c语言-数据的储存(无废话)
Posted 起个名字好难嗷
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了c语言-数据的储存(无废话)相关的知识,希望对你有一定的参考价值。
前言
不废话,纯干货,无套路!!!文章目录
数据类型
数据类型一共分为 八种类型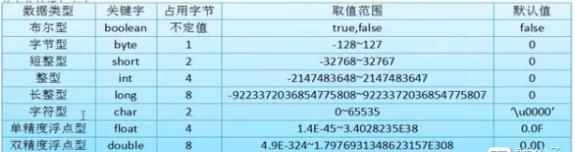
细分下来还有
整形类型

浮点型类型
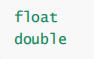
构造类型

指针类型

空类型

整形的存储
我们知道,变量的创建是要在内存中开辟空间的。空间的大小由不同的类型决定。
那么我们首先应该了解,它们所存储数据的方式,这是重中之重。
由此我们可以引入-原码,反码,补码的概念
原码
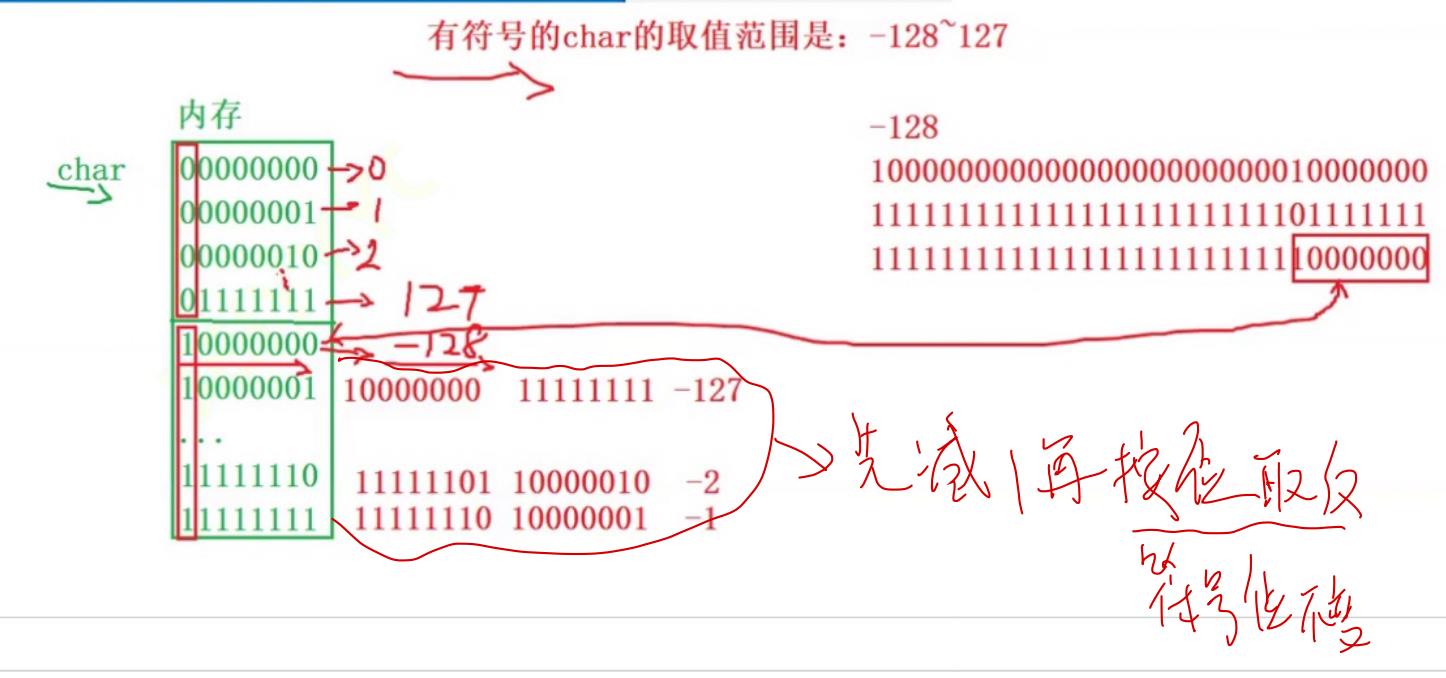
原码:一个整数,按照绝对值大小转换成的二进制数,称为原码。通俗的来说,就是直接将数按照正负数的形式翻译成二进制就行。在翻译的过程应当 勿忘,最左边应当是符号位,右边通常是数值位。符号位用0表示正数,而用1表示负数,这个概念容易混淆,需要我们多加注意!
反码
原码的符号位不变,其他位按位取反得到反码
补码
反码加一得到了补码,这里的加一我们通常在后面加,并且,由于是二进制,所以遇到2应该进一位然后余0.小tip:一般都是加后面那几位,因为他们是数值位。
小推论
1>正数的原码反码补码都相同。
2>补码取反再加一可以再次得到原码!!按原码变补码的规则,补码变原码应该是“减1取反”,可是对于二进制,“减1取反”和“取反加1”的效果是一样的,所以补码的补码就是原码;
3>对于整形来说,数据存放于内存中的应当是补码。可以用补码来推地址。

在内存中的储存
内存存储数据示意
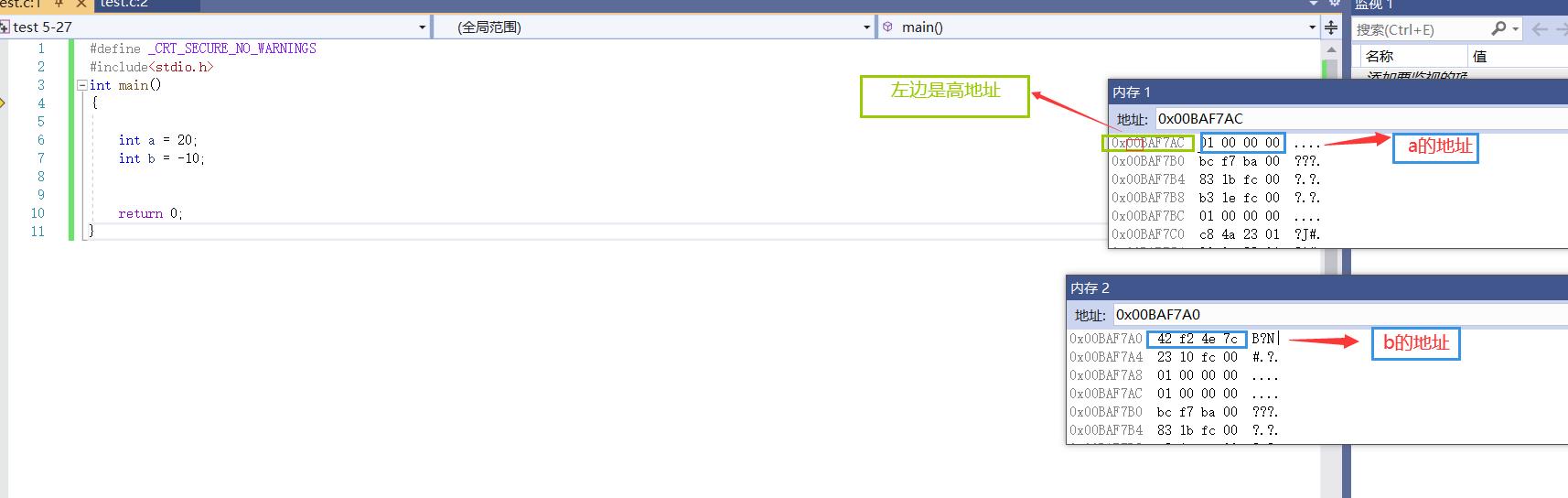
这时候我们按一下f10进行调试(博主的编译环境是vs2019)。 此时,在这里,你们发现了什么?
我们可以明显看出高地址中存储着数据的低位,这是为什么呢?
我们引出大小端的概念
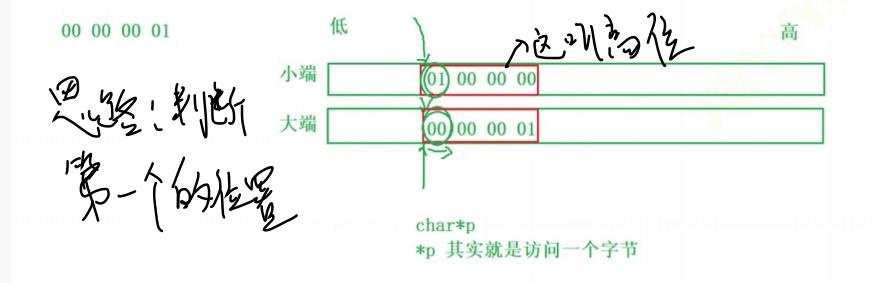
大小端储存
大端存储
所谓大端存储,就是让数据的低位存储在内存的高地址中,然后数据的高位,保存在内存的低地址中
(反顺序)
小端存储
所谓小端存储,就是将数据的低位存储在内存的低位中,然后数据的高位,存储在内存的高地址中。
(正顺序)
大小端图示

引例
请设计一个小程序来判断当前机器的字节序。
思路
易懂版本

这个代码的思路很清晰,结合上面的图示我们可以知道,当他是小端字节时,第一位应当是1,当它是大端字节时,第一个数字应当返回0,由此判断它是大端还是小端。(char*)是类型转换一下。
简洁版本
但那样并不够,我们要追求代码的简洁性。

省略了if语句,思路同上。
练习
补充一些练习所需重要的知识!

练习1
题目

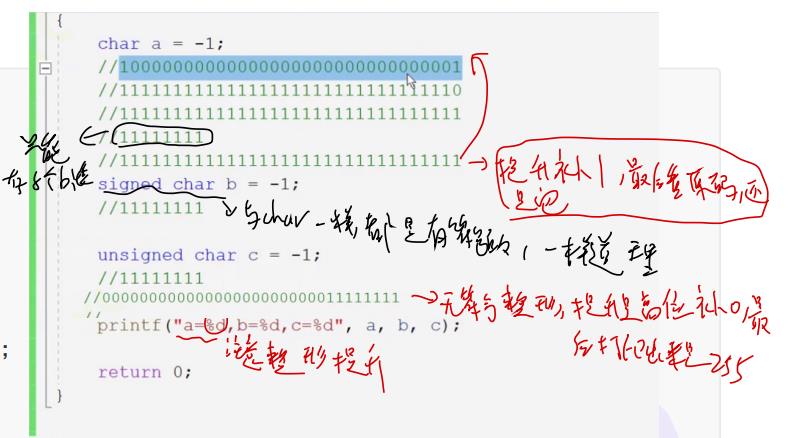
仔细观察可以发现,它们是%d形式打印的,所以我们应该注意整形提升!!
那么,通过比较signed与unsigned我们可以得知它们的解法
练习2
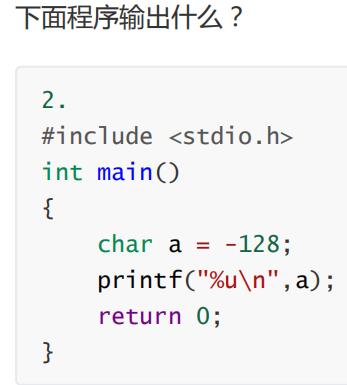

这个最好用电脑的计算器算一下,数有些大,原理和上一题一样嗷。
练习3
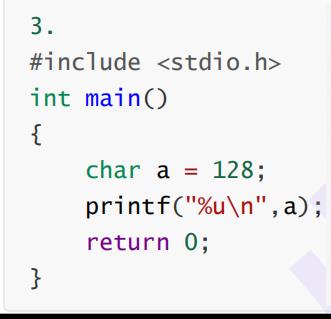
这个同样是128,只不过不同点在于它是正数,需要注意正数的原反补相同,然后还是像上题那样整型提升,由于高位补1,所以我们可以发现最后结果没有变。

来个图解

练习4
题目

解析如图

练习5
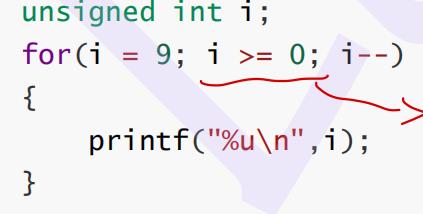
解答
因为i是恒定大于等于0的,所以肯定是永远满足这个条件呢,因此他是一个死循环。
练习6
题目

根据strlen的定义,它是通过查找\\0来使字符终止,由上面我们补充的char的循环知识我们可以得出它是由255一循环,所以当i<1000的时候,范围确定了,那么这个题的结果也就能很快得出。
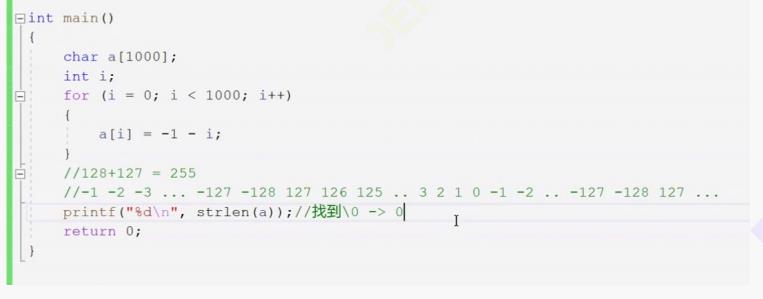
练习7
题目
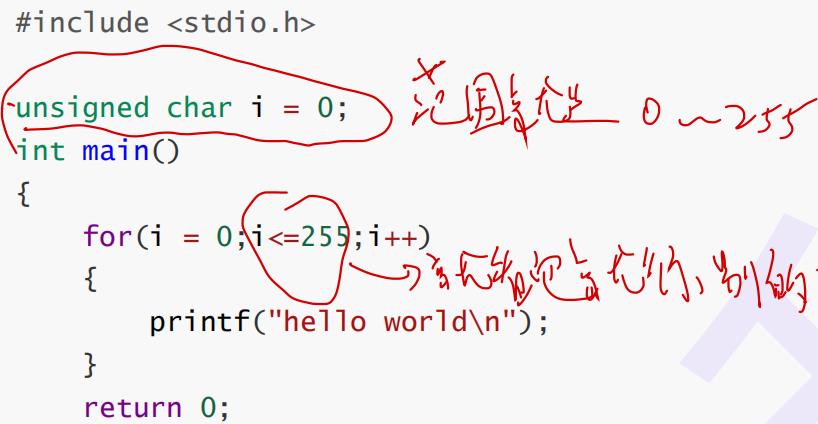
解析如上图
总结
纯笔记向博客,如有不当,还望指出!
博主的gitee地址码云仓库
以上是关于c语言-数据的储存(无废话)的主要内容,如果未能解决你的问题,请参考以下文章