四种方式带你层层递进解剖算法---hash表不一定适合寻找重复数据
Posted 烟花散尽13141
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了四种方式带你层层递进解剖算法---hash表不一定适合寻找重复数据相关的知识,希望对你有一定的参考价值。
一、题目描述
在一个长度为 n 的数组 nums 里的所有数字都在 0~n-1 的范围内。数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了几次。请找出数组中任意一个重复的数字。
二、思路分析
- 算法(Algorithm)指的是解题的方案,是一系列解决问题的明确动作。所以说算法没有语言区分,只要我们的方案是完整的任何语言都可以实现它。我是C++出身但是从事Java多年,下面将是通过java来实现算法
考察点
- 任何算法基本上都可以通过暴力枚举来解决,但那仅仅是理论上。解决问题不仅要考虑理论最终还得取决于硬件和时间的支持。所以我们面对一个问题首先得确定方案。想要确定方案就得知道问题的痛点或者说问题的考点在哪里
- 此题是要找出重复的数字,想要找出重复的数字就得有一个对比的操作,想要有一个对比的操作就得将旧数据存放在一定规则的区域中。关于规则的区域这就引入了哈希表(HashTable)。
三、代码+解析
初版
public int findRepeatNumber(int[] nums) {
//构建hash表 。 Java中Map天生的Hash表
Map<Integer, Object> map = new HashMap<>();
for (int num : nums) {
//已经在hash表中存在的说明数据重复
if (map.containsKey(num)) {
return num;
}
//没有重复的数据需要添加到hash表中
map.put(num, num);
}
return 0;
}
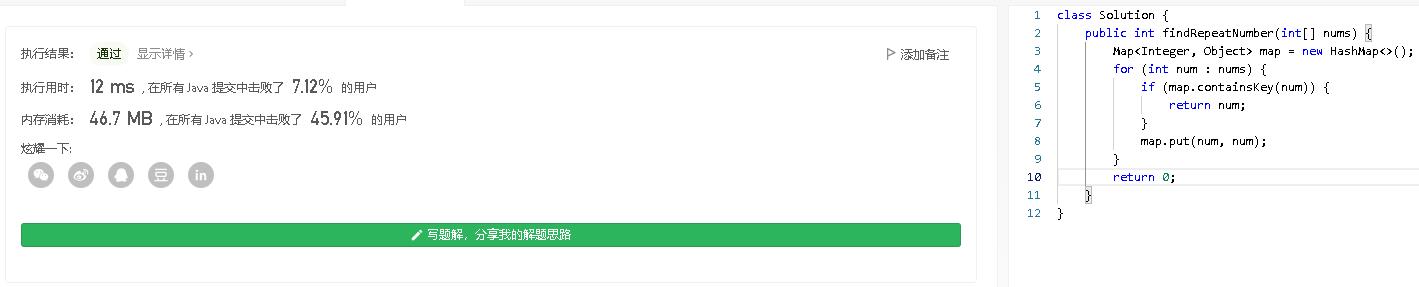
- 此题是leetcode中简单类型的题目。既然是刷题首先得找简单的找找自信。正好也确定下自己的刷题风格。结果很明显是没有问题也是一次性通过。
- 虽然题目简单但是我们不能仅仅满足于完成。回过头来想想我们这样做有啥缺点是不是还有进步的空间呢?
首次升级
升级点
- 在上面的那个版本中我们借助于hash表来实现数据的存储从而进行数据的比对是否重复。这里因为引入了hash表而hash表就需要在内存中开辟空间这就导致了我们的程序在内存上开辟的比较大。会随着数组的重复性后偏导致我们的hash表内存越来越大,极端情况下我们的hash表中的元素和数组中的元素趋近于相等。
- 其次是每次都需要从hash中获取数据和数组中的数据进行对比。我们知道hash表尤其是Java中的Map的实现在获取数据是需要先根据hashcode值定位到hash槽,然后在从槽头开始遍历链表或者是树进行数据寻找。这个过程虽然已经很快了但是和数组直接寻址法相比就弱爆了。
- 基于上面两个痛点,我决定取消Hash表的引入。上面说了本题的考点是Hash表,但是并不意味着必须使用Hash表来实现是最优的。所谓条条大路通罗马实现是有很多种的,善于利用周遭的环境是我们人类的本能。
优化落地
- 既然是查找重复数据如果是有序的数组的话只需要逐个对相邻的两个进行比较就可以了。因为有序状态的数组每个元素会起着隔离的效果,这样就避免的Hash表的存在在内存上肯定比Hash表低的,而且上面也提到了数组的寻址比
HashMap快的多,所以在速度上应该也会快很多的
public int findRepeatNumber(int[] nums) {
Arrays.sort(nums);
for (int i = 1; i < nums.length; i++) {
if (nums[i] == nums[i - 1]) {
return nums[i];
}
}
return 0;
}
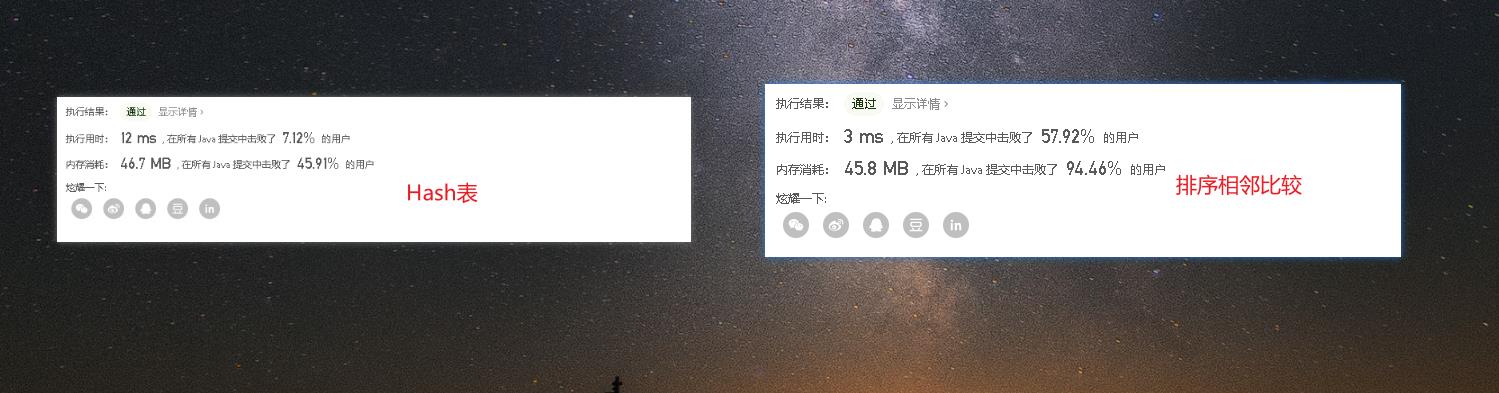
- 上图中左边是Hash表的方式运行效果,右图是相邻比较的运行效果。两者在执行时间和内存消耗上不是在同一个量级的。提升了两倍之多
再次升级
升级点
- 上面排序后相邻位置比较运行的结果我觉得还是挺满意的,但是在代码的是实现上有个边界的问题。而且我们需要逐个进行比较,逐个比较在时间上应该是比较耗时的。
- 基于上面逐个比较,笔者这里再次进行优化。将进行跳位比较
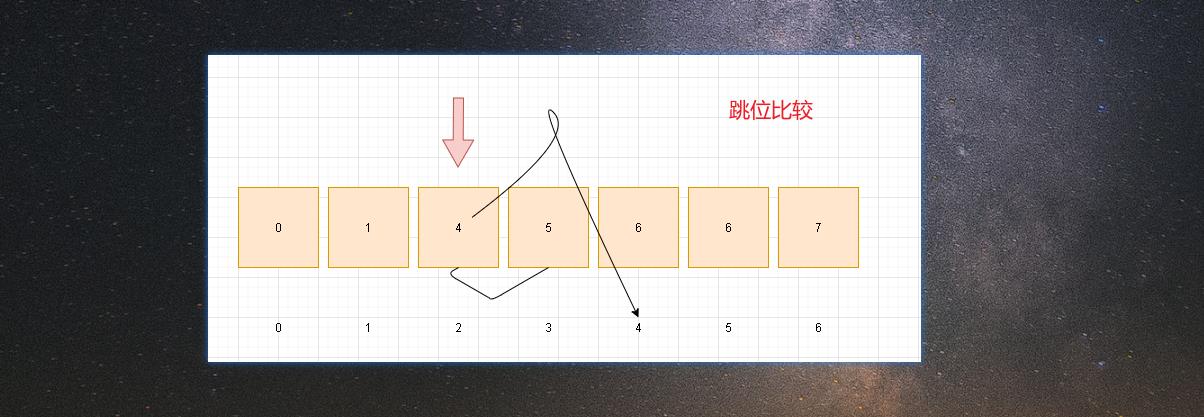
- 跳位就避免了逐个比较,将比较的次数控制下来。
public int findRepeatNumber(int[] nums) {
Arrays.sort(nums);
for (int i = 0; i < nums.length; i++) {
int index =i;
while (index != nums[index]) {
index = nums[index];
}
if (index != i) {
return index;
}
}
return 0;
}
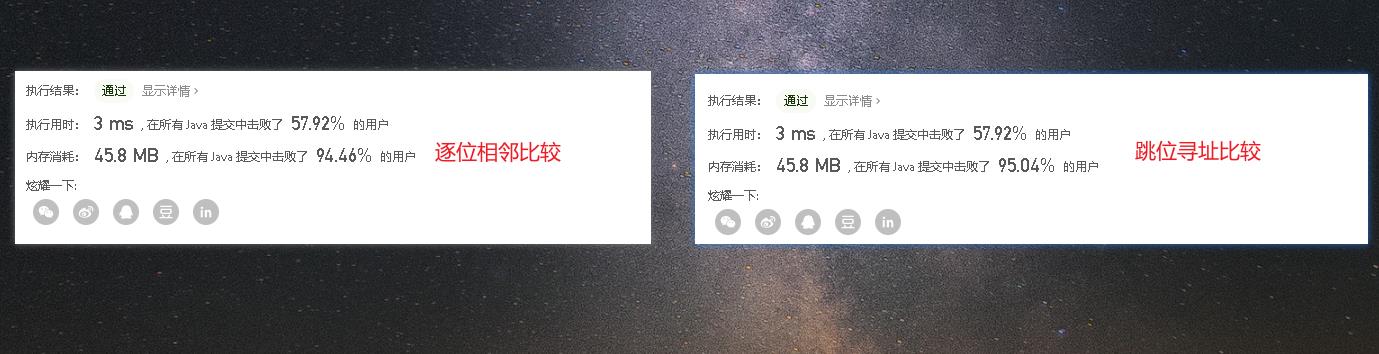
- 效果对比看一下,两者基本没有区别。在执行速度上基本一致。内存消耗上后者应该比前者高一点的,可能是leetcode统计内存没有那么细致再结合运行期间不稳定因素所以执行出来的结果虽然是后者高但是实际上笔者这里认为逐位相邻比较才是最优的。
- 本次的升级实际上是失败的,充其量就是逐位相邻比较的一种变形。但是本次的变形却引入另外一个概念—跳位交换
最终升级
升级点
-
其实仔细思考下为什么跳位寻址比较没有逐位相邻比较有什么显著的提升呢。说到底是因为我们已经排好顺序了在已经排好的顺序中我们跳位进行比对是没有起到太大的作用的。
-
这里笔者又查阅了官方的推荐解法–原地交换。这里的【原地交换】和笔者提出的【跳位寻址比较】不谋而合。下面我将翻译下官网的推荐解法(官网是真的强大)
-
这里官网推荐的代码就不贴了。大家可以直接在官网题解中找到原地交换讲解 。 但是笔者尝试了很多次都没有题解中说的100% 。 可能语言的差异所以他的实现并不支持java的。笔者这里对他进行稍微的带动
public int findRepeatNumber(int[] nums) {
for (int i = 0; i < nums.length; i++) {
while (i != nums[i]) {
if (nums[i] == nums[nums[i]]) {
return nums[i];
}
nums[i] = nums[i] ^ nums[nums[i]];
nums[nums[i]] = nums[nums[i]]^nums[i];
nums[i] = nums[i] ^ nums[nums[i]];
}
}
return 0;
}
- 官网中引入了一个临时变量用于交换数据暂存。这里内存就会一直被占用。理论上内存也不会太受影响的。但是结果在java中运行却不是那么完美
- 笔者这里将通过异或的方式实现数据的交换。运行结果相对会高点 。这里笔者在此提醒下leetcode每次运行因为大环境的问题并不能准确反映性能的问题
- 下面是笔者在leetcode连续运行三次的效果图
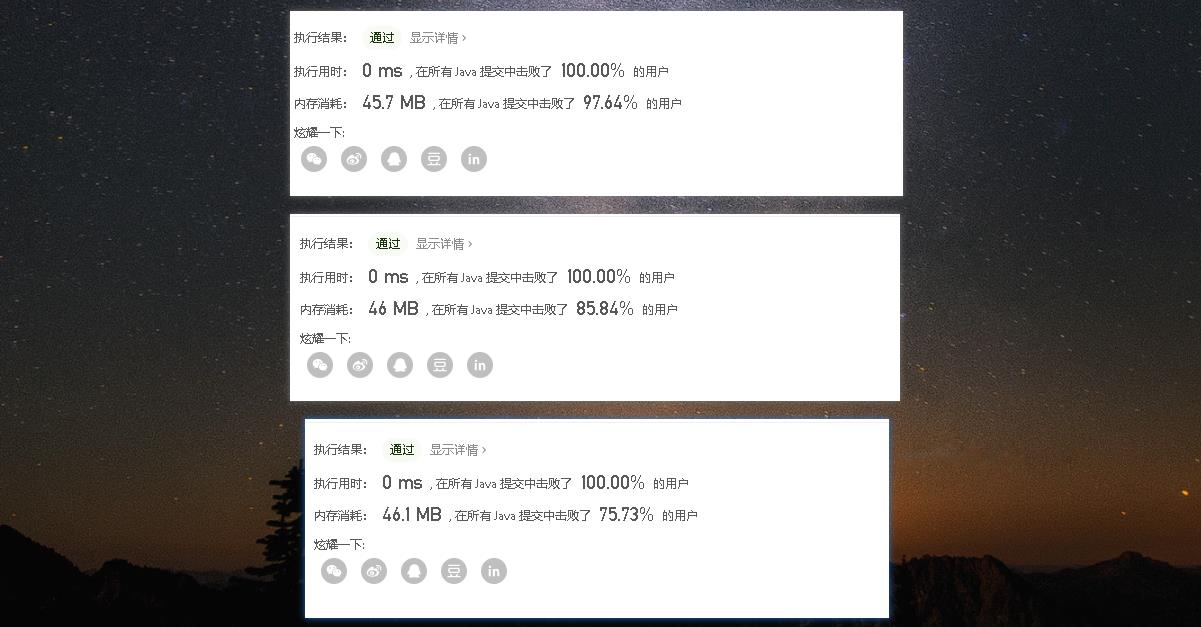
四、总结
- 不能仅仅依赖leetcode的运行结果作为衡量程序好坏的依据。笔者这里只是从个人的角度出发区分出程序的优劣
- 虽然leetcode不能作为唯一标准,但是多次运行的结果可以做一个参考价值。
- 算法的实现并不是一层不变的。我们学习算法是基础面对实际的问题还是得在算法的基础上进行扩展,结合实际的场景触发才是最正确的选择
最后还得送各位兄弟一句话,关注、点赞、收藏不能忘。万一哪天你找不到我了呢
以上是关于四种方式带你层层递进解剖算法---hash表不一定适合寻找重复数据的主要内容,如果未能解决你的问题,请参考以下文章