实战排查由于系统负载引起的服务响应异常
Posted 程序员大咖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实战排查由于系统负载引起的服务响应异常相关的知识,希望对你有一定的参考价值。
????????关注后回复 “进群” ,拉你进程序员交流群????????
作者丨Coder的技术之路
来源丨Coder的技术之路
Duang,风和日丽的某天上午,一连串的服务耗时异常报警,打破了宁静~ 万茜还有张雨绮~

服务为啥突然超时了
从大方面说基本上就是两类,一类是链路出了问题,包括网络抖动,链路环中的某一节点抖动等。另一类是服务本身的问题,包括服务器自身问题如磁盘老化等,还有代码bug造成的服务等待或服务器负载问题。
对第一类问题比较好发现,看监控,查异常超时日志,总会发现端倪,但是对第二类场景就不那么容易定位了,但基本上有一个排查的套路。
系统负载
WIKI: the system Load is a measure of the amount of work that a compute system is doing
啥意思,就是衡量计算机这个时候正在做多少事,是不是忙不过来了~
那么,怎么判断当前系统是否已经过载了呢对一般的系统来说,Load平均值要小于CPU的数量;好在linux足够的强大,有强大的命令来支撑排查问题。
问题排查
「top」看整体表现
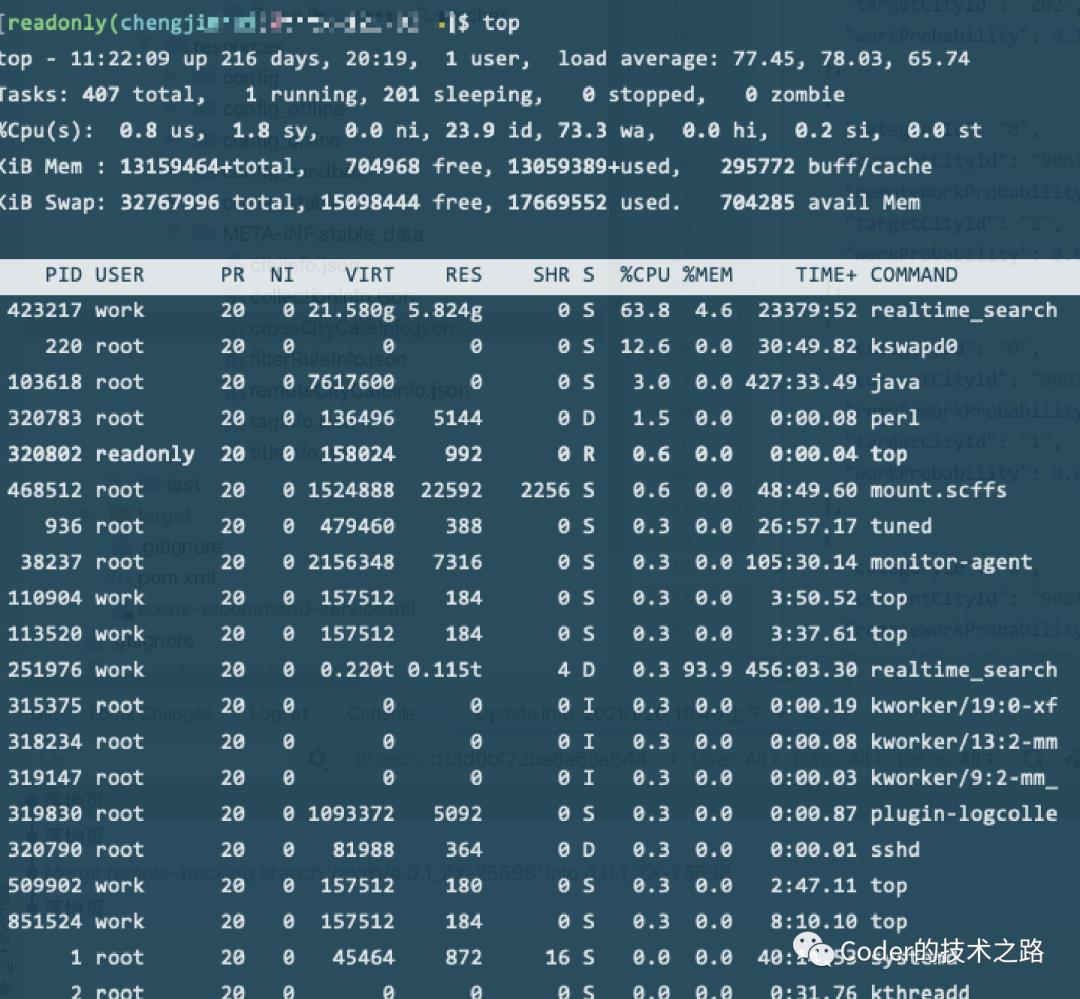
可以看出,系统负载确实出现了问题
load average : 77 78 65
对于我们的32cpu的机器来说,已经过载
Tasks行 zombie=0,还好没假死进程;
Cpus行,wa=73.3 居然这么高,IO的问题要重点看
Swap行,交换区使用了一半多,也不低
有的同学说,是swap的原因,内存不够,导致物理内存与swap分区发生置换引起的过载,那么到底是不是这个原因呢。
「vmstat 3」看性能指标

每3秒捕捉一次性能指标,重点看si 和 so 的数值,「si是由内存进入内存交换区的数量;so是由内存交换区进入内存的数量」。如果两个值长时间都是0,即使swap的值很大,其实系统也是可以认为是正常的。
观察发现,其实swap的指标还算正常,那swap还不是最终的原因。
「iostat -x 1 5」看IO
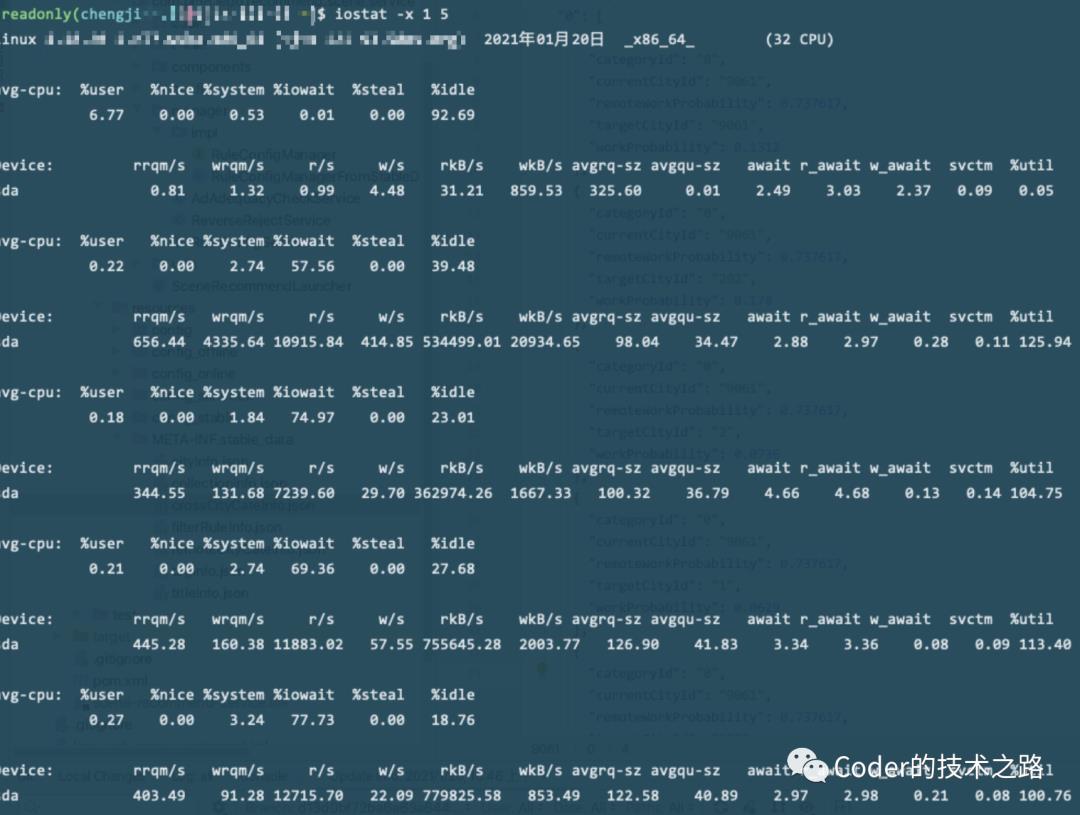 我的天,都不用看读写的指标,直接看最后一个util,居然每次都达到了100往上,IO满负荷运行啊。
我的天,都不用看读写的指标,直接看最后一个util,居然每次都达到了100往上,IO满负荷运行啊。
系统运行队列基本都被IO占领,肯定会过载了。那就重点排查在这个时间点附近有过上线的代码,果然,由于代码原因导致正排倒排域全部暴涨,写索引的也随之暴涨。回滚代码,恢复正常。
福利环节,恢复了就完了么?
顺便把负载相关的命令和指标理一遍不好么
「top」命令:
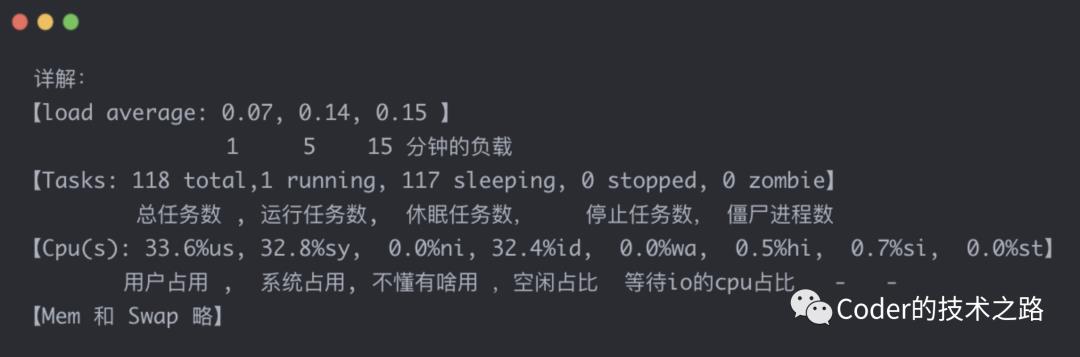
在top命令下按1 ,可以看到分cpu的指标展示。
在top命令下,按shift + "c",则将进程按照CPU使用率从大到小排序。
在top命令下,按shift+"p",则将进程按照内存使用率从大到小排序,可以定位出哪些服务占用了较高的CPU和内存。
「vmstat 1 」命令

摘自大神总结:
CPU:
r 列表示运行和等待cpu时间片的进程数,如果长期大于1,说明cpu不足,需要增加cpu。
b 列表示在等待资源的进程数,比如正在等待I/O、或者内存交换等。cpu 表示cpu的使用状态
us 列显示了用户方式下所花费 CPU 时间的百分比。us的值比较高时,
说明用户进程消耗的cpu时间多,但是如果长期大于50%,需要考虑优化用户的程序。
sy 列显示了内核进程所花费的cpu时间的百分比。这里us + sy的参考值为80%,
如果us+sy 大于80%说明可能存在CPU不足。
wa 列显示了IO等待所占用的CPU时间的百分比。这里wa的参考值为30%,
如果wa超过30%,说明IO等待严重,这可能是磁盘大量随机访问造成的,
也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作)。
id 列显示了cpu处在空闲状态的时间百分比 system 显示采集间隔内发生的中断数
in 列表示在某一时间间隔中观测到的每秒设备中断数。cs列表示每秒产生的上下文
切换次数,如当cs比磁盘I/O和网络信息包速率高得多,都应进行进一步调查。
memory
swpd 切换到内存交换区的内存数量(k表示)。如果swpd的值不为0,
或者比较大,比如超过了100m,只要si、so的值长期为0,系统性能还是正常
free 当前的空闲页面列表中内存数量(k表示)
buff 作为buffer cache的内存数量,一般对块设备的读写才需要缓冲。
cache: 作为page cache的内存数量,一般作为文件系统的cache,如果cache较大,
说明用到cache的文件较多,如果此时IO中bi比较小,说明文件系统效率比较好。
swap
si 由内存进入内存交换区数量。
so由内存交换区进入内存数量。
IO
bi 从块设备读入数据的总量(读磁盘)(每秒kb)。
bo 块设备写入数据的总量(写磁盘)(每秒kb)
这里我们设置的bi+bo参考值为1000,如果超过1000,而且wa值较大应该考虑
均衡磁 盘负载,可以结合iostat输出来分析
-End-
最近有一些小伙伴,让我帮忙找一些 面试题 资料,于是我翻遍了收藏的 5T 资料后,汇总整理出来,可以说是程序员面试必备!所有资料都整理到网盘了,欢迎下载!
点击????卡片,关注后回复【面试题】即可获取
在看点这里![]() 好文分享给更多人↓↓
好文分享给更多人↓↓
以上是关于实战排查由于系统负载引起的服务响应异常的主要内容,如果未能解决你的问题,请参考以下文章