Hibernate 一级缓存源码级
Posted 不可描述的两脚兽
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hibernate 一级缓存源码级相关的知识,希望对你有一定的参考价值。
你是否遇到过这类情况:
case 1:
- 查询返回10条数据
- 其他程序修改数据
- 再次查询返回的数据并没有被修改
case 2:
- 查询返回5条数据
- 修改已有5条数据的部分字段,并新增5条数据。
- 再次查询,读取到10条数据,已被查询过的5条数据没有被更新,新查询到的5条数据的值是最新的。
没错,这些情况都是由于缓存导致的。如果你还完全不知道什么是一级缓存,不建议阅读本文。
太长不看版:
一. 一级缓存是Session级别的。
二. 判断Entity是否存在于缓存中是根据Identifier区分。
三. 当从DB query回结果,会根据结果中的数据生成Identifier与缓存中的Identifier比较。如果不存在则存入缓存,如果存在则无操作。
四.session.setCacheable(true),同一条重复的SQL完全从缓存中读取数据跳过DB。
五.session.setCacheable(false),执行(3.)中的逻辑。
六. 因此只能跳过读取DB,不能跳过读取缓存。
七. 缓存是可以被清理的。如:session.clear(),session.evict()
八. 清理cache后再读取可获取最新数据。
文章目录
这是第一次查询方法调用栈:
几乎所有的查询操作都会调用到list()方法,最后的addEntry()是将结果加到缓存中。
addEntry(Object, Status, Object[], Object, Serializable, Object, LockMode, boolean, EntityPersister, boolean, boolean):507, StatefulPersistenceContext {org.hibernate.engine}, StatefulPersistenceContext.java
postHydrate(EntityPersister, Serializable, Object[], Object, Object, LockMode, boolean, SessionImplementor):80, TwoPhaseLoad {org.hibernate.engine}, TwoPhaseLoad.java
loadFromResultSet(ResultSet, int, Object, String, EntityKey, String, LockMode, Loadable, SessionImplementor):1562, Loader {org.hibernate.loader}, Loader.java
instanceNotYetLoaded(ResultSet, int, Loadable, String, EntityKey, LockMode, EntityKey, Object, List, SessionImplementor):1455, Loader {org.hibernate.loader}, Loader.java
getRow(ResultSet, Loadable[], EntityKey[], Object, EntityKey, LockMode[], List, SessionImplementor):1355, Loader {org.hibernate.loader}, Loader.java
getRowFromResultSet(ResultSet, SessionImplementor, QueryParameters, LockMode[], EntityKey, List, EntityKey[], boolean):611, Loader {org.hibernate.loader}, Loader.java
doQuery(SessionImplementor, QueryParameters, boolean):829, Loader {org.hibernate.loader}, Loader.java
doQueryAndInitializeNonLazyCollections(SessionImplementor, QueryParameters, boolean):274, Loader {org.hibernate.loader}, Loader.java
doList(SessionImplementor, QueryParameters):2533, Loader {org.hibernate.loader}, Loader.java
listIgnoreQueryCache(SessionImplementor, QueryParameters):2276, Loader {org.hibernate.loader}, Loader.java
list(SessionImplementor, QueryParameters, Set, Type[]):2271, Loader {org.hibernate.loader}, Loader.java
list(SessionImplementor, QueryParameters):452, QueryLoader {org.hibernate.loader.hql}, QueryLoader.java
list(SessionImplementor, QueryParameters):363, QueryTranslatorImpl {org.hibernate.hql.ast}, QueryTranslatorImpl.java
performList(QueryParameters, SessionImplementor):196, HQLQueryPlan {org.hibernate.engine.query}, HQLQueryPlan.java
list(String, QueryParameters):1268, SessionImpl {org.hibernate.impl}, SessionImpl.java
list():102, QueryImpl {org.hibernate.impl}, QueryImpl.java
已经在代码注释中使用数字需要如(1. 2. 3. …)进行调用顺序的标识。
一、 一级缓存是Session级别的。
我们说的Session其实是一个接口org.hibernate.Session,它提供了一些与数据库交互的方法。
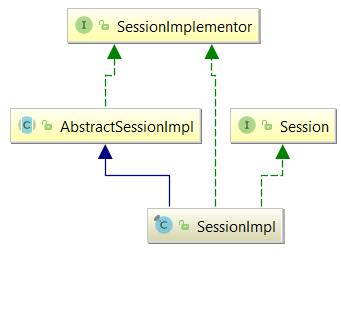
实际用到的是它的实现类SessionImpl,这里会根据生成的执行计划(HQLQueryPlan)调用对应的翻译器(QueryTranslatorImpl),而翻译器器是继承自(org.hibernate.loader.Loader),后续大量的操作都是在Loader完成的。
Loader的入口:
几乎所有的查询操作,最终都会通过list()的接口完成。
这里对配置的是否使用缓存选择不同的代码分支。
// 1. 这是Loader最先被调用的方法,这里对是否读取缓存进行了判断
protected List list(SessionImplementor session, QueryParameters queryParameters, Set querySpaces, Type[] resultTypes) throws HibernateException {
// this.factory.getSettings().isQueryCacheEnabled() 是通过hibernate.cache.use_query_cache,这是二级缓存后续介绍
// queryParameters.isCacheable()是通过session.setCacheable()确定
boolean cacheable = this.factory.getSettings().isQueryCacheEnabled() && queryParameters.isCacheable();
//这样通过cacheable,true:使用查询缓存,false:忽略缓存
return cacheable ? this.listUsingQueryCache(session, queryParameters, querySpaces, resultTypes) : this.listIgnoreQueryCache(session, queryParameters);
}
先看不使用缓存的情况listIgnoreQueryCache(),通过doList()完成工作
private List listIgnoreQueryCache(SessionImplementor session, QueryParameters queryParameters) {
// 2. 实际的工作是doList()完成的
return this.getResultList(this.doList(session, queryParameters), queryParameters.getResultTransformer());
}
接下来通过一些列参数的准备工作后(参考上面的调用栈),会调用到doQuery(),这里是真正的读取数据库,用到我们熟悉的JDBC的接口。
下面是doQuery()方法里的内容:
PreparedStatement st = this.prepareQueryStatement(queryParameters, false, session);
ResultSet rs = this.getResultSet(st, queryParameters.hasAutoDiscoverScalarTypes(), queryParameters.isCallable(), selection, session);
这里是经典的JDBC操作,返回的rs就是查询DB返回的结果集了。
下面就是遍历结果集对每一条数据进行处理
// rs.next()遍历结果
for(count = 0; count < maxRows && rs.next(); ++count) {
if (log.isTraceEnabled()) {
log.debug("result set row: " + count);
}
// 3. 对rs结果进行处理
Object result = this.getRowFromResultSet(rs, session, queryParameters, lockModesArray, optionalObjectKey, hydratedObjects, keys, returnProxies);
// 处理后的结果加到返回集
results.add(result);
if (createSubselects) {
subselectResultKeys.add(keys);
keys = new EntityKey[entitySpan];
}
}
// 13. 非常重要!!这里包含了很多工作
// 真正初始化对象的地方,并且包含interceptor的onLoad回调.
// 通过深拷贝将从缓存复制对象到返回结果集,执行之前results中的对象只是空壳,执行后正真deepCopy。
// 将对象管理状态修改为Status.MANAGED
this.initializeEntitiesAndCollections(hydratedObjects, rs, session, queryParameters.isReadOnly(session));
return results;
二、判断Entity是否存在于缓存中是根据Identifier区分。
三、 当从DB query回结果,会根据结果中的数据生成Identifier与缓存中的Identifier比较。如果不存在则存入缓存,如果存在则无操作。
extractKeysFromResultSet()是用于通过Identifier自动抽取key的方法,会将结果填充到keys这个集合。
private Object getRowFromResultSet(ResultSet resultSet, SessionImplementor session, QueryParameters queryParameters, LockMode[] lockModesArray, EntityKey optionalObjectKey, List hydratedObjects, EntityKey[] keys, boolean returnProxies) throws SQLException, HibernateException {
Loadable[] persisters = this.getEntityPersisters();
int entitySpan = persisters.length;
// 4. 从结果集抽取keys,这个命名非常好,见名知意。这个方法的作用就是从DB返回的数据中提取对象的identifier放到keys这个集合里面,这个key的作用就是用于与缓存中的对象比较。相同的数据key是相同的。
this.extractKeysFromResultSet(persisters, queryParameters, resultSet, session, keys, lockModesArray, hydratedObjects);
this.registerNonExists(keys, persisters, session);
// 5. getRow()就用于是提取数据并返回,下一个代码块我们看里面实现
Object[] row = this.getRow(resultSet, persisters, keys, queryParameters.getOptionalObject(), optionalObjectKey, lockModesArray, hydratedObjects, session);
this.readCollectionElements(row, resultSet, session);
if (returnProxies) {
for(int i = 0; i < entitySpan; ++i) {
Object entity = row[i];
Object proxy = session.getPersistenceContext().proxyFor(persisters[i], keys[i], entity);
if (entity != proxy) {
((HibernateProxy)proxy).getHibernateLazyInitializer().setImplementation(entity);
row[i] = proxy;
}
}
}
this.applyPostLoadLocks(row, lockModesArray, session);
return this.getResultColumnOrRow(row, queryParameters.getResultTransformer(), resultSet, session);
}
private Object[] getRow(ResultSet rs, Loadable[] persisters, EntityKey[] keys, Object optionalObject, EntityKey optionalObjectKey, LockMode[] lockModes, List hydratedObjects, SessionImplementor session) throws HibernateException, SQLException {
int cols = persisters.length;
EntityAliases[] descriptors = this.getEntityAliases();
Object[] rowResults = new Object[cols];
for(int i = 0; i < cols; ++i) {
Object object = null;
EntityKey key = keys[i];
if (keys[i] != null) {
// 6. hibernate提供了很多回调配置以interceptor的接口,这里就已经去查缓存,并检查interceptor.
// 7. 注意:这里通过session调用,故访问一级缓存
object = session.getEntityUsingInterceptor(key);
// 缓存中不存在对象会返回null
if (object != null) {
// 14. 实例已存在 >> 处理已缓存的情况
this.instanceAlreadyLoaded(rs, i, persisters[i], key, object, lockModes[i], session);
} else {
// 8. 实例未被加载过,这里跟进此方法
object = this.instanceNotYetLoaded(rs, i, persisters[i], descriptors[i].getRowIdAlias(), key, lockModes[i], optionalObjectKey, optionalObject, hydratedObjects, session);
}
}
rowResults[i] = object;
}
return rowResults;
}
六、 因此只能跳过读取DB,不能跳过读取缓存。
这里总是会去缓存去一次数据
public Object getEntityUsingInterceptor(EntityKey key) throws HibernateException {
this.errorIfClosed();
// persistenceContext是缓存上对象了,通过前面提到的key,从缓存中获得对象。
Object result = this.persistenceContext.getEntity(key);
if (result == null) {
// 调用配置interceptor的getEntity()方法。没有配置interceptor会有一个默认的EmptyInterceptor,方法实现返回null。也就是说,如果缓存里没有对象,给你个回调机会可以自己构造一个对象作为结果返回。
Object newObject = this.interceptor.getEntity(key.getEntityName(), key.getIdentifier());
if (newObject != null) {
this.lock(newObject, LockMode.NONE);
}
// 缓存中没有get到,那么这里会返回null,请返回上一个代码块继续。
return newObject;
} else {
return result;
}
}
如果缓存中没有对应的Identifier,那么:
private Object instanceNotYetLoaded(ResultSet rs, int i, Loadable persister, String rowIdAlias, EntityKey key, LockMode lockMode, EntityKey optionalObjectKey, Object optionalObject, List hydratedObjects, SessionImplementor session) throws HibernateException, SQLException {
//得到POJO全类名
String instanceClass = this.getInstanceClass(rs, i, persister, key.getIdentifier(), session);
Object object;
if (optionalObjectKey != null && key.equals(optionalObjectKey)) {
object = optionalObject;
} else {
// 可以理解为反射一个实例,将identifier传进去,对象的其他属性没有被赋值。
object = session.instantiate(instanceClass, key.getIdentifier());
}
LockMode acquiredLockMode = lockMode == LockMode.NONE ? LockMode.READ : lockMode;
// 9. 最终的加载数据的方法
this.loadFromResultSet(rs, i, object, instanceClass, key, rowIdAlias, acquiredLockMode, persister, session);
hydratedObjects.add(object);
return object;
}
private void loadFromResultSet(ResultSet rs, int i, Object object, String instanceEntityName, EntityKey key, String rowIdAlias, LockMode lockMode, Loadable rootPersister, SessionImplementor session) throws SQLException, HibernateException {
Serializable id = key.getIdentifier();
Loadable persister = (Loadable)this.getFactory().getEntityPersister(instanceEntityName);
boolean eagerPropertyFetch = this.isEagerPropertyFetchEnabled(i);
// 代码非常清晰,2阶段加载。
// 10. 添加未初始化的实体。object是上面提到的一个仅带有identifier的空对象,把它加到缓存。
TwoPhaseLoad.addUninitializedEntity(key, object, persister, lockMode, !eagerPropertyFetch, session);
String[][] cols = persister == rootPersister ? this.getEntityAliases()[i].getSuffixedPropertyAliases() : this.getEntityAliases()[i].getSuffixedPropertyAliases(persister);
// 11. 这里处理数据,提取真实的数据到values
Object[] values = persister.hydrate(rs, id, object, rootPersister, cols, eagerPropertyFetch, session);
Object rowId = persister.hasRowId() ? rs.getObject(rowIdAlias) : null;
AssociationType[] ownerAssociationTypes = this.getOwnerAssociationTypes();
if (ownerAssociationTypes != Hibernate 一级缓存源码级