记一次服务器高CPU的排查思路
Posted echoxian
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记一次服务器高CPU的排查思路相关的知识,希望对你有一定的参考价值。
现象
排查思路
另一台服务器CPU正常,由于消息中心有部分老接口是域名调用的,网关已做负载均衡,并且pinpoint上的两台服务器gc如图,初步猜测是否是负载不均衡导致。
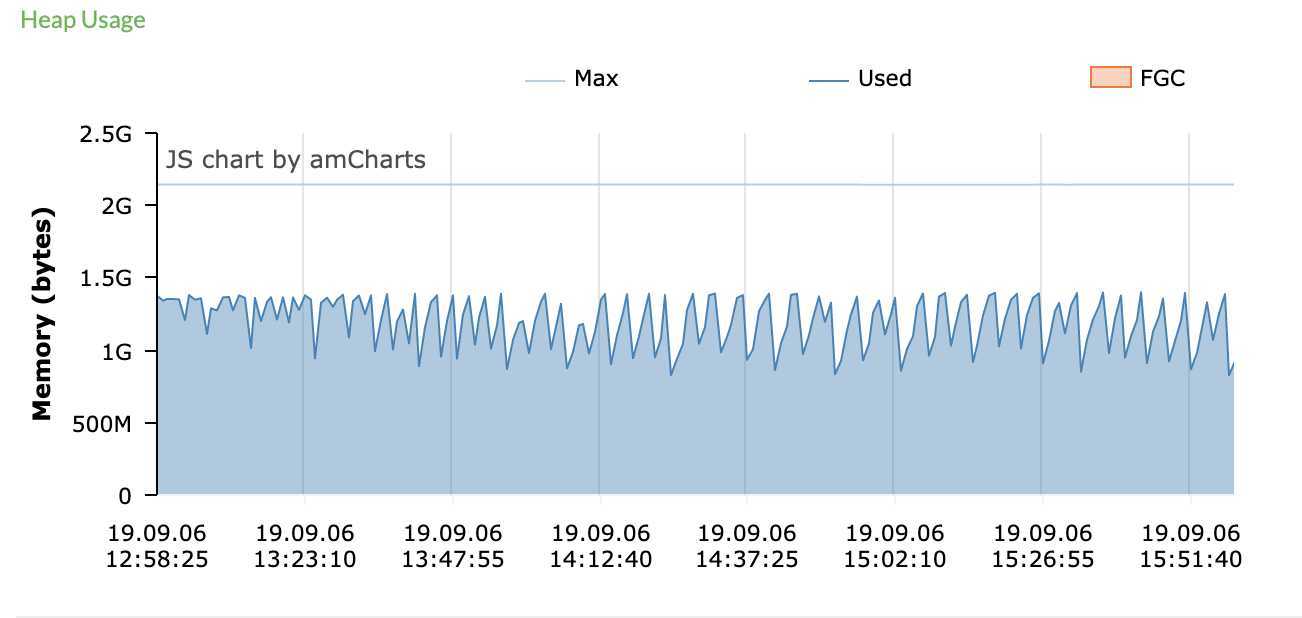
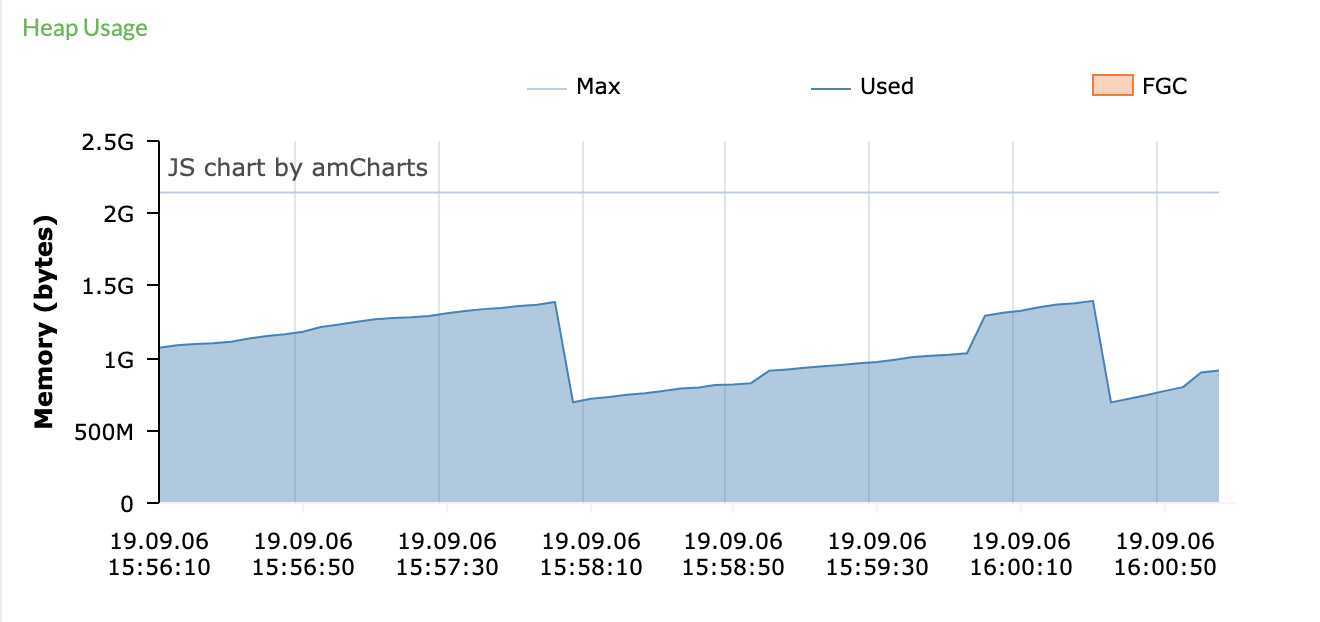
经运维调试nginx权重无效,证明与负载均衡无关。那么先看子线程,这种情况必定由某几个线程引起
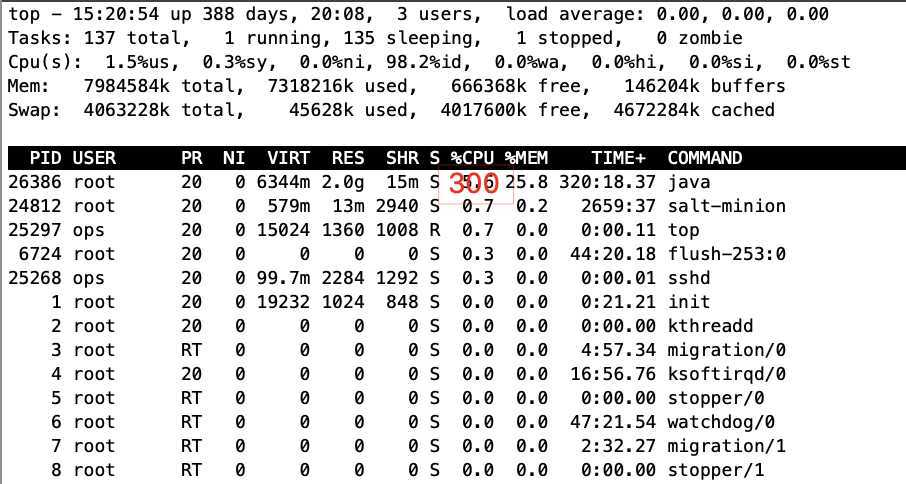
ps -mp pid -o THREAD,tid,time命令查看子线程,如图
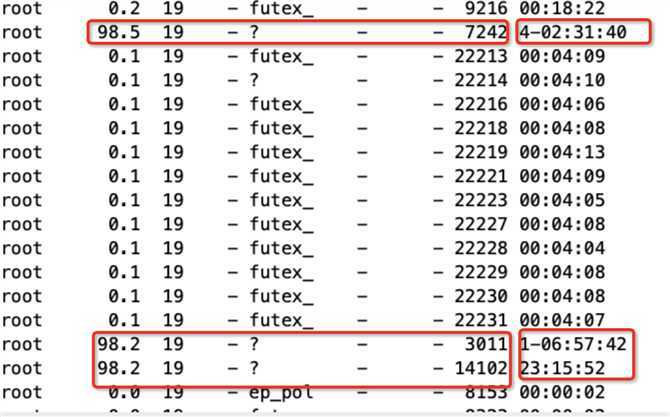
这个数据上,分两部分看,1、有3个占用高的线程,2、执行时间可以注意到分别是4天,1天,23小时。说明线程出于某种情况,死锁,死循环。
由于这时候jstack操作可能引起内存溢出,应用直接挂掉,由运维操作下载日志。
jstack pid |grep tid
由上述子线程pid转化十六进制查询对应日志。如下:
"HttpClient@440f33e8-124521" #124521 prio=5 os_prio=0 tid=0x00007f2c7c042800 nid=0x1c4a runnable [0x00007f2c5e9c1000]
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.EPollArrayWrapper.interrupt(Native Method)
at sun.nio.ch.EPollArrayWrapper.interrupt(EPollArrayWrapper.java:317)
at sun.nio.ch.EPollSelectorImpl.wakeup(EPollSelectorImpl.java:207)
- locked <0x000000008658afa0> (a java.lang.Object)
at java.nio.channels.spi.AbstractSelector$1.interrupt(AbstractSelector.java:213)
at java.nio.channels.spi.AbstractSelector.begin(AbstractSelector.java:219)
at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:92)
at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86)
- locked <0x0000000086587170> (a sun.nio.ch.Util$2)
- locked <0x000000008658ad40> (a java.util.Collections$UnmodifiableSet)
- locked <0x000000008658ab98> (a sun.nio.ch.EPollSelectorImpl)
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:97)
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:101)
at org.eclipse.jetty.io.ManagedSelector$SelectorProducer.select(ManagedSelector.java:385)
at org.eclipse.jetty.io.ManagedSelector$SelectorProducer.produce(ManagedSelector.java:326)
at org.eclipse.jetty.util.thread.strategy.EatWhatYouKill.produceTask(EatWhatYouKill.java:342)
at org.eclipse.jetty.util.thread.strategy.EatWhatYouKill.doProduce(EatWhatYouKill.java:189)
at org.eclipse.jetty.util.thread.strategy.EatWhatYouKill.tryProduce(EatWhatYouKill.java:175)
at org.eclipse.jetty.util.thread.strategy.EatWhatYouKill.produce(EatWhatYouKill.java:139)
at org.eclipse.jetty.io.ManagedSelector$$Lambda$106/586427179.run(Unknown Source)
at org.eclipse.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:754)
at org.eclipse.jetty.util.thread.QueuedThreadPool$2.run(QueuedThreadPool.java:672)
at java.lang.Thread.run(Thread.java:745)
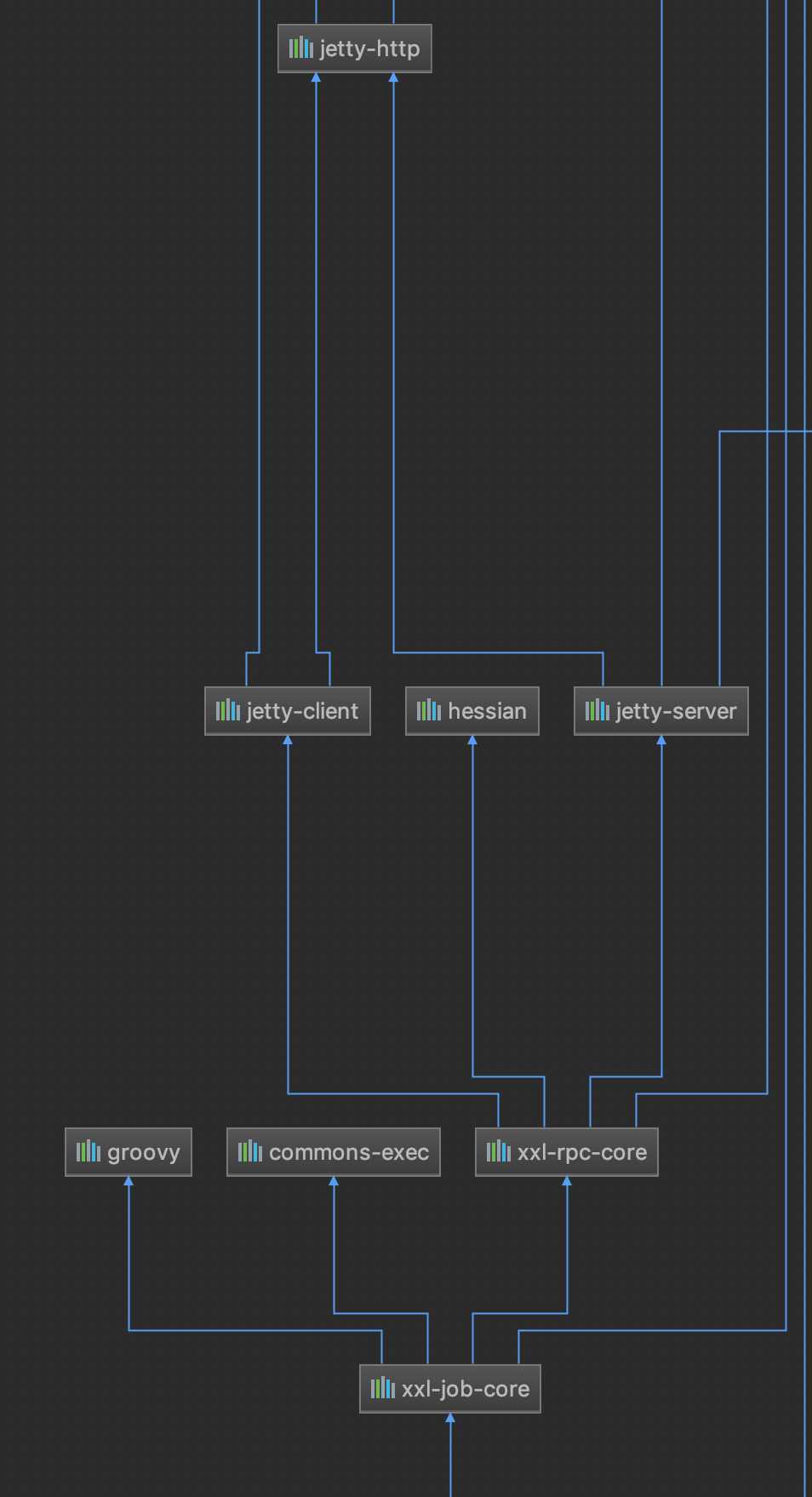
可以看到由多个locked操作,可以看到有引用org.eclipse.jetty.io及sun.nio.ch.,但是我们的代码里并没有用到这两个jar包内容。
代码内maven引用反推,可以看到jetty包是由定时任务xxl-job引入的,那么可以判断这个问题是由xxl-job引起的,但是这么多应用都在使用定时任务,为什么只有消息中心有问题?这里抛出这个问题。
查看定时任务的设置,在定时任务配置方向和其他应用有什么不同。
如下可以看到消息中心一共配了17个任务,而其他应用任务最多不超过4个。并且由上面jstack日志所示,有使用到NIO的异步线程EPoll,难道是因为线程池耗尽了,出于某种原因导致死锁?

那么看下NIO有什么坑吧。下面是我查到的官方原文:

简单来说,就是epoll这个异步线程是一个复用型线程,他的使用过程是socket协议——开启通道——执行——关闭通道——socket协议关闭,
但是本来应该被移除的fd,被后来的线程给注册上了,导致这个线程进入死循环。这也可以解释为什么只有3个线程死锁,并没有出现大面积死锁,因为这是一个并发导致的隐藏问题。
然后再看这三个子线程,按当时时间反推,毛估估刚好是整点触发,猜测是不是由于17个定时任务,在某个时间同时触发导致这个问题?这个没有证据能够证明他是这个原因导致的。
但是在看源码的时候可以注意到,jetty里有一个httpclient有使用到epoll的异步线程,刚好这也是消息中心的定时任务与其他应用的不同之处。
由于.net应用没有定时任务,即通过xxl-job的GLUE方式使用jetty的httpclient基于消息中心服务器请求接口。
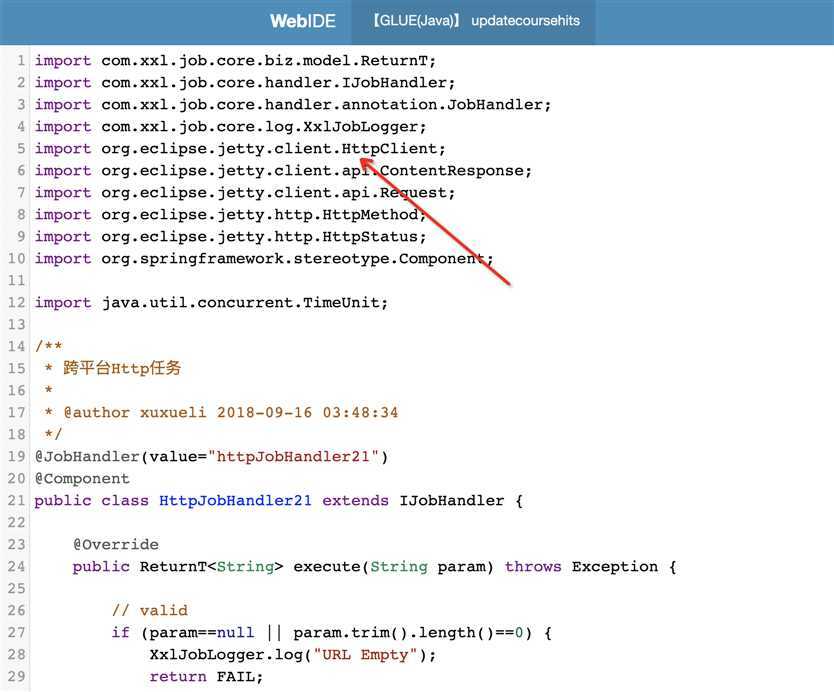
那么可以大概断定,大概率是这里导致的死锁,去xxl-job的github上也可以看到作者将这种方式改成了java.net.HttpURLConnection方式请求。改完配置,重新发布,已观察两天没有问题。后续若再发现类似问题,继续跟进
以上是关于记一次服务器高CPU的排查思路的主要内容,如果未能解决你的问题,请参考以下文章