python爬虫-抓取BOSS直聘python岗位招聘信息
Posted 不加班的程序员丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫-抓取BOSS直聘python岗位招聘信息相关的知识,希望对你有一定的参考价值。
最近忙着找工作,想了解一下用人单位的招聘要求,以爬取boss直聘的招聘信息作为参考。这里记录一下的爬取流程,并不作为其它用途!
分析页面结构
-
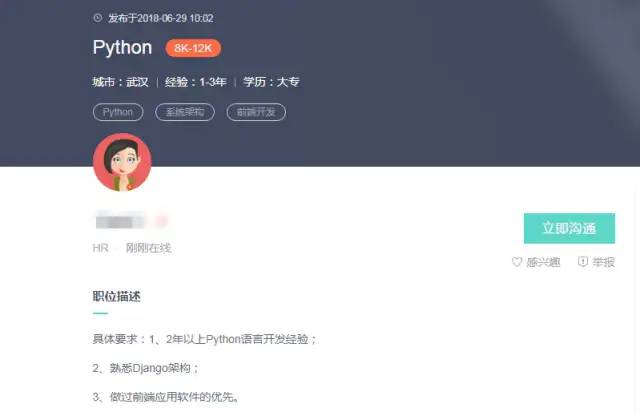
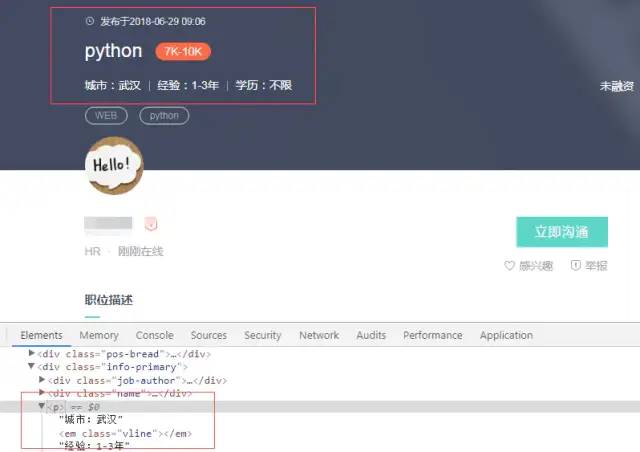
通过分析页面,发现招聘的详细信息都在详情页(如下图),故通过详情页来提取招聘内容
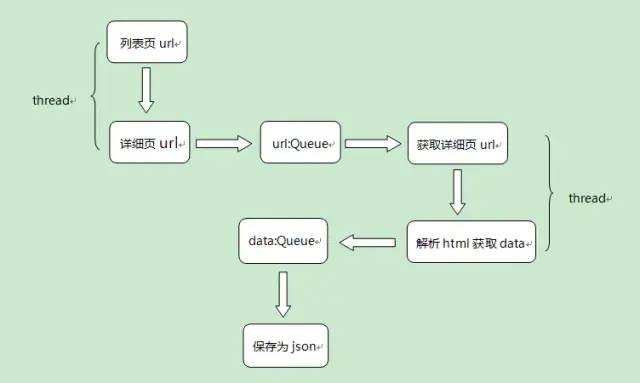
设计爬虫策略
-
通过列表页获取详细页的url地址,然后存入到url队列中,发现列表页有10页,这里使用多线程提高爬取效率;
-
通过url队列中的详情页url地址得到详情页的html内容,采用xpath解析,提取招聘信息,以字典形式存入data队列中,这里也采用多线程;
-
将data队列中的数据保存为json文件,这里每保存的一个json文件都是一个列表页所有的招聘信息。
页面请求方式的判断
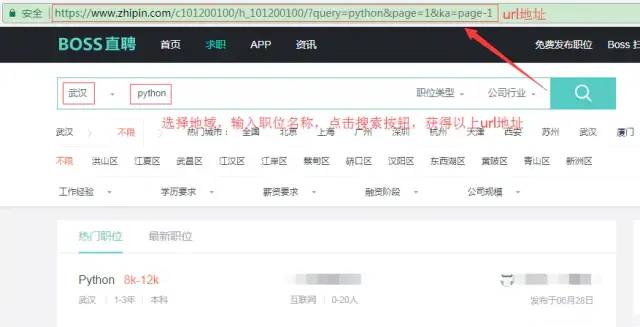
-
不难发现,这里是通过get请求并添加查询字符串获取指定页面的;
-
查询字符串参数的含义:query=python表示搜索的职位,page=1表示列表页的页码,ka=page-1这个没用到可以忽略掉;
-
对应的代码如下:
-

-
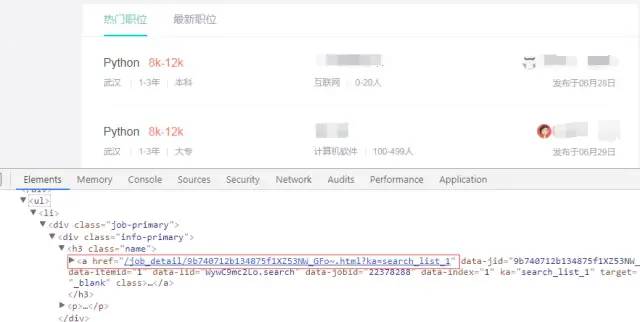
通过列表页获取详情页url
-
这里通过xpath语法@href获取a标签href属性值,拿到详细页url地址,代码如下:

解析详情页的数据

保存数据为json文件
-
通过xpath解析数据,然后将数据存储为字典放到队列中,代码如下:
代码如下:

json数据示例

其它
-
div中存在<br/>标签,xpath无法获取div标签中所有的文本内容(如下图):

-
解决办法:拿到html文本后,提前通过正则表达式剔除该标签
-
核心代码如下:
-

2.当爬取速度过快时,会被封ip,这里将多线程改为单线程版,并使用time.sleep降低爬取速度。
为了帮助大家更轻松的学好Python,我给大家分享一套Python学习资料,帮助大家在成为Python高手的道路上披荆斩棘
需要这份资料,那么帮忙点个赞扫一扫【爬虫】

以上是关于python爬虫-抓取BOSS直聘python岗位招聘信息的主要内容,如果未能解决你的问题,请参考以下文章
打造IP代理池,Python爬取Boss直聘,帮你获取全国各类职业薪酬榜