基于ID_MAPPING(ID拉通)实现多源用户整合及行为数据采集
Posted 信小呆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于ID_MAPPING(ID拉通)实现多源用户整合及行为数据采集相关的知识,希望对你有一定的参考价值。
1、序言:
全渠道数据采集,全域用户ID打通,全场景多维度数据分析,全渠道精准用户触达,是现在企业数字化营销的必备技能。同时数据安全也成为大家的关注问题,脱离数据上云,私有化服务成为大家的必选,对于好多中小型公司来说,去购买行业内的营销智能产品成本都点高,或者说是大才小用,现在我们就基于一个小案例来讲解和设计一下如何实现这个产品。
2、场景
现在举一个新零售的例子,某安保险实现线上产品销售,有自己产品官网、H5、小程序等,对于他们的交集用户及行为很难分析,多端新增,多端活跃等指标都是很有价值的用户,现在需要结合全渠道分析产出高价值的用户、并分析精准营销的行动与反馈,真正的实现数字化营销。
3、设计方案
3.1、简单架构图
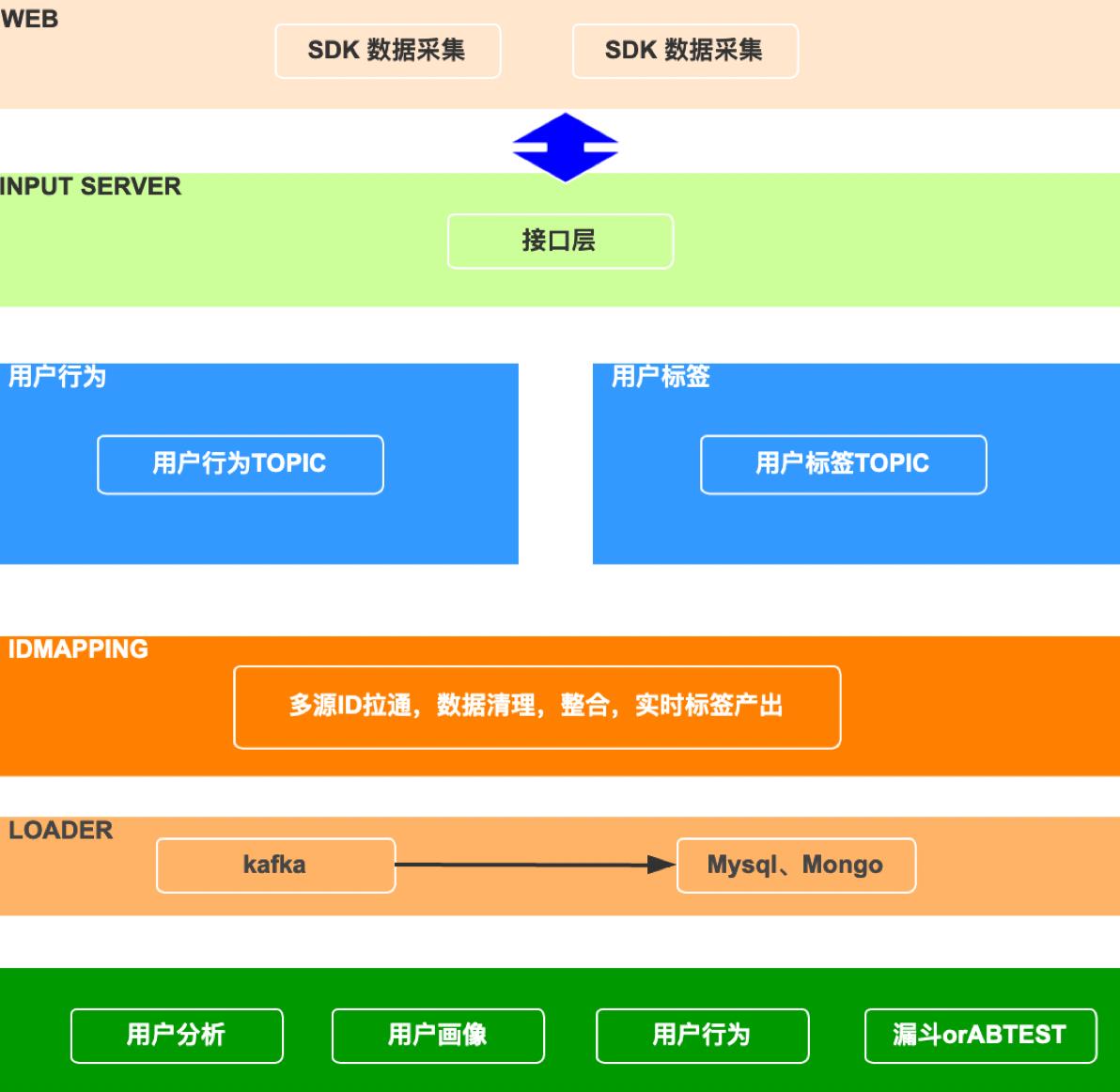
只面向一个数据量不大(日1w以内)一个简单的架构图
3.2、用户数据采集
业界厂商都会提供他们自己的SDK程序,集成到自己的程序中,实现用户及行为数据的自动采集,现在实现自己的小产品就需要自己开发,对于网页来说,JS SDK 是运行于网页的一段 javascript 代码,会在网站用户加载网页后自动启动,并收集用户的行为数据。包括数据来源,动作坐标,操作内容,请求数据,操作系统,屏幕分辨率,访问来源,用户唯一标识 ID,访问唯一标识 ID,访问时间、页面标题等。尽可能的多搜集,这里我们不具体研究SDK如何生成,对于前端开发的小伙伴来说,这些都是小事儿。
3.3、IDMAPPING的设计
对于ID拉通来说,厘清业务场景的非常重要,ID包括有,手机号、身份证号、faceID、设备id、账号Id、IMEI,openID等等,对于复杂的业务场景,他们的ID关系都是多对多的,如何拉通这些ID就成为了难点。高级的ID拉通可利用线性回归预测id关系,利用数据分析中的高级算法实现id拉通,实现用户ID图。对于很多小型业务场景来说,没有必要去高一个很重的工程来计算他的Id。
现在来设计一个简单的IDMAPPING 设计方法,这套方法也在实践中证明比较有效。一个典型的场景是APP端与服务端的关联,或者是APP登陆前后的关联,有一个用户打开网页浏览产品、查看详情、登陆账号、收藏、加入购物车、购买产品,下面介绍一下如何用idMapping来解决拉通互用行为,从“浏览"到”购买“的转化率解决运营分析的需求。
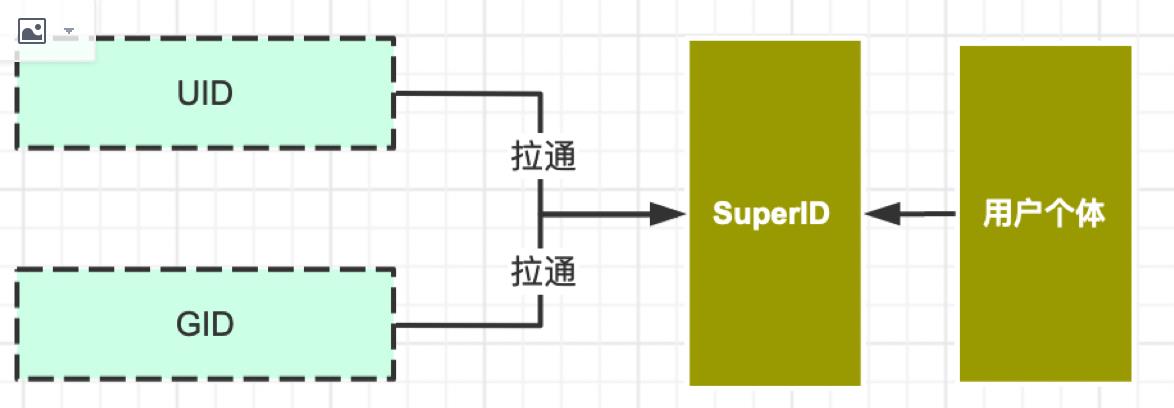
这个例子中我门用到的id为账号ID和设备ID,我们简称uid和gid,gid为设备id,每条源数据都应该有这个id,生成策略暂不讲解,通过ID关联,产出这两个ID的关联关系。
小李->第一次用公司电脑浏览页面查看的A产品的,得到了gid。
superId = gid1
set gid1->superId
->看到了某款产品不错,登陆账号加入购物车,登陆的时候得到了gid和uid
superId = get gid1
set uid1->superId
这样可以为每条数据添加到superId,以superId来分析用户行为。
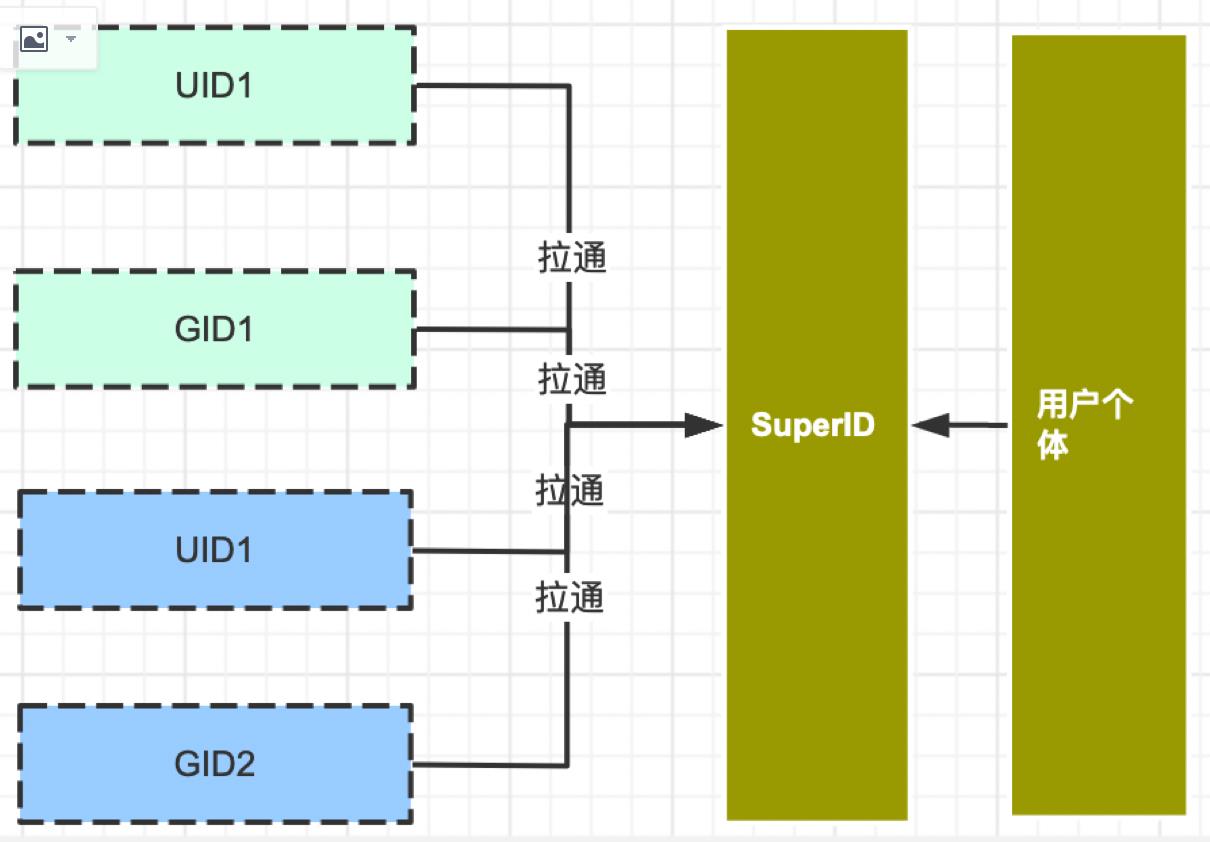
当然这只是一个简单的场景,一般情况下还会出现多设备,以及多用户单设备的情况,也会涉及到ID移主(superId的跟新),这个时候我们需要配饰id的配置属性,比如是否单例,id之间的优先关系。比我我们配置了uid为单例(uid与superID只存在1:1的关系),切uid的优先级最大。
接着上面的案例,小李回家后用自己电脑登陆了账号看自己的产品,当然刚开始他也没有登陆(gid2)
superId = if get gid2 == null ?gid2 : get gid2
set gid2 -> superId
登陆账号后(uid,gid2)
superId = if get uid1 == null ?uid : get uid
set uid -> superId
set gid2 -> superId (ID做出了更新操作)
最终我们得到了一种ID映射关系表
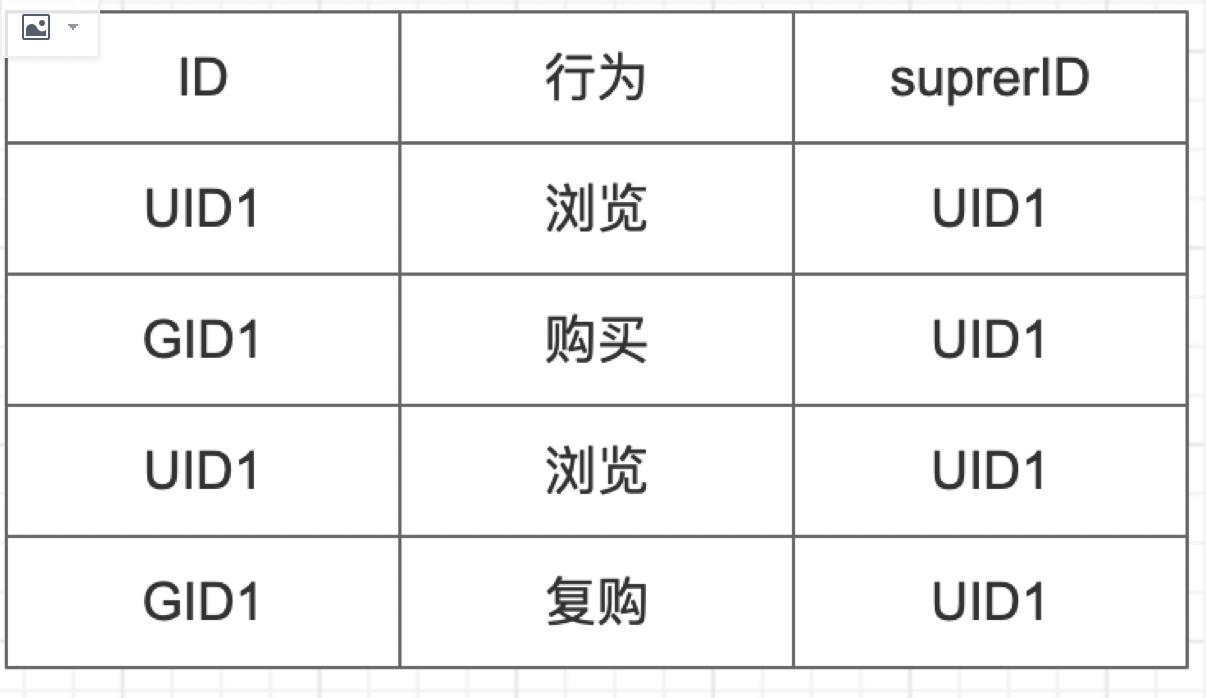
这歌时候我们使用原始ID的其中一个作为superId,后续我们也可以自己设计Id生成逻辑,避免后续的数据倾斜。
4、系统技术选型
4.1、使用的 Key-Value 数据库
1、存储IDMAPPING关系,看用户量选择技术,用户量少的话使用Redis完全可以(完全当作数据存储),如果Id数量很大,我们可以使用Redis+Hbase或者Pegasus。
4.2、使用KAFKA当作数据缓存
4.3、流式数据处理
1、使用flink或者spark,消费用户数据生成Id关系及数据清理,注意使用大数据技术要考虑并非处理,在处理Id关系的时候要记得加锁,保证Id映射的一致性。数据量小的话我们完全可以脱离这些大数据框架,完全有java Or python来简单的处理这些数据。
2、处理结果落地,为了保证不影响前端的数据处理流程速度,在处理及落地之间加入消息队列,将数据load到mysql Or ES OR Mongo OR CK,着就看数据量和业务需求了
5、基于ID关系产出用户标签
1、用户标签可以分为:用户属性标签,用户行为标签,比如:地理位置(属性标签)、近一年是否有购买产品(行为标签)等。
同样也可以分为实时标签和离线标签,有效标签和无效标签,比如:近三分钟时候有登陆(实时标签),近三分钟涉及到了时效性,所以有了有效标签和无效标签的区别。

TAG可以配置自己的属性(有效时间,创建时间、标签英文名等)
2、对于标签的产出我们可以算用的技术有kudu和hbase,用着用非关系型数据库来存储用户标签,后续也可以LOAD入ES OR CK。为需求提供支持。
6、总结
这些只是一个简单的逻辑想法,希望可以帮到大家,当然在各个厂商里有更好的技术和方法也是值得我们去学习,去进步。下面用最简单的java实现了这些功能,感兴趣可以瞅瞅。
码云地址:https://gitee.com/liyong9177/deepuser
给一个start吧
以上是关于基于ID_MAPPING(ID拉通)实现多源用户整合及行为数据采集的主要内容,如果未能解决你的问题,请参考以下文章
基于ID_MAPPING(ID拉通)实现多源用户整合及行为数据采集
基于ID_MAPPING(ID拉通)实现多源用户整合及行为数据采集