高并发消息队列补充篇:在所依赖存储不授信的场景下实现柔性事务降级
Posted 程序员大咖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高并发消息队列补充篇:在所依赖存储不授信的场景下实现柔性事务降级相关的知识,希望对你有一定的参考价值。
????????关注后回复 “进群” ,拉你进程序员交流群????????
本文内容预览:
新公司做设计的些许不适应
基础服务支持不到位的坑
2.1 项目背景和整理设计思路2.2 不可缺少的强依赖--存储2.3 存储的调研和选择消息队列的介入
3.1 非强一致存储为啥会丢数据3.2 消息队列登场3.3 更进一步--存储降级总结
Part1新公司做设计的些许不适应
在大厂和小厂做研发到底有啥不一样?其他好的坏的方方面面没法细说,咱主要还得说技术方面。
本来大部分的架构体系和思维都是在大厂构建的,到了小厂之后发现,起止是不适用,简直就是不适用(夸大了,????)。其实就本人理解主要是在底层的基础能力的支持程度上有所差异。
很多时候,在大厂待惯了的同学,或者一直在大厂待着的同学,思维惯性是不可避免的,感觉某些能力是理所应当的时候,往往实际情况是无法百分之百契合的。
所以,这种情况下,更要求我们有更强的细节把控能力,在系统设计和实施之前,要把所有涉及到的外部服务、底层支撑程度全都考虑进去,并一一应证,以做到万无一失。
本文阐述一个本人真实的采坑经历,希望帮大家加深对系统设计把控能力的重视。
Part2基础服务支持不到位的坑
2.1项目背景和整理设计思路
项目背景其实还是我们的数据一致性保证长事务引擎。
整体架构如下: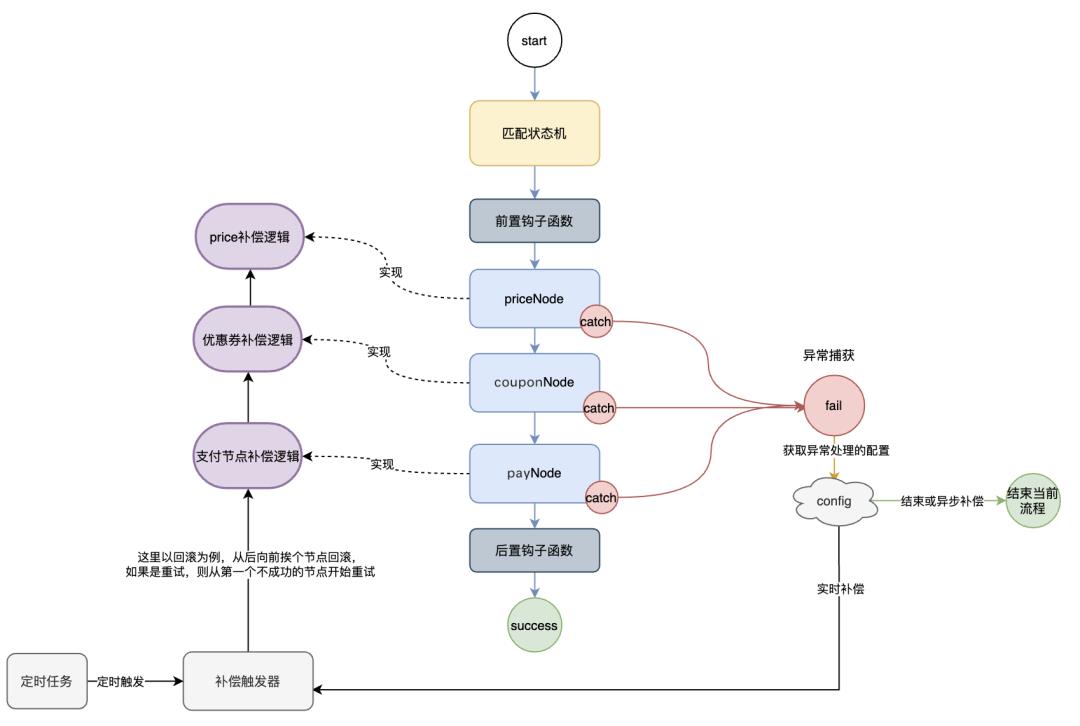
通过状态机来组织和支持多种不同的业务流
通过将外部服务节点化来抽象和规范化参与者的服务
通过节点的异常捕获来感知参与方的执行结果
通过实时或异步的恢复机制,实现柔性事务·
2.2不可缺少的强依赖--存储
想要业务请求保证最终一致,不可能是没有存储参与的一锤子买卖,因为还要考虑本身服务器的抖动,业务上的异步要求等等。所以,存储是一个不可缺少的依赖,如下图所示: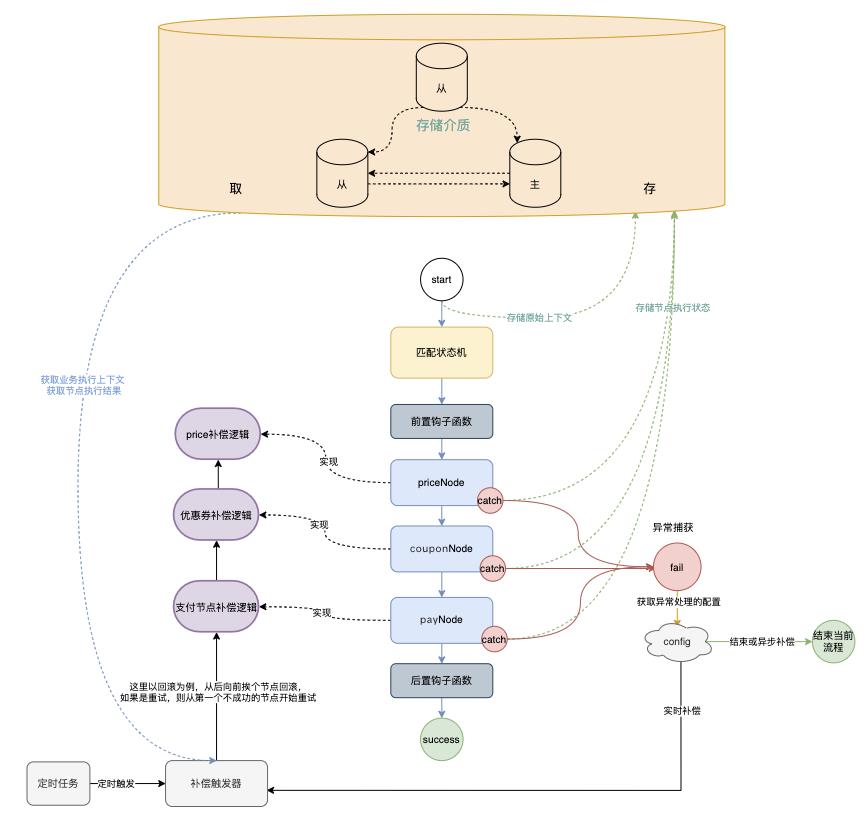 存储服务作用在引擎的整个生命周期:
存储服务作用在引擎的整个生命周期:
在请求进入初期,进行上下文落地(因为广告流量只有一次操作,不像普通支付可以允许用户重试,广告场景下,用户的多次操作需要进行分别计费,并且不太适合利用MQ的ack机制进行重试,因为那需要等流程全部执行完,会影响消息消费速率)
在节点执行结束,进行节点执行状态落地(这样,在遇到需要补偿的情况,可以避免冗余调用,防止不需要重试的系统被其他抖动的系统冲击)
在异步恢复时,获取上下文和节点执行状态集合,以完成事务的最终一致性处理。
2.3存储的调研和选择
业界的选择--数据库
对于支付类业务,其实,最好的是用数据库。业务层的订单表相当于业务请求上下文,会将请求的所需信息落地(没有上下文落地其实也没关系,返回用户失败即可)。
节点执行状态数据存在和订单表同库的另一个表中,即可支持一个在一个本地事务内保证分布式事务的最终一致性逻辑。
业务特性决定了数据库不合适
由于种种原因,我们这里不太适合用数据库,一个是广告上下文太大,且绝大多时候没有用,为了少数异常存到订单表的话太浪费;二是目前采用实时库+历史库的方式进行,没有分库,如果增加了中间状态表,目前的并发量,对数据库压力会很大,但目前搞分库又不是那么必要。
所以数据库不太适合。
公司自研存储的选择和使用
正好,公司自研了一套基于rocksdb的高性能存储,在读写性能和数据结构方面基本可以代替mysql和Redis。在公司内部被广泛使用。
两个版本,一个是paxos强一致版本,读写性能稍弱,但保证数据强一致;另一个是普通版本,读写性能更高,但不保证强一致,即有可能主从切换会丢数据。
对于带金融属性的业务来说,在理论上的读写性能满足业务要求的情况下,当然是首选强一致的版本了。特别是业务上下文,丢失的结果就是该请求的整个异常恢复流程无法被正常唤起。
然而,理想照进现实,由于该版本之前应对的业务场景较为简单,并发也没有我们这么大,一些底层调优不到位导致服务抖动频繁。
如果是在大厂,就像之前用OB,只要OB有承若数据不丢,那基本不用考虑丢失的问题。如果丢了,我想可能大概率就会把锅抛给存储团队,限时优化之类。
但,我们小厂可都是相亲相爱的一家人,怎么能干这种事。所以选了另一个版本,使用更广泛,更成熟的非强一致版本。而数据丢失的问题由业务自己来想办法。
Part3消息队列的介入
3.1非强一致存储为啥会丢数据
 如上图所示,该存储架构采用的是主从模式,数据由主写入,同步到从,当主异常时,进行主从切换,恢复服务。
如上图所示,该存储架构采用的是主从模式,数据由主写入,同步到从,当主异常时,进行主从切换,恢复服务。
但是,由于不是强一致协议,写主成功即为成功,当主宕机时,虽然主从切换很快,10秒完成,但还没有来得及同步到从的那部分数据,就会因为因为主从切换而丢失。
怎么办?
3.2消息队列登场
为了应对存储不授信的情况,我们引入了消息队列来实现存储的丢失补偿。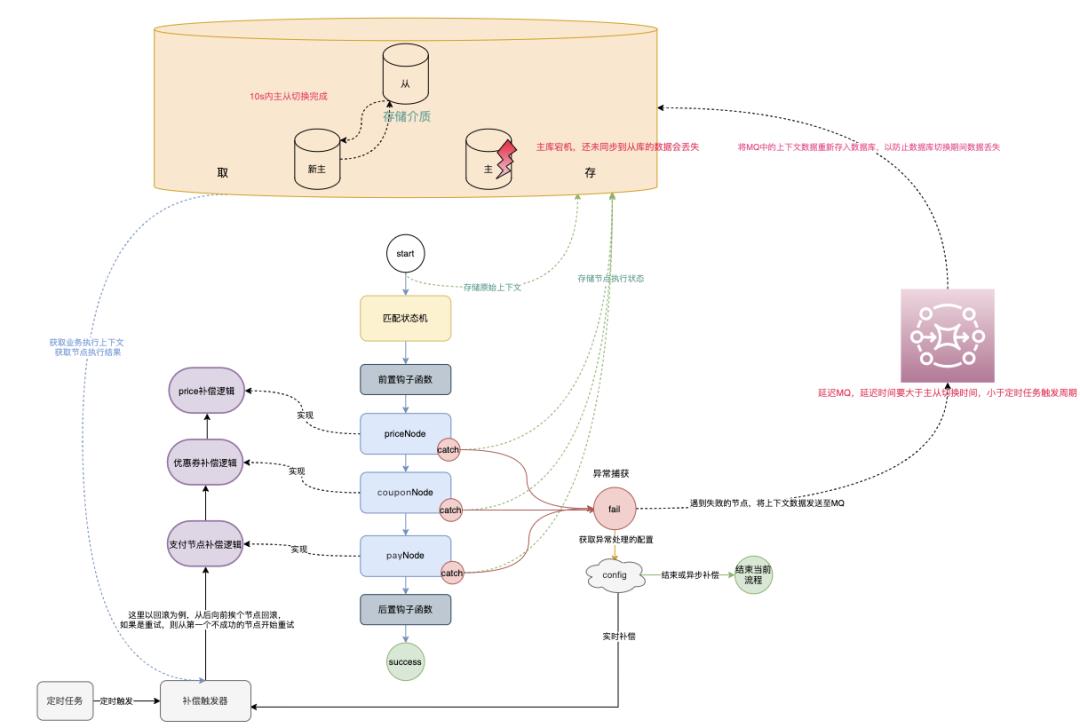 如上图所示,引入延迟消息进入处理流程。
如上图所示,引入延迟消息进入处理流程。
当节点执行发生异常时,发送当前业务上下文到消息队列。如果是正常执行的情况则无需发送。
消息的延迟间隔,要大于主从切换的时间,并且需要小于定时任务的触发间隔。比如,主从切换需要10s,那延迟消息的延迟间隔就设置为30s , 接收消息都重新插入上下文到存储。在节点异常一分钟之后,被定时任务捞取,执行处理。
用两个时间差来覆盖掉主从切换带来的数据丢失的影响。
3.3更进一步--存储降级
那么,更极端的情况,如果整个存储服务持续不可用怎么办?
降级: 自己的命运要把握在自己手中。目的是保证绝大部分服务正常。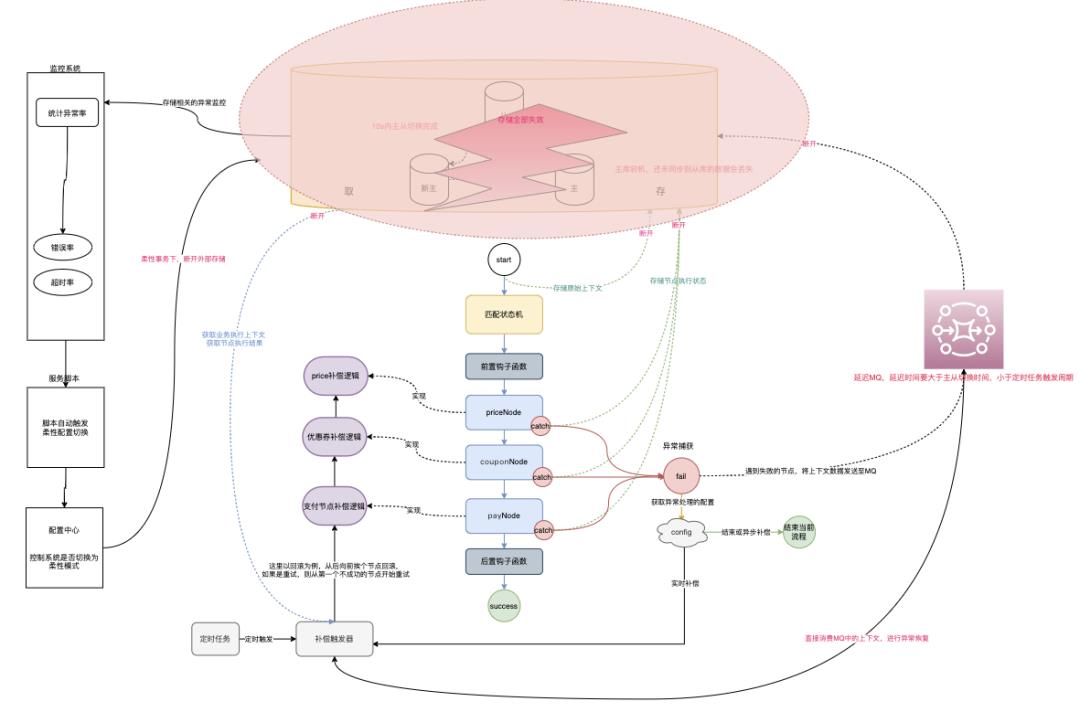
监控系统。用于收集和汇报操作存储时的异常,并统计错误率和超时率
一旦错误率和超时率达到阈值(比如持续30s,所有服务全部超时)执行关联脚本。
脚本负责触发配置中心的配置切换,由正常模式切换为柔性模式。
柔性模式下,所有涉及存储读写的操作将被忽略,以保障绝大部分请求可以正常执行。
遇到执行异常的节点,将上下文发送至消息队列,消费时不再插入存储,而是改为直接消费。
Part4总结
本文想从实际的案例出发,给大家提供一种利用消息队列解决问题的思路。希望大家遇到其他问题的时候,可以有所借鉴。毕竟业务场景千千万,只有思路得人心。
-End-
最近有一些小伙伴,让我帮忙找一些 面试题 资料,于是我翻遍了收藏的 5T 资料后,汇总整理出来,可以说是程序员面试必备!所有资料都整理到网盘了,欢迎下载!
点击????卡片,关注后回复【面试题】即可获取
在看点这里![]() 好文分享给更多人↓↓
好文分享给更多人↓↓
以上是关于高并发消息队列补充篇:在所依赖存储不授信的场景下实现柔性事务降级的主要内容,如果未能解决你的问题,请参考以下文章