一文读懂I/O多路复用技术
Posted IT小智
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文读懂I/O多路复用技术相关的知识,希望对你有一定的参考价值。
前言
当我们要编写一个echo服务器程序的时候,需要对用户从标准输入键入的交互命令做出响应。在这种情况下,服务器必须响应两个相互独立的I/O事件:1)网络客户端发起网络连接请求,2)用户在键盘上键入命令行。我们先等待哪个事件呢?没有哪个选择是理想的。如果在acceptor中等待一个连接请求,我们就不能响应输入的命令。类似地,如果在read中等待一个输入命令,我们就不能响应任何连接请求。针对这种困境的一个解决办法就是I/O多路复用技术。基本思路就是使用select函数,要求内核挂起进程,只有在一个或多个I/O事件发生后,才将控制返回给应用程序。–《UNIX网络编程》
我们以书中的这段描述来引出我们要讲述的I/O多路复用技术。
I/O多路复用概述
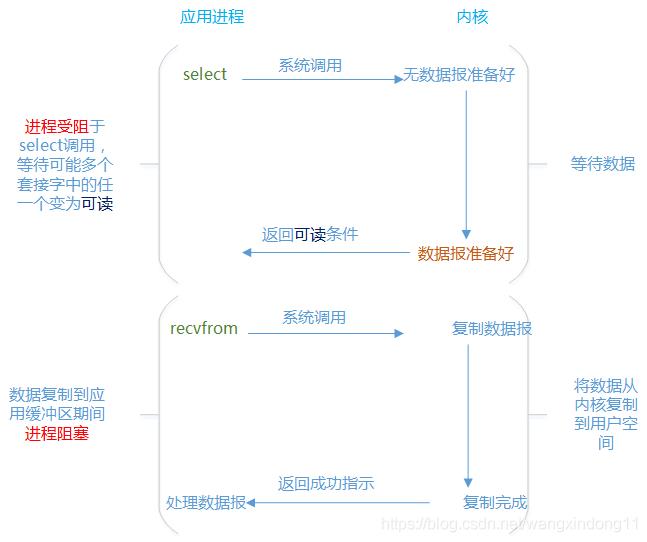
I/O多路复用,I/O就是指的我们网络I/O,多路指多个TCP连接(或多个Channel),复用指复用一个或少量线程。串起来理解就是很多个网络I/O复用一个或少量的线程来处理这些连接。现在大部分讲述I/O多路复用的文章用到的上面这张图是《UNIX网络编程》一书的。那么这也是当前我们理解I/O多路复用技术的基础知识。从这张图里面我们GET到哪些点呢?
个人理解有:
1、怎么区分的应用进程与内核
2、有两次系统调用分别是select和recvfrom
3、两次系统调用进程都阻塞
4、等待哪些数据准备好
下面我们逐一阐述。
二、用户进程和内核

根据网络OSI七层模型和网际网协议族的同比,我们可以知道这里说的用户进程和内核是以传输层为分割线,传输层以上(不包括)是指用户进程,传输层以下(包括)是指内核。上三层,web客户端比如浏览器、web服务器这些都属于应用层,里面跑的程序则是应用进程。下四层处理所有的通信细节,发送数据,等待确认,给无序到达的数据排序等等。这四层也是通常作为操作系统内核的一部分提供。由此可见图1中说的系统调用的地方正是第四层和第五层之间的位置。
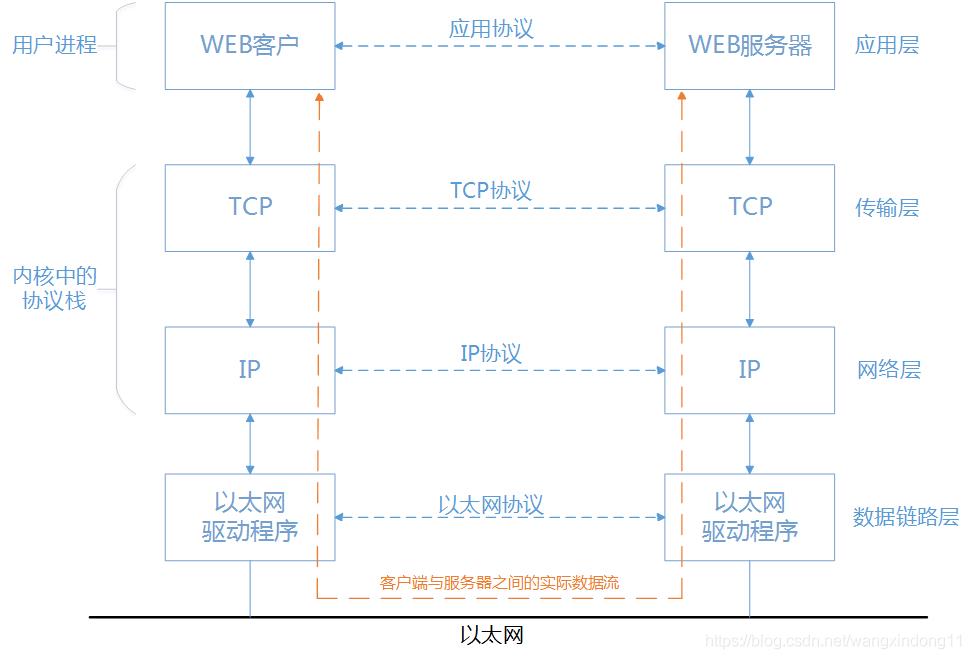
为了理解用户进程和内核,再来看一张图,网络数据流向图。也清晰的标明了用户进程和内核的位置。值得注意的一点是客户与服务器之间的信息流在其中一端是向下通过协议栈的,跨越网络后,在另一端是向上通过协议栈的。这张图描述的是局域网内,如果是在广域网那么就是通过很多个路由器承载实际数据流。
三、select和recvfrom
3.1、select
理解了select就抓住了I/O多路复用的精髓,对应的操作系统中调用的则是系统的select函数,该函数会等待多个I/O事件(比如读就绪,写)的任何一个发生,并且只要有一个网络事件发生,select线程就会执行。如果没有任何一个事件发生则阻塞。我们在下面小节中会重点讲述。函数如下:
#include<sys/select.h>
#include<sys/time.h>
int select(int maxfdpl,fd_set *readset,fd_set *writeset,fd_set *exceptset,const struct timeval *timeout);
从这个函数的定义中的参数,我们能够看出它描述的是,当调用select的时候告知内核对那些事件(读就绪,写)感兴趣以及等待多长时间。
为了方便我们理解select调用,可以参照下面这张图,是jdk的基于I/O多路复用技术的NIO实现。重点在于理解Selector复用器。
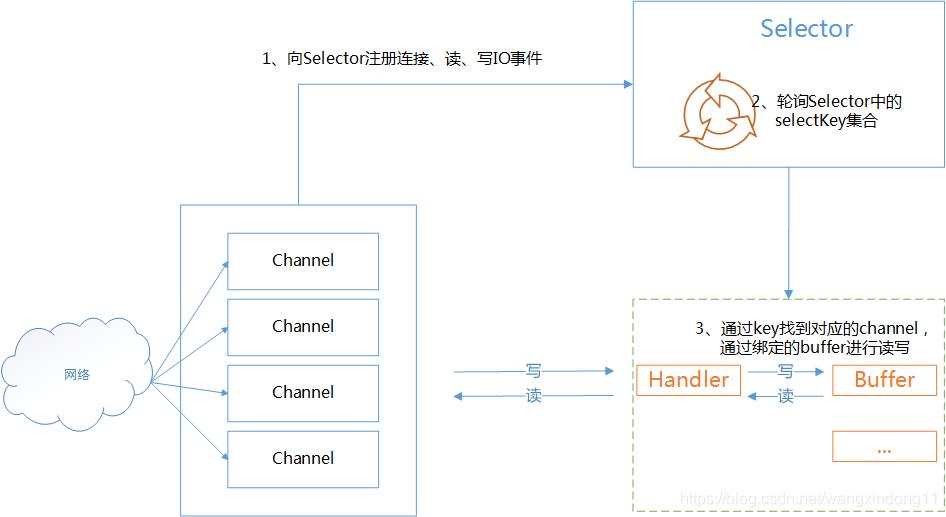
大致代码如下:
ServerSocketChannel serverChannel = ServerSocketChannel.open();// 打开一个未绑定的serversocketchannel
Selector selector = Selector.open();// 创建一个Selector
serverChannel .configureBlocking(false);//设置非阻塞模式
serverChannel .register(selector, SelectionKey.OP_READ);//将ServerSocketChannel注册到Selector
while(true) {
int readyChannels = selector.select();
if(readyChannels == 0) continue;
Set selectedKeys = selector.selectedKeys();
Iterator keyIterator = selectedKeys.iterator();
while(keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if(key.isAcceptable()) {
// a connection was accepted by a ServerSocketChannel.
} else if (key.isConnectable()) {//连接就绪
// a connection was established with a remote server.
} else if (key.isReadable()) {//读就绪
// a channel is ready for reading
} else if (key.isWritable()) {//写就绪
// a channel is ready for writing
}
keyIterator.remove();
}
}
3.2、recvfrom
recvfrom一般用于UDP协议中,但是如果在TCP中connect函数调用后也可以用。用于从(已连接)套接口上接收数据,并捕获数据发送源的地址。也就是我们本文中以及书中说的真正的I/O操作。
四、阻塞、非阻塞
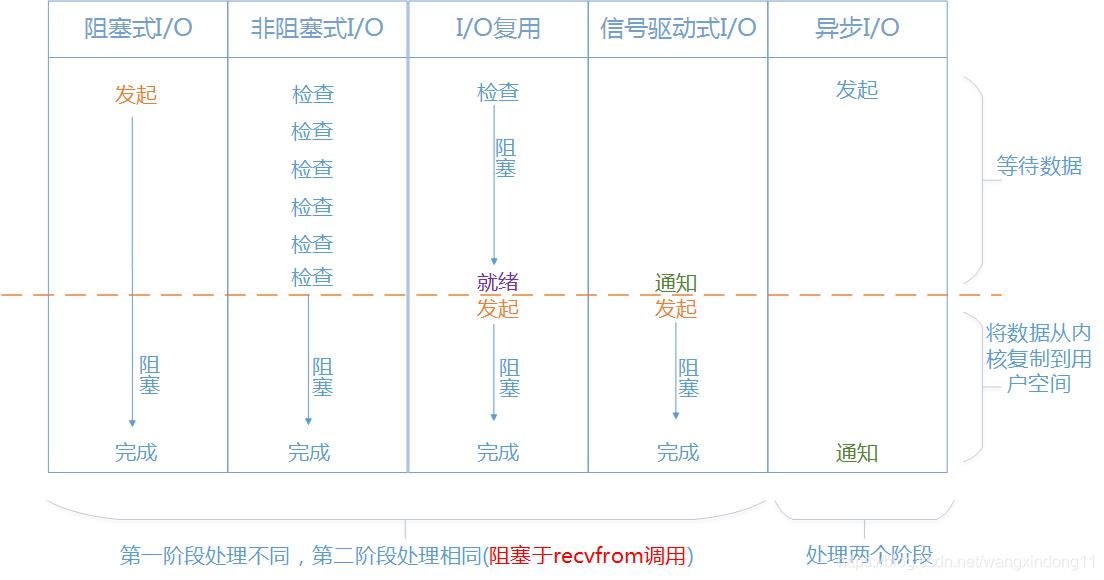
这张图可以看出阻塞式I/O、非阻塞式I/O、I/O复用、信号驱动式I/O他们的第二阶段都相同,也就是都会阻塞到recvfrom调用上面就是图中“发起”的动作。异步式I/O两个阶段都要处理。这里我们重点对比阻塞式I/O(也就是我们常说的传统的BIO)和I/O复用之间的区别。
阻塞式I/O和I/O复用,两个阶段都阻塞,那区别在哪里呢?就在于第三节讲述的Selector,虽然第一阶段都是阻塞,但是阻塞式I/O如果要接收更多的连接,就必须创建更多的线程。I/O复用模式下在第一个阶段大量的连接统统都可以过来直接注册到Selector复用器上面,同时只要单个或者少量的线程来循环处理这些连接事件就可以了,一旦达到“就绪”的条件,就可以立即执行真正的I/O操作。这就是I/O复用与传统的阻塞式I/O最大的不同。也正是I/O复用的精髓所在。
从应用进程的角度去理解始终是阻塞的,等待数据和将数据复制到用户进程这两个阶段都是阻塞的。这一点我们从应用程序是可以清楚的得知,比如我们调用一个以I/O复用为基础的NIO应用服务。调用端是一直阻塞等待返回结果的。
从内核的角度等待Selector上面的网络事件就绪,是阻塞的,如果没有任何一个网络事件就绪则一直等待直到有一个或者多个网络事件就绪。但是从内核的角度考虑,有一点是不阻塞的,就是复制数据,因为内核不用等待,当有就绪条件满足的时候,它直接复制,其余时间在处理别的就绪的条件。这也是大家一直说的非阻塞I/O。实际上是就是指的这个地方的非阻塞。
当我们阅读《UNIX网络编程》(第三版)一书的时候。P124,6.2.3小节中“而不是阻塞在真正的I/O系统调用上”这里的阻塞是相对内核来说的。P127,6.2.7小节“因为其中真正的I/O操作(recvfrom)将阻塞进程”这里的阻塞是相对用户进程来说的。明白了这两点,理解起来就不矛盾了,而且一通到底!
五、适用场景
当服务程序需要承载大量TCP链接的时候,比如我们的消息推送系统,IM通讯,web聊天等等,在我们已经理解Selector原理的情况下,知道使用I/O复用可以用少量的线程处理大量的链接。I/O多路复用技术以事件驱动编程为基础。它运行在单一进程上下文中,因此每个逻辑流都能访问该进程的全部地址空间,这样在流之间共享数据变得很容易。
六、总结
我们通常说的NIO大多数场景下都是基于I/O复用技术的NIO,比如jdk中的NIO,当然Tomcat8以后的NIO也是指的基于I/O复用的NIO。注意,使用NIO != 高性能,当连接数<1000,并发程度不高或者局域网环境下NIO并没有显著的性能优势。如果放到线上环境,网络情况在有时候并不稳定的情况下,这种基于I/O复用技术的NIO的优势就是传统BIO不可同比的了。那么使用select的优势在于我们可以等到网络事件就绪,那么用少量的线程去轮询Selector上面注册的事件,不就绪的不处理,就绪的拿出来立即执行真正的I/O操作。这个使得我们就可以用极少量的线程去HOLD住大量的连接。
转载https://blog.csdn.net/wangxindong11/article/details/78591308
参考资料:
《UNIX网络编程》、《深入理解计算机操作系统》
以上是关于一文读懂I/O多路复用技术的主要内容,如果未能解决你的问题,请参考以下文章