2020-2021Android中高级面试题大全
Posted bug樱樱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2020-2021Android中高级面试题大全相关的知识,希望对你有一定的参考价值。
第一章网络面试题
1、HTTP协议
HTTP简介
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。
HTTP是一个基于TCP/IP通信协议来传递数据(html 文件, 图片文件, 查询结果等)。
HTTP是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。它于1990年提出,经过几年的使用与发展,得到不断地完善和扩展。目前在WWW中使用的是HTTP/1.0的第六版,HTTP/1.1的规范化工作正在进行之中,而且HTTP-NG(Next Generation of HTTP)的建议已经提出。
HTTP协议工作于客户端-服务端架构为上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。
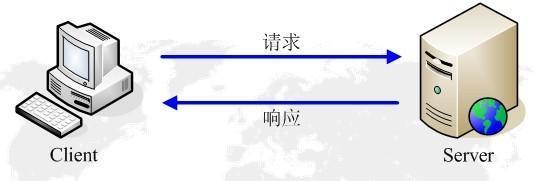
http请求-响应模型.jpg
主要特点
1、简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
2、灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
3.无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
4.无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。 5、支持B/S及C/S模式。
URI和URL的区别
URI,是uniform resource identifier,统一资源标识符,用来唯一的标识一个资源。
Web上可用的每种资源如HTML文档、图像、视频片段、程序等都是一个来URI来定位的 URI一般由三部组成: ①访问资源的命名机制 ②存放资源的主机名 ③资源自身的名称,由路径表示,着重强调于资源。
URL是uniform resource locator,统一资源定位器,它是一种具体的URI,即URL可以用来标识一个资源,而且还指明了如何locate这个资源。
URL是Internet上用来描述信息资源的字符串,主要用在各种WWW客户程序和服务器程序上,特别是著名的Mosaic。 采用URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。URL一般由三部组成: ①协议(或称为服务方式) ②存有该资源的主机IP地址(有时也包括端口号) ③主机资源的具体地址。如目录和文件名等
URN,uniform resource name,统一资源命名,是通过名字来标识资源,比如mailto:java-net@java.sun.com。
URI是以一种抽象的,高层次概念定义统一资源标识,而URL和URN则是具体的资源标识的方式。URL和URN都是一种URI。笼统地说,每个 URL 都是 URI,但不一定每个 URI 都是 URL。这是因为 URI 还包括一个子类,即统一资源名称 (URN),它命名资源但不指定如何定位资源。上面的 mailto、news 和 isbn URI 都是 URN 的示例。
在Java的URI中,一个URI实例可以代表绝对的,也可以是相对的,只要它符合URI的语法规则。而URL类则不仅符合语义,还包含了定位该资源的信息,因此它不能是相对的。 在Java类库中,URI类不包含任何访问资源的方法,它唯一的作用就是解析。 相反的是,URL类可以打开一个到达资源的流。
HTTP之请求消息Request
客户端发送一个HTTP请求到服务器的请求消息包括以下格式:
请求行(request line)、请求头部(header)、空行和请求数据四个部分组成。
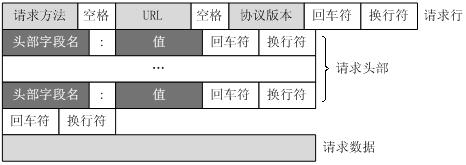
请求行以一个方法符号开头,以空格分开,后面跟着请求的URI和协议的版本。
Get请求例子,使用Charles抓取的request:
GET /562f25980001b1b106000338.jpg HTTP/1.1
Host img.mukewang.com
User-Agent Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36
Accept image/webp,image/*,*/*;q=0.8
Referer http://www.imooc.com/
Accept-Encoding gzip, deflate, sdch
Accept-Language zh-CN,zh;q=0.8
第一部分:请求行,用来说明请求类型,要访问的资源以及所使用的HTTP版本.
GET说明请求类型为GET,[/562f25980001b1b106000338.jpg]为要访问的资源,该行的最后一部分说明使用的是HTTP1.1版本。
第二部分:请求头部,紧接着请求行(即第一行)之后的部分,用来说明服务器要使用的附加信息
从第二行起为请求头部,HOST将指出请求的目的地.User-Agent,服务器端和客户端脚本都能访问它,它是浏览器类型检测逻辑的重要基础.该信息由你的浏览器来定义,并且在每个请求中自动发送等等
第三部分:空行,请求头部后面的空行是必须的
即使第四部分的请求数据为空,也必须有空行。
第四部分:请求数据也叫主体,可以添加任意的其他数据。
这个例子的请求数据为空。
POST请求例子,使用Charles抓取的request:
POST / HTTP1.1
Host:www.wrox.com
User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022)
Content-Type:application/x-www-form-urlencoded
Content-Length:40
Connection: Keep-Alive
name=Professional%20Ajax&publisher=Wiley
第一部分:请求行,第一行明了是post请求,以及http1.1版本。 第二部分:请求头部,第二行至第六行。 第三部分:空行,第七行的空行。 第四部分:请求数据,第八行。
HTTP之响应消息Response
一般情况下,服务器接收并处理客户端发过来的请求后会返回一个HTTP的响应消息。
HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文。
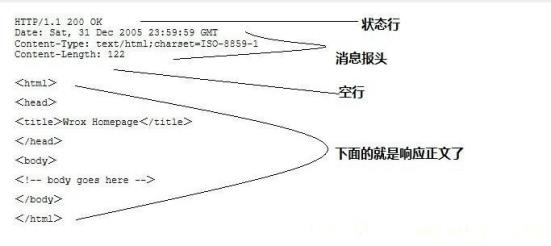
例子
HTTP/1.1 200 OK
Date: Fri, 22 May 2009 06:07:21 GMT
Content-Type: text/html; charset=UTF-8
<html>
<head></head>
<body>
<!--body goes here-->
</body>
</html>
第一部分:状态行,由HTTP协议版本号, 状态码, 状态消息 三部分组成。
第一行为状态行,(HTTP/1.1)表明HTTP版本为1.1版本,状态码为200,状态消息为(ok)
第二部分:消息报头,用来说明客户端要使用的一些附加信息
第二行和第三行为消息报头, Date:生成响应的日期和时间;Content-Type:指定了MIME类型的HTML(text/html),编码类型是UTF-8
第三部分:空行,消息报头后面的空行是必须的
第四部分:响应正文,服务器返回给客户端的文本信息。
空行后面的html部分为响应正文。
HTTP之状态码
状态代码有三位数字组成,第一个数字定义了响应的类别,共分五种类别:
1xx:指示信息–表示请求已接收,继续处理
2xx:成功–表示请求已被成功接收、理解、接受
3xx:重定向–要完成请求必须进行更进一步的操作
4xx:客户端错误–请求有语法错误或请求无法实现
5xx:服务器端错误–服务器未能实现合法的请求
常见状态码:
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
更多状态码http://www.runoob.com/http/http-status-codes.html
HTTP请求方法
根据HTTP标准,HTTP请求可以使用多种请求方法。 HTTP1.0定义了三种请求方法: GET, POST 和 HEAD方法。 HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
GET 请求指定的页面信息,并返回实体主体。
HEAD 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头
POST 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。
PUT 从客户端向服务器传送的数据取代指定的文档的内容。
DELETE 请求服务器删除指定的页面。
CONNECT HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
OPTIONS 允许客户端查看服务器的性能。
TRACE 回显服务器收到的请求,主要用于测试或诊断。
HTTP工作原理
HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
GET和POST请求的区别
GET请求
GET /books/?sex=man&name=Professional HTTP/1.1
Host: www.wrox.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6)
Gecko/20050225 Firefox/1.0.1
Connection: Keep-Alive
注意最后一行是空行
POST请求
Host: www.wrox.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6)
Gecko/20050225 Firefox/1.0.1
Content-Type: application/x-www-form-urlencoded
Content-Length: 40
Connection: Keep-Alive
name=Professional%20Ajax&publisher=Wiley
1、GET提交,请求的数据会附在URL之后(就是把数据放置在HTTP协议头中),以?分割URL和传输数据,多个参数用&连接;例 如:login.action?name=hyddd&password=idontknow&verify=%E4%BD%A0 %E5%A5%BD。如果数据是英文字母/数字,原样发送,如果是空格,转换为+,如果是中文/其他字符,则直接把字符串用BASE64加密,得出如: %E4%BD%A0%E5%A5%BD,其中%XX中的XX为该符号以16进制表示的ASCII。
POST提交:把提交的数据放置在是HTTP包的包体中。上文示例中红色字体标明的就是实际的传输数据
因此,GET提交的数据会在地址栏中显示出来,而POST提交,地址栏不会改变
2、传输数据的大小:首先声明:HTTP协议没有对传输的数据大小进行限制,HTTP协议规范也没有对URL长度进行限制。
而在实际开发中存在的限制主要有:
GET:特定浏览器和服务器对URL长度有限制,例如 IE对URL长度的限制是2083字节(2K+35)。对于其他浏览器,如Netscape、FireFox等,理论上没有长度限制,其限制取决于操作系 统的支持。
因此对于GET提交时,传输数据就会受到URL长度的 限制。
POST:由于不是通过URL传值,理论上数据不受 限。但实际各个WEB服务器会规定对post提交数据大小进行限制,Apache、IIS6都有各自的配置。
3、安全性
POST的安全性要比GET的安全性高。比如:通过GET提交数据,用户名和密码将明文出现在URL上,因为(1)登录页面有可能被浏览器缓存;(2)其他人查看浏览器的历史纪录,那么别人就可以拿到你的账号和密码了,除此之外,使用GET提交数据还可能会造成Cross-site request forgery攻击
4、Http get,post,soap协议都是在http上运行的
(1)get:请求参数是作为一个key/value对的序列(查询字符串)附加到URL上的 查询字符串的长度受到web浏览器和web服务器的限制(如IE最多支持2048个字符),不适合传输大型数据集同时,它很不安全
(2)post:请求参数是在http标题的一个不同部分(名为entity body)传输的,这一部分用来传输表单信息,因此必须将Content-type设置为:application/x-www-form- urlencoded。post设计用来支持web窗体上的用户字段,其参数也是作为key/value对传输。 但是:它不支持复杂数据类型,因为post没有定义传输数据结构的语义和规则。
(3)soap:是http post的一个专用版本,遵循一种特殊的xml消息格式 Content-type设置为: text/xml 任何数据都可以xml化。
Http协议定义了很多与服务器交互的方法,最基本的有4种,分别是GET,POST,PUT,DELETE. 一个URL地址用于描述一个网络上的资源,而HTTP中的GET, POST, PUT, DELETE就对应着对这个资源的查,改,增,删4个操作。 我们最常见的就是GET和POST了。GET一般用于获取/查询资源信息,而POST一般用于更新资源信息.
我们看看GET和POST的区别
GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditPosts.aspx?name=test1&id=123456. POST方法是把提交的数据放在HTTP包的Body中.
GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制.
GET方式需要使用Request.QueryString来取得变量的值,而POST方式通过Request.Form来获取变量的值。
GET方式提交数据,会带来安全问题,比如一个登录页面,通过GET方式提交数据时,用户名和密码将出现在URL上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从历史记录获得该用户的账号和密码.
2、TCP/IP协议
一.TCP/IP协议定义
(TransmissionControlProtocol/InternetProtocol)是传输控制协议和网络协议的简称,它定义了电子设备如何连入因特网,以及数据如何在它们之间传输的标准。
TCP/IP不是一个协议,而是一个协议族的统称,里面包括了IP协议、ICMP协议、TCP协议、以及http、ftp、pop3、https协议等。网络中的计算机都采用这套协议族进行互联。
网络协议栈架构
1.OSI七层模型
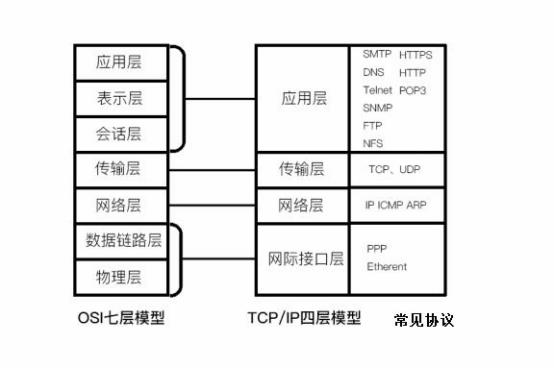
2. TCP/IP四层模型
(1)应用层:应用程序通过这一层访问网络,常见 FTP、HTTP、DNS 和 TELNET 协议;
(2)传输层:TCP 协议和 UDP 协议;
(3)网络层:IP 协议,ARP、RARP 协议,ICMP 协议等;
(4)网络接口层:是 TCP/IP 协议的基层,负责数据帧的发送和接收。

二、网络基础
1.IP 地址
网络上每一个节点都必须有一个独立的 IP 地址,通常使用的 IP 地址是一个 32bit 的数字,被分成 4 组,例如,255.255.255.255 就是一个 IP 地址。IP地址就是计算机网络组成的最小单位。
在 Linux 系统中,可以用 ifconfig -a 命令查看自己的 IP 地址,windows的DOS中可以用ipconfing查看
2.域名
用 12 位数字组成的 IP 地址,在实际应用时,用户一般不需要记住 IP 地址,互联网给每个 IP 地址起了一个别名,习惯上称作域名。
可以使用命令 nslookup 或者 ping 在Linux中查看与域名相对应的 IP 地址。
3.MAC 地址
MAC(Media Access Control)地址,或称为物理地址、硬件地址,用来定义互联网中设备的位置。
在 TCP/IP 层次模型中,网络层管理 IP 地址,链路层则负责 MAC 地址。因此每个网络位置会有一个专属于它的 IP 地址,而每个主机会有一个专属于它 MAC 地址。
三.交互时数据处理的方式(封装和分用)
封装:当应用程序发送数据的时候,数据在协议层次当中从顶向下通过每一层,每一层都会对数据增加一些首部或尾部信息,这样的信息称之为协议数据单元(Protocol Data Unit,缩写为PDU),在分层协议系统里,在指定的协议层上传送的数据单元,包含了该层的协议控制信息和用户信息。如下图所示:
· 物理层(一层)PDU指数据位(Bit)
· 数据链路层(二层)PDU指数据帧(Frame)
· 网络层(三层)PDU指数据包(Packet)
· 传输层(四层)PDU指数据段(Segment)
· 第五层以上为数据(data)
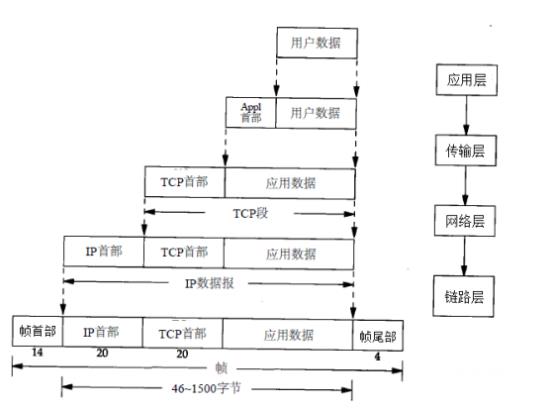
分用:当主机收到一个数据帧时,数据就从协议层底向上升,通过每一层时,检查并去掉对应层次的报文首部或尾部,与封装过程正好相反。
RFC
RFC(Request for Comment)文档是所有以太网协议的正式标准,并在其官网上面公布,由 IETF 标准协会制定。大量的 RFC 并不是正式的标准,出版的目的只是为了提供信息。RFC 的篇幅不一,从几页到几百页不等。每一种协议都用一个数字来标识,如 RFC 3720 是 iSCSI 协议的标准,数字越大说是 RFC 的内容越新或者是对应的协议(标准)出现的比较晚。
所有的 RFC 文档都可以从网络上找到,其官网为IETF。在网站上面可以通过分类以及搜索快速找到目标协议的 RFC 文档。目前在 IETF 网站上面的 RFC 文档有数千个,但是我们不需要全部掌握,在工作或学习中如果遇到可以找到对应的解释,理论与实际结合会有更好地效果,单纯阅读 RFC 的效果一般。
3、TCP的三次我握手与四次挥手理解及面试题

序列号seq:占4个字节,用来标记数据段的顺序,TCP把连接中发送的所有数据字节都编上一个序号,第一个字节的编号由本地随机产生;给字节编上序号后,就给每一个报文段指派一个序号;序列号seq就是这个报文段中的第一个字节的数据编号。
确认号ack:占4个字节,期待收到对方下一个报文段的第一个数据字节的序号;序列号表示报文段携带数据的第一个字节的编号;而确认号指的是期望接收到下一个字节的编号;因此当前报文段最后一个字节的编号+1即为确认号。
确认ACK:占1位,仅当ACK=1时,确认号字段才有效。ACK=0时,确认号无效
同步SYN:连接建立时用于同步序号。当SYN=1,ACK=0时表示:这是一个连接请求报文段。若同意连接,则在响应报文段中使得SYN=1,ACK=1。因此,SYN=1表示这是一个连接请求,或连接接受报文。SYN这个标志位只有在TCP建产连接时才会被置1,握手完成后SYN标志位被置0。
终止FIN:用来释放一个连接。FIN=1表示:此报文段的发送方的数据已经发送完毕,并要求释放运输连接
PS:ACK、SYN和FIN这些大写的单词表示标志位,其值要么是1,要么是0;ack、seq小写的单词表示序号。

三次握手过程理解

第一次握手:建立连接时,客户端发送syn包(syn=x)到服务器,并进入SYN_SENT状态,等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)。
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=x+1),同时自己也发送一个SYN包(syn=y),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=y+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。
四次挥手过程理解

1)客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时,客户端进入FIN-WAIT-1(终止等待1)状态。 TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。 2)服务器收到连接释放报文,发出确认报文,ACK=1,ack=u+1,并且带上自己的序列号seq=v,此时,服务端就进入了CLOSE-WAIT(关闭等待)状态。TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。 3)客户端收到服务器的确认请求后,此时,客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。 4)服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。 5)客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,ack=w+1,而自己的序列号是seq=u+1,此时,客户端就进入了TIME-WAIT(时间等待)状态。注意此时TCP连接还没有释放,必须经过2∗∗MSL(最长报文段寿命)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。 6)服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。
常见面试题
【问题1】为什么连接的时候是三次握手,关闭的时候却是四次握手?
答:因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,“你发的FIN报文我收到了”。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
【问题2】为什么TIME_WAIT状态需要经过2MSL(最大报文段生存时间)才能返回到CLOSE状态?
答:虽然按道理,四个报文都发送完毕,我们可以直接进入CLOSE状态了,但是我们必须假象网络是不可靠的,有可以最后一个ACK丢失。所以TIME_WAIT状态就是用来重发可能丢失的ACK报文。在Client发送出最后的ACK回复,但该ACK可能丢失。Server如果没有收到ACK,将不断重复发送FIN片段。所以Client不能立即关闭,它必须确认Server接收到了该ACK。Client会在发送出ACK之后进入到TIME_WAIT状态。Client会设置一个计时器,等待2MSL的时间。如果在该时间内再次收到FIN,那么Client会重发ACK并再次等待2MSL。所谓的2MSL是两倍的MSL(Maximum Segment Lifetime)。MSL指一个片段在网络中最大的存活时间,2MSL就是一个发送和一个回复所需的最大时间。如果直到2MSL,Client都没有再次收到FIN,那么Client推断ACK已经被成功接收,则结束TCP连接。
【问题3】为什么不能用两次握手进行连接?
答:3次握手完成两个重要的功能,既要双方做好发送数据的准备工作(双方都知道彼此已准备好),也要允许双方就初始序列号进行协商,这个序列号在握手过程中被发送和确认。
现在把三次握手改成仅需要两次握手,死锁是可能发生的。作为例子,考虑计算机S和C之间的通信,假定C给S发送一个连接请求分组,S收到了这个分组,并发 送了确认应答分组。按照两次握手的协定,S认为连接已经成功地建立了,可以开始发送数据分组。可是,C在S的应答分组在传输中被丢失的情况下,将不知道S 是否已准备好,不知道S建立什么样的序列号,C甚至怀疑S是否收到自己的连接请求分组。在这种情况下,C认为连接还未建立成功,将忽略S发来的任何数据分 组,只等待连接确认应答分组。而S在发出的分组超时后,重复发送同样的分组。这样就形成了死锁。
【问题4】如果已经建立了连接,但是客户端突然出现故障了怎么办?
TCP还设有一个保活计时器,显然,客户端如果出现故障,服务器不能一直等下去,白白浪费资源。服务器每收到一次客户端的请求后都会重新复位这个计时器,时间通常是设置为2小时,若两小时还没有收到客户端的任何数据,服务器就会发送一个探测报文段,以后每隔75秒钟发送一次。若一连发送10个探测报文仍然没反应,服务器就认为客户端出了故障,接着就关闭连接。
4、网页中输入url,到渲染整个界面的整个过程,以及中间用了什么协议?
1)过程分析:主要分为三步
DNS解析。用户输入url后,需要通过DNS解析找到域名对应的ip地址,有了ip地址才能找到服务器端。首先会查找浏览器缓存,是否有对应的dns记录。再继续按照操作系统缓存—路由缓存—isp的dns服务器—根服务器的顺序进行DNS解析,直到找到对应的ip地址。
客户端(浏览器)和服务器交互。浏览器根据解析到的ip地址和端口号发起HTTP请求,请求到达传输层,这里也就是TCP层,开始三次握手建立连接。服务器收到请求后,发送相应报文给客户端(浏览器),客户端收到相应报文并进行解析,得到html页面数据,包括html,js,css等。
客户端(浏览器)解析html数据,构建DOM树,再构造呈现树(render树),最终绘制到浏览器页面上。
2)其中涉及到TCP/IP协议簇,包括DNS,TCP,IP,HTTP协议等等。
5.TCP和UDP的区别?
TCP提供的是面向连接,可靠的字节流服务。即客户和服务器交换数据前,必须现在双方之间建立一个TCP连接(三次握手),之后才能传输数据。并且提供超时重发,丢弃重复数据,检验数据,流量控制等功能,保证数据能从一端传到另一端。
UDP 是一个简单的面向数据报的运输层协议。它不提供可靠性,只是把应用程序传给IP层的数据报发送出去,但是不能保证它们能到达目的地。由于UDP在传输数据报前不用再客户和服务器之间建立一个连接,且没有超时重发等机制,所以传输速度很快。
所以总结下来就是:
TCP 是面向连接的,UDP 是面向无连接的
TCP数据报头包括序列号,确认号,等等。相比之下UDP程序结构较简单。
TCP 是面向字节流的,UDP 是基于数据报的
TCP 保证数据正确性,UDP 可能丢包
TCP 保证数据顺序,UDP 不保证
可以看到TCP适用于稳定的应用场景,他会保证数据的正确性和顺序,所以一般的浏览网页,接口访问都使用的是TCP传输,所以才会有三次握手保证连接的稳定性。 而UDP是一种结构简单的协议,不会考虑丢包啊,建立连接等。优点在于数据传输很快,所以适用于直播,游戏等场景。
6.HTTP的几种请求方法具体介绍
常见的有四种:
GET 获取资源,没有body,幂等性
POST 增加或者修改资源,有body
PUT 修改资源,有body,幂等性
DELETE 删除资源,幂等性
7.HTTP请求和响应报文的格式,以及常用状态码
1)请求报文:
//请求行(包括method、path、HTTP版本)
GET /s HTTP/1.1
//Headers
Host: www.baidu.com
Content-Type: text/plain
//Body
搜索****
2)响应报文
//状态行 (包括HTTP版本、状态码,状态信息)
HTTP/1.1 200 OK
//Headers
Content-Type: application/json; charset=utf-8
//Body
[{"info":"xixi"}]
3)常用状态码
主要分为五种类型:
1开头, 代表临时性消息,比如100(继续发送)
2开头, 代表请求成功,比如200(OK)
3开头, 代表重定向,比如304(内容无改变)
4开头, 代表客户端的一些错误,比如403(禁止访问)
5开头, 代表服务器的一些错误,比如500
8.一个 TCP 连接上面能发多少个 HTTP 请求
一道经典的面试题是从 URL 在浏览器被被输入到页面展现的过程中发生了什么,大多数回答都是说请求响应之后 DOM 怎么被构建,被绘制出来。但是你有没有想过,收到的 HTML 如果包含几十个图片标签,这些图片是以什么方式、什么顺序、建立了多少连接、使用什么协议被下载下来的呢?
要搞懂这个问题,我们需要先解决下面五个问题:
现代浏览器在与服务器建立了一个 TCP 连接后是否会在一个 HTTP 请求完成后断开?什么情况下会断开?
一个 TCP 连接可以对应几个 HTTP 请求?
一个 TCP 连接中 HTTP 请求发送可以一起发送么(比如一起发三个请求,再三个响应一起接收)?
为什么有的时候刷新页面不需要重新建立 SSL 连接?
浏览器对同一 Host 建立 TCP 连接到数量有没有限制?
先来谈谈第一个问题:现代浏览器在与服务器建立了一个 TCP 连接后是否会在一个 HTTP 请求完成后断开?什么情况下会断开?
在 HTTP/1.0 中,一个服务器在发送完一个 HTTP 响应后,会断开 TCP 链接。但是这样每次请求都会重新建立和断开 TCP 连接,代价过大。所以虽然标准中没有设定,某些服务器对 Connection: keep-alive 的 Header 进行了支持。意思是说,完成这个 HTTP 请求之后,不要断开 HTTP 请求使用的 TCP 连接。这样的好处是连接可以被重新使用,之后发送 HTTP 请求的时候不需要重新建立 TCP 连接,以及如果维持连接,那么 SSL 的开销也可以避免,两张图片是我短时间内两次访问 https://www.github.com 的时间统计: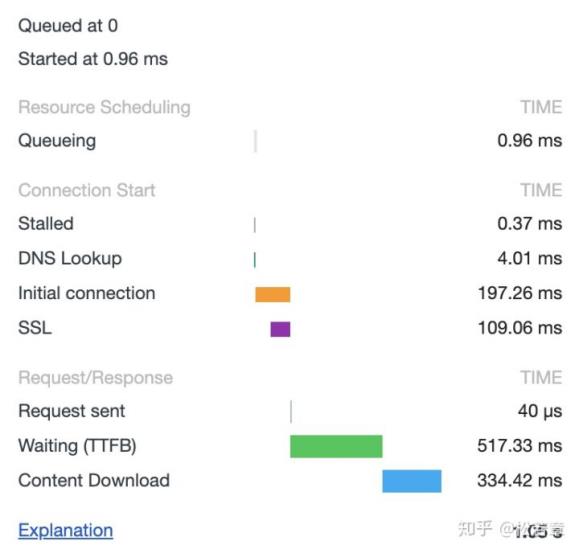
头一次访问,有初始化连接和 SSL 开销

初始化连接和 SSL 开销消失了,说明使用的是同一个 TCP 连接
持久连接:既然维持 TCP 连接好处这么多,HTTP/1.1 就把 Connection 头写进标准,并且默认开启持久连接,除非请求中写明 Connection: close,那么浏览器和服务器之间是会维持一段时间的 TCP 连接,不会一个请求结束就断掉。
所以第一个问题的答案是:默认情况下建立 TCP 连接不会断开,只有在请求报头中声明 Connection: close 才会在请求完成后关闭连接。(详细文档见下面的链接)
Hypertext Transfer Protocol – HTTP/1.1tools.ietf.org
第二个问题:一个 TCP 连接可以对应几个 HTTP 请求?
了解了第一个问题之后,其实这个问题已经有了答案,如果维持连接,一个 TCP 连接是可以发送多个 HTTP 请求的。
第三个问题:一个 TCP 连接中 HTTP 请求发送可以一起发送么(比如一起发三个请求,再三个响应一起接收)?
HTTP/1.1 存在一个问题,单个 TCP 连接在同一时刻只能处理一个请求,意思是说:两个请求的生命周期不能重叠,任意两个 HTTP 请求从开始到结束的时间在同一个 TCP 连接里不能重叠。
虽然 HTTP/1.1 规范中规定了 Pipelining 来试图解决这个问题,但是这个功能在浏览器中默认是关闭的。
先来看一下 Pipelining 是什么,RFC 2616 中规定了:
A client that supports persistent connections MAY “pipeline” its requests (i.e., send multiple requests without waiting for each response). A server MUST send its responses to those requests in the same order that the requests were received. 一个支持持久连接的客户端可以在一个连接中发送多个请求(不需要等待任意请求的响应)。收到请求的服务器必须按照请求收到的顺序发送响应。
至于标准为什么这么设定,我们可以大概推测一个原因:由于 HTTP/1.1 是个文本协议,同时返回的内容也并不能区分对应于哪个发送的请求,所以顺序必须维持一致。比如你向服务器发送了两个请求 GET /query?q=A和 GET /query?q=B,服务器返回了两个结果,浏览器是没有办法根据响应结果来判断响应对应于哪一个请求的。
Pipelining 这种设想看起来比较美好,但是在实践中会出现许多问题:
一些代理服务器不能正确的处理 HTTP Pipelining。
正确的流水线实现是复杂的。详见HTTP/1.x 的连接管理developer.mozilla.org
Head-of-line Blocking 连接头阻塞:在建立起一个 TCP 连接之后,假设客户端在这个连接连续向服务器发送了几个请求。按照标准,服务器应该按照收到请求的顺序返回结果,假设服务器在处理首个请求时花费了大量时间,那么后面所有的请求都需要等着首个请求结束才能响应。
所以现代浏览器默认是不开启 HTTP Pipelining 的。
但是,HTTP2 提供了 Multiplexing 多路传输特性,可以在一个 TCP 连接中同时完成多个 HTTP 请求。至于 Multiplexing 具体怎么实现的就是另一个问题了。我们可以看一下使用 HTTP2 的效果。

绿色是发起请求到请求返回的等待时间,蓝色是响应的下载时间,可以看到都是在同一个 Connection,并行完成的
所以这个问题也有了答案:在 HTTP/1.1 存在 Pipelining 技术可以完成这个多个请求同时发送,但是由于浏览器默认关闭,所以可以认为这是不可行的。在 HTTP2 中由于 Multiplexing 特点的存在,多个 HTTP 请求可以在同一个 TCP 连接中并行进行。
那么在 HTTP/1.1 时代,浏览器是如何提高页面加载效率的呢?主要有下面两点:
维持和服务器已经建立的 TCP 连接,在同一连接上顺序处理多个请求。
和服务器建立多个 TCP 连接。
第四个问题:为什么有的时候刷新页面不需要重新建立 SSL 连接?
在第一个问题的讨论中已经有答案了,TCP 连接有的时候会被浏览器和服务端维持一段时间。TCP 不需要重新建立,SSL 自然也会用之前的。
第五个问题:浏览器对同一 Host 建立 TCP 连接到数量有没有限制?
假设我们还处在 HTTP/1.1 时代,那个时候没有多路传输,当浏览器拿到一个有几十张图片的网页该怎么办呢?肯定不能只开一个 TCP 连接顺序下载,那样用户肯定等的很难受,但是如果每个图片都开一个 TCP 连接发 HTTP 请求,那电脑或者服务器都可能受不了,要是有 1000 张图片的话总不能开 1000 个TCP 连接吧,你的电脑同意 NAT 也不一定会同意。
所以答案是:有。Chrome 最多允许对同一个 Host 建立六个 TCP 连接。不同的浏览器有一些区别。
那么回到最开始的问题,收到的 HTML 如果包含几十个图片标签,这些图片是以什么方式、什么顺序、建立了多少连接、使用什么协议被下载下来的呢?
如果图片都是 HTTPS 连接并且在同一个域名下,那么浏览器在 SSL 握手之后会和服务器商量能不能用 HTTP2,如果能的话就使用 Multiplexing 功能在这个连接上进行多路传输。不过也未必会所有挂在这个域名的资源都会使用一个 TCP 连接去获取,但是可以确定的是 Multiplexing 很可能会被用到。
如果发现用不了 HTTP2 呢?或者用不了 HTTPS(现实中的 HTTP2 都是在 HTTPS 上实现的,所以也就是只能使用 HTTP/1.1)。那浏览器就会在一个 HOST 上建立多个 TCP 连接,连接数量的最大限制取决于浏览器设置,这些连接会在空闲的时候被浏览器用来发送新的请求,如果所有的连接都正在发送请求呢?那其他的请求就只能等等了。
第二章数据结构与算法面试题

第三章Java面试题

第三章Java面试题

最后
———— 由于篇幅原因,以上完整学习笔记pdf如有需要,可以点击这里获得免费领取方式!
以上是关于2020-2021Android中高级面试题大全的主要内容,如果未能解决你的问题,请参考以下文章
BAT面试 Android中高级面试题解析大全,金九银十涨薪必备
金九银十求职季,这份阿里出品 Android开发中高级面试题大全,不容错过