高并发框架之消息队列
Posted Panda_Java
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高并发框架之消息队列相关的知识,希望对你有一定的参考价值。
高并发框架之消息队列
- 1 为什么使用消息队列?(消息队列的应用场景?)
- 2. 各种消息队列产品的比较?
- 3 消息队列的优点和缺点?
- 4 如何保证消息队列的高可用?
- 5 如何保证消息不丢失?(如何保证消息的可靠性传输?)
- 6 如何保证消息不被重复消费?(如何保证消息消费的幂等性)
- 7 如何保证消息消费的顺序性?
- 8 大量消息堆积处理 如何处理?
- 9. 消息过期怎样处理?
- 10 参考视频及文档
1 为什么使用消息队列?(消息队列的应用场景?)
为什么使用消息队列? 消息队列有什么优缺点?kafka、activemq 都有什么区别以及合适哪些场景?
链接: Activemq入门教程.
1.1 解耦
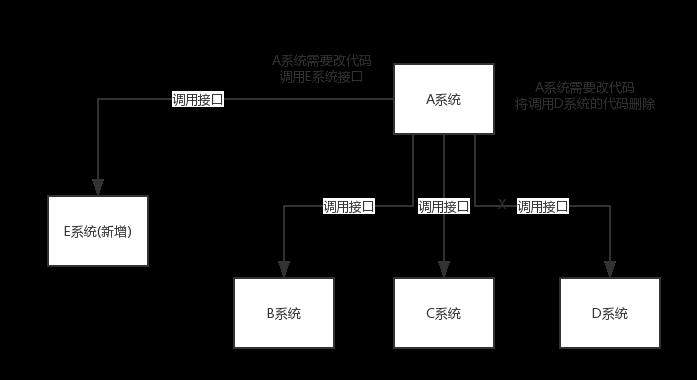
- 耦合场景:看这么个场景。A 系统发送数据到 BCD 三个系统,通过接口调用发送。如果 E 系统也要这个数据呢?那如果 C 系统现在不需要了呢?A 系统负责人几乎崩溃…
1.2 异步
- 异步场景:再来看一个场景,A 系统接收一个请求,需要在自己本地写库,还需要在 BCD 三个系统写库,自己本地写库要 3ms,BCD 三个系统分别写库要 300ms、450ms、200ms。最终请求总延时是 3 + 300 + 450 + 200 = 953ms,接近 1s,用户感觉搞个什么东西,慢死了慢死了。用户通过浏览器发起请求,等待个 1s,这几乎是不可接受的。


1.3 削峰
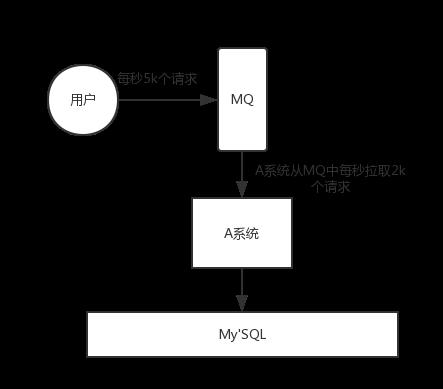
一般的 mysql,扛到每秒 2k 个请求就差不多了,如果每秒请求到 5k 的话,可能就直接把 MySQL 给打死了,导致系统崩溃,用户也就没法再使用系统了。
但是高峰期一过,到了下午的时候,就成了低峰期,可能也就 1w 的用户同时在网站上操作,每秒中的请求数量可能也就 50 个请求,对整个系统几乎没有任何的压力。

如果使用 MQ,每秒 5k 个请求写入 MQ,A 系统每秒钟最多处理 2k 个请求,因为 MySQL 每秒钟最多处理 2k 个。A 系统从 MQ 中慢慢拉取请求,每秒钟就拉取 2k 个请求,不要超过自己每秒能处理的最大请求数量就 ok,这样下来,哪怕是高峰期的时候,A 系统也绝对不会挂掉。而 MQ 每秒钟 5k 个请求进来,就 2k 个请求出去,结果就导致在中午高峰期(1 个小时),可能有几十万甚至几百万的请求积压在 MQ 中。
2. 各种消息队列产品的比较?

综上,各种对比之后,有如下建议:
一般的业务系统要引入 MQ,最早大家都用 ActiveMQ,但是现在确实大家用的不多了,没经过大规模吞吐量场景的验证,社区也不是很活跃,所以大家还是算了吧,我个人不推荐用这个了。
后来大家开始用 RabbitMQ,但是确实 erlang 语言阻止了大量的 Java 工程师去深入研究和掌控它,对公司而言,几乎处于不可控的状态,但是确实人家是开源的,比较稳定的支持,活跃度也高。
不过现在确实越来越多的公司会去用 RocketMQ,确实很不错,毕竟是阿里出品,但社区可能有突然黄掉的风险(目前 RocketMQ 已捐给 Apache,但 GitHub 上的活跃度其实不算高)对自己公司技术实力有绝对自信的,推荐用 RocketMQ,否则回去老老实实用 RabbitMQ 吧,人家有活跃的开源社区,绝对不会黄。
所以中小型公司,技术实力较为一般,技术挑战不是特别高,用 RabbitMQ 是不错的选择;大型公司,基础架构研发实力较强,用 RocketMQ 是很好的选择。
如果是大数据领域的实时计算、日志采集等场景,用 Kafka 是业内标准的,绝对没问题,社区活跃度很高,绝对不会黄,何况几乎是全世界这个领域的事实性规范。
3 消息队列的优点和缺点?
缺点有以下几个:
3.1 系统可用性降低
系统引入的外部依赖越多,越容易挂掉。本来你就是 A 系统调用 BCD 三个系统的接口就好了,ABCD 四个系统还好好的,没啥问题,你偏加个 MQ 进来,万一 MQ 挂了咋整?MQ 一挂,整套系统崩溃,你不就完了?如何保证消息队列的高可用,可以点击这里查看。
3.2 系统复杂度提高
硬生生加个 MQ 进来,你怎么保证消息没有重复消费?怎么处理消息丢失的情况?怎么保证消息传递的顺序性?头大头大,问题一大堆,痛苦不已。

3.3 一致性问题
A 系统处理完了直接返回成功了,人都以为你这个请求就成功了;但是问题是,要是 BCD 三个系统那里,BD 两个系统写库成功了,结果 C 系统写库失败了,咋整?你这数据就不一致了。
所以消息队列实际是一种非常复杂的架构,你引入它有很多好处,但是也得针对它带来的坏处做各种额外的技术方案和架构来规避掉,做好之后,你会发现,妈呀,系统复杂度提升了一个数量级,也许是复杂了 10 倍。但是关键时刻,用,还是得用的。

4 如何保证消息队列的高可用?

4.1 RabbitMQ 的高可用性
RabbitMQ 是比较有代表性的,因为是基于主从(非分布式)做高可用性的,我们就以 RabbitMQ 为例子讲解第一种 MQ 的高可用性怎么实现。
普通集群模式(无高可用性)
普通集群模式,意思就是在多台机器上启动多个 RabbitMQ 实例,每台机器启动一个。你创建的 queue,只会放在一个 RabbitMQ 实例上,但是每个实例都同步 queue 的元数据(元数据可以认为是 queue 的一些配置信息,通过元数据,可以找到 queue 所在实例)。你消费的时候,实际上如果连接到了另外一个实例,那么那个实例会从 queue 所在实例上拉取数据过来。

RabbitMQ 镜像集群模式(高可用性)

4.2 Kafka 的高可用性
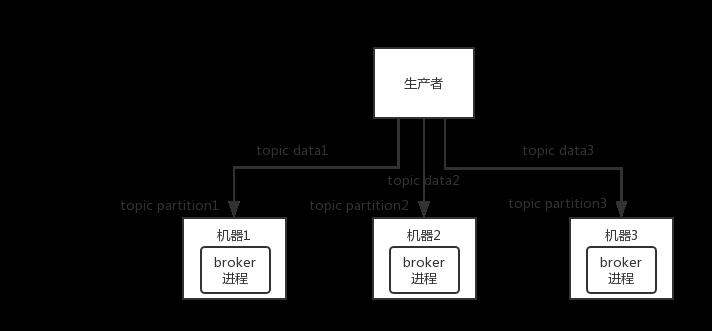
Kafka 一个最基本的架构认识:由多个 broker 组成,每个 broker 是一个节点;你创建一个 topic,这个 topic 可以划分为多个 partition,每个 partition 可以存在于不同的 broker 上,每个 partition 就放一部分数据。
这就是天然的分布式消息队列,就是说一个 topic 的数据,是分散放在多个机器上的,每个机器就放一部分数据。
链接: 高可用.
5 如何保证消息不丢失?(如何保证消息的可靠性传输?)
5.1 消息丢失的原因
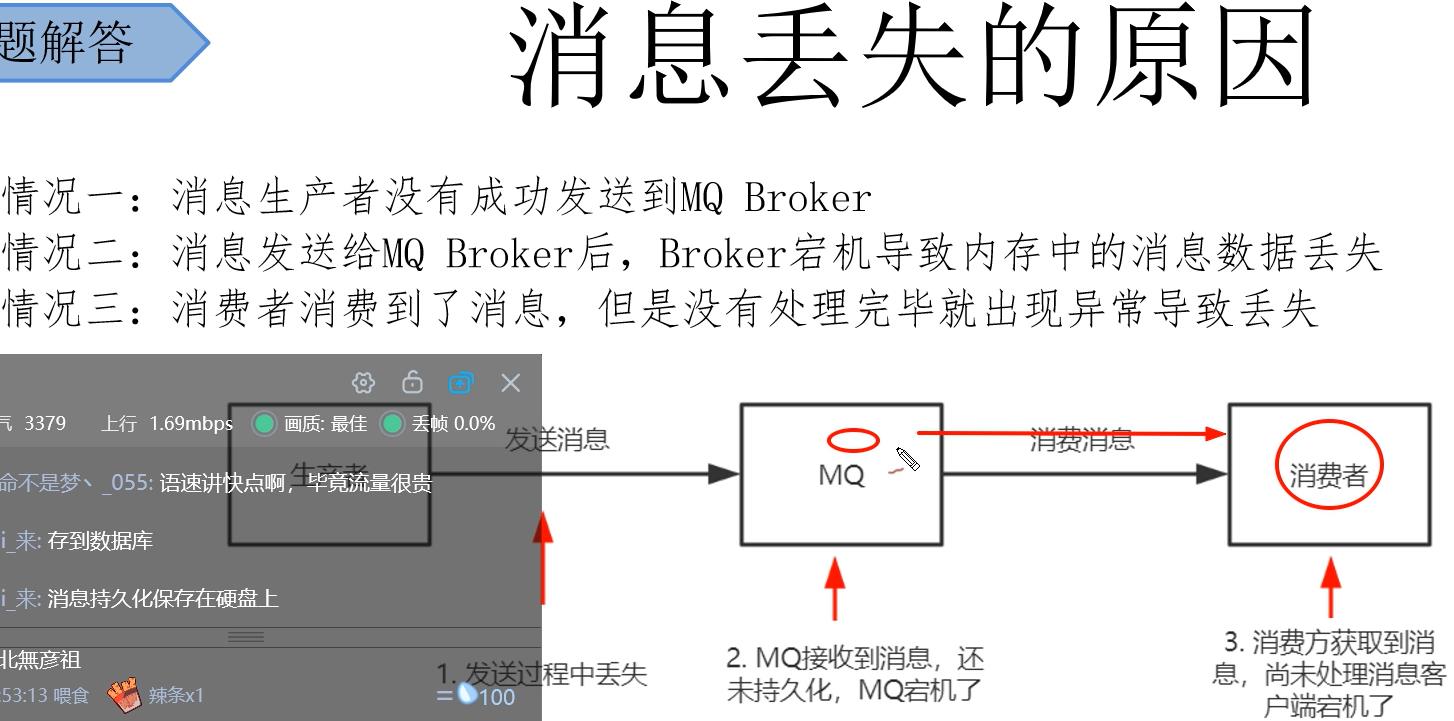
5.2 确保消息不丢失的方案
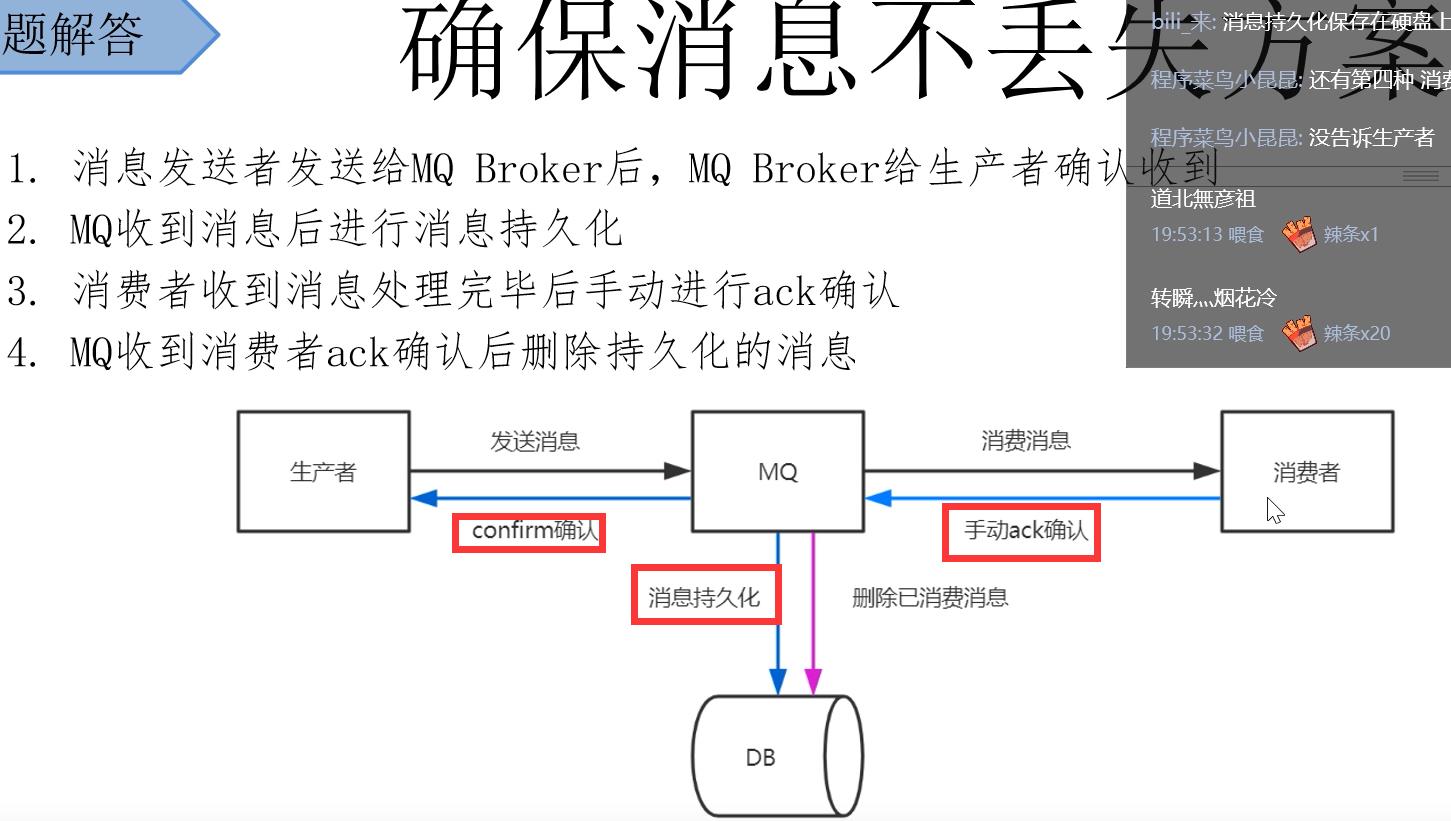
6 如何保证消息不被重复消费?(如何保证消息消费的幂等性)
6.1 重复消息产生的原因

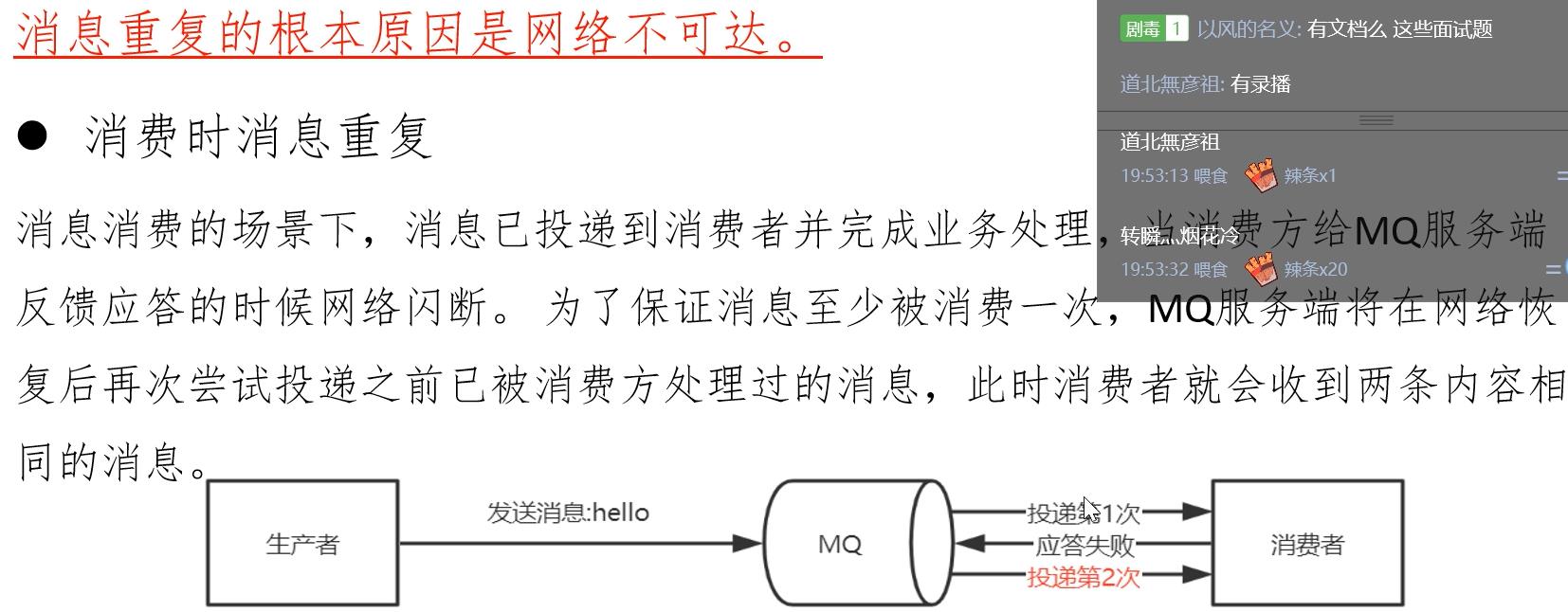
6.2 消息重复消费的解决方案

7 如何保证消息消费的顺序性?
7.1 消费者是否理解什么是消息顺序消费?

7.2 消费者是否思考过确保消息顺序消费的方案?

8 大量消息堆积处理 如何处理?

8.1 消息堆积的原因

8.2 消息堆积处理方案

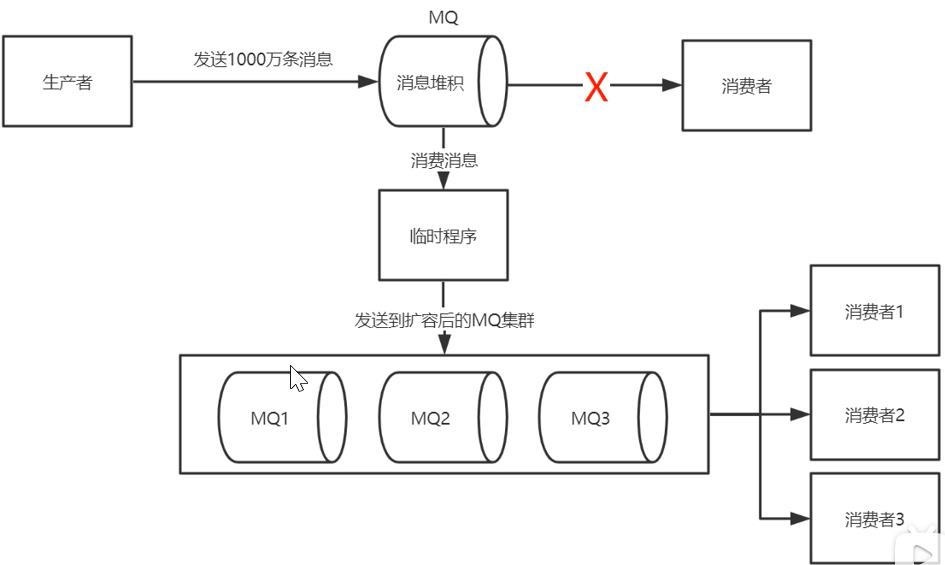
9. 消息过期怎样处理?
9.1 消息为什么会过期?

9.2 针对过期消息如何处理?

10 参考视频及文档
以上是关于高并发框架之消息队列的主要内容,如果未能解决你的问题,请参考以下文章