SpringBoot整合MyCat实现读写分离,稳进大厂
Posted 爱看动漫的Java程序员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SpringBoot整合MyCat实现读写分离,稳进大厂相关的知识,希望对你有一定的参考价值。
一、Spring Cloud微服务概念定义
提起微服务,不得不提 Spring Cloud 全家桶系列,Spring Cloud 是一个服务治理平台,是若干个框架的集合,提供了全套的分布式系统解决方案。包含了:服务注册与发现、配置中心、服务网关、智能路由、负载均衡、断路器、监控跟踪、分布式消息队列等等。
Spring Cloud 通过 Spring Boot 风格的封装,屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、容易部署的分布式系统开发工具包。开发者可以快速的启动服务或构建应用、同时能够快速和云平台资源进行对接。微服务是可以独立部署、水平扩展、独立访问(或者有独立的数据库)的服务单元,Spring Cloud 就是这些微服务的大管家,采用了微服务这种架构之后,项目的数量会非常多,Spring Cloud 做为大管家需要管理好这些微服务,自然需要很多小弟来帮忙。

正文
在实际的工作项目中, 缓存成为高并发、高性能架构的关键组件 ,那么Redis为什么可以作为缓存使用呢?首先可以作为缓存的两个主要特征:
- 在分层系统中处于内存/CPU具有访问性能良好,
- 缓存数据饱和,有良好的数据淘汰机制
由于Redis 天然就具有这两个特征,Redis基于内存操作的,且其具有完善的数据淘汰机制,十分适合作为缓存组件。
其中,基于内存操作,容量可以为32-96GB,且操作时间平均为100ns,操作效率高。而且数据淘汰机制众多,在Redis 4.0 后就有8种了促使Redis作为缓存可以适用很多场景。
那Redis缓存为什么需要数据淘汰机制呢?有哪8种数据淘汰机制呢?
数据淘汰机制
Redis缓存基于内存实现的,则其缓存其容量是有限的,当出现缓存被写满的情况,那么这时Redis该如何处理呢?
Redis对于缓存被写满的情况,Redis就需要缓存数据淘汰机制,通过一定淘汰规则将一些数据刷选出来删除,让缓存服务可再使用。那么Redis使用哪些淘汰策略进行刷选删除数据?
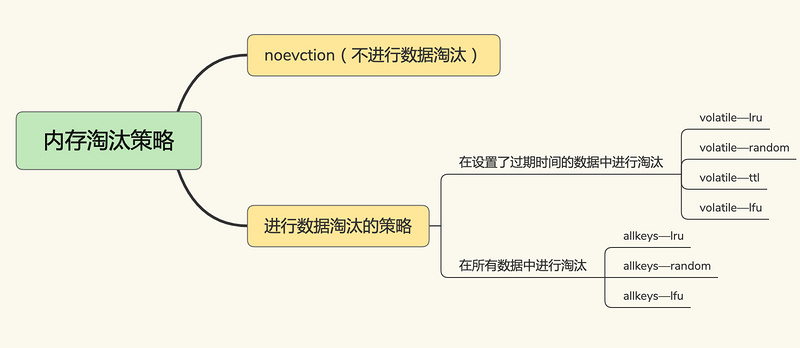
在Redis 4.0 之后,Redis 缓存淘汰策略6+2种,包括分成三大类:
-
不淘汰数据
- noeviction ,不进行数据淘汰,当缓存被写满后,Redis不提供服务直接返回错误。
-
在设置过期时间的键值对中,
- volatile-random ,在设置过期时间的键值对中随机删除
- volatile-ttl ,在设置过期时间的键值对,基于过期时间的先后进行删除,越早过期的越先被删除。
- volatile-lru , 基于LRU(Least Recently Used) 算法筛选设置了过期时间的键值对, 最近最少使用的原则来筛选数据
- volatile-lfu ,使用 LFU( Least Frequently Used ) 算法选择设置了过期时间的键值对, 使用频率最少的键值对,来筛选数据。
-
在所有的键值对中,
- allkeys-random, 从所有键值对中随机选择并删除数据
- allkeys-lru, 使用 LRU 算法在所有数据中进行筛选
- allkeys-lfu, 使用 LFU 算法在所有数据中进行筛选
Note: LRU( 最近最少使用,Least Recently Used)算法, LRU维护一个双向链表 ,链表的头和尾分别表示 MRU 端和 LRU 端,分别代表最近最常使用的数据和最近最不常用的数据。
LRU 算法在实际实现时,需要用链表管理所有的缓存数据,这会带来额外的空间开销。而且,当有数据被访问时,需要在链表上把该数据移动到 MRU 端,如果有大量数据被访问,就会带来很多链表移动操作,会很耗时,进而会降低 Redis 缓存性能。
其中,LRU和LFU 基于Redis的对象结构redisObject的lru和refcount属性实现的:
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
// 对象最后一次被访问的时间
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
// 引用计数 * and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
Redis的LRU会使用redisObject的lru记录最近一次被访问的时间,随机选取参数maxmemory-samples 配置的数量作为候选集合,在其中选择 lru 属性值最小的数据淘汰出去。
在实际项目中,那么该如何选择数据淘汰机制呢?
- 优先选择 allkeys-lru算法,将最近最常访问的数据留在缓存中,提升应用的访问性能。
- 有顶置数据使用 volatile-lru算法 ,顶置数据不设置缓存过期时间,其他数据设置过期时间,基于LRU 规则进行筛选 。
在理解了Redis缓存淘汰机制后,来看看Redis作为缓存其有多少种模式呢?
Redis缓存模式
Redis缓存模式基于是否接收写请求,可以分成只读缓存和读写缓存:
只读缓存:只处理读操作,所有的更新操作都在数据库中,这样数据不会有丢失的风险。
- Cache Aside模式
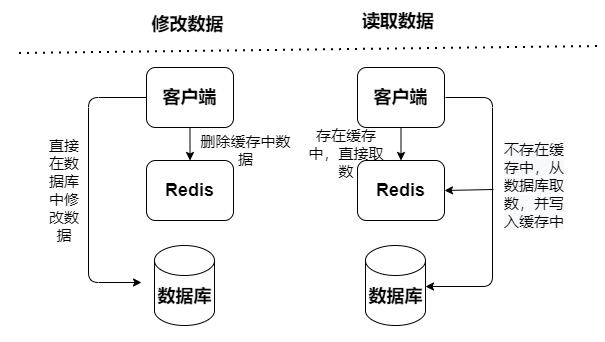
读写缓存,读写操作都在缓存中执行,出现宕机故障,会导致数据丢失。缓存回写数据到数据库有分成两种同步和异步:
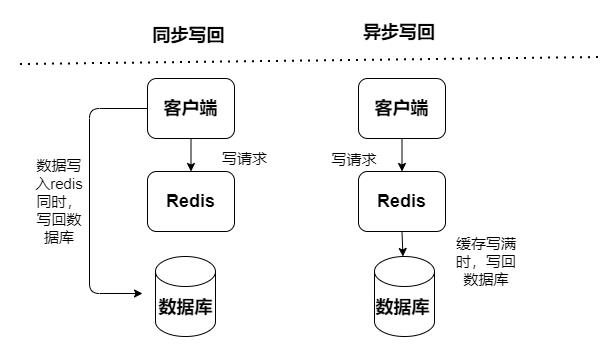
-
同步:访问性能偏低,其更加侧重于保证数据可靠性
- Read-Throug模式
- Write-Through模式
-
异步:有数据丢失风险,其侧重于提供低延迟访问
- Write-Behind模式
Cache Aside模式
查询数据先从缓存读取数据,如果缓存中不存在,则再到数据库中读取数据,获取到数据之后更新到缓存Cache中,但更新数据操作,会先去更新数据库种的数据,然后将缓存种的数据失效。
而且Cache Aside模式会存在并发风险:执行读操作未命中缓存,然后查询数据库中取数据,数据已经查询到还没放入缓存,同时一个更新写操作让缓存失效,然后读操作再把查询到数据加载缓存,导致缓存的脏数据。
Read/Write-Throug模式
查询数据和更新数据都直接访问缓存服务,缓存服务同步方式地将数据更新到数据库。出现脏数据的概率较低,但是就强依赖缓存,对缓存服务的稳定性有较大要求,但同步更新会导致其性能不好。
Write Behind模式
查询数据和更新数据都直接访问缓存服务,但缓存服务使用异步方式地将数据更新到数据库(通过异步任务) 速度快,效率会非常高,但是数据的一致性比较差,还可能会有数据的丢失情况,实现逻辑也较为复杂。
在实际项目开发中根据实际的业务场景需求来进行选择缓存模式。那了解上述后,我们的应用中为什么需要使用到redis缓存呢?
在应用使用Redis缓存可以提高系统性能和并发,主要体现在
- 高性能:基于内存查询,KV结构,简单逻辑运算
- 高并发: mysql 每秒只能支持2000左右的请求,Redis轻松每秒1W以上。让80%以上查询走缓存,20%以下查询走数据库,能让系统吞吐量有很大的提高
虽然使用Redis缓存可以大大提升系统的性能,但是使用了缓存,会出现一些问题,比如,缓存与数据库双向不一致、缓存雪崩等,对于出现的这些问题该怎么解决呢?
使用缓存常见的问题
使用了缓存,会出现一些问题,主要体现在:
- 缓存与数据库双写不一致
- 缓存雪崩: Redis 缓存无法处理大量的应用请求,转移到数据库层导致数据库层的压力激增;
- 缓存穿透:访问数据不存在在Redis缓存中和数据库中,导致大量访问穿透缓存直接转移到数据库导致数据库层的压力激增;
- 缓存击穿:缓存无法处理高频热点数据,导致直接高频访问数据库导致数据库层的压力激增;
缓存与数据库数据不一致
只读缓存(Cache Aside模式)
对于只读缓存(Cache Aside模式), 读操作都发生在缓存中,数据不一致只会发生在删改操作上(新增操作不会,因为新增只会在数据库处理),当发生删改操作时,缓存将数据中标志为无效和更新数据库 。因此在更新数据库和删除缓存值的过程中,无论这两个操作的执行顺序谁先谁后,只要有一个操作失败了就会出现数据不一致的情况。
Kafka实战笔记
关于这份笔记,为了不影响大家的阅读体验,我只能在文章中展示部分的章节内容和核心截图,如果你需要完整的pdf版本,戳这里即可免费领取。

- Kafka入门
- 为什么选择Kafka
- Karka的安装、管理和配置
- Kafka的集群
- 第一个Kafka程序

afka的生产者

- Kafka的消费者
- 深入理解Kafka
- 可靠的数据传递


- Spring和Kalka的整合
- Sprinboot和Kafka的整合
- Kafka实战之削峰填谷
- 数据管道和流式处理(了解即可)

- Kafka实战之削峰填谷

prinboot和Kafka的整合**
- Kafka实战之削峰填谷
- 数据管道和流式处理(了解即可)
[外链图片转存中…(img-8upgRA8p-1621224869151)]
- Kafka实战之削峰填谷
[外链图片转存中…(img-2WTIVsKT-1621224869152)]
以上是关于SpringBoot整合MyCat实现读写分离,稳进大厂的主要内容,如果未能解决你的问题,请参考以下文章
mycat系列三SpringBoot + mybatisPlus + Mycat + Mysql (多主多从) 整合