学术界AV1编码优化技术的进展
Posted LiveVideoStack_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学术界AV1编码优化技术的进展相关的知识,希望对你有一定的参考价值。
# Editorial Note #
学术界的一些优化工作实涵盖了编码过程的大部分模块。很 明显的趋势就是许多深度学习的网络或者方法已经开始与编码的模块进行结合,并取得了很多不错的收益。本文将按照编码过程的大致顺序分享学术界AV1编码优化技术的进展。
文 / 朱辰
整理 / LiveVideoStack

各位专家以及屏幕前的各位观众大家好!我是朱辰,目前是上海交通大学图像所的在读博士生。本次分享的主题是学术界AV1编码优化技术的进展。
AV1编码标准
首先介绍一下AV1编码标准。AV1是由开放媒体联盟AOM阵营提出的面向互联网流媒体的开发编码标准开放编码标准。AOM是由谷歌主导,并且吸纳了很多ICT领域的大厂加入,例如我们国内的腾讯还有爱奇艺都是联盟成员。AOM建立的初衷是想解决专利问题,形成一些免费开源的编码方案,同时性能超过HEVC。
AV1核心编码工具

此处是对AV1新增的一些核心编码工具进行了一些整理总结。首先,最大的编码单元目前已经扩展到了128×128的大小;同时划分模式是支持2等分和4等分。帧内预测方面,除了扩展了方向性的预测模式以外,还添加了比如交叉分量、递归滤波的预测模式。帧间预测方面是最多支持7个参考帧,同时支持仿射运动轨迹,混合预测模式等。变换是支持包含DCT在内的4种模式。熵编码使用的是一种多符号的上下文字适应的算术码。环路滤波共支持区块滤波,方向增强滤波,还有修复滤波,总共三种算子。最后特别的对于屏幕内容编码,还涉及了一些例如调色板,块匹配等技术。
AV1编解码器

AV1在生态建设方面步伐非常快,现在可以看到已有三款开源的编码器和一款开源的解码器。另外我们也已经看到已经有三款商用的AV1编码器。对于AV1性能,相比于HEVC标准下的x265, AV1的前身VP9,大概有20~30%的增益。在商业应用方面,从去年开始AV1已经开始有规模在一些比如浏览器端、安卓客户端、OTT以及智能电视设备上得到支持和使用。
AV1优化技术工作
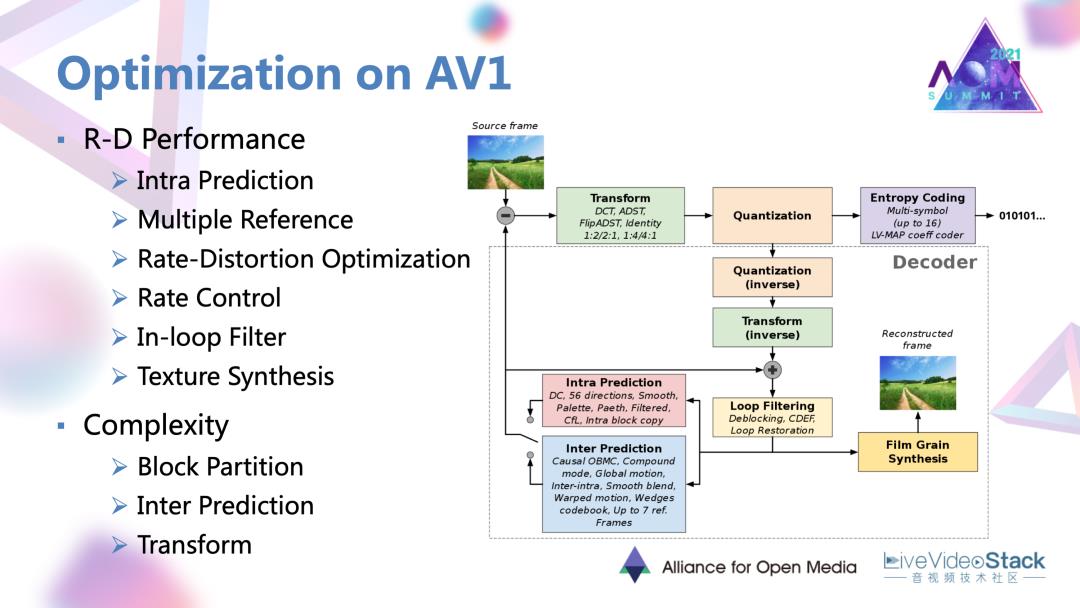
接下来是对AV1上的一些优化技术和优化工作进行一些介绍。因为现在我们的市场上的视频应用种类是非常多的,例如点播、直播,互动类的场景。对于不同类的应用,实际上对编码的需求也有一定差异。
对于AV1定稿的编码标准而言,往往没有办法同时满足这样多方面的需求的。所以对标准编码器还会衍生出很多方面的优化,含R-D性能、复杂度、延迟,一些硬件实现上的优化。对此整理了AV1定稿以后近两三年在学术界或者说以论文形式发表的优化工作,发现目前主要就是集中在性能和复杂度优化方面。上图中列出了优化方法的编码模块,实际上也可以看到其中的大部分编码过程中的大部分模块都已经有相应的优化路径。
此次分享会按照编码过程的大致顺序,对各类工作进行一些介绍。
#1. 性能优化方面
1.1 帧内预测的优化

首先是性能优化方面的工作。其中首先是帧内预测的优化工作。AV1本身是有56个方向性模式,5个非方向的帧内模式。这个工作的出发点是发现相邻块的选择的帧内模式往往是相同的或者是相近的,但目前的AV1里面还没有应用到相邻块的模式信息。此外,AV1帧内预测本身只用了一个相邻的参考线中的中间块作为参考,但当对于一些像纹理图案这种相邻样本变化比较大的区域的时,如还是使用单一的参考线,可能会导致残差较大、预测误差较大的现象。所以针对这两点,工作提出了自适应预测角度,非相邻的参考线两种方法。
1.1.1 自适应预测角度

自适应预测角度,首先要做的是改变候选角度的一个粒度。意思是说根据刚刚说的相邻块的模式,往往会被当前块选中。上图中间图中所示,对于相邻块方向的候选角度仍然保持一个细粒度。
其他方向的候选角度,可以用一个粗粒度去进行选择。在此基础上它提出了一个叫做“Allowed”,叫做允许的帧内测模式集合。最大数量有40个,意思就是将AV1原有大概60多个可能的帧内模式,按照一定的优先级顺序去填满 AIPM集合。
它的一个选择顺序:首先是非方向性的模式,这些模式的选中概率是最高的;然后是刚刚说的相邻块的方向性模式;其次是优先级,相邻块方向性模式加上一些细致度偏置以后的角度模式;最后当集合数量还没填满的时候,加入一些默认的模式进行填充。这个工作对这提出的集合进行了一个验证;发现在CTC序列上的命中率可以有93%左右,是非常有效的一个方法。
文章还相应提出了说对相邻块的角度,用一个短码进行编码替代原来的相同码上编码,实现更优质的编码。
1.1.2 自适应的非近邻参考线
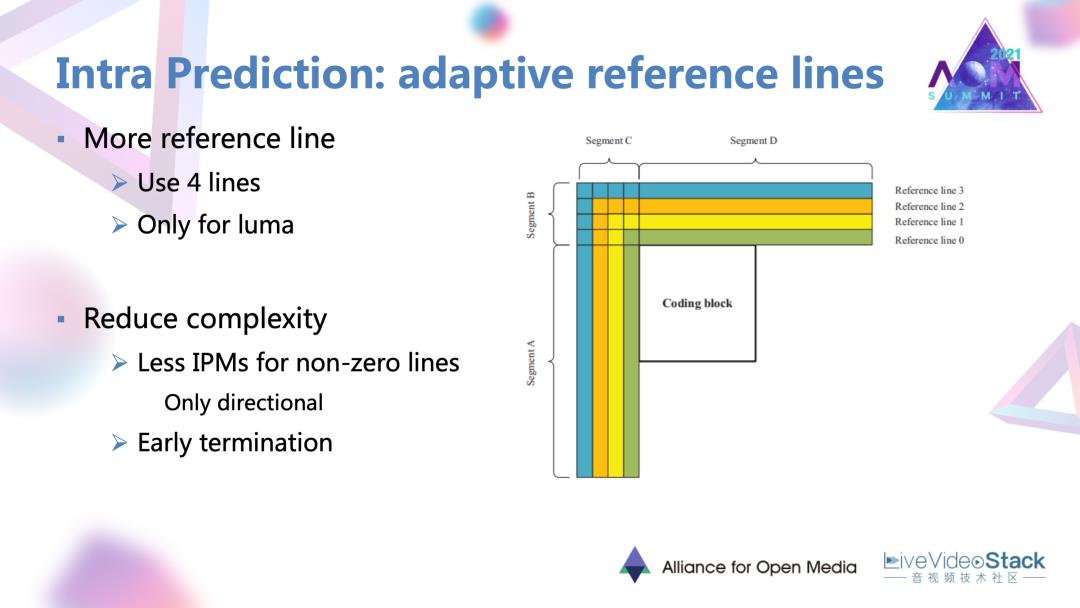
自适应的非近邻参考线的概念比较易懂的。在原来只有单个参考线的基础上,额外的添加了三个稍微相邻的但是较远的参考线,仅针对Y分量有效。但如果直接增加这样几条参考线,文章中也给出会增加成倍的编码事,要进行一个复杂度和性能提升之间的权衡。它也利用了一些快速终止以及较远参考线简化候选模式,只保留方向性模式,去达到平衡。
1.1.3 帧内预测的结果
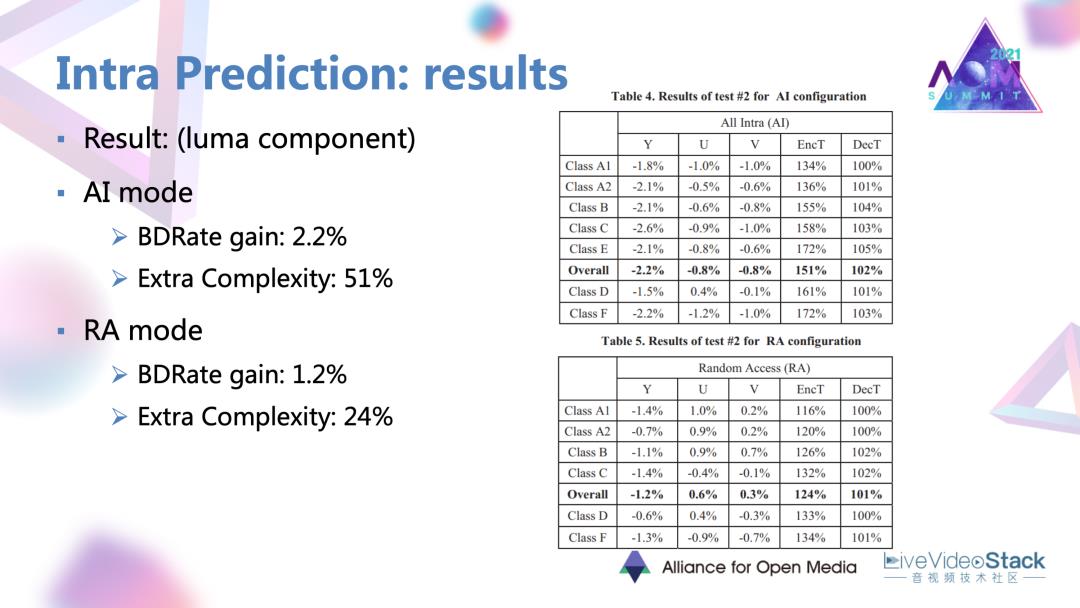
这样的两个方法最终取得了Y分量在两个编码模式里面2%的一个性能提升。
1.2 帧间预测的优化
1.2.1 针对于帧间预测的多层、多参考帧的框架
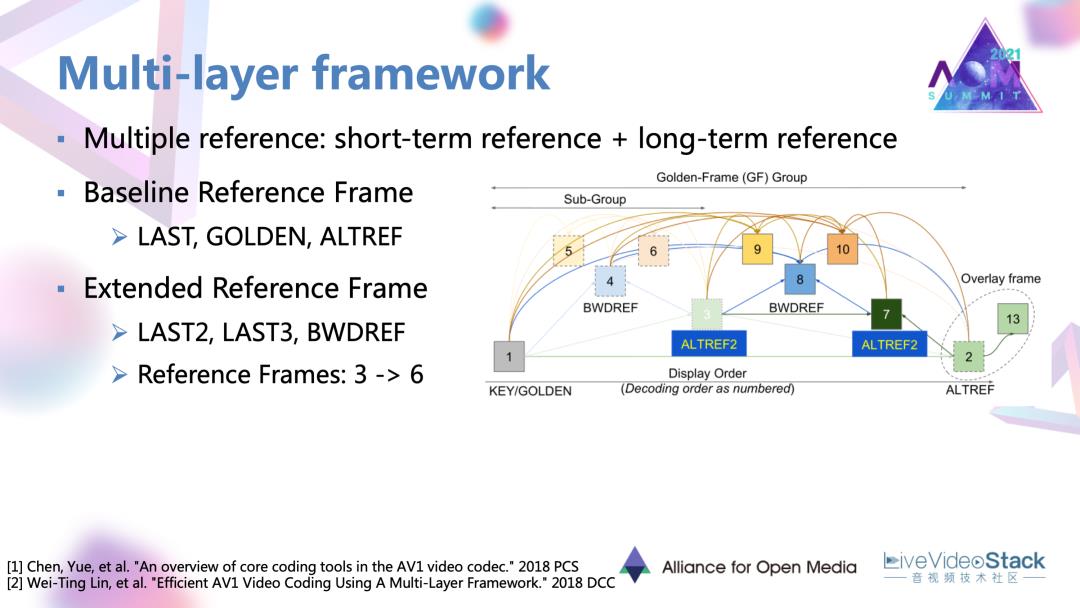
这个框架目前应用在 AV1官方编码器Libaom中,用到短期参考和长期参考,多参考帧的概念去适应不同运动内容,不同运动特性,或者不同种类内容的视频,去达到一个更好的帧间预测。
它以AV1前身VP9作为base line,VP9用到三种参考帧,一个是LAST就是紧邻的前一帧,另一个是golden frame。一个起始的golden frame加上一定数量的帧,就可以形成一个golden frame group。另一帧叫做ALT帧参考帧,利用一些较远的未来帧去通过时域滤波构建的,这个帧本身主要用于参考,是不用于具体的显示的。在一个golden frame group里会共用golden frame,还有 ALT帧。在此基础上工作就扩展了候选帧的数量是添加了两再添加了两个紧邻的过去帧,还添加了一个叫做“BWD”可以用于后项参考的参考帧。参考帧数量达到翻倍的效果。在目前的AV1版本里面,还会生成新的一帧,中间的ALT帧作为golden frame和原来的ALT参考帧的一个过渡的形态。所以可以总共有七帧参考。
1.2.2 选候参考帧集合后编码增益情况
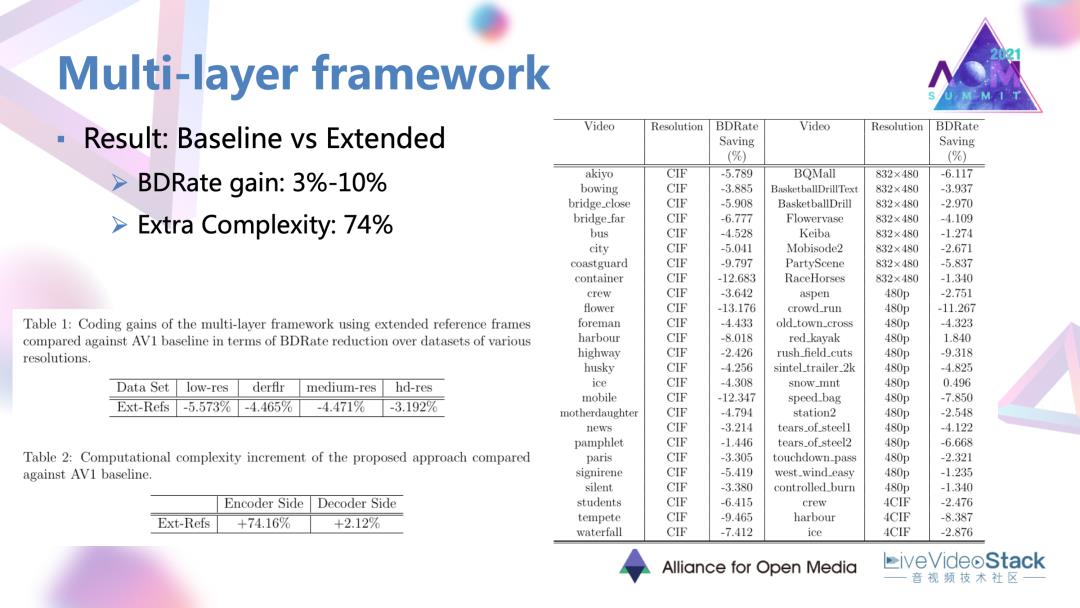
有这样一个很丰富的选候参考帧集合后,可以发现确实是有非常明显的效果,有3~10%的一个不同序列上的编码增益。但是因为参考帧的数量较多,它的一些模式选择性较多,复杂度增加也是较大。
#2. 率失真优化和RDO的优化工作
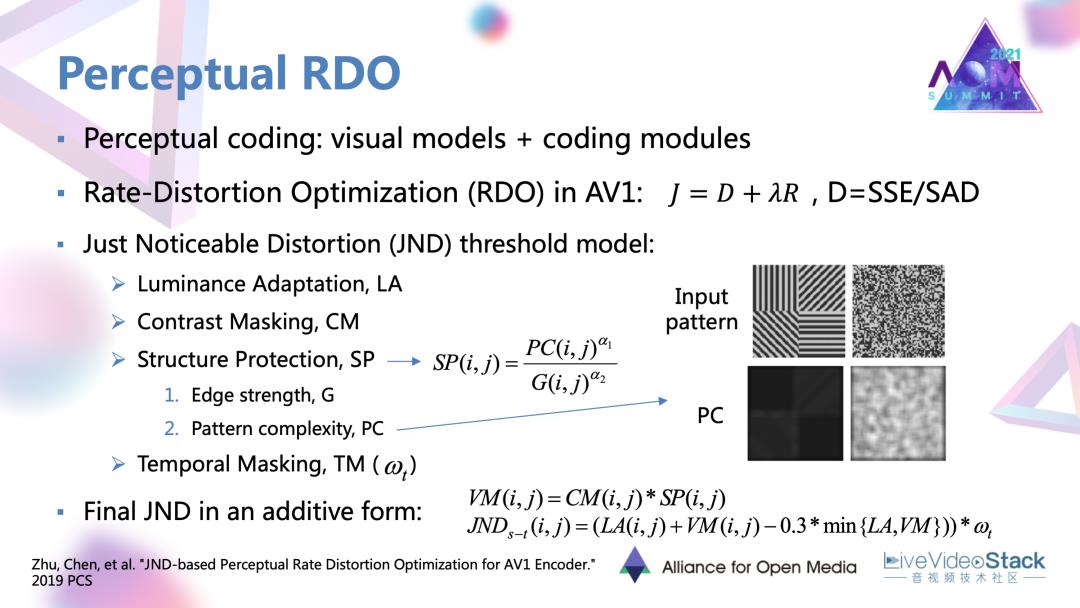
接下来是一个对于率失真优化和RDO的优化工作,是我们实验室团队和谷歌共同合作。它对原有的RDO进行了一个感知优化。整体的感知编码的概念是想把很多反映人眼主观感受的一些视觉模型。最常见的可能就是SSIM、VMAF这种质量指标模型。它与特定的编码模块相结合,达到一种去除感知冗余的目标。
我们这里的模块是RDO。像AV1这种主流的编码器中用到的拉格朗日RDO中使用的失真准则。它会用一些SSE/SAD这种很简单的数学统计量去作为度量,再用于后续的一个推导。实际上这种统计量与主观的感受的差距还是很大的,确实应该加入一些感知的因素。对此我们就加入了叫做恰可觉察失真的这个模型。
这个模型是表示大部分观看者恰好感受到失真时的阈值,也代表了一种失真可容忍的阈值。当这种可容忍阈值越高的时表示人眼对于这块区域的敏感度越低,有相反的关系。
在使用JND时,通常首先会生成一些考虑不同视觉感受的,不同视觉因素的因子。这里用到的就是亮度适应性、对比度掩蔽、结构性保护、时域掩蔽。它分别表示人眼对于不同的背景亮度、对比度,边缘结构强度,运动强度的差异化敏感度。有了这样的很多因子以后,采用像素JND,它会利用一种非线性叠加的形式,把各类因子结合起来,形成一个最终的整体模型。
2.1 JND模型与RDO更好融合的过程
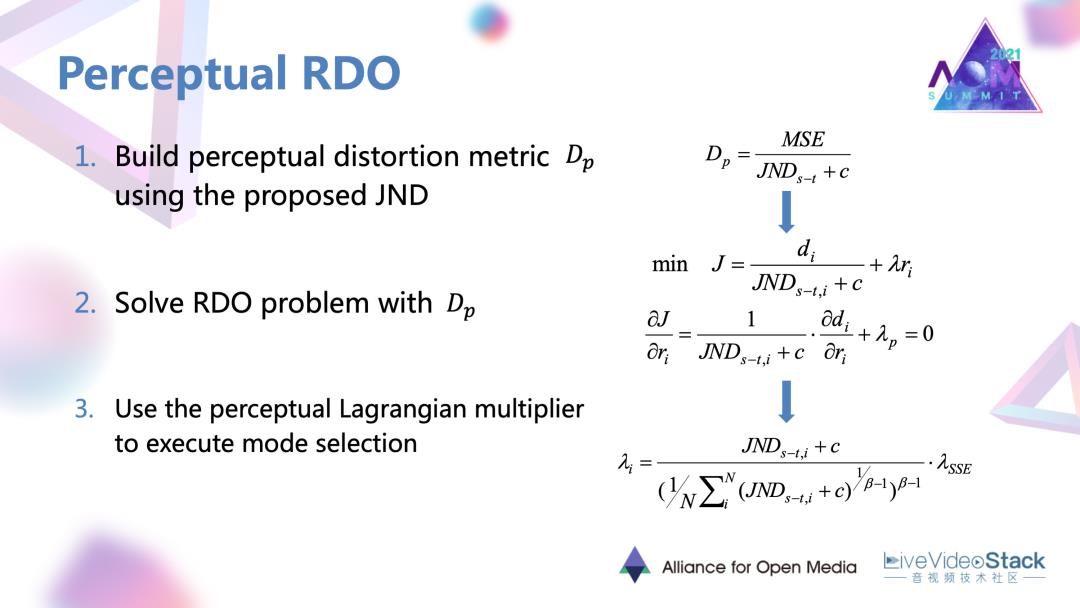
为了把得到的JND模型与RDO更好融合,进行了以下过程:首先是提出了一个感知的指标,它是将MSE还有整体JND结合起来形成的一个指标。它对于同类不同类的区域,如果存在相同的MSE失真,当它的JND阈值越大,对于人眼的敏感度越低时,它的感知失真应该更小,有比较定性的关系,利用提出的感知指标作为RDO里面新的失真准则进行后续的数学推导,最后可以推导出一个包含JND,包含以原来SSE 失真为为推导的拉格朗日乘子的形式。生成一个感知的拉格朗日乘子,去调节每个编码块的编码模式,将它往更偏向感知的方向去进行编码。
2.2 JND模型与RDO融合增益情况
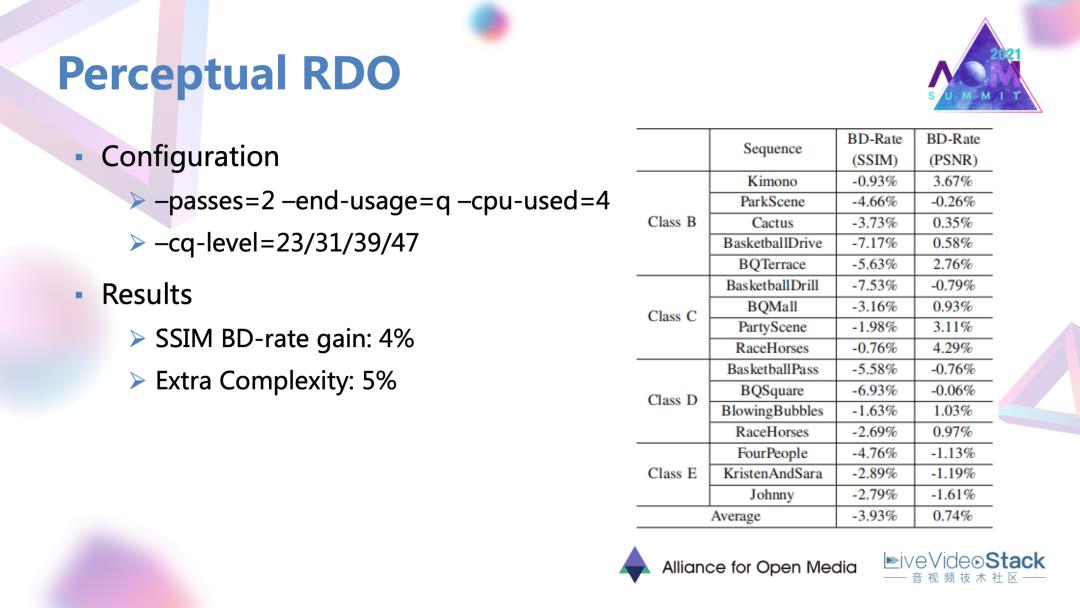
这个工作是在一个质量较高,速度又比较快的档位进行测试的,得到了4%的 SSIM BD-rate增益。
同时它的额外复杂度因为JND计算非常简便,额外复杂度并不高。
#3. AV1码率控制模块优化
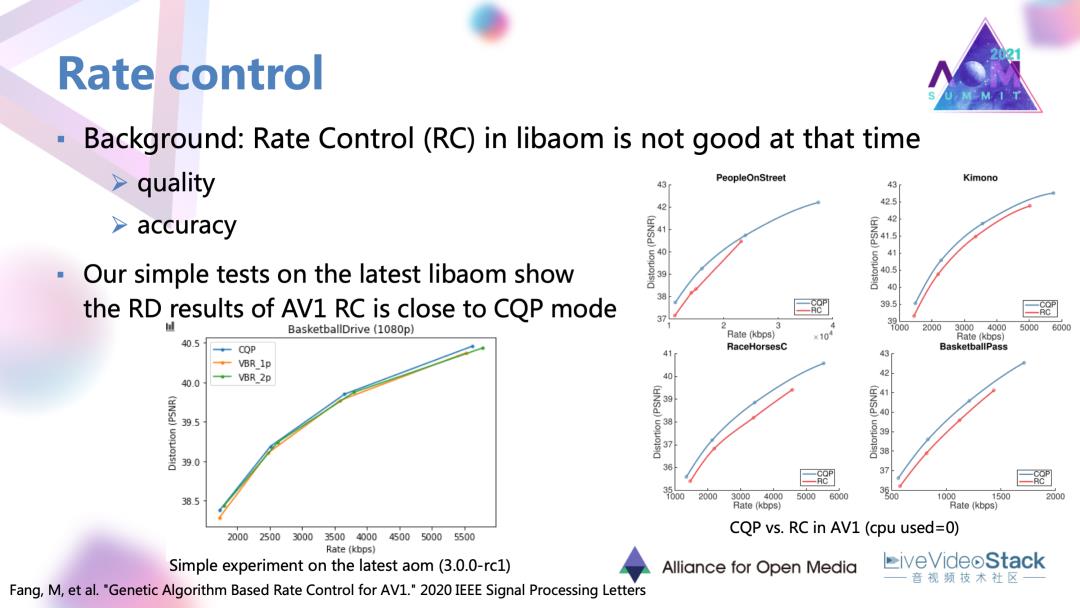
码控模块的目标是对序列各帧、各个编码模块去分配一定的码率,使得实际输出的码率接近目标的给定码率。这个工作里面首先也是对当时版本的码率控制进行了测试,发现AV1当时版本的码率控制在RD性能以及码控准确度方面有所不足。我们也对目前版本的码控方案进行了简单的测试,发现它在性能上其实与 CQP已经比较接近。不过在码控准确度方面还可以有一定的改进。
3.1 优化工作的思路
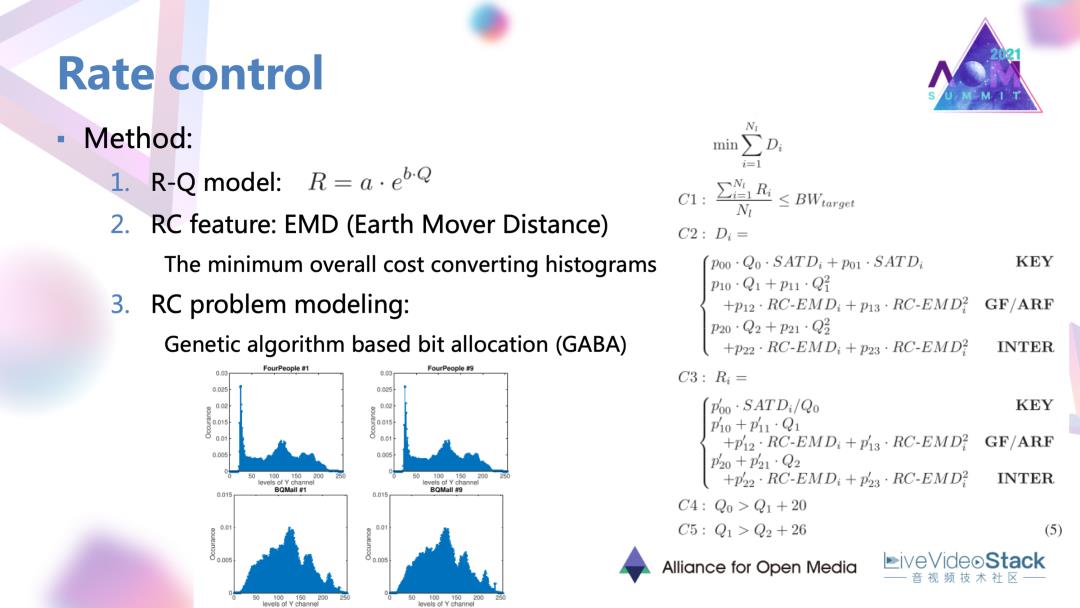
把码控的一般过程去进行一个介绍。首先是要找到码率和具体编码参数的一个关系,才能作用到实际的编码。在这个工作里面就找到了码率与量化步长 RQ的模型。其次要确定一些失真准则或特征去作为码率分配的标准。这也是找了一个叫做EMD的特征用于后续的码率估计。最后在这两点的基础上就可以对码率问题进行建模和求解。
3.2 码率约束
一般的码率码控条件是在码率约束下寻求最小的失真,在其他给定的失真或者特征情况下,限定一些额外的条件。最后的话这个工作使用了一种遗传算法的求解方式。是找到了一组码控的局部最优解去优化码率控制。
3.3 增益情况
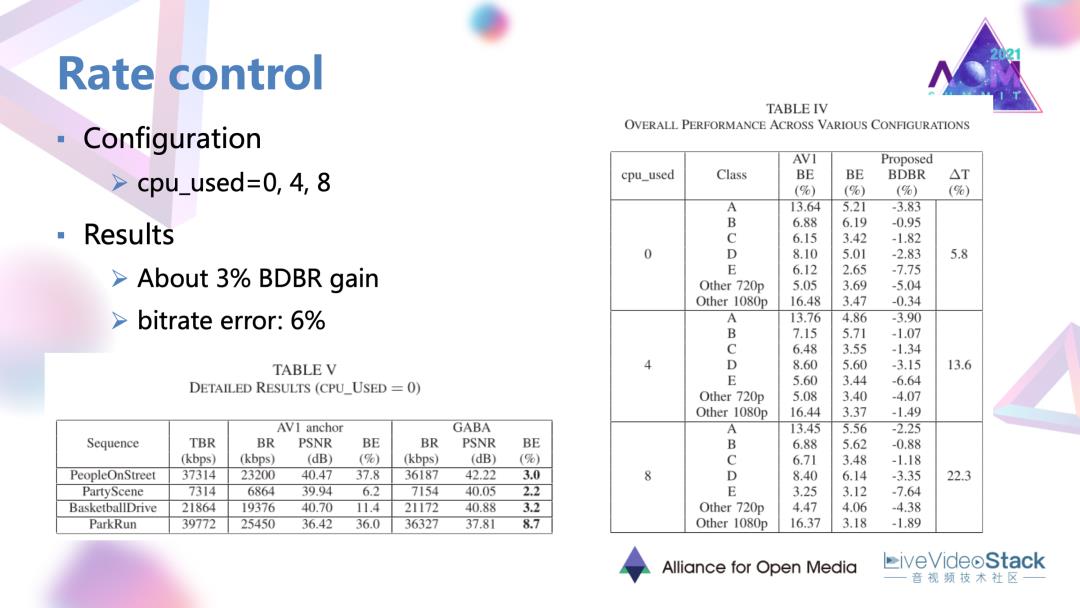
这个方法是在三种编码模式下取得了平均百分之三的增益,但是还会有一定的码控误差。
#4. AV1的环路滤波优化

接下来的话就说一下AV1的环路滤波的优化。AV1里面已经有三种滤波器,还包括一种叫做电影(纹理)颗粒合成的,后处理的模块。这几个滤波器或者模块在相应的位置以一种串联的方式对单帧进行增强的。
4.1 基于CNN的环路滤波
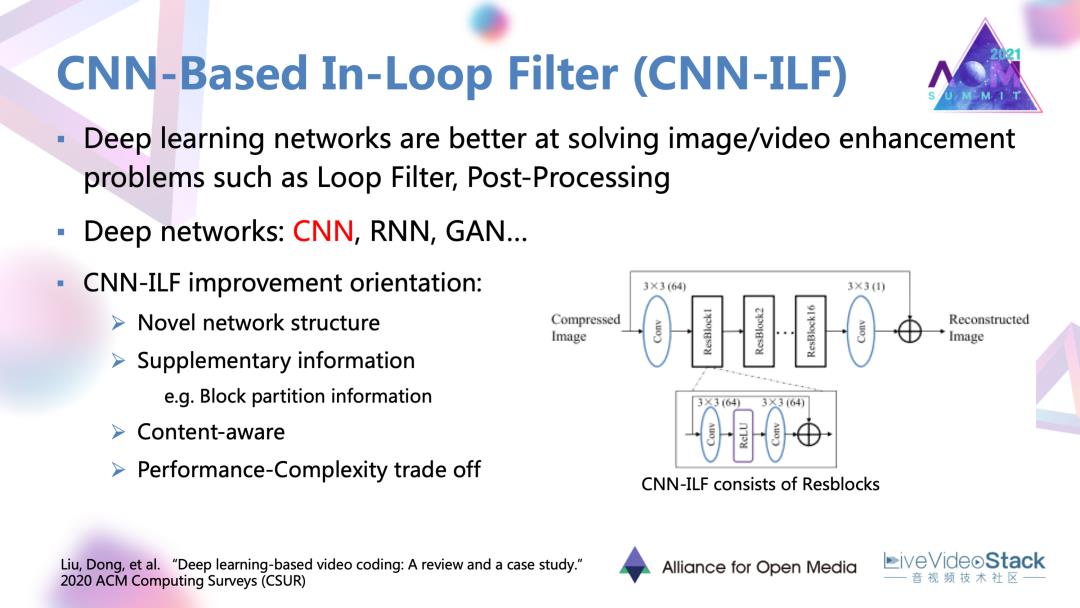
近年来有很明显的趋势,就是深度学习网络越来越多的被用在环路滤波中,可以取得非常大的增益。编码的环路滤波更多的是基于CNN的环路滤波,滤波器也有很多优化的方向。最主要是第一种设计一些新的网络架构。上图右侧给出的以Resblock为单位的残差网络,现在越来越多的被作为一种基本架构去优化。除此之外,利用辅助的编码信息,还有基于内容自适应去进行深度学习滤波,对这种深度网络进行复杂度的优化。
4.2 案例
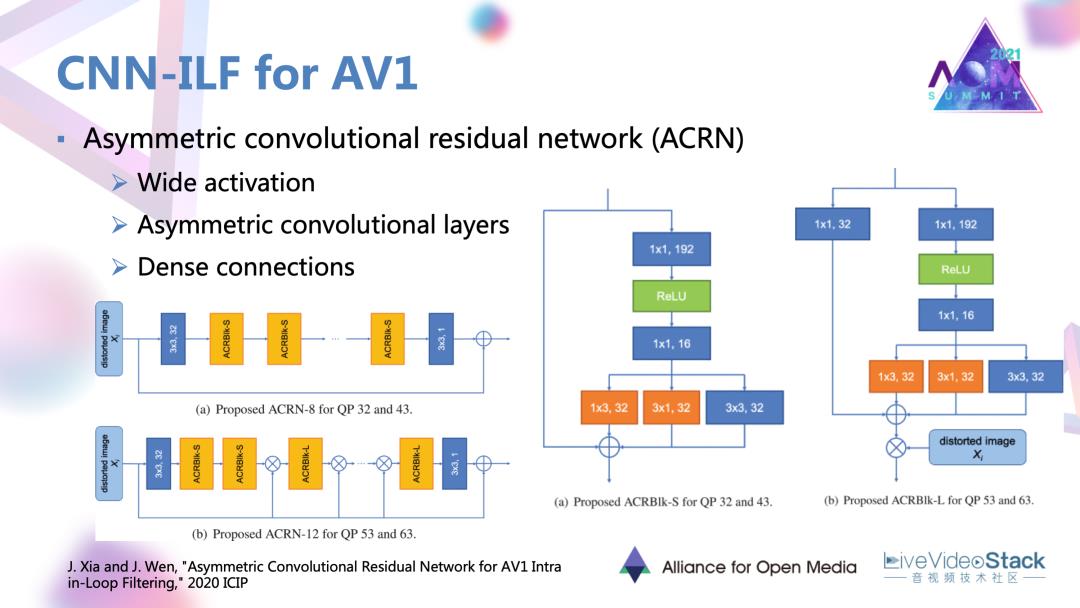
分享以去年ICIP的一个工作为例,它设计了一种非对称的卷机残差网络-ACRN,在网络里面还有这样的几种设计,例如宽激活,还有非对称的卷积层,以及稠密连接。这几种设计可以更细致的捕获到底层的一些特征,捕获一些方向性的特征,以及在网络中不断的去强化输入或者说失真图像本身的一些信息,比如说编码的块信息,达到上述效果。
4.3 CNN滤波器增益效果
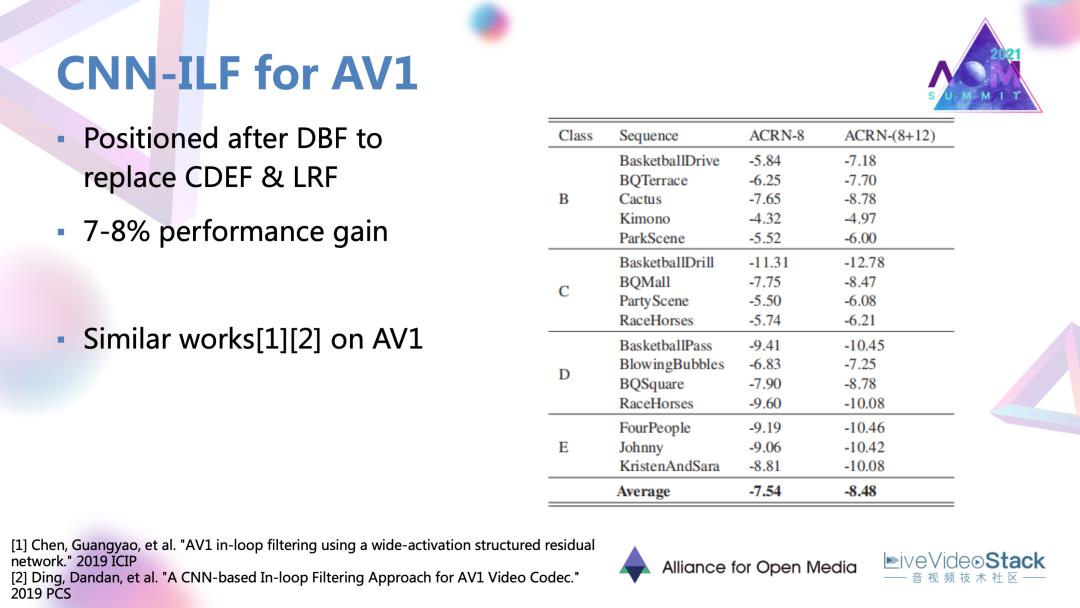
通过CNN滤波器设计替代 AV1新引入的两种滤波器,可以达到7~8%的一个编码增益,相对于其他模块是比较高的增益。
#5. 纹理合成性能优化
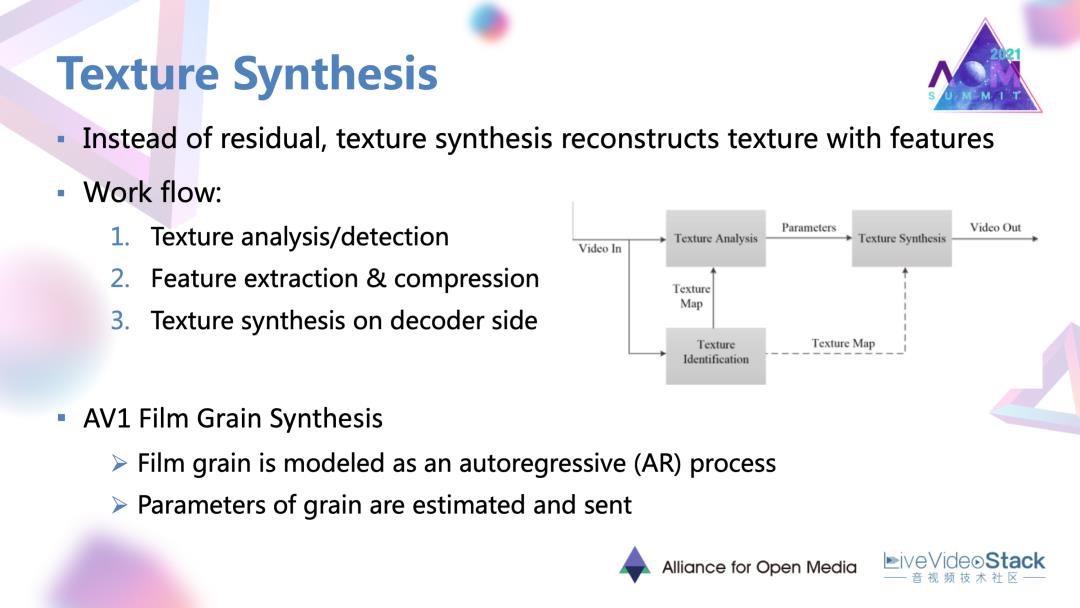
性能优化里面的最后一个方向,纹理合成。相比于一些简单静态的场景,复杂的纹理在基于残差块的编码框架下是非常难编的。所以纹理合成要做的是直接利用纹理本身的特征去进行编码和恢复。
它的一个常规的工作流主要包含首先是对纹理进行探测,那些被认为是纹理的区域,就直接去对特征进行编码,并传到解码端,在解码端也是利用纹理本身的这种特征去还原和合成纹理。例如刚刚提到的AV1电影颗粒合成也是一种纹理合成的方法。这个方法中电影的颗粒被建模为是一种叫做自回归AR的过程,AR的过程里面的一些系数就可以作为颗粒的参数或者表达在解码端去合成逼真的电影颗粒。
5.1 AV1上的纹理合成工作
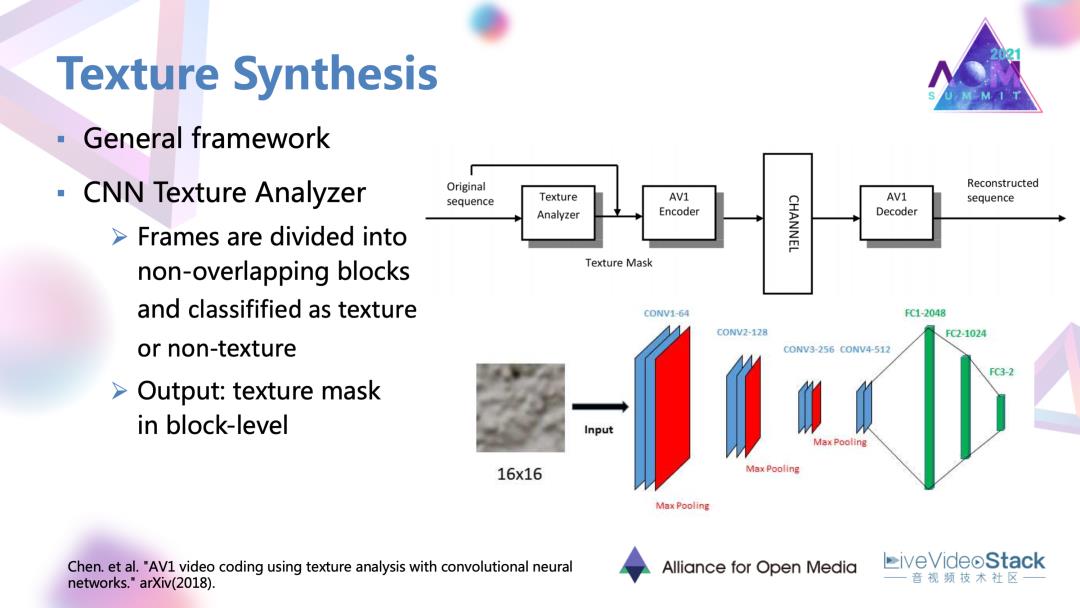
这里要介绍的一个在AV1上的纹理合成工作,也采用了比较常规的框架。首先是一个CNN的纹理分析器。它将原始帧去分割成非重叠的小块,每个小块过分析器得到二分类的判断是否为纹理的标签。最后可以在整帧上得到一个基于块级别的纹理mask。在mask指导下,被认为是纹理的区域就直接通过纹理模式编码而不再进行基于残差块的编码。
5.2 AV1上的纹理合成工作过程
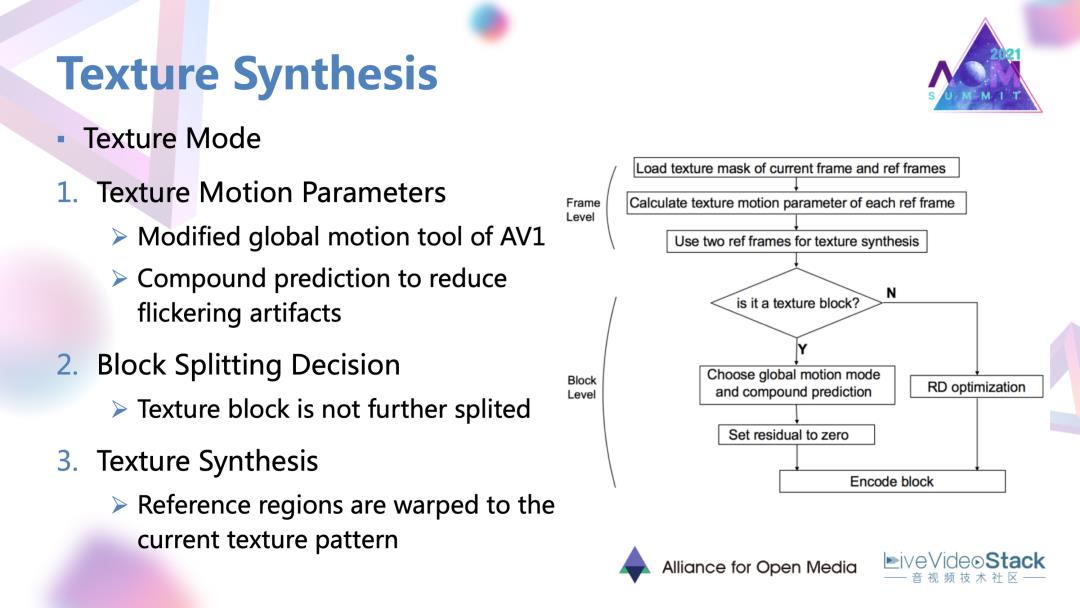
它的一个过程是这样的:首先是估计纹理的运动参数。这个参数也是在一种复合或说多参考帧的预测下得到的,也是为了降低纹理合成的闪烁以及块效应等伪像。运动参数也是被编码和传到解码端的,在解码端一些用常规编码的参考区域,就在这种运动参数的指导下进行一种warp变换,扭曲成当前区应有的这种纹理样式达到纹理合成的效果。
5.3 纹理合成的工作结果
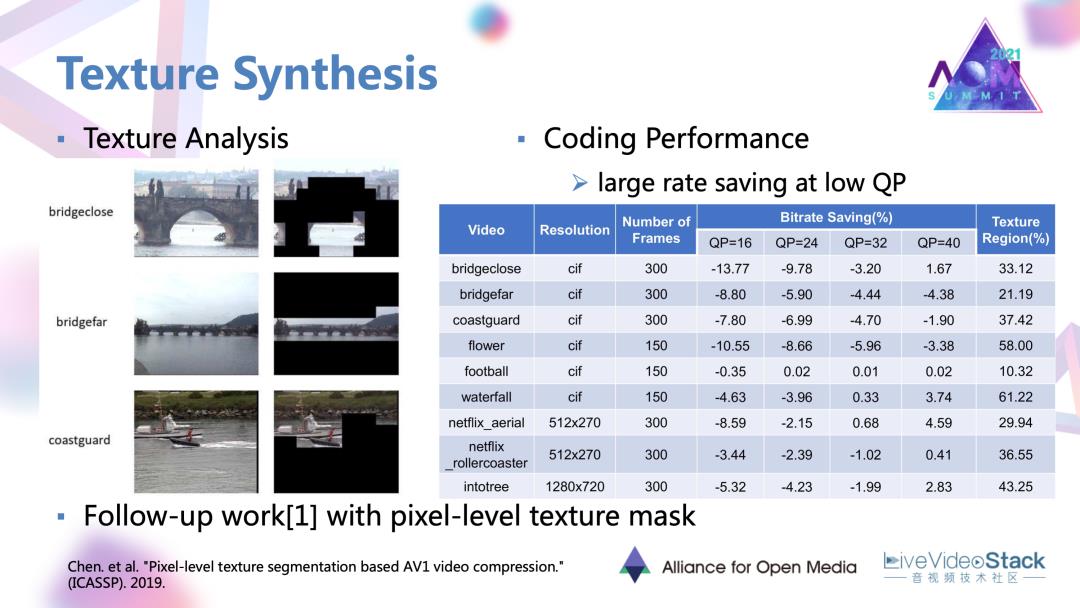
可以看到它工作给的一些结果,在低QP,高码率的情况下,这种以参数替代残差块的编码方法或者说合成方法是可以取得一定的码率节省的。
#6. AV1复杂度优化

接下来是复杂度优化方面,AV1新增的很多编码工具实际上带来了大量的编码时间,所以对AV1去进行复杂度的优化很有必要,而且会带来很大的收益。目前看到在AV1上的复杂度优化工作主要包含块划分、帧间预测、变换搜索方面的加速工作。尽管这些加速工作是针对不同模块,它们也有一些比较共通的路径。
主要有这样三种:
第一点是去人为的定义一些特征,并且基于这些特征手工制定相关的快速决策准则的传统方法。
第二点是人为设定的特征输入网络去学习的机器学习方法。
第三点是直接定义输入输出,让网络自己去学习决策过程的深度学习方法。
目前看到的AV1上的工作主要集中于前两条路径。
6.1 一个块划分的加速方法

首先要介绍的是一个块划分的加速方法,这个方法可以算作一个传统的路径。比较特殊的点在于它是基于跨分辨率的加速方法。首先是对同一视频在不同分辨率下的块划分情况进行了一个查看,发现精细的分割区域其实是共通的或者说相似的,主要是一些复杂的纹理以及快速运动的物体。基于这个现象,这个文章中就假定了一种特征f,它是表现细节的精细度以及物体运动快慢程度的一个特征。有了这样一个特征后,每个块被划分的概率或者趋势E(X),与这种特征有一个正相关的关系,进一步的去假定这个特征。f有一个分辨率不变性以后,那f就可以与两种或者多种分辨率的划分结果。比如说E(X1)、E(X2)有两种映射关系,比如说g1和g2。进一步把这个f作为中间连接的一个桥梁以后,最终可以达到这样一种目的:在得到一个低分辨率的块划分结果E(X2)以后,就可以通过反映射的方式转换为高分辨率的划分结果。通过推导后,实际上,f就并不用具体的去提取某一种特征,只是在推导里面被用到。
6.2 应用场景
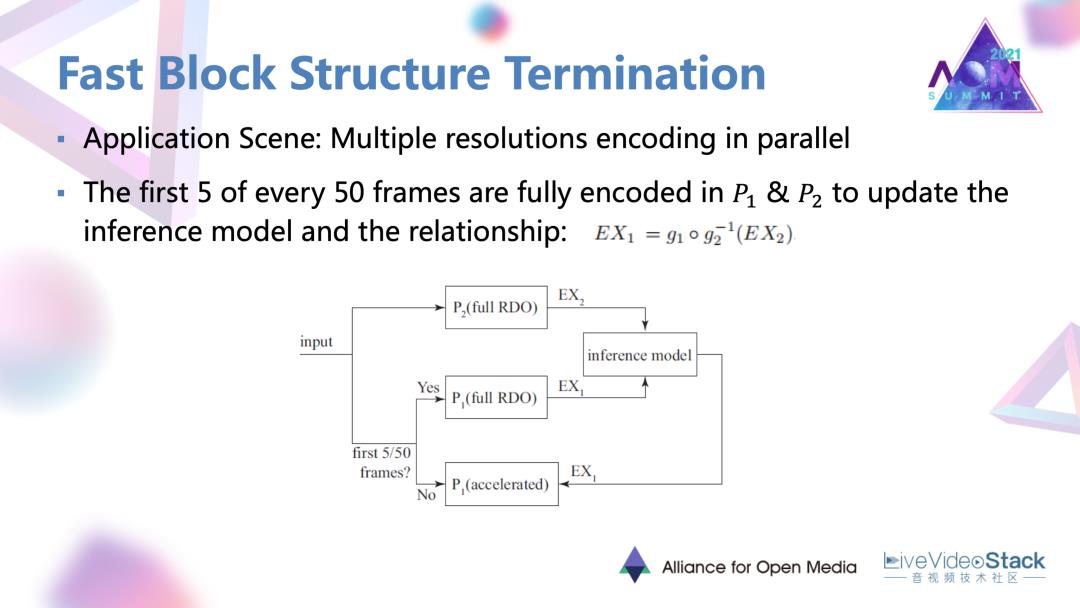
理论去具体去用的时候会存在应用场景。这个场景就是多分辨率同时编码的一个情况。这种场景在一些流媒体的服务器端是经常存在的。在具体实现的时候对于编码的每50帧,所有的50帧都是对于低分辨率,都是常规的进行RDO去进行完整编码,对于50帧里的前5帧的高分辨率编码,它也是进行完整的 RDO过程,然后会得到 E(X1)以及低分辨率的E(X2)的划分结果。首先要通过一个influence Model去推理出这两种划分结果的一个映射关系。基于前5帧的一个结果,对于之后的90%,大概是45帧,利用 influence结果以及实际编码的低分辨率划分结果,直接去推导出高分辨率的划分结果,不再进行完整的RDO,达到一个加速的目的。
6.3 节省效果

方法最终是实现大约30~40%的时间节省。这里还设定了一个预估错误的阈值,阈值越高的话,就会导致比较大的码率损失。
#7. 帧间预测加速工作
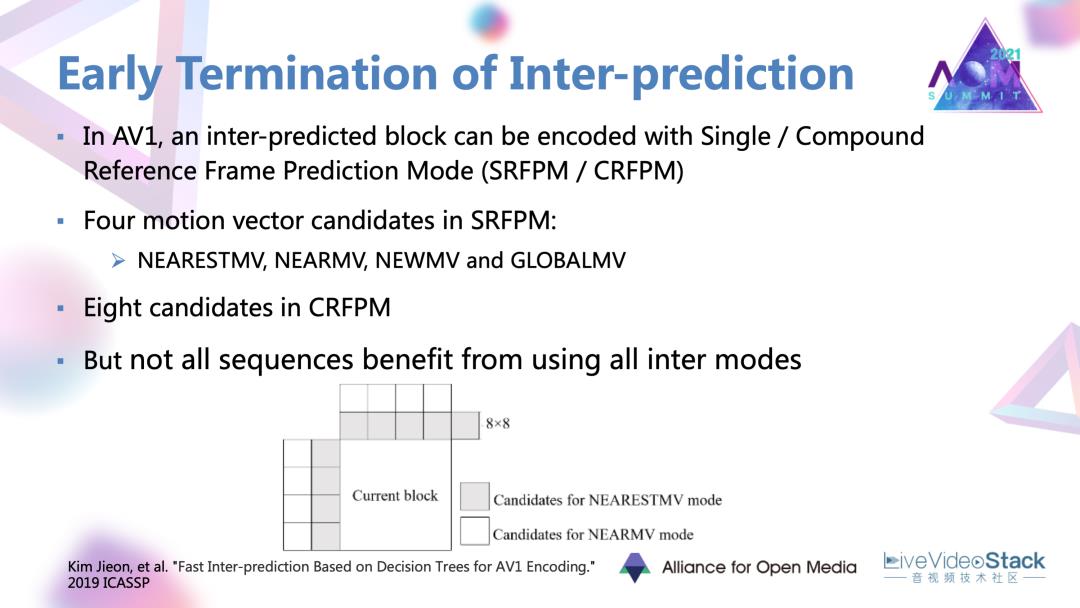
在AV1里面。目前提供了基于单参考帧,以及混合的基于双参考帧的帧间预测模式。在这两种模式下都有一些很丰富的运动向量。这篇文章的出发点,发现并不是所有的序列都会因为这些丰富的候选模式而产生很大的编码增益的,可以进行一些简化。
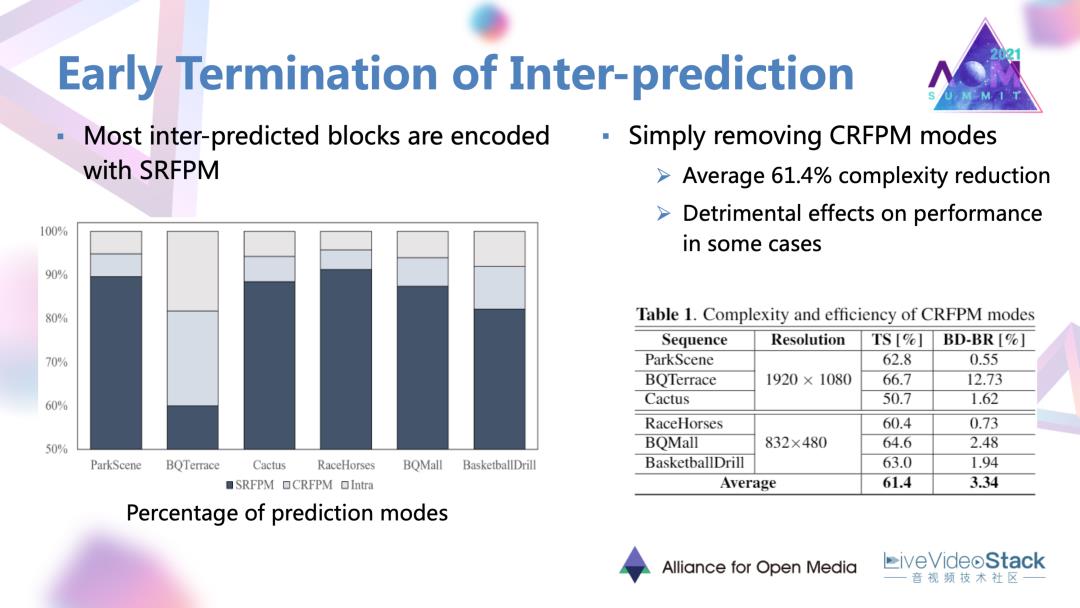
文章首先对各个序列的编码结果进行了评估,发现了大部分的帧间预测块都是以单参考帧的模式被编码的,所以一个很直接很简单的尝试就是去除混合预测模式。结果发现会有很大的编码复杂度的降低,但同时对于一些序列会产生很严重的性能损失。还是要找一种能保住性能的稳妥做法。
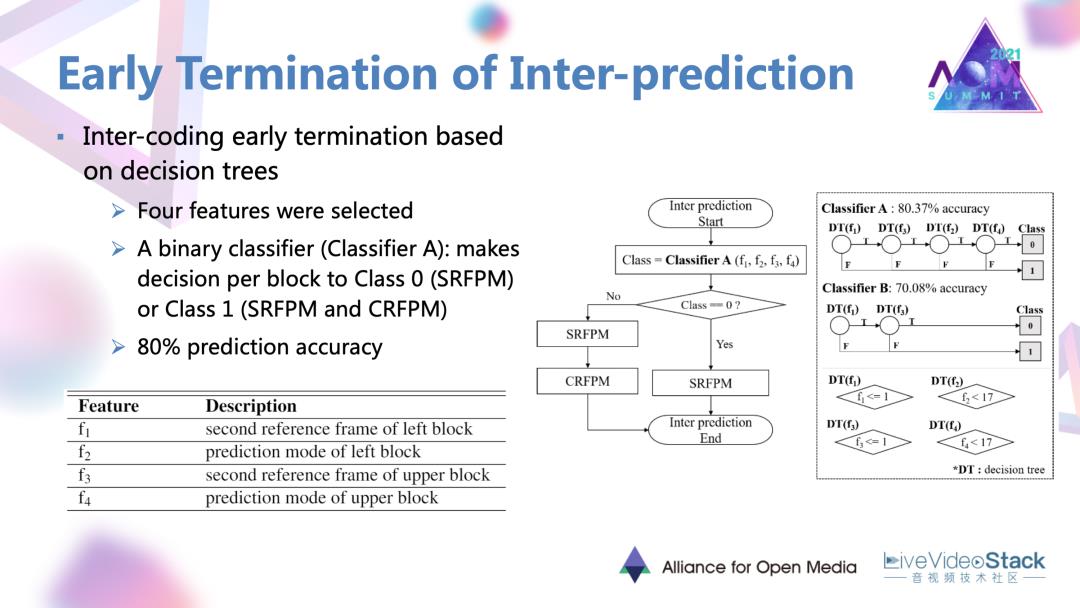
文章中也是使用了基于机器学习的决策树的网络。在网络里面首先设定了4种特征输入网络。特征分别是当前块相邻的左块与上块的预测模式,左块、上块在第二参考帧中的相应内容。特征输入以后,一个二分类的分类器就对每一块进行决策,决定当前块是进行单参考帧的预测模式,还是遍历两种帧间预测模式。这样一个分类器可以最终达到80%的预测精度。
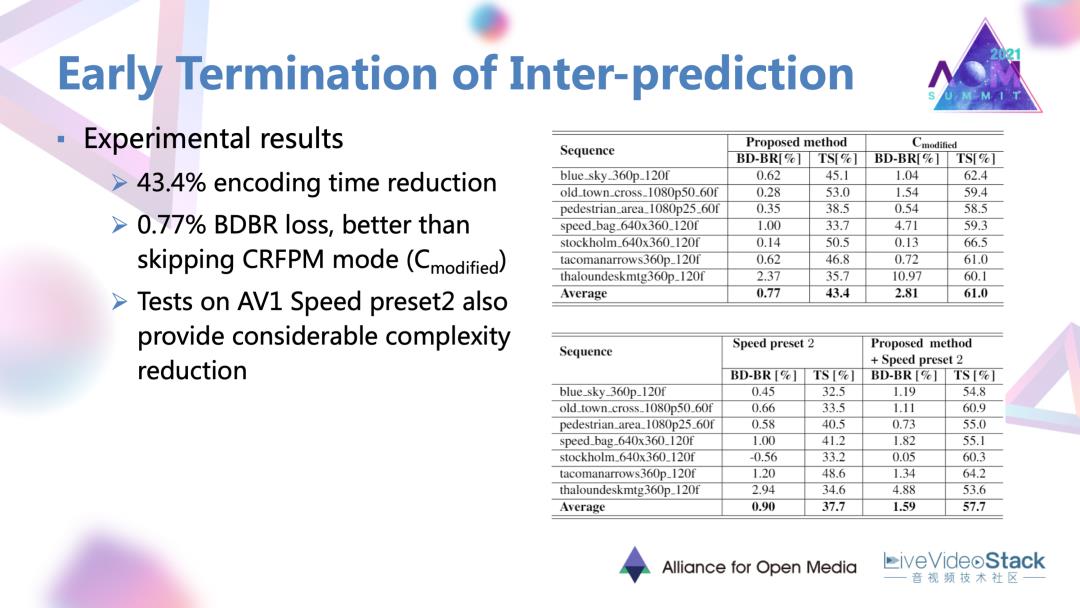
通过这样一种做法相比于原有的AV1编码器可以达到43%的编码时间降低,以及0.77%的比较小的性能损失。
#8. 变换搜索加速方法
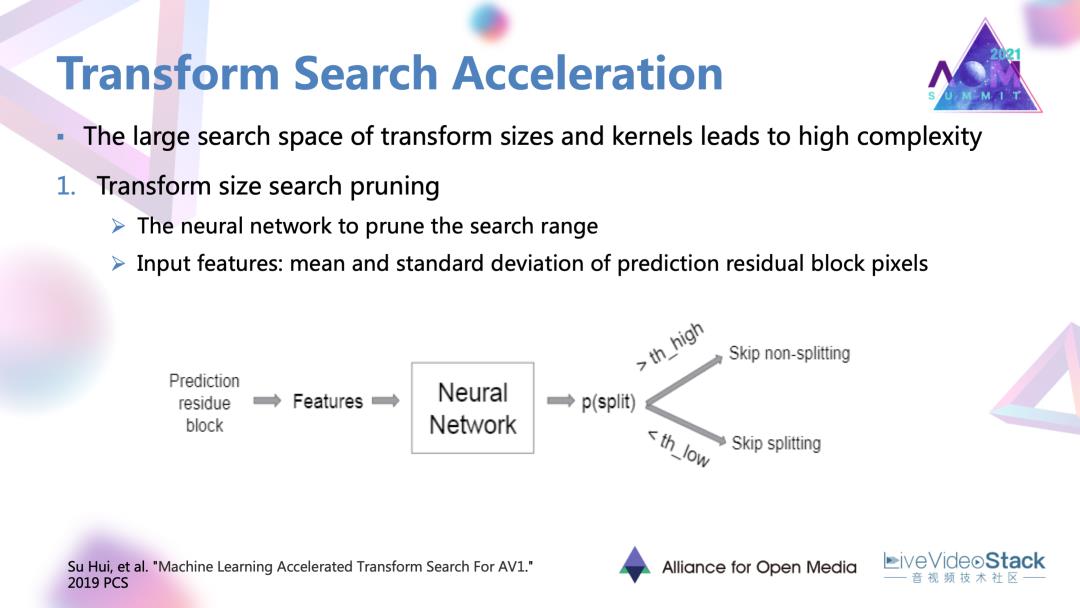
最后是一个变换搜索的加速方法。AV1提供了很丰富的变化和带来了很大的复杂度。这一个工作是对变换尺寸以及变换核搜索进行一个裁剪。
首先是尺寸的裁剪,它对于每一个预测残差块去提取均值以及标准差这两个特征,输入到一个相应的神经网络里面去学习,并最后输出一个当前块是否应该被分割的数值。这一个数值会与已经设定好的两端的阈值进行比较,当超过阈值的时候可能就不再选取比较大或者比较小的变化尺寸。
第二点就是变化核的裁剪。
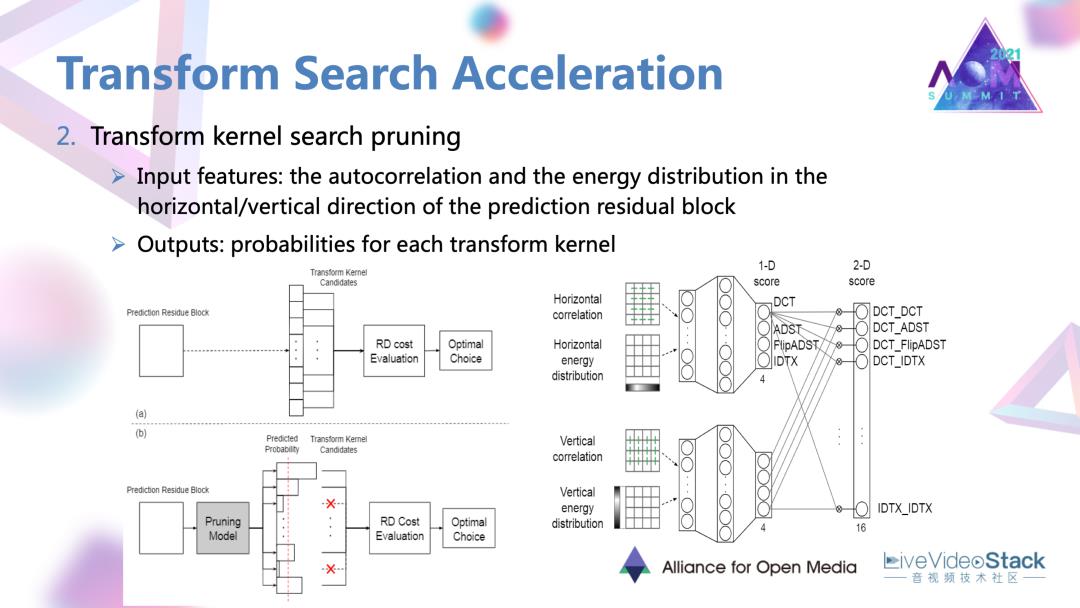
这里的做法就是对每一个残差块的纵向和横向两个方向分别设置两个网络。网络会输入一些自相关以及能量分的特征。两个子网络的一些输出进行融合以后,会最终对每一个可能的变换核被选中的概率进行一个评估。在具体的编码中,如果说被评估的是被选中概率很低的一些变化核,可能直接被舍弃,去达到一个简化的目的。
8.1 节省效果
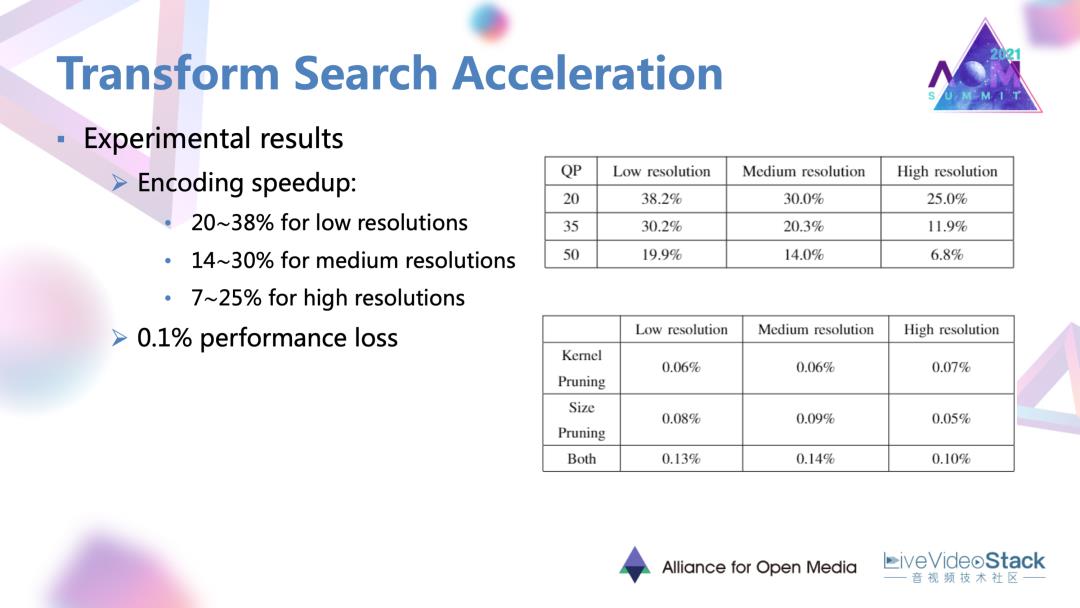
最终这样一个简化方法可以在不同分辨率下达到大概10%到30%不等的时间的节省。对于变换的简化,性能损失比较小,在0.1%左右的程度。
#9. 总结

学术界的一些优化工作实际上也涵盖了编码过程的大部分模块。很明显的趋势就是许多深度学习的网络或者方法已经开始与编码的模块进行结合,并取得了很多不错的收益。但是在标准编码器中,这种AI与Codec到底应该结合到怎样的一个程度还是需要被探究和摸索的。所以也让我们期待AOM联盟的下一代编码器AV2吧。
以上就是我所有的分享,谢谢大家!
- The cover from creativeboom.com
讲师招募 LiveVideoStackCon 2021 北京站
LiveVideoStackCon 2021 北京站(9月3-4日)正在面向社会公开招募讲师,欢迎通过 speaker@livevideostack.com 提交个人及议题资料,无论你的公司大小,title高低,老鸟还是菜鸟,只要你的内容对技术人有帮助,其他都是次要的,我们将会在24小时内给予反馈。
以上是关于学术界AV1编码优化技术的进展的主要内容,如果未能解决你的问题,请参考以下文章