何为计算机视觉?计算机视觉与数字图像处理的区别Opencv的起源。
Posted 17岁boy想当攻城狮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了何为计算机视觉?计算机视觉与数字图像处理的区别Opencv的起源。相关的知识,希望对你有一定的参考价值。
目录
6.Opencv库组成体系(取自:学习Opencv图1-5)
四、什么是数字图像处理?它和计算机视觉的区别在哪儿?以及什么是图像分析?
1.Opencv第一个windows版本是2000年6月推出的,“OpenCV alpha 3”同年12月发布在Linux平台下!
3.Opencv是属于Intel公司的一个开源项目(IPP不开源),
4.Opencv目前可以运用在制造业、机器学习、生物识别、检验、文档分析、医疗诊断、和军事等领域等各种智能/自主应用方面,应用范围非常广泛!
5.Opencv源代码是C/C++编写的,如果想要调用IPP库加速内部函数代码需要购买!
6.Opencv库可以在Windows、Linux、Mac平台下运行,并为python,Ruby,MATLAB等流行编程语言提供接口
7.opencv是由cv(图像处理和视觉算法),mll(统计分类器),highgui(GUI/图像和视频输入/输出),cxcore(基本结构和算法,xml支持,绘图函数),五大模块组成!
10.图像序列是就是一组图像(或者拍摄时的图像)的先后顺序!
13.实时分析就是对输入设备里的数据进行实施动作分析,而非实时分析就是对一组有序存储于本地存储器上的图片进行动作分析!
14.想要真正实现一个完全人工智能视觉产品是很复杂的,其中要考虑到很多复杂因素!
15.数字图像处理,即数字,将图像转化为数字的形式,对图像做处理,即将图像转化成计算机可识别的二进制数据文件,文件里的数据以像素点位单位,针对像素点进行算法处理。
17.图像处理是使用输入和输出图像内容的,即对输入图像的内容做处理,列如将一个RGB图像裁剪一半,就是把一幅图像的数字信息的一半给删除掉,并输出到屏幕上或输出到存储器的其它位置保存起来!
19.图像分析是对一幅图像进行分析,比如:运动分析,图像质量分析,噪声分析,目标分析!
概述
在学习任何一门新的语言或者框架时都应该了解这个行业的背景知识,正所谓工欲善其事,必先利其器!
一、 什么是计算机视觉?
在说Opencv之前要说一下什么是计算机视觉,计算机视觉是在图像基础上发展起来的一门新兴学科,计算机视觉是研究让机器如何看世界,认识这个五彩缤纷的世界,就是让摄像头代替人眼来对目标进行识别,跟踪和测量,并进一步对捕获的图像数据(视频数据)转换成一种新的表达方式或者一个新的决策的过程!在转换过程中进行的转换都是为了达到某一目标。
举个列子:通过输入设备(摄像头、扫描仪)将前方1米处发现的物体输入到电脑中,并对这些数据进行处理,然后与数据库里的模型比对,那么最后得到的决策可能是前方有一辆汽车或者站着一个人,处理的过程可能是把彩色图像转换成单通道的灰色图(灰色图要比彩色图容易处理后面会说为什么),对图像降噪声,或者通过图像序列分析去除摄像机晃动的影响,这些转换过程/处理过程最终将会转换成一种新的决策,表达方式!
这里稍微补充一下什么是图像序列分析,这里说的图像序列分析和图像序列不同!
图像序列是就是一组图像(或者拍摄时的图像)的先后顺序!
图像序列分析利用计算机视觉技术从一组图像序列中检测运动及运动物体并对其进行运动分析、跟踪或识别。图像序列分析在国民经济和军事领域的许多方面有着广泛的应用。
随着计算机视觉的诞生,人工智能技术也随着和诞生,其中人工智能技术中生物识别技术能从计算机处理的图像数据(多维数据)中获取信息,并对这个信息进行识别,并做相应的处理,人工智能领域下有很多技术比如最著名的机器学习等等这里就不做太多的详细介绍,后面学到机器学习时会和大家详细介绍人工智能技术下各个领域作用!
因为计算机视觉是计算机学科所以在、工程、信号处理、物理学、应用数学和统计学、神经生理学和认知科学等都有研究方面,在制造业、检验、文档分析、医疗诊断、和军事等领域等各种智能/自主应用方面,都有非常广阔的前景发展!
二、计算机视觉实现起来难吗?
人类本身是视觉动物,所以觉得人类觉得可以很容易实现计算机视觉,假如说让你从一个场景中找到一辆汽车,显然很容易,因为汽车本身较大,容易被眼睛所捕获,但是其中在捕获的过程中有着很复杂的过程:
人脑将视觉信号划分入很多个通道,将各种不同的信息输入你的大脑。你的大脑有一个关注系统,会根据任务识别出场景的重要部分,并做重点分析,而其他部分则分析的较少。在人类视觉流中存在着大量的反馈,但是目前人类对之了解甚少,肌肉控制的传感器以及其他所有传感器的输入信息之间存在着广泛的关联,这使得大脑可以依赖从出生以来所学到的信息,大脑中的反馈在信息处理的各个阶段都存在,在眼睛(传感器)中也存在。在眼睛中反馈来调节通过瞳孔的进光量,以及调节视网膜表面上的接受单元!
所以我们要想真正的实现一个人工智能产品的话就要把人类自己本身的所有信息模拟到计算机上,比如大脑=CPU,眼睛=摄像头,感官=传感器,并且要让之间协调工作,相对来说是非常复杂的!
其次计算机接受到的数据主要来源于摄像头,磁盘文件中的数值矩阵!
图1.1(取之“学习Opencv“)中的汽车有一个反光镜但是计算机只看到一组数值矩阵:

由于该图是单通道(黑白图)所以一个矩阵数值就可以表示一个像素点,如果是多通道的RGB颜色就需要三个数值表示,比如194 210 201表示一个像素点,而单通道194就可以表示像素点!
其中非常令人头疼的问题就是图像噪声
左:正常图片右:带图像噪声的图片

如果一张图里每个像素点上都掺杂着图像噪声的话会降低图像识别的准确率
图像噪声产生的问题主要来自输入设备(摄像机),造成摄像机产生图像噪声的几种原因如下:
1. 外部噪声:
即指系统外部干扰以电磁波或经电源串进系统内部而引起的噪声。如电气设备,天体放电现象等引起的噪声。
2.内部噪声(分为四种):
(1)由光和电的基本性质所引起的噪声。如电流的产生是由电子或空穴粒子的集合,定向运动所形成。因这些粒子运动的随机性而形成的散粒噪声;导体中自由电子的无规则热运动所形成的热噪声;根据光的粒子性,图像是由光量子所传输,而光量子密度随时间和空间变化所形成的光量子噪声等。
(2)电器的机械运动产生的噪声。如各种接头因抖动引起电流变化所产生的噪声;磁头、磁带等抖动或一起的抖动等。
(3)器材材料本身引起的噪声。如正片和负片的表面颗粒性和磁带磁盘表面缺陷所产生的噪声。随着材料科学的发展,这些噪声有望不断减少,但在目前来讲,还是不可避免的。
(4)系统内部设备电路所引起的噪声。如电源引入的交流噪声;偏转系统和箝位电路所引起的噪声等。
3.网络噪声
这个只是简单提一下一般的单机视觉开发一般用不到:网络噪声就是在通过UDP传输图像数据时因为网络不稳定造成传输时出现丢包的现象,导致传输过去的矩阵数值与原数值不一样,导致每个像素点上的值出现损坏的情况,每个像素点上就出现很多白色小斑点的图状物就叫图像噪声!
TCP不会出现图像噪声的问题,因为TCP为了确保数据的准确性,有重发机制,这里不做详细介绍,想详细了解可以在我的分栏里“网络层原理”这一栏中找到关于对TCP详细介绍的文章!
如果一个视觉系统里没有模式识别系统,自动控制的对焦和光圈,没有多年来的经验累计的视觉系统通常属于很低级的视觉系统!
4.根据特征切割场景
除了噪声以外还有许多其他阻挡计算机视觉处理的难题,列如场景物体的干扰,在三维场景中重建二维图
场景物体的干扰:
假如我们要做一个能够自动把房间里掉地上的书捡起来放到书架上,那么我们需要从这个房间场景中找出我们所需要的目标物品:书。
假如说这个人的房间非常大或者在客厅,那么时首先如果从右到左或者从左到右采用地毯式的搜索的话会需要进行大量的分析算法同时因为CPU/ALT运算单元会进行过多的算法运算一直处于高电平状态。
会加快消耗机器人的电能,在这样的情况下我们可以告诉机器人书一般会在某个地方出现:书柜、桌子、床上,沙发的周边地区。
然后将这三个模型导入到捡书机器人的比对数据库里,首先一点是在拍摄这些配对模型时,要将物品放到最能表现其特征的地方:“正中心位置”。
为了让捡书机器人在比对模型时准确率更高可以为其比对模型添加一些隐含的变量:大小,重力方向以及其他变量,然后在比对时将捕获的床或者沙发进行分析推断出物品体积并通过机器学习技术不停的根据上下文解释信息进行建模训练,校正变量,让其准确率更高!
(这里说一下重力方向:给予重力方向的优点是可以通过目标物体的重力方向推断出该物体会在那个位置出现,这样在一个非常大的宫殿里寻找一张床,有了这张床的重力方向,可以以自身为中心并根据床的重力方向推断出大概会在那个方位!)
有了这些信息之后那么机器人可以很快的过滤掉场景中书籍不可能会掉落的地方,那么机器人可以很快的找出书籍并放到书架上!当然你也可以给机器人安装激光扫描仪使其捕获的物品体积使其在机器训练时用捕获的数据与模型数据进行校正时更加准确!
并且捡书机器人上的摄像机并非属于固定摄像机,固定摄像机对场景约束较多,但是可以通过这些约束简化问题,但是移动摄像机需要不停的变更场景,所以移动摄像机的场景约束较少,需要做更多的简化工作!
重建二维图
就像上面说的,要从一个房间里找到书可以根据特征来寻找加快寻找时间,那么在找到一个目标时首先要将这个目标转换成二维图,也就是说三维图是立体的,存在前后之分,而二维图不存在前后之分,只有宽高,为什么要转换成二维图?可以想一下图1是三维图图二是二维图(图像来源:http://www.opencv.org.cn/opencvdoc/2.3.2/html/doc/tutorials/features2d/feature_homography/feature_homography.html)这一部分不必管是如何实现的!
二维图的方法就是从一个三维图(立体)中根据二维特征(平面)将二维数据提取出来并映射到另外一个图像数据上!
可以可看到二维图可以更好的方便识别所需表面特征!
1. opencv还可以很好的修复图像中的畸变
下图列子展示了图像畸变和畸变后校正的图像(转自:http://www.cnblogs.com/Lemon-Li/p/3283059.html)
图一畸变图像

图像空间畸变图:

图二opencv畸变校正后的图像


现在先不管是如何利用opencv修复的,到后面的文章会慢慢和大家讲解!
图像畸变会给人一种凹凸的感觉,所以在视觉上看起来并不是特别美观!
三. Opencv发展历程
1.起源
早期在做图像处理时所需要的算法运算量是非常大的,所以那个时候在对图像做基础处理都要耗费很长的时间,正因如此1996年时lntel发布奔腾处理器时同时发布MMX指令集“看过我那篇“深度理解指令集”的朋友应该都对这个指令集有所了解“,MMX(后来的SSE)这种单指令多数据的多媒体指令集在运算时运算速度要比平常的图像算法快上几倍甚至几十倍,这才把图像处理从慢车道推向了快车道!
如果想深度了解MMX指令集的发展史可以去看我这篇“深度理解“指令集”的最后一段!
可是如果想要使用MMX(SSE)指令集的话必须会汇编语言才行,所以基于汇编的算法开发和优化需要耗费时间比较长。
所以后来Intel基于MMX(SSE)指令集推出了IPL库,IPL是基于MMX指令集,后来因为MMX指令集的缺陷推出SSE指令集同时推出封装SSE指令集的IPP库,换句话说IPP库就是基于IPL库的!
MMX(SSE)指令集里包含的大多都是对图像处理的基础函数,在对图像进行复杂处理时短时间里比较难以实现,而且MMX(SSE)指令集是非开源的,在那个年代追求效率的企业都希望既能开发出性能优越的视觉系统,提高开发效率,降低开发成本,所以后来1999年Intenl启动CLV项目主要目标是人机界面,能被UI调用的实时计算机视觉库,为Intel处理器做了特定优化。
后来2000年6月正式发布的第一个在Windows平台下第一个Opencv开源版本“OpenCV alpha 3”同年12月发布在Linux平台下“OpenCV beta 1”开源版本。
Opencv不仅开源免费,内部对图像处理的函数非常丰富,内部函数的实现一般都使用IPP库做优化,同上其实Opencv并不是完全开源,因为IPP库是非开源的,所以内部使用IPP做优化的函数属于非开源没有使用IPP做优化的属于开源,可以说Opencv属于半开源的项目!
2.可移植性
Opencv采用C/C++编写在不同的系统环境上只要稍微修改一下代码就可以编译通过,可以在Mac/Linux/Windows系统上运行,并且为python,Ruby,MATLAB等编程语言提供接口!
3.运行效率
Opencv在设计时的目标就是执行速度尽量快所以内部函数都是标C函数来编写的,如果想要起到硬件加速(内部函数用IPP优化)需要购买IPP库,购买IPP库后Opencv在运行时会自动调用IPP库做优化!
4.应用领域
目前Opencv应用领域非常广泛,在医疗设备、工厂检验、立体视觉、机器学习、人脸别识别、图像拼接、生物医学分析、无人机、等人工智能领域有广泛应用!
甚至计算机视觉可以用在声谱图上,对声音和音乐进行分析!
并且计算机视觉被广泛应用于工厂检验,大规模的产品制造在流水线上的某一环节都使用计算机视觉做检测!
5.Opencv目标
Opencv的目标是为解决计算机视觉提供基本工具,当然在有些情况下,Opencv还提供了许多高层函数用于解决复杂式图像处理,当然如果没有这些高层函数也完全可以基于Opencv提供的基础函数上建立一个完整的解决方案,在用Opencv建立一个解决方案时,尽管这个解决方案不是特别完美,但是有了第一个解决方案之后,便会从这个解决方案中找到许多不足的地方,但是可以基于这个解决方案之上来不停的对其优化整改,到一套完整的解决方案体系,虽然说很难达到十全十美但是达到十全九美就可以了,当然解决方案的不足也可以通过系统所使用的环境来解决,比如要识别出场景中这个人的身高,可以为计算机安装激光红外扫描仪来精准的捕获目标物体的身高并输入到计算机里更加方便的处理数据!
6.Opencv库组成体系(取自:学习Opencv图1-5)
这些体系可能与你当前使用的Opencv版本不同
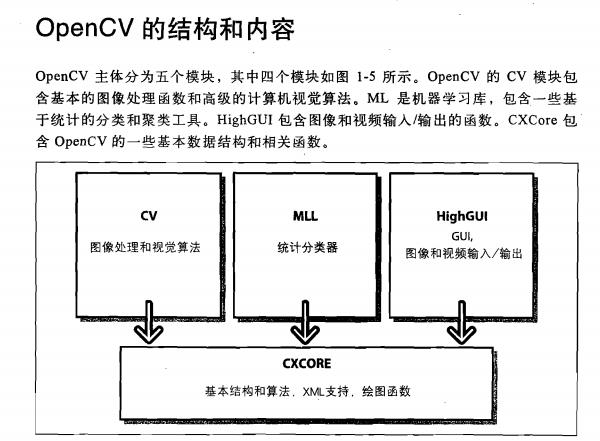
图中没用包含CvAux模块,因为该模块中一般包含一些即将淘汰的算法和函数(比如基于嵌入式隐马尔可夫模型的人脸识别等等),所以如果突然有一天你发现你要使用的基于某个算法写出来的函数不见了,可以到这个模块里或许能找到!
7. 版权
Opencv开源协议允许你使用Opencv库的全部代码,生成商业产品,并且不需要公开源代码,或对Opencv库中的算法改善后的算法!
8.预备
在学习Opencv之前要懂得C/C++编程,和一些数学基础!
四、什么是数字图像处理?它和计算机视觉的区别在哪儿?以及什么是图像分析?
数字图像处理,即数字,将图像转化为数字的形式,对图像做处理,我们平时所见到的图像,在计算机中都是一组数字,当通过相机捕获现实世界的景物时,相机会捕获现实世界的光源信号,并转化为数字信号保存到存储器上,当显示时,GPU会根据这些数字信息,并控制LRT将其绘制到屏幕上,呈现出来!
一幅图像可以定义成一个二维空间函数,即s = f(x,y),s是二维空间,x和y是空间中的坐标,f是位于二维空间中x和y坐标处的灰度值(为什么说是灰度值?因为这里是用单字节表示,即单通道)!并且当x和y位于的s空间坐标处的f值是有限的离散数值(自然整数)时才可以称为数字图像!这里有限的大小是指固定的,为什么这么说?因为在计算机当中,是以字节作为基本单位来描述数据的,当把一幅图像转化成一组数据时,这组数据里的每个数组大小都是以一个字节作为基本单位存储到存储单元中的,上限值是一个字节的取值范围:2~8次方 = 256,并且每个数组对应着图像的各个颜色信息!
列如如下是一幅图像:

那么被转化成数字存储到计算机当中后的数据是这样的:

上面的每个值分别对应着图像的各个点,用于描述图像每个点上的颜色信息,当我们要显示这些数据时,计算机会把这组数据写入到显存里,由GPU根据显存数据将其显示到屏幕上(ps:这里补充一点,显存的存储方式是以矩阵存储的,分别对应显示器屏幕的每个点(3个值对应一个点),向每个点上写入数据,GPU就会控制LRT向屏幕的那个点放射RGB光线!),将这些颜色点打到屏幕的荧光粉处就会发出与图片对应的光,那么这些点聚合在一起之后就形成了一幅完整的图像!
这里说一点,如果是单通道的情况下,CPU会组合写入显存,列如上面这幅图像是单通道,CPU会将第一个元素写入到显存后另外两个值也会写入与该值一样的值,并且根据屏幕分辨率,写入对应范围的显存矩阵,具体请参考:RGB颜色空间、色调、饱和度、亮度、HSV颜色空间详解
操作系统是如何获取分辨率的?
答:显示器中自带一个小型flash(闪存,断电也能保存数据的小型存储器),这种存储器不大,只能存储分辨率和亮度对比度等信息,操作系统从中获取信息,并根据信息和内存中的显示数据根据获取到的信息按比例经过算法写入到显存矩阵中!
那么问题来了,当我们点击显示器的调节对比度亮度的按钮时是什么芯片在根据按键情况写入到flash中?
答:显示器中使用MCU单元,当我们按下某个按键时按键对应的寄存器上的值就会发生改变,MCU会将改变后的寄存器值写入到flash中,MCU会通过串口或其他连接方式连接到CPU主板上外设总线,并根据外设总线连接到显存上,可以直接写入显存数据,GPU是根据内部总线连接到外部总线获取显存数据的,当我们每次修改时MCU会以动画的形式将改变结果呈现到屏幕中,这一步不需要操作系统也可以进行,MCU会直接写入到显存当中,所以即使没有操作系统当我们修改分辨率对比度时也能看到改变时产生的与用户交互的界面,该界面是根据操作状态实时画出来的!

人类的眼睛仅能捕获电磁波谱的可见光波(通俗易懂的说就是太阳平时放射出来的电磁波(太阳辐射),或者是电子加速或电子与磁场交互产生的能源),但是一些不可见的光波人类是无法捕获的,列如:无线电波,超声波,计算机可以利用天线接收器,等产品捕获无线电波或超声波并根据电波频率将其成像出来!
什么是图像处理和计算机视觉?
图像处理:是使用输入和输出图像内容的,即对输入图像的内容做处理,列如将一个RGB图像裁剪一半,就是把一幅图像的数字信息的一半给删除掉,并输出到屏幕上或输出到存储器的其它位置保存起来!
计算机视觉:对图像进行识别!
但有时有的处理又不能算是图像处理,列如计算某个图像的灰度程度,这仅仅只是取出RGB三个值,并计算平均值,这样的处理太过于简单,甚至都没有对图像数据做任何处理!
还有一个是位于图像处理和计算机视觉中间的:图像分析!
图像分析:即对一幅图像进行分析,比如:运动分析,图像质量分析,噪声分析,目标分析!
图像识别分为三个等级:
假如说我们拿到了一张图像,要求是判断这个图像中有没有一只猫!

那么首先要考虑的是这张图像是否有噪声或者图像不清晰,图像质量较差的情况,为了解决这些问题应当先对其进行模糊平滑处理降低图像噪声,在对比度增强和锐度增强,让颜色更加鲜艳,图像更加清晰,这些算是预处理即初级处理!
那么当图像变得清晰可见时,我们就进行中级处理,从预处理后的图像中将特征提取出来,这里不是识别,只是将一幅图像中的带有轮廓边缘的物体(即RGB值比较凸出的一部分)裁剪减少目标信息,过滤掉一些可能影响后续识别的信息!这里是中级处理,特征提取!

最后在根据已经提取的特征进行识别,这里就是高级处理!
在最后当你识别完成之后已经将要识别出的物体存在于图像中二维空间的位置给标出来了,就可以对其进行图像识别,从图像中找到小猫

经过图像识别找到小猫,并加以分析!

总结 撒花
1.Opencv第一个windows版本是2000年6月推出的,“OpenCV alpha 3”同年12月发布在Linux平台下!
2.Opencv第一个开源版本是OpenCV beta 1
3.Opencv是属于Intel公司的一个开源项目(IPP不开源),
4.Opencv目前可以运用在制造业、机器学习、生物识别、检验、文档分析、医疗诊断、和军事等领域等各种智能/自主应用方面,应用范围非常广泛!
5.Opencv源代码是C/C++编写的,如果想要调用IPP库加速内部函数代码需要购买!
6.Opencv库可以在Windows、Linux、Mac平台下运行,并为python,Ruby,MATLAB等流行编程语言提供接口
7.opencv是由cv(图像处理和视觉算法),mll(统计分类器),highgui(GUI/图像和视频输入/输出),cxcore(基本结构和算法,xml支持,绘图函数),五大模块组成!
8.图像识别令人最头疼的地方是图像噪声,场景重塑
9.图像噪声产生原因由:外部噪声,内部噪声,还有网络噪声。
10.图像序列是就是一组图像(或者拍摄时的图像)的先后顺序!
11.图像序列分析是对一组已经排序好的图像进行运动分析!
12.图像分析分为两种:实时分析,非实时分析
13.实时分析就是对输入设备里的数据进行实施动作分析,而非实时分析就是对一组有序存储于本地存储器上的图片进行动作分析!
14.想要真正实现一个完全人工智能视觉产品是很复杂的,其中要考虑到很多复杂因素!
15.数字图像处理,即数字,将图像转化为数字的形式,对图像做处理,即将图像转化成计算机可识别的二进制数据文件,文件里的数据以像素点位单位,针对像素点进行算法处理。
17.图像处理是使用输入和输出图像内容的,即对输入图像的内容做处理,列如将一个RGB图像裁剪一半,就是把一幅图像的数字信息的一半给删除掉,并输出到屏幕上或输出到存储器的其它位置保存起来!
18.计算机视觉是对图像进行识别,让计算机看懂这个世界。
19.图像分析是对一幅图像进行分析,比如:运动分析,图像质量分析,噪声分析,目标分析!
以上是关于何为计算机视觉?计算机视觉与数字图像处理的区别Opencv的起源。的主要内容,如果未能解决你的问题,请参考以下文章