Python爬虫项目实战—全站 950 套美女写真套图爬虫下载
Posted 程序猿中的BUG
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫项目实战—全站 950 套美女写真套图爬虫下载相关的知识,希望对你有一定的参考价值。
目录
爬取网站 : http://www.mmjpg.com
写代码是一种艺术,来源于生活并且服务于生活
想要看妹子的图片怎么办,上网找阿,于是某度之

一看排名第一,来头不小,那就决定是你了
觉得不能只是走马观花地浏览,所以决定把整个网站的套图全都爬下来,以便以后慢慢品味
配上一杯咖啡以及网易云一个电音歌单,经过指尖的一阵阵翻云覆雨之后,代码算是写好了。测试好,没问题,走你!
不知不觉中,套图已全部爬取完成
全站 950 套图片,共 3.86 G
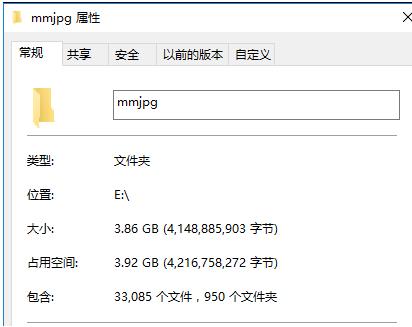
爬虫使用多进程,学校 8M 的网速基本满速
图片违规
源码
import os
import time
import threading
from multiprocessing import Pool, cpu_count
import requests
from bs4 import BeautifulSoup
HEADERS = {
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 '
'(Khtml, like Gecko) Chrome/56.0.2924.87 Safari/537.36',
'Referer': "http://www.mmjpg.com"
}
DIR_PATH = r"E:\\mmjpg" # 下载图片保存路径
def save_pic(pic_src, pic_cnt):
"""
将图片下载到本地文件夹
"""
try:
img = requests.get(pic_src, headers=HEADERS, timeout=10)
img_name = "pic_cnt_{}.jpg".format(pic_cnt + 1)
with open(img_name, 'ab') as f:
f.write(img.content)
print(img_name)
except Exception as e:
print(e)
def make_dir(folder_name):
"""
新建套图文件夹并切换到该目录下
"""
path = os.path.join(DIR_PATH, folder_name)
# 如果目录已经存在就不用再次爬取了,去重,提高效率。存在返回 False,否则反之
if not os.path.exists(path):
os.makedirs(path)
print(path)
os.chdir(path)
return True
print("Folder has existed!")
return False
def delete_empty_dir(save_dir):
"""
如果程序半路中断的话,可能存在已经新建好文件夹但是仍没有下载的图片的
情况但此时文件夹已经存在所以会忽略该套图的下载,此时要删除空文件夹
"""
if os.path.exists(save_dir):
if os.path.isdir(save_dir):
for d in os.listdir(save_dir):
path = os.path.join(save_dir, d) # 组装下一级地址
if os.path.isdir(path):
delete_empty_dir(path) # 递归删除空文件夹
if not os.listdir(save_dir):
os.rmdir(save_dir)
print("remove the empty dir: {}".format(save_dir))
else:
print("Please start your performance!") # 请开始你的表演
lock = threading.Lock() # 全局资源锁
def urls_crawler(url):
"""
爬虫入口,主要爬取操作
"""
try:
r = requests.get(url, headers=HEADERS, timeout=10).text
# 套图名,也作为文件夹名
folder_name = BeautifulSoup(r, 'lxml').find(
'h2').text.encode('ISO-8859-1').decode('utf-8')
with lock:
if make_dir(folder_name):
# 套图张数
max_count = BeautifulSoup(r, 'lxml').find(
'div', class_='page').find_all('a')[-2].get_text()
# 套图页面
page_urls = [url + "/" + str(i) for i in
range(1, int(max_count) + 1)]
# 图片地址
img_urls = []
for index, page_url in enumerate(page_urls):
result = requests.get(
page_url, headers=HEADERS, timeout=10).text
# 最后一张图片没有a标签直接就是img所以分开解析
if index + 1 < len(page_urls):
img_url = BeautifulSoup(result, 'lxml').find(
'div', class_='content').find('a').img['src']
img_urls.append(img_url)
else:
img_url = BeautifulSoup(result, 'lxml').find(
'div', class_='content').find('img')['src']
img_urls.append(img_url)
for cnt, url in enumerate(img_urls):
save_pic(url, cnt)
except Exception as e:
print(e)
if __name__ == "__main__":
urls = ['http://mmjpg.com/mm/{cnt}'.format(cnt=cnt)
for cnt in range(1, 953)]
pool = Pool(processes=cpu_count())
try:
delete_empty_dir(DIR_PATH)
pool.map(urls_crawler, urls)
except Exception:
time.sleep(30)
delete_empty_dir(DIR_PATH)
pool.map(urls_crawler, urls)代码整理:
import os
import json
def file_name(file_dir):
for root, dirs, files in os.walk(file_dir):
for file in files:
yield file
def gen_json(paths):
d = [{"imgSrc": path} for path in paths]
with open("yummy.json", "w+") as f:
json.dump(d, f)
if __name__ == "__main__":
gen_json(file_name('yummy'))源码太多啦,想要获取完整的源码可以戳这里
或者+qq群聊 :222020937【既能学习也能接单,而且资料及视频代码也准备好了】 欢迎加入

以上是关于Python爬虫项目实战—全站 950 套美女写真套图爬虫下载的主要内容,如果未能解决你的问题,请参考以下文章