Python爬虫实战——从大师网站自动下载项目图片
Posted 不加班的程序员丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫实战——从大师网站自动下载项目图片相关的知识,希望对你有一定的参考价值。
然而这年头各个大师们的事务所网站大家都懂得,各种高冷或者炫酷的动画效果让人一次只能看一张图,要想更高效率的看图或者下载到高清大图就更加麻烦了。
那么身为新时代的设计师,有没有简单高效的方式来搞定这一切吗?
有!答案就是Python爬虫。
我们今天以著名结构建筑两栖大师卡拉特拉瓦的个人网站为例。简单介绍下怎样用Python爬虫高效获取大师的高清作品集
密尔沃基美术馆
用爬虫获取大师的作品集,其实原理上跟浏览网页一样,都是先打开项目的页面,点开高清大图,然后保存图片,只不过python爬虫的速度很快而已。
因为是爬取图片,所以本次爬虫没有使用Selenium,而是选择了纯代码的方式,这样可以省下浏览器打开图片渲染页面的时间消耗。
整个爬虫分为四个步骤:
-
访问网站
-
找到有哪些项目,以及项目的详细介绍的网页
-
在项目详细介绍的网页找到高清大图的地址
-
下载图片
在最开始我们可以用任意一款python编辑器,新建一个空的.py的文件。然后在最开头的地方加入我们需要用到的程序包,本次爬虫用了Beautifulsoup包,如果没有安装可以按以下方法安装。
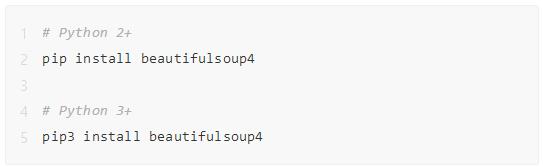
Beautifulsoup包安装方法,强烈推荐使用Anaconda,这些常用包都是默认配置好的。

1.我们需要访问到大师网站。
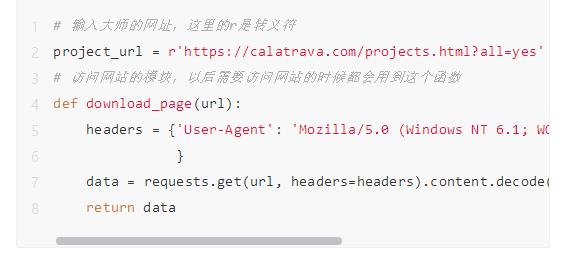
2.找到有哪些项目,以及项目的详细介绍的网址
我们可以通过F12调出浏览器的开发者工具,看看这个网页到底是怎么构成的。我们可以看到所有的项目信息都在一个<div>打头的大标签里。在这个标签中,每个项目又分别对应了一个<li>的标签,li标签的class名是odd或者even。利用Beautifulsoup的find_all方法,我们就可以拆分出这个页面中出现的每个项目的网页信息,而项目的详细地址

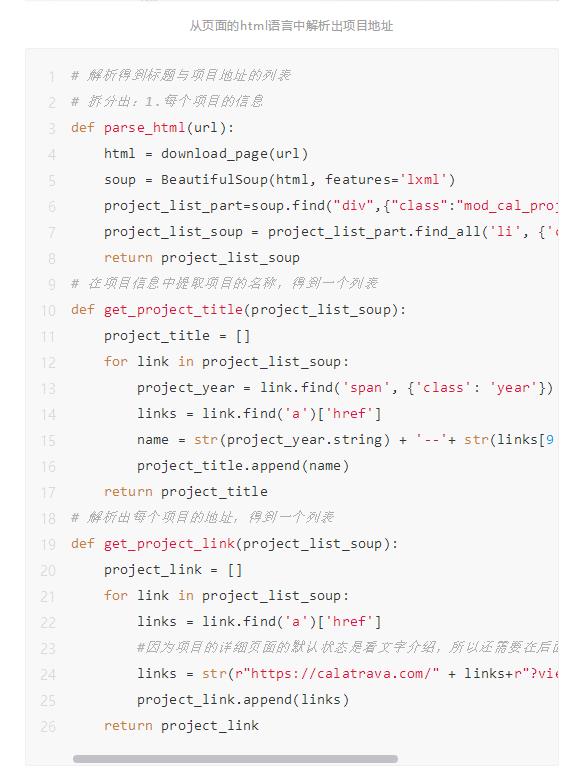
3.我们需要在项目详细介绍的网页找到高清大图的地址。
我们依然按F12进入浏览器的开发者模式,进入Network标签页,找到项目的大图的实际地址。再通过大图的实际地址转到element标签页中进行查找,这样我们可以解析出隐藏在翻页动画背后的高清大图的存储结构。
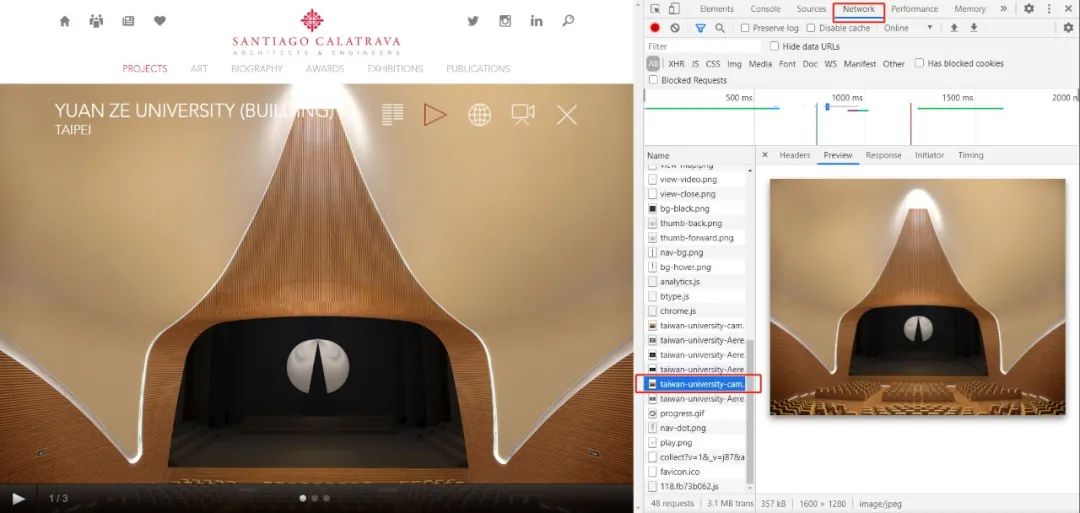
在开发者模式的network标签页中找到高清大图的位置
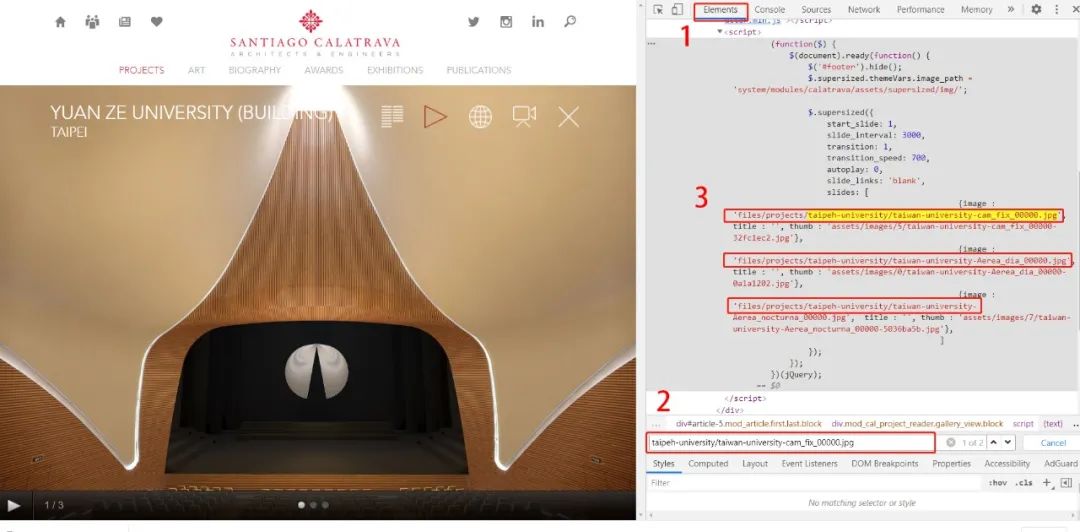
用找到的高清大图的名称,回到element标签页中Ctrl+F查找这个名称
至此我们可以发现页面的动画效果是通过一个javascript代码实现的,而每个项目的大图都是结构化的存储在这段json对象中,那我们直接用正则表达式提取出来就好了。

4.最后保存图片即可
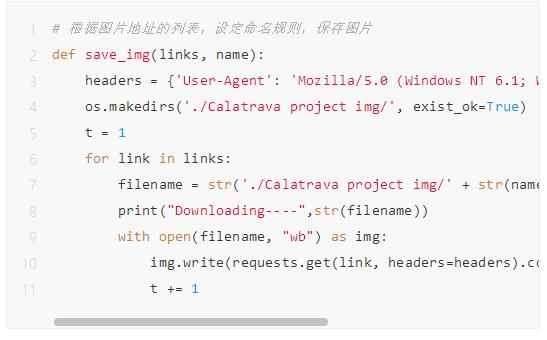
至此我们每一个步骤的方法都写完了,最后的最后组装成一个main函数运行就可以搓手收图了。

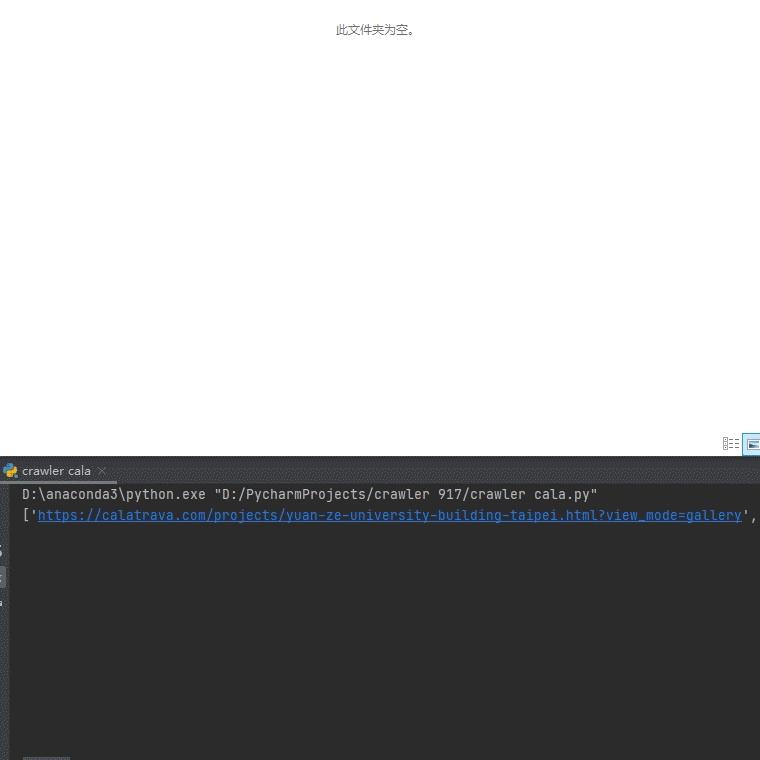
运行状态
卡拉特拉瓦的事务所网站一共90个项目,630张高清大图,就这样可以自动下好了。而且这个爬虫基本可以覆盖市面上95%以上的事务所网站的构架了,稍微改改地址之类的操作就可以一虫多用,是不是真香!需要相关爬虫资料的可以扫一扫备注【999】

以上是关于Python爬虫实战——从大师网站自动下载项目图片的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫实战,零基础初试爬虫下载图片(附源码和分析过程)
Python爬虫编程思想(91):项目实战--支持搜索功能的图片爬虫
Python爬虫编程思想(91):项目实战--支持搜索功能的图片爬虫