BP预测基于麻雀算法改进BP神经网络预测模型matlab源码
Posted Matlab走起
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了BP预测基于麻雀算法改进BP神经网络预测模型matlab源码相关的知识,希望对你有一定的参考价值。
1.数据介绍
本案例数据一共2000组,其中1900组用于训练,100组用于测试。数据的输入为2维数据,预测的输出为1维数据
3.SSA优化BP神经网络
3.1 BP神经网络参数设置
神经网络参数如下:
-
%% 构造网络结构 -
%创建神经网络 -
inputnum = 2; %inputnum 输入层节点数 2维特征 -
hiddennum = 10; %hiddennum 隐含层节点数 -
outputnum = 1; %outputnum 隐含层节点数
- 1
- 2
- 3
- 4
- 5
3.2 麻雀算法应用
从麻雀的群体智慧、觅食行为和反捕食行为出发,提出了一种新的群体优化方法&麻雀搜索算法(SSA)。在19个基准函数上进行了实验,测试了该算法的性能,并与其他算法如灰太狼算法(gwolf optimizer,gwolf)、引力搜索算法(GSA)和粒子群优化算法(PSO)进行了比较。仿真结果表明,该算法在精度、收敛速度、稳定性和鲁棒性等方面优于GWO、PSO和GSA。最后,通过两个工程实例验证了该方法的有效性。
1.算法原理
建立麻雀搜索算法的数学模型,主要规则如下所述:
- 发现者通常拥有较高的能源储备并且在整个种群中负责搜索到具有丰富食物的区域,为所有的加入者提供觅食的区域和方向。在模型建立中能量储备的高低取决于麻雀个体所对应的适应度值(Fitness Value)的好坏。
- 一旦麻雀发现了捕食者,个体开始发出鸣叫作为报警信号。当报警值大于安全值时,发现者会将加入者带到其它安全区域进行觅食。
- 发现者和加入者的身份是动态变化的。只要能够寻找到更好的食物来源,每只麻雀都可以成为发现者,但是发现者和加入者所占整个种群数量的比重是不变的。也就是说,有一只麻雀变成发现者必然有另一只麻雀变成加入者。
- 加入者的能量越低,它们在整个种群中所处的觅食位置就越差。一些饥肠辘辘的加入者更有可能飞往其它地方觅食,以获得更多的能量。
- 在觅食过程中,加入者总是能够搜索到提供最好食物的发现者,然后从最好的食物中获取食物或者在该发现者周围觅食。与此同时,一些加入者为了增加自己的捕食率可能会不断地监控发现者进而去争夺食物资源。
- 当意识到危险时,群体边缘的麻雀会迅速向安全区域移动,以获得更好的位置,位于种群中间的麻雀则会随机走动,以靠近其它麻雀。
在模拟实验中,我们需要使用虚拟麻雀进行食物的寻找,由n只麻雀组成的种群可表示为如下形式:

其中,d 表示待优化问题变量的维数,n 则是麻雀的数量。那么,所有麻雀的适应度值可以表示为如下形式:
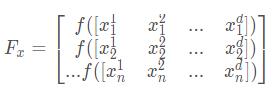
其中,f 表示适应度值。
在 SSA 中,具有较好适应度值的发现者在搜索过程中会优先获取食物。此外,因为发现者负责为整个麻雀种群寻找食物并为所有加入者提供觅食的方向。因此,发现者可以获得比加入者更大的觅食搜索范围。根据规则(1)和规则(2),在每次迭代的过程中,发现者的位置更新描述如下:

麻雀算法的参数设置为:
-
popsize = 20;%种群数量 -
Max_iteration = 20;%最大迭代次数 -
lb = -5;%权值阈值下边界 -
ub = 5;%权值阈值上边界 -
% inputnum * hiddennum + hiddennum*outputnum 为阈值的个数 -
% hiddennum + outputnum 为权值的个数 -
dim = inputnum * hiddennum + hiddennum*outputnum + hiddennum + outputnum ;% inputnum * hiddennum + hiddennum*outputnum维度
这里需要注意的是,神经网络的阈值数量计算方式如下:
本网络有2层:
第一层的阈值数量为:2*10 = 20; 即inputnum * hiddennum;
第一层的权值数量为:10;即hiddennum;
第二层的阈值数量为:10*1 = 10;即hiddenum * outputnum;
第二层权值数量为:1;即outputnum;
于是可知我们优化的维度为:inputnum * hiddennum + hiddennum*outputnum + hiddennum + outputnum = 41;
适应度函数值设定:
本文设置适应度函数如下:
f i t n e s s = a r g m i n ( m s e ( T r a i n D a t a E r r o r ) + m e s ( T e s t D a t a E r r o r ) ) fitness = argmin(mse(TrainDataError) + mes(TestDataError))fitness=argmin(mse(TrainDataError)+mes(TestDataError))
其中TrainDataError,TestDataError分别为训练集和测试集的预测误差。mse为求取均方误差函数,适应度函数表明我们最终想得到的网络是在测试集和训练集上均可以得到较好结果的网络。
-
% </html> -
%% 清空环境 -
clc -
clear -
%读取数据 -
load data -
z=data'; -
n=length(z); -
for i=1:6; -
sample(i,:)=z(i:i+n-6); -
end -
%训练数据和预测数据 -
input_train=sample(1:5,1:1400); -
output_train=sample(6,1:1400); -
input_test=sample(1:5,1401:1483); -
output_test=sample(6,1401:1483); -
%节点个数 -
inputnum=5; -
hiddennum=3; -
outputnum=1; -
%选连样本输入输出数据归一化 -
[inputn,inputps]=mapminmax(input_train); -
[outputn,outputps]=mapminmax(output_train); -
%% BP网络训练 -
%网络进化参数 -
net.trainParam.epochs=100; -
net.trainParam.lr=0.1; -
%net.trainParam.goal=0.00001; -
%网络训练 -
[net,per2]=train(net,inputn,outputn); -
%% BP网络预测 -
%数据归一化 -
inputn_test=mapminmax('apply',input_test,inputps); -
an=sim(net,inputn_test); -
test_simu=mapminmax('reverse',an,outputps); -
error=test_simu-output_test; -
E=mean(abs(error./output_test)) -
plot(output_test,'b*') -
hold on; -
plot(test_simu,'-o') -
title('结果','fontsize',12) -
legend('实际值','预测值') -
xlabel('时间') -
ylabel('比较')
4.测试结果:
从麻雀算法的收敛曲线可以看到,整体误差是不断下降的,说明麻雀算法起到了优化的作用:
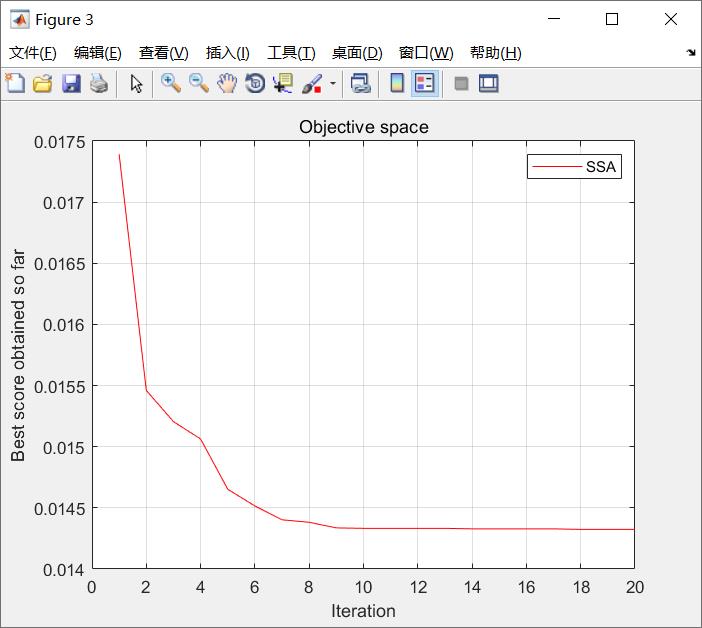
图1 麻雀算法收敛曲线
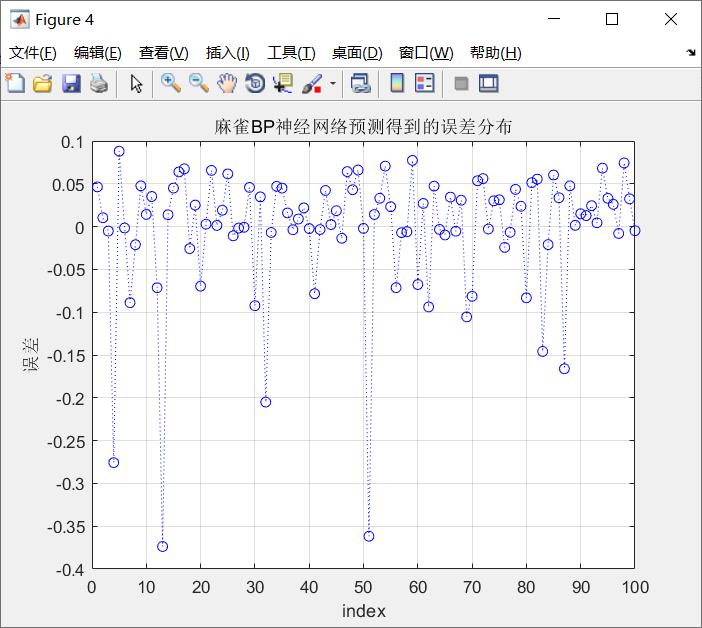
图2.SSA-BP误差分布图
测试统计如下表所示
| 测试结果 | 预测MSE |
|---|---|
| BP神经网络 | 0.018157 |
| SSA-BP | 0.0062555 |
从结果来看,SSA-BP的mse明显小于基础BP神经网络,优化后的BP神经网络结果更好。
完整代码添加QQ1575304183
以上是关于BP预测基于麻雀算法改进BP神经网络预测模型matlab源码的主要内容,如果未能解决你的问题,请参考以下文章
BP预测基于Logistic混沌映射改进麻雀算法改进BP神经网络实现数据预测
BP预测基于Tent混沌映射改进麻雀算法改进BP神经网络实现数据预测
BP预测基于Logistic混沌映射改进麻雀算法改进BP神经网络实现数据预测
BP预测基于Tent混沌映射改进麻雀算法改进BP神经网络实现数据预测