python求音频的梅尔倒谱系数
Posted 宫水二叶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python求音频的梅尔倒谱系数相关的知识,希望对你有一定的参考价值。
文章目录
写在前面
唔

这次实验是对音频进行处理,求音频的梅尔倒谱系数,虽然上学期上过了多媒体课,早就学习过梅尔倒谱系数,傅里叶变换,DCT变换,可这次实验中遇到的时候脑海里还是一片空白。不禁想起一段话:“我蹲在菜市场里,农民伯伯从我身旁走过,只听他发自内心的感叹:真是好菜呀!”。希望大家平时学习的时候探究问题的根源,不要像我一样浅尝辄止,到头来只能感叹自己真是太菜了。
这次参考了好多篇大佬的博客,这里列举一下(代码基本来源于第一篇,我只不过加了一些解读):
python 计算MFCC详细步骤
论文笔记:语音情感识别(四)语音特征之声谱图,log梅尔谱,MFCC,deltas
梅尔倒谱系数特征(Mel-frequency cepstral coefficients,MFCC)
梅尔频率倒谱系数(MFCC) 学习笔记
如何决定要使用多少点来做FFT
详解离散余弦变换(DCT)
最后写一句我耳机里正在放的歌吧“我该怎样度过人生的旅途,孤独或者庸俗”
一、必备的关于音频的知识
想要看懂下面的实验,这些知识必不可少。
1.关于采样率
采样率即在一秒的音频时间里进行采样的次数,采样率为20k时即是一秒钟对音频进行20000次采样。
根据香农采样定理,想要完整地还原声音,采样率至少要为音频中最高频率的2倍。
人耳的可感知频率是20-20khz,因此为真实地还原音频,CD采用了40+kHz的采样率。
2.关于波形图,声谱图
(1)波形图:
又称振幅图,是音频的振幅(或能量)这个维度的图形表达。波形图的横坐标一般为时间,纵坐标一般为dB(即分贝)来表示。
Python 在读音频时,可以使用 librosa 模块或者 scipy 模块,两种读取代码如下:
代码如下(示例):
import librosa
import librosa.display
import matplotlib.pyplot as plt
data1 , sampling_rate1 = librosa.load('chew.wav', sr=22050)#采样率默认值是22050
from scipy.io import wavfile
sample_rate, signal = wavfile.read('chew.wav')
librosa模块得到波形图的代码如下:
#波形图
plt.figure()
librosa.display.waveplot(data1*32767, sr=sampling_rate1)
plt.show()
示例波形图如下:
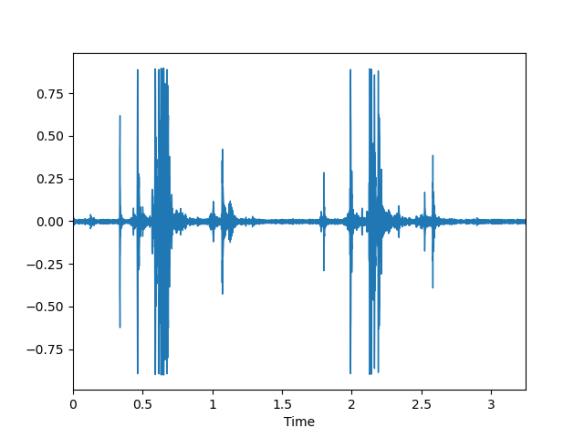
注意librosa模块读音频时进行了归一化处理,想要得到真实的振幅可以将信号乘于32767。
(2)声谱图:
声音信号是一维信号,直观上只能看到时域信息,不能看到频域信息。通过傅里叶变换(FT)可以变换到频域,但是丢失了时域信息,无法看到时频关系。声谱图是声音或其他信号的频率随时间变化时的频谱(spectrum)的一种直观表示。
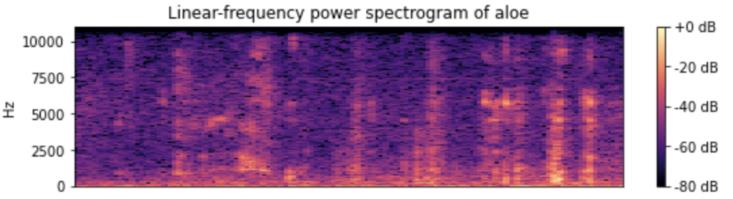
librosa模块得到声谱图的代码如下:
#声谱图
D = librosa.amplitude_to_db(np.abs(librosa.stft(data1)), ref=np.max)
librosa.display.specshow(D, y_axis='linear')
plt.colorbar(format = '%+2.0f dB')
plt.title('Linear-frequency power spectrogram of aloe')
plt.show()
示例声谱图如下:
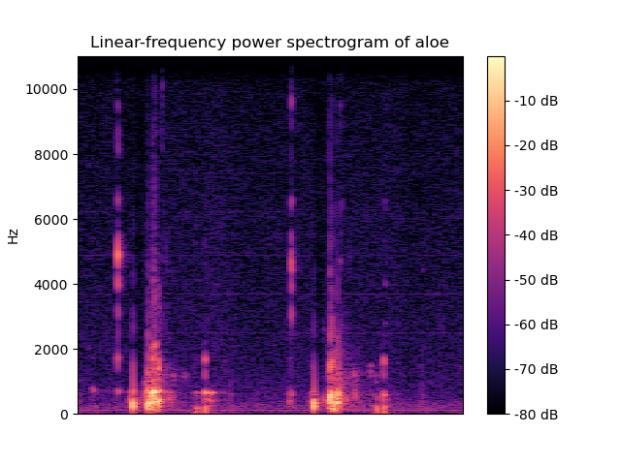
二、音频的梅尔倒谱系数的含义和求解步骤
1. 梅尔倒谱系数的含义
感知实验表明,人耳对于声音信号的感知聚焦于某一特定频率区域内,而非在整个频谱包络中。耳蜗的滤波作用是在对数频率尺度进行的,在1000Hz以下为线性,在1000Hz以上为对数,这就使得人耳对低频比高频更敏感。
心理物理学研究表明,人类对语音信号频率内容的感知遵循一种主观上定义的非线性尺度,该非线性标度可被称为“Mel”标度。
一般来说,声音的频率和人耳所听到的声音高低不成正比,而是与音调(人们为了描述声音高低而定义的概念)成正比,声音的频率分布与临界频带分布相一致。梅尔频率标度的单位是 Mel,它是为了描绘音调而被定义出来的,它更生动地反映出了频率和音调的非线性关系。
MFCC是将人耳的听觉感知特性和语音产生机制相结合,因此目前大多数语音识别系统广泛使用这种特征。对频率轴不均匀划分是MFCC特征区别于前面普通倒谱特征的最重要的特点,变换到Mel域后,Mel带通滤波器组的中心频率是按照Mel刻度均匀排列的。
语音的MFCC特征是基于人耳感知实验得到,将人耳当成特定的滤波器,只考虑某些特定频率成分。这些滤波器是在频域上不均匀分布的。更多的滤波器聚集于低频部分,高频部分的滤波器较少。
梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient, MFCC)考虑到了人类的听觉特征,先将线性频谱映射到基于听觉感知的Mel非线性频谱中,然后转换到倒谱上。
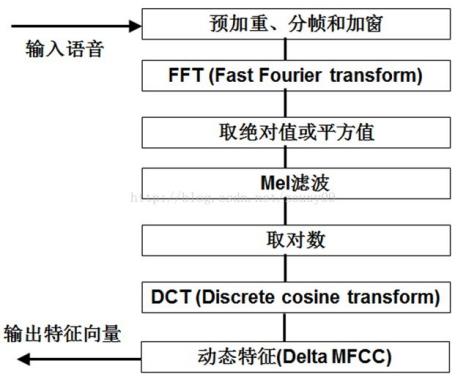
2. 梅尔倒谱系数的求解步骤概括
梅尔倒谱系数(MFCC)特征提取包含以下几个步骤:
1、对语音信号进行预加重、分帧和加窗处理;
2、用周期图(periodogram)法来进行功率谱(power spectrum)估计;(短时傅里叶变换)
3、对功率谱用Mel滤波器组进行滤波,计算每个滤波器里的能量;(梅尔频谱)
4、对每个滤波器的能量取log;(log梅尔频谱)
5、进行离散余弦变换(DCT)变换;(梅尔倒谱)
6、保留DCT的第2-13个系数,去掉其它。(MFCC特征)
三、求梅尔倒谱系数详细过程
1. 预加重、分帧和加窗处理
(1)读入音频
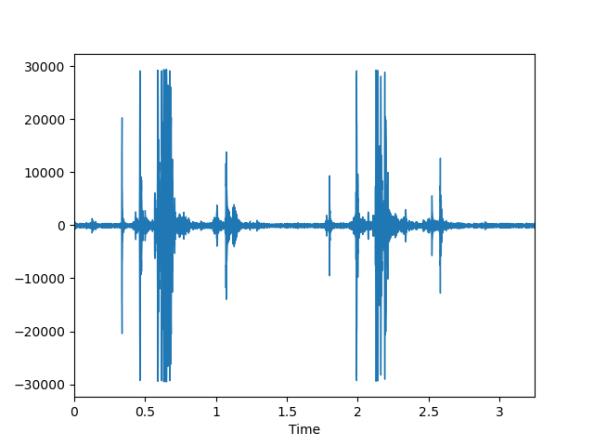
这里我们选择使用python的librosa模块读取音频,注意将振幅乘于32767来抵消归一化:
signal , sample_rate = librosa.load('chew.wav', sr=22050)#采样率默认值是22050,注意读取出来的数据,是做了32767的归一化
signal = signal * 32767
print(len(signal))
axis_x = numpy.arange(0, signal.size, 1)
plt.plot(axis_x, signal, linewidth=5)
plt.title("Time domain plot")
plt.xlabel("Time", fontsize=14)
plt.ylabel("Amplitude", fontsize=14)
plt.tick_params(axis='both', labelsize=14)
plt.savefig('Time domain plot.png')
plt.show()
波形图如下:
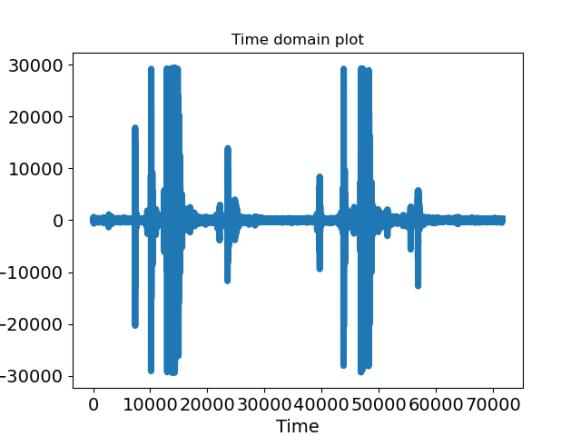
(2)预加重
对信号应用预加重滤波器,以放大高频。预加重滤波器在几种方面有用:
(1)平衡频谱,因为高频通常比低频具有较小的幅度;
(2)避免在傅立叶变换操作期间出现数值问题;
(3)还可改善信号 噪声比(SNR)。
可以使用以下公式中的一阶滤波器将预加重滤波器应用于信号x:
y(t) = x(t) - α*x(t-1),其中滤波器系数(α)的典型值为0.95或0.97
pre_emphasis = 0.97
emphasized_signal = numpy.append(signal[0], signal[1:] - pre_emphasis * signal[:-1])
axis_x = numpy.arange(0, emphasized_signal.size, 1)
plt.plot(axis_x, emphasized_signal, linewidth=5)
plt.title("Pre-Emphasis")
plt.xlabel("Time", fontsize=14)
plt.ylabel("Amplitude", fontsize=14)
plt.tick_params(axis='both', labelsize=14)
plt.savefig("Pre-Emphasis.png")
plt.show()
预加重后波形图如下:
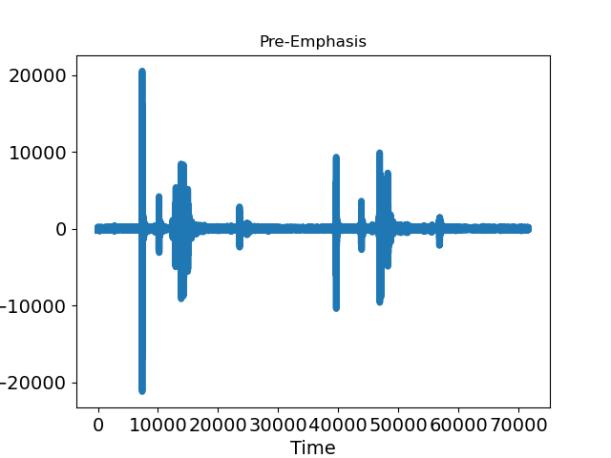
(3)分帧
经过预加重后,我们需要将信号分成短帧。 此步骤的基本原理是信号中的频率会随时间变化,因此在大多数情况下,对整个信号进行傅立叶变换是没有意义的,因为我们会随时间丢失信号的频率轮廓。
为避免这种情况,我们可以假设信号的频率在很短的时间内是固定的。 因此,通过在此短帧上进行傅立叶变换,可以通过串联相邻帧来获得信号频率轮廓较好的近似。
语音处理中的典型帧大小为20毫秒至40毫秒,连续帧之间有50%(+/- 10%)重叠。常见的设置是帧大小为25毫秒,frame_size = 0.025和10毫秒跨度(重叠15毫秒)
先计算一些长度,注意这里的长度是指包含采样点的数量。
frame_length是每一帧的长度,frame_step是帧的跨度,signal_length是音频信号长度。
frame_stride = 0.01
frame_size = 0.025
frame_length, frame_step = frame_size * sample_rate, frame_stride * sample_rate # Convert from seconds to samples
signal_length = len(emphasized_signal)
frame_length = int(round(frame_length))
frame_step = int(round(frame_step))
求帧的数量,这里用到了numpy.ceil函数,即向上取整函数。
#numpy.ceil 向上取整函数
num_frames = int(numpy.ceil
(float(numpy.abs(signal_length - frame_length + frame_step)) / frame_step)) # Make sure that we have at least 1 frame
由于信号的长度可能不是帧长的整数倍,我们需要对原信号进行填充,将其填充至帧长的整数倍,下面代码中的z即是要填充的0矩阵:
pad_signal_length = (num_frames - 1) * frame_step + frame_length
# 填充信号以确保所有帧具有相同数量的样本,而不会截断原始信号中的任何样本
z = numpy.zeros((pad_signal_length - signal_length))
pad_signal = numpy.append(emphasized_signal, z)
填充前和填充后音频信号的长度如下:
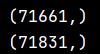
下面我们将音频信号转化为二维矩阵,每一行即是一个音频帧的内容,frames即是分帧后的二维矩阵,在本次实验中,帧矩阵的shape是325*551
#前一个 num_frames * frame_length 后一个 num_frames * frame_length,index是个二维矩阵,每一行是一个frame的值,比如第一行是0-550,第二行就是220-770
indices = numpy.tile(numpy.arange(0, frame_length), (num_frames, 1)) + numpy.tile(
numpy.arange(0, num_frames * frame_step, frame_step), (frame_length, 1)).T
print(indices.shape)
#将pad_signal转成num_frames * frame_length的格式,indices中的值是pad_signal的index
frames = pad_signal[indices.astype(numpy.int32, copy=False)]
(4)加窗
将信号切成帧后,我们对每个帧应用诸如汉明窗之类的窗口函数。 Hamming窗口具有以下形式:w[n]=0.54-0.46cos(2pin/(N-1))
其中0<=n<=N-1, N是窗长,有很多原因需要将窗函数应用于这些帧,特别是要抵消FFT无限计算并减少频谱泄漏。
使用numpy的窗函数对音频信号加窗:
frames *= numpy.hamming(frame_length)
2. 用周期图(periodogram)法来进行功率谱(power spectrum)估计;(短时傅里叶变换)
现在,我们可以在每个帧上执行N点FFT来计算频谱,这也称为短时傅立叶变换(STFT),
其中N通常为256或512,NFFT = 512; 然后使用以下公式计算功率谱(周期图):P=|FFT(xi)|^2/N,其中,xi是信号x的第i帧。
NFFT = 512
mag_frames = numpy.absolute(numpy.fft.rfft(frames, NFFT)) # Magnitude of the FFT
#print(mag_frames.shape)
pow_frames = ((1.0 / NFFT) * ((mag_frames) ** 2)) # Power Spectrum,**2是平方
在本次实验中,功率谱的shape是 325*257。
功率谱示例如下,它的横坐标是帧下标,纵坐标是不同频率,图中颜色越深(比如红色),对应频率的能量越大:
3.对功率谱用Mel滤波器组进行滤波,计算每个滤波器里的能量,对每个滤波器的能量取log
声谱图往往是很大的一张图,且依旧包含了大量无用的信息,所以我们需要通过梅尔标度滤波器组(mel-scale filter banks)将其变为梅尔频谱
(1)梅尔尺度(Mel Scale)是建立从人类的听觉感知的频率——Pitch到声音实际频率直接的映射。频率的单位是赫兹(Hz),人耳能听到的频率范围是20-20000Hz,但人耳对Hz这种标度单位并不是线性感知关系,例如,若把音调频率从1000Hz提高到2000Hz,我们的耳朵只能觉察到频率似乎提高了一些而不是一倍。但是通过把频率转换成美尔尺度,我们的特征就能够更好的匹配人类的听觉感知效果。从频率到梅尔频率的转换公式如下:
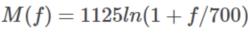
或者

我们可以观察一下转换后的映射图,可以发现人耳对于低频声音的分辨率要高于高频的声音,因为赫兹到梅尔是log的关系,所以当频率较小时,mel随Hz变化较快;当频率很大时,mel的上升很缓慢,曲线的斜率很小。这说明了人耳对低频音调的感知较灵敏,在高频时人耳是很迟钝的,梅尔标度滤波器组启发于此。
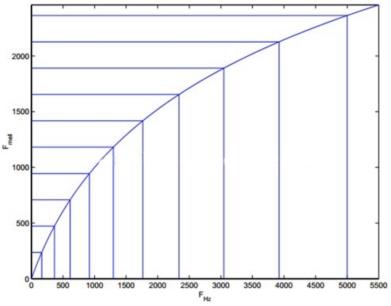
(2)梅尔滤波器
为了模拟人耳对声音的感知,人们发明的梅尔滤波器组。一组大约20-40(通常26)个三角滤波器组,它会对上一步得到的周期图的功率谱估计进行滤波。而且区间的频率越高,滤波器就越宽(但是如果把它变换到美尔尺度则是一样宽的)。为了计算方便,我们通常把26个滤波器用一个矩阵来表示,这个矩阵有26行,列数就是傅里叶变换的点数。
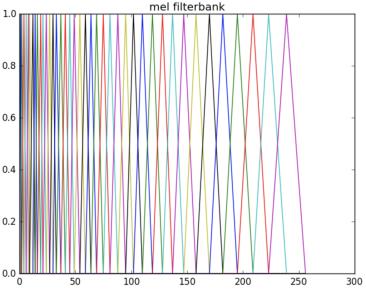
计算过程如下图所示,最后我们会保留这26个滤波器的能量。图(a)是26个滤波器;图(b)是滤波后的信号;图©是其中的第8个滤波器,它只让某一频率范围的信号通过;图(d)通过它的信号的能量;图(e)是第20个滤波器;图(f)是通过它的信号的能量。
(3)滤波
选取最低频率为0,最高频率为采样率的一半,设置26个区间,因为一个滤波器实际山要占据三个刻度,因此要划分出28和区间。
使用公式进行频率和梅尔刻度的转换。
nfilt = 26
low_freq_mel = 0
high_freq_mel = (2595 * numpy.log10(1 + (sample_rate / 2) / 700)) # Convert Hz to Mel
mel_points = numpy.linspace(low_freq_mel, high_freq_mel, nfilt + 2) # Equally spaced in Mel scale,划分出nfilt+2个区间
#print(mel_points)
hz_points = (700 * (10 ** (mel_points / 2595) - 1)) # Convert Mel to Hz
#print(hz_points)
bin = numpy.floor((NFFT + 1) * hz_points / sample_rate)
bin储存的是刻度对应的傅里叶变换点数。

fbank的shape是26*257,用来存储每个滤波器的值。
fbank = numpy.zeros((nfilt, int(numpy.floor(NFFT / 2 + 1))))
print(fbank.shape)
for m in range(1, nfilt + 1):
f_m_minus = int(bin[m - 1]) # left
f_m = int(bin[m]) # center
f_m_plus = int(bin[m + 1]) # right
for k in range(f_m_minus, f_m):
fbank[m - 1, k] = (k - bin[m - 1]) / (bin[m] - bin[m - 1])
for k in range(f_m, f_m_plus):
fbank[m - 1, k] = (bin[m + 1] - k) / (bin[m + 1] - bin[m])
将功率谱与滤波器做点积,这时filter_bank的shape是325*26,达成了降维的目标。
再将filter_bank中的0值改为最小负数,防止运算出现问题,再对每个滤波器的能量取log即得到log梅尔频谱。
filter_banks = numpy.dot(pow_frames, fbank.T)
filter_banks = numpy.where(filter_banks == 0, numpy.finfo(float).eps, filter_banks) # Numerical Stability
filter_banks = 20 * numpy.log10(filter_banks) # dB
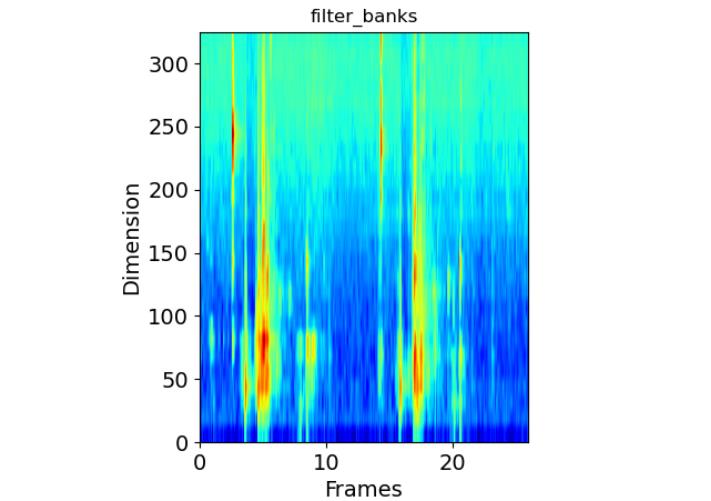
3. 进行离散余弦变换(DCT)变换,保留DCT的第2-13个系数
进行离散余弦变换(DCT)变换,保留DCT的第2-13个系数
事实证明,在上一步中计算出的滤波器组系数是高度相关的,这在某些机器学习算法中可能会出现问题。因此,我们可以应用离散余弦变换(DCT)去相关滤波器组系数,并产生滤波器组的压缩表示。
通常,对于自动语音识别(ASR),结果倒谱系数2-13将保留,其余的将被丢弃; num_ceps =12。丢弃其他系数的原因是它们代表滤波器组系数的快速变化,而这些细微的细节对自动语音识别(ASR)毫无帮助。
这里在进行DCT变化时用到了scipy模块的scipy.fftpack.dct函数。
num_ceps = 12
mfcc = dct(filter_banks, type=2, axis=1, norm='ortho')[:, 1: (num_ceps + 1)] # Keep 2-13
"""
可以将正弦提升器1应用于MFCC,去加重过高的MFCCs,这被可以改善嘈杂信号中的语音识别。
"""
cep_lifter = 22
(nframes, ncoeff) = mfcc.shape
n = numpy.arange(ncoeff)
lift = 1 + (cep_lifter / 2) * numpy.sin(numpy.pi * n / cep_lifter)
mfcc *= lift # *
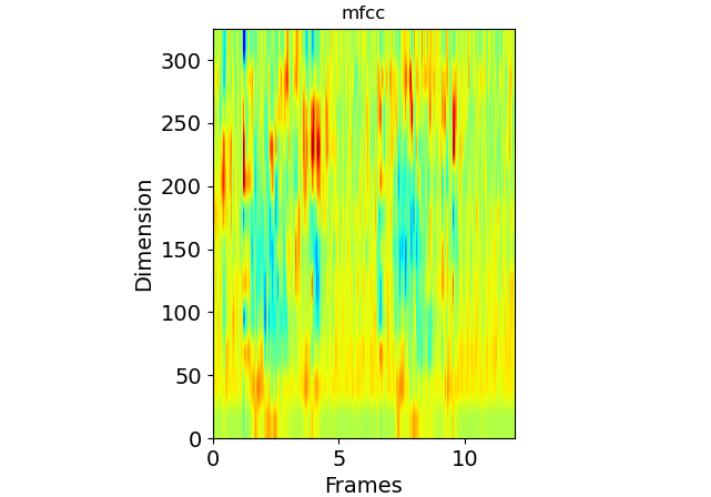
四、代码总和
import numpy
import librosa
from scipy.io import wavfile
from scipy.fftpack import dct
import matplotlib.pyplot as plt
signal , sample_rate = librosa.load('chew.wav', sr=22050)#采样率默认值是22050,注意读取出来的数据,是做了32767的归一化
signal = signal * 32767
print(len(signal))
axis_x = numpy.arange(0, signal.size, 1)
plt.plot(axis_x, signal, linewidth=5)
plt.title("Time domain plot")
plt.xlabel("Time", fontsize=14)
plt.ylabel("Amplitude", fontsize=14)
plt.tick_params(axis='both', labelsize=14)
plt.savefig('Time domain plot.png')
plt.show()
"""
Pre-Emphasis 预加重
"""
pre_emphasis = 0.97
emphasized_signal = numpy.append(signal[0], signal[1:] - pre_emphasis * signal[:-1])
axis_x = numpy.arange(0, emphasized_signal.size, 1)
plt.plot(axis_x, emphasized_signal, linewidth=5)
plt.title("Pre-Emphasis")
plt.xlabel("Time", fontsize=14)
plt.ylabel("Amplitude", fontsize=14)
plt.tick_params(axis='both', labelsize=14)
plt.savefig("Pre-Emphasis.png")
plt.show()
frame_stride = 0.01
frame_size = 0.025
frame_length, frame_step = frame_size * sample_rate, frame_stride * sample_rate # Convert from seconds to samples
signal_length = len(emphasized_signal)
frame_length = int(round(frame_length))
frame_step = int(round(frame_step))
'''num_frames = int(numpy.ceil
(float(numpy.abs(signal_length - frame_length)) / frame_step)) # Make sure that we have at least 1 frame
#numpy.ceil 向上取整函数
pad_signal_length = num_frames * frame_step + frame_length'''
#numpy.ceil 向上取整函数
num_frames = int(numpy.ceil
(float(numpy.abs(signal_length - frame_length + frame_step)) / frame_step)) # Make sure that we have at least 1 frame
pad_signal_length = (num_frames - 1) * frame_step + frame_length
# 填充信号以确保所有帧具有相同数量的样本,而不会截断原始信号中的任何样本
z = numpy.zeros((pad_signal_length - signal_length))
pad_signal = numpy.append(emphasized_signal, z)
print(emphasized_signal.shape)
print(pad_signal.shape)
#前一个 num_frames * frame_length 后一个 num_frames * frame_length,index是个二维矩阵,每一行是一个frame的值,比如第一行是0-550,第二行就是220-770
indices = numpy.tile(numpy.arange(0, frame_length), (num_frames, 1)) + numpy.tile(
numpy.arange(0, num_frames * frame_step, frame_step), (frame_length, 1)).T
print(indices.shape)
#将pad_signal转成num_frames * frame_length的格式,indices中的值是pad_signal的index
frames = pad_signal[indices.astype(numpy.int32, copy=False)]
frames *= numpy.hamming(frame_length)
# frames *= 0.54 - 0.46 * numpy.cos((2 * numpy.pi * n) / (frame_length - 1)) # Explicit Implementation **
# 傅立叶变换和功率谱
NFFT = 512
mag_frames = numpy.absolute(numpy.fft.rfft(frames, NFFT)) # Magnitude of the FFT
#print(mag_frames.shape)
pow_frames = ((1.0 / NFFT) * ((mag_frames) ** 2)) # Power Spectrum,**2是平方
#print(pow_frames.shape)
# 滤波器组 Filter Banks
nfilt = 26
low_freq_mel = 0
high_freq_mel = (2595 * numpy.log10(1 + (sample_rate / 2) / 700)) # Convert Hz to Mel
mel_points = numpy.linspace(low_freq_mel, high_freq_mel, nfilt + 2) # Equally spaced in Mel scale,划分出nfilt+2个区间
#print(mel_points)
hz_points = (700 * (10 ** (mel_points / 2595) - 1)) # Convert Mel to Hz
python求音频的梅尔倒谱系数