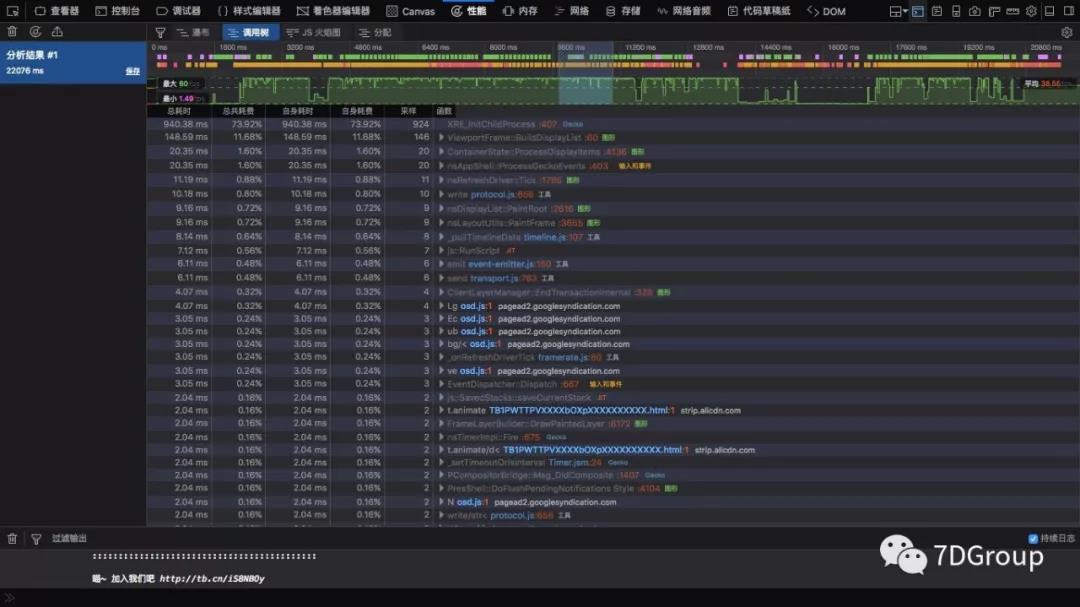
性能视图的树视图,只要看一眼就知道哪慢。
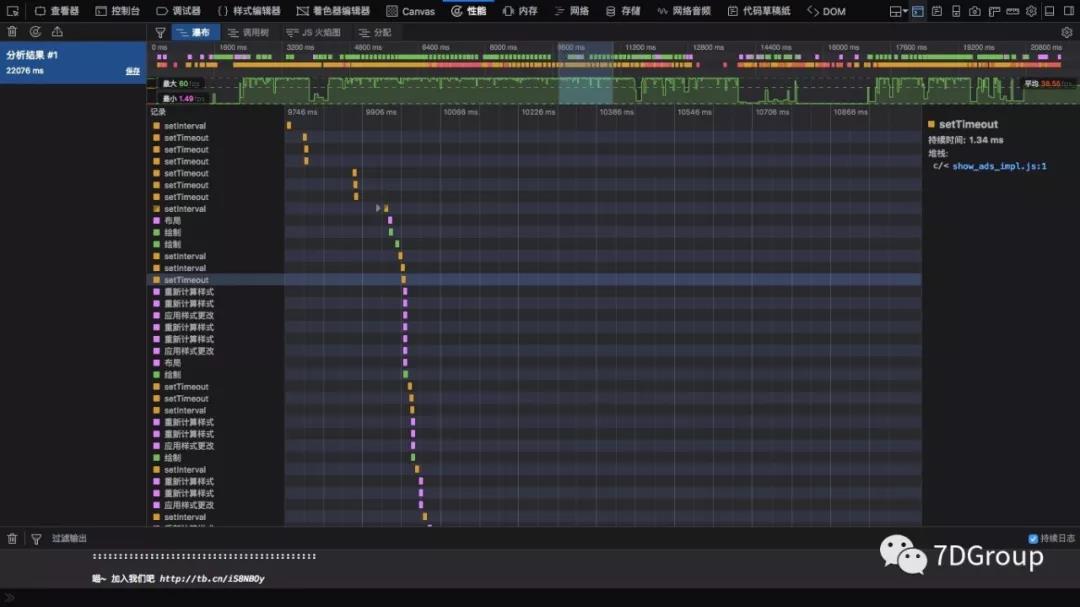
性能的瀑布分的非常细,以致于想看整体还要翻挺长。
6、小结
以上的工具中,都有对前端做调试的功能,下个断点,改个页面参数,复制请求,重发请求,自组装请求之类的。
总之,对于前端的性能分析来说,工具真的已经做的非常完整清晰了。要是说分析时间消耗,看这些就够了。
以上是关于常见性能工具一览的主要内容,如果未能解决你的问题,请参考以下文章
性能工具之前端分析工Chrome Developer Tools性能标签
性能工具之前端分析工Chrome Developer Tools性能标签