一篇文章搞定一个大数据组件:kudu知识点全集
Posted 明月十四桥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一篇文章搞定一个大数据组件:kudu知识点全集相关的知识,希望对你有一定的参考价值。
目录
1、kudu的定位
HDFS: 存储格式Textfile,Parquet,ORC,适合离线分析,不支持单条记录级别的update操作,随机读写性能差。
HBASE :可以进行高效随机读写,但写快读慢,大批量数据获取时的性能较差。并不适用于基于SQL的数据分析方向。
Kudu:
-
批量更新和单条记录更新都很友好 --FastData
-
与Impala组合使用,OLAP性能强大 --FastAnalytics
-
高可用
-
动态扩展
2、kudu基本概念
-
Table(表):一张table是数据存储在kudu的位置。Table具有schema和全局有序的primarykey(主键)。
-
Tablet(段):一个tablet是一张table连续的segment,与其他数据存储引擎或关系型数据的partition相似。Tablet存在副本机制,其中一个副本为leadertablet。任何副本都可以对读取进行服务,并且写入时需要在所有副本对应的tabletserver之间达成一致性。
-
Tabletserver:存储tablet和为tablet向client提供服务。对于给定的tablet,一个tabletserver充当leader,其他tabletserver充当该tablet的follower副本。只有leader服务写请求,leader与follower为每个服务提供读请求。
-
Master:主要用来管理元数据(元数据存储在只有一个tablet的catalogtable中),即tablet与表的基本信息,监听tserver的状态
-
CatalogTable: 元数据表,用来存储table(schema、locations、states)与tablet(现有的tablet列表,每个tablet及其副本所处tserver,tablet当前状态以及开始和结束键)的信息。
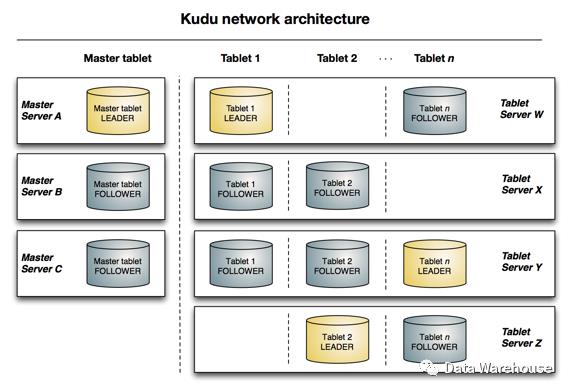
3、存储架构
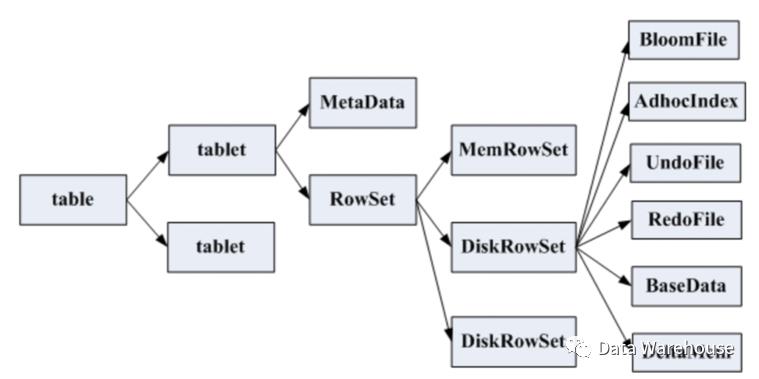
•MemRowSet
用于新数据insert及已在MemRowSet中的数据的更新,一个MemRowSet写满后会将数据刷到磁盘形成若干个DiskRowSet。(默认是1G或者或者120S)
•DiskRowSet
用于老数据的变更(mutation),后台定期对DiskRowSet做compaction,以删除没用的数据及合并历史数据,减少查询过程中的IO开销。
•BloomFile
根据一个DiskRowSet中的key生成一个bloomfilter,用于快速模糊定位某个key是否在DiskRowSet中存在。
•Ad_hocIndex
主键的索引,用于定位key在DiskRowSet中的具体哪个偏移位置。
•BaseData
MemRowSet flush下来的数据,按列存储,按主键有序。
•UndoFile
基于BaseData之前时间的历史数据,通过在BaseData上applyUndoFile中的记录,可以获得历史数据。
•RedoFile
基于BaseData之后时间的变更(mutation)记录,通过在BaseData上applyRedoFile中的记录,可获得较新的数据。
•DeltaMem
用于DiskRowSet中数据的变更mutation,先写到内存中,写满后flush到磁盘形成RedoFile。
3.1 储存架构:Tablet
| 分区策略 | Writes | Reads | Tablet Growth |
| Range | 所有写入都会落到最新分区 | 可以通过分区键提高读能力 | 可添加新tablets |
| Hash | 在tablets上均匀分布 | 可以通过分区键提高读能力 | tablets会无限增长 |
Hash分区有利于提高写吞吐量Range分区可避免tablet无限增长问题,所以我们可以使用多级分区,组合这两种分区方式
3.2 储存架构:RowSets
Tablet在底层被进一步细分成了一个称之为RowSets的单元
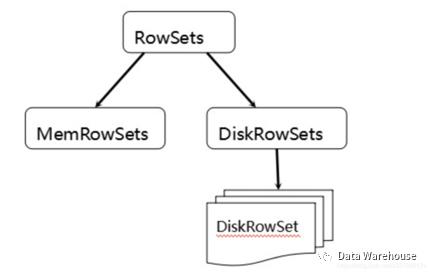
•MemRowSet
用于新数据insert及已在MemRowSet中的数据的更新,一个MemRowSet写满后会将数据刷到磁盘形成若干个DiskRowSet。(默认是1G或者或者120S)
•DiskRowSet
用于老数据的变更(mutation),后台定期对DiskRowSet做compaction,以删除没用的数据及合并历史数据,减少查询过程中的IO开销。
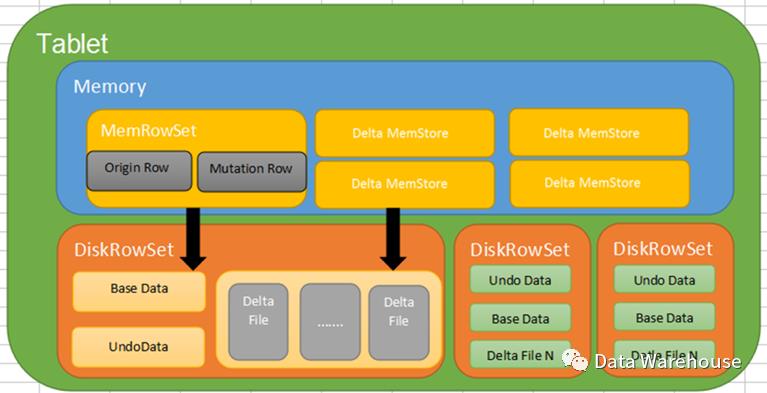
3.3 储存架构:DiskRowSets
DiskRowSet分为了两部分:basedata、deltastores。basedata 负责存储基础数据,deltastores负责存储 basedata 中的变更数据
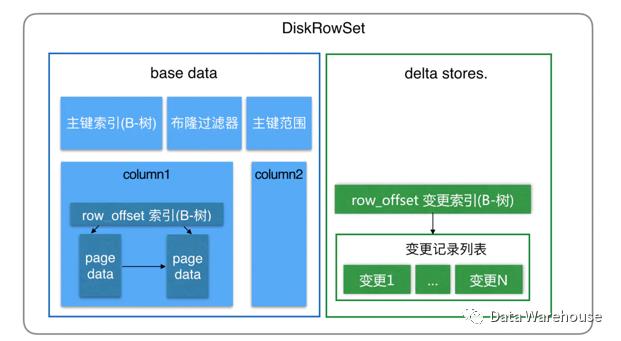
4、kudu工作原理
4.1 Compaction
由于所有插入的数据都是先写入memRowSet,到达一定条件后再写入DiskRowSet,而且DiskRowSet中的basedata是不变的,这就导致会出现数据重叠的现象,导致写或查询时需要搜索大量的DiskRowSet

三种Compaction策略:
DiskRowSet Compaction:减少DiskRowSet数量,优化insert、update和scans时间。
Minor Delta Compaction:只减少delta file数量,优化scans时间。
Major Delta Compaction:对base data和delta file进行compaction,优化scans时间
4.2 Tablet切分规则
建表时指定分区策略
Hash Partitioning:哈希分区通过哈希值将行分配到某一个bucket,每个bucket对应一个tablet,建表时设置bucket的数量。
Range Partitioning:range partition使用完全有序的分区键来分配行,分区键必须是kudu表主键的子集。
DEMO:
CREATE TABLE cust_behavior (
_id BIGINT PRIMARY KEY,
skuSTRING,
rating INT,
fulfilled_dateBIGINT
)
PARTITION BY RANGE(_id)
(
PARTITION VALUES< 1439560049342,
PARTITION1439560049342 <= VALUES < 1439566253755,
PARTITION1439566253755 <= VALUES < 1439572458168,
PARTITION1439572458168 <= VALUES < 1439578662581,
PARTITION1439578662581 <= VALUES < 1439584866994,
PARTITION1439584866994 <= VALUES < 1439591071407,
PARTITION1439591071407 <= VALUES
)
STORED AS KUDU;
4.3 kudu写过程:insert
Kudu与HBase不同,Kudu将写入操作分为两种:一种是插入新数据,另一种是更新数据
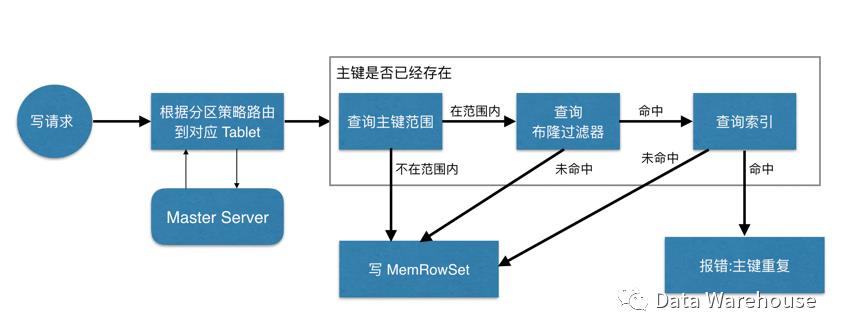
1、客户端连接Master获取表的相关信息,包括分区信息,表中所有tablet的信息;
2、客户端找到负责处理读写请求的tablet所负责维护的TServer。Kudu接受客户端的请求,检查请求是否符合要求(表结构);
3、Kudu在Tablet中的所有rowset(memrowset,diskrowset)中进行查找,看是否存在与待插入数据相同主键的数据,如果存在就返回错误,否则继续;
4、Kudu在MemRowset中写入一行新数据,在MemRowset数据达到一定大小时,MemRowset将数据落盘,并生成一个diskrowset用于持久化数据,还生成一个memrowset继续接收新数据的请求。
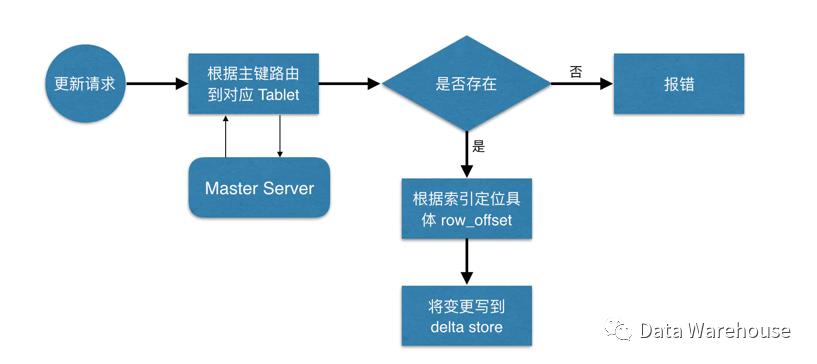
4.4 kudu写过程:update
4.5 Kudu读过程
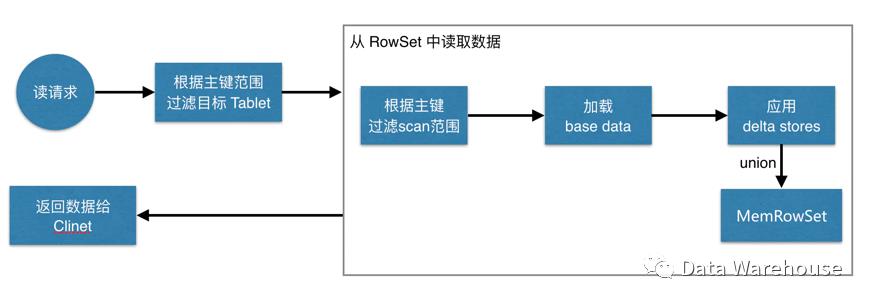
1、客户端连接Master获取表的相关信息,包括分区信息,表中所有tablet的信息;
2、客户端找到需要读取的数据的tablet所在的TServer,Kudu接受读请求,并记录timestamp信息,如果没有显式指定,那么表示使用当前时间;
3、Kudu找到待读数据的所有相关信息,当目标数据处于memrowset时,根据读取操作中包含的timestamp信息将该timestamp前提交的更新操作合并到base data中,这个更新操作记录在该行数据对应的mutation链表中;
4、当读取的目标数据位于diskrowset中,在所有DeltaFile中找到所有目标数据相关的UNDO record和REDO records,REDO records可能位于多个DeltaFile中,根据读操作中包含的timestamp信息判断是否需要将base data进行回滚或者利用REDO records将base data进行合并更新。
整理不易,一键三连可好。

以上是关于一篇文章搞定一个大数据组件:kudu知识点全集的主要内容,如果未能解决你的问题,请参考以下文章