如何使用MATLAB爬取北京市房价经纬度等信息
Posted slandarer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何使用MATLAB爬取北京市房价经纬度等信息相关的知识,希望对你有一定的参考价值。
注:本篇博客的启发来自于打浦桥程序员——用Matlab研究上海房价
作者[打浦桥程序员]在文中只给出了获取小区名称和链接的简单代码,这里将其进行完善,获取其价格、剩余数量、经纬度等信息。
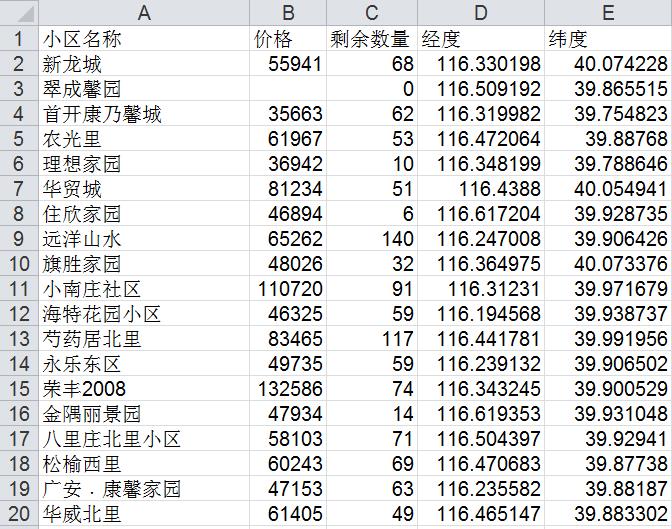
效果: 空的地方为暂无价格信息的位置
目录
0.准备工作:如何查看网页源代码
在写matlab程序之前首先要了解如何查看网页的源代码数据
右键->查看网页源代码
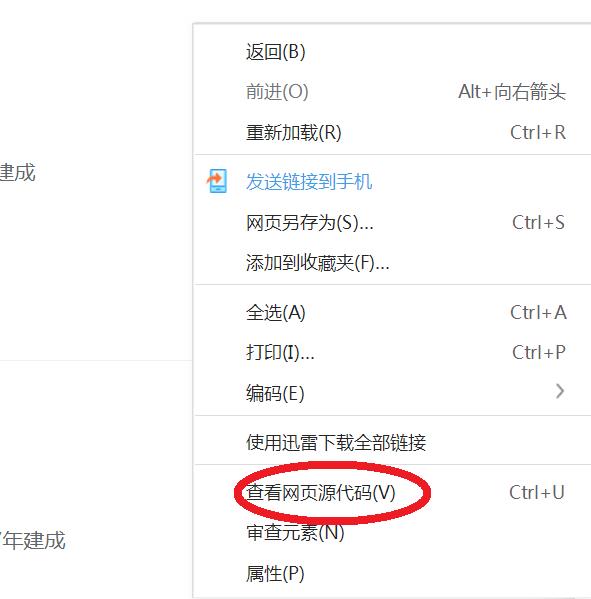
可以打开这样一个界面,看到网页源代码

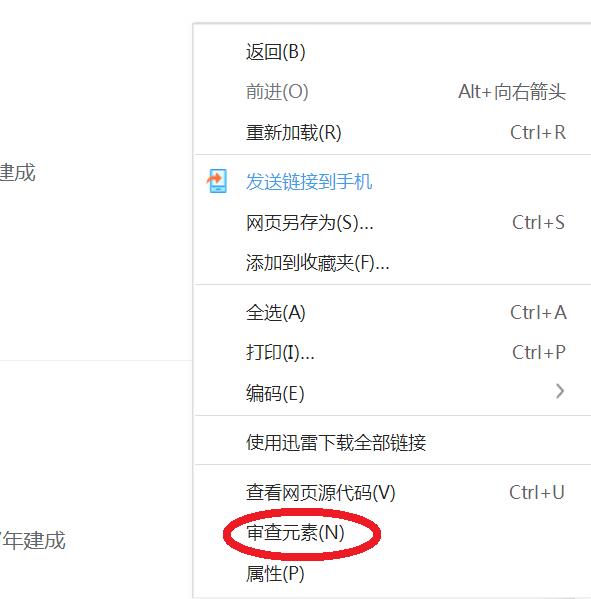
右键->审查元素
在那么多文本中找到想要的数据实在是太难,这时候我们可以使用审查元素功能。
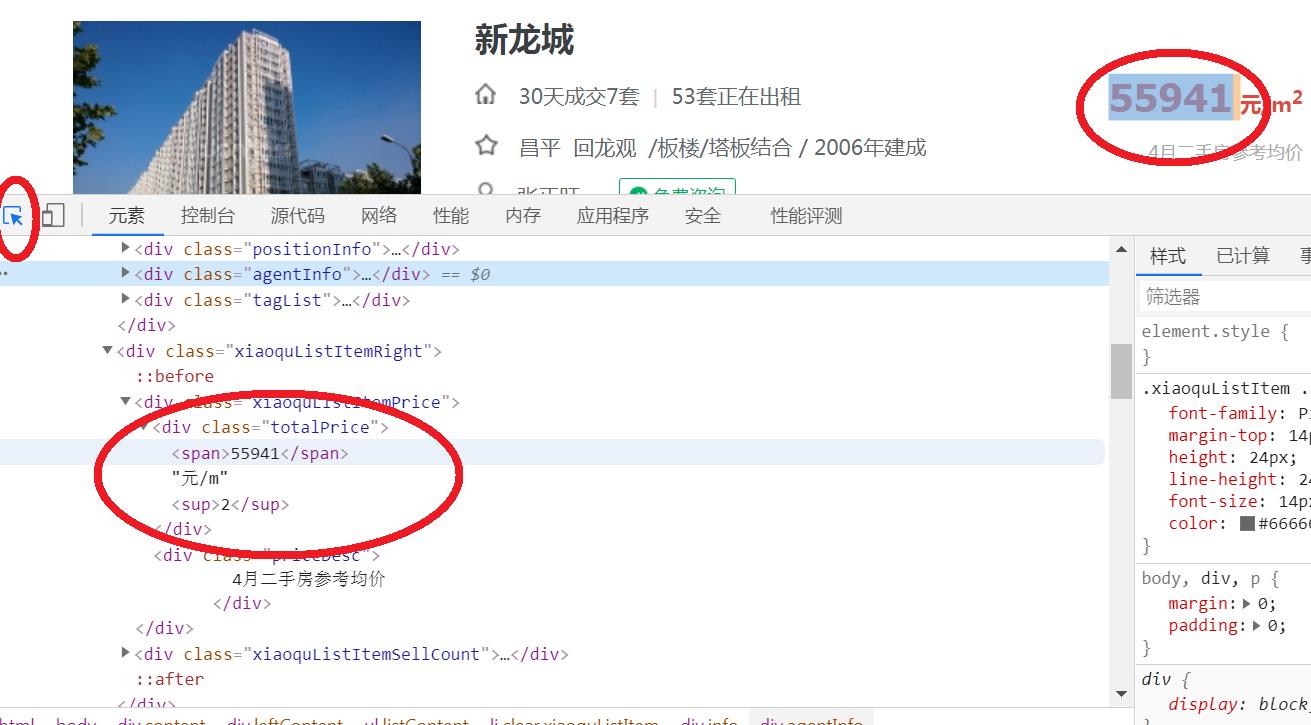
点击左侧的小箭头,可以进行元素检查器的功能,这时候点击网页的某一部分,就能显示出其前后的源代码:
1.MATLAB获取网页源代码
1.1获取源代码
可以使用以下的代码获取小区第一页的源代码:
page1_content=webread(https://bj.lianjia.com/xiaoqu/pg1/?from=rec);
读取效果如下:

1.2 urlread还是webread
建议用webread,因为urlread读取次数多了容易失效,别问我是怎么知道的。。。

1.3 如何切换页面
我们观察发现第一页和第二页的链接差别很小:
https://bj.lianjia.com/xiaoqu/pg1/?from=rec
https://bj.lianjia.com/xiaoqu/pg2/?from=rec
所以我们只需要知道一共有多少页,然后一次一次改变字符串后读取源代码即可:
path_front='http://bj.lianjia.com/xiaoqu/pg';
path_back='/?from=rec';
for page_num=1:300
page_path=[path_front,num2str(page_num),path_back];
page_content=webread(page_path);
end
1.4 如何提取源代码信息 以页码总数为例
我们可以发现:
总页数信息是被夹在totalPage和curPage着俩字符串之间的,我们首先就要找到着俩字符串位置

通过以下代码可以找到着俩玩意的起始位置
totalPage_start=regexpi(page1_content,'totalPage');
totalPage_end=regexpi(page1_content,'curPage');
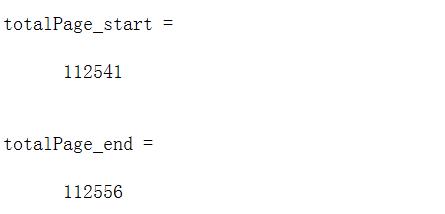
但若是直接totalPage=page1_content(totalPage_start:totalPage_end)的话会得到以下效果:
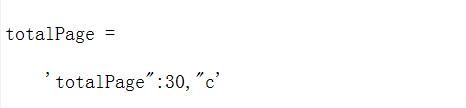
这是因为之前找到的是起始位置,想要把数字部分截取出来,可以做出如下操作:
totalPage=page1_content(totalPage_start+11:totalPage_end-3);

就可以得到总页数,但记得此时页数是字符串格式,记得将其str2num一下。
2.信息提取
2.1 房子价格
我们可以找到前后的字符串:

price_start=regexpi(page_content,'<div class="totalPrice"><span>');
price_end=regexpi(page_content,'<div class="priceDesc">');
这里因为一页有多套房子,所以price_start,price_end都是数组,我们需要写个循环提取字符串,例如:
for i=1:length(price_start)
price=page_content(price_start(i)+30:price_end(i)-42);
end
这里是为了方便大家理解才这么写的,实际写法请参考最后面的完整代码。
2.2 房子数量

与上面类似:
count_start=regexpi(page_content,'class="totalSellCount"><span>');
count_end=regexpi(page_content,'</span>套</a>');
for i=1:length(count_start)
count=page_content(count_start(i)+29:count_end(i)-1);
end
2.3 房子链接
房子的经纬度以及房子名称在不点开它自己的链接确实不好找,我们发现每个房子的链接在这:

link_start=regexpi(page_content,'<a class="img" href="https://bj.lianjia.com/xiaoqu/');
link_end=regexpi(page_content,'<img class="lj-lazy"');
for link_num=1:length(link_start)
link=page_content(link_start(link_num)+21:link_end(link_num)-24);
link_content=webread(link);
end
这样我们就可以进入每个房子自己的页面找到相关信息了
2.4 房子名称
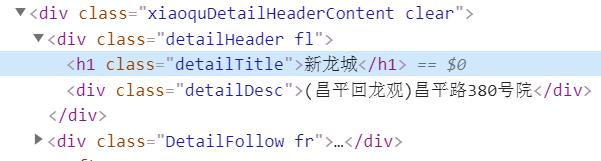
estateName_start=regexpi(link_content,'<h1 class="detailTitle">');
estateName_end=regexpi(link_content,'</h1><div class="detailDesc">');
estateName=link_content(estateName_start+24:estateName_end-1);
2.5 经纬度
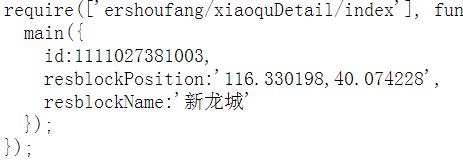
crood_start=regexpi(link_content,'resblockPosition:');
crood_end=regexpi(link_content,'resblockName:');
crood=link_content(crood_start+18:crood_end-8);
注意此时经纬度是连在一起的字符串,我们要找到逗号的位置将其分开:
sep=regexpi(crood,',');
lon=crood(1:sep-1);
lat=crood(sep+1:end);
3.完整代码
function getPriceBj
path_front='http://bj.lianjia.com/xiaoqu/pg';
path_back='/?from=rec';
data={'小区名称','价格','剩余数量','经度','纬度'};
data_num=2;
data_start_num=2;
%获取网站总页数
page1_path=[path_front,'1',path_back];
page1_content=webread(page1_path);
totalPage_start=regexpi(page1_content,'totalPage');
totalPage_end=regexpi(page1_content,'curPage');
totalPage=page1_content(totalPage_start+11:totalPage_end-3);
totalPage=str2num(totalPage);
%获取主页面信息
for page_num=1:totalPage
page_path=[path_front,num2str(page_num),path_back];
page_content=webread(page_path);
price_start=regexpi(page_content,'<div class="totalPrice"><span>');
price_end=regexpi(page_content,'<div class="priceDesc">');
count_start=regexpi(page_content,'class="totalSellCount"><span>');
count_end=regexpi(page_content,'</span>套</a>');
link_start=regexpi(page_content,'<a class="img" href="https://bj.lianjia.com/xiaoqu/');
link_end=regexpi(page_content,'<img class="lj-lazy"');
%依据主页面各小区连接获取各小区详细信息
for link_num=1:length(link_start)
link=page_content(link_start(link_num)+21:link_end(link_num)-24);
link_content=webread(link);
estateName_start=regexpi(link_content,'<h1 class="detailTitle">');
estateName_end=regexpi(link_content,'</h1><div class="detailDesc">');
estateName=link_content(estateName_start+24:estateName_end-1);
crood_start=regexpi(link_content,'resblockPosition:');
crood_end=regexpi(link_content,'resblockName:');
crood=link_content(crood_start+18:crood_end-8);
sep=regexpi(crood,',');
lon=crood(1:sep-1);
lat=crood(sep+1:end);
price=page_content(price_start(link_num)+30:price_end(link_num)-42);
count=page_content(count_start(link_num)+29:count_end(link_num)-1);
data(data_num,1)={estateName};
data(data_num,2)={str2num(price)};
data(data_num,3)={str2num(count)};
data(data_num,4)={str2num(lon)};
data(data_num,5)={str2num(lat)};
disp(['已获得数据[',num2str(data_num-1),']: ',data{data_num,1}])
data_num=data_num+1;
end
disp(' ')
disp('部分数据展示:')
disp('===================================================================')
disp(data(data_start_num:data_num-1,:))
data_start_num=data_num;
disp(' ')
end
%数据存储
writecell(data,'price_data.txt')
writecell(data,'price_data.xls')
end
4.爬取效果
命令行输出:
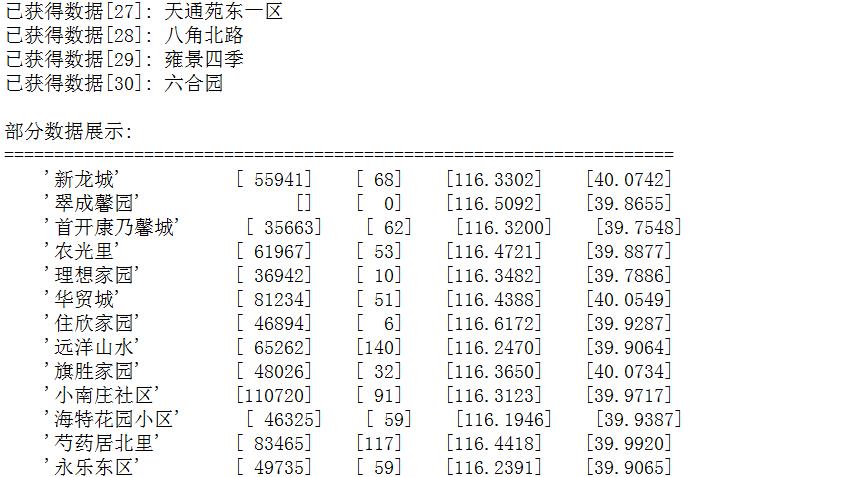
txt文件输出:

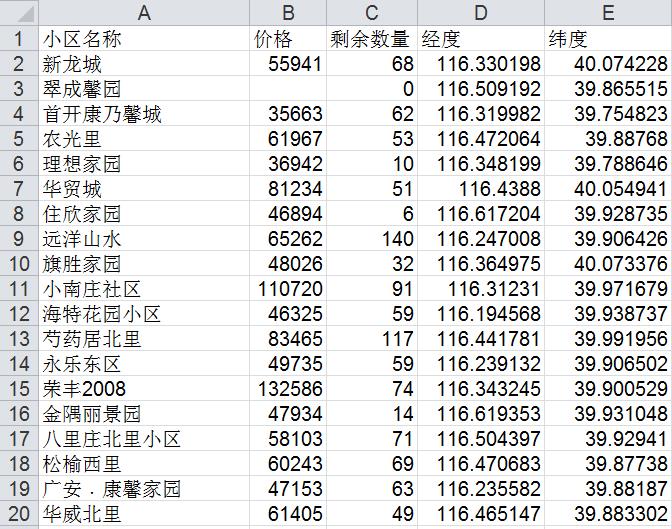
excel输出:
以上是关于如何使用MATLAB爬取北京市房价经纬度等信息的主要内容,如果未能解决你的问题,请参考以下文章