全网最python爬虫系统入门到进阶学习学完可就业(附带源码)
Posted 不加班的程序员丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了全网最python爬虫系统入门到进阶学习学完可就业(附带源码)相关的知识,希望对你有一定的参考价值。
爬虫介绍 认识爬虫
1、初始爬虫
爬虫,从本质上来说,就是利用程序在网上拿到对我们有价值的数据。
2、明晰路径
2-1、浏览器工作原理
(1)解析数据:当服务器把数据响应给浏览器之后,浏览器并不会直接把数据丢给我们。因为这些数据是用计算机的语言写的,浏览器还要把这些数据翻译成我们能看得懂的内容;
(2)提取数据:我们就可以在拿到的数据中,挑选出对我们有用的数据;
(3)存储数据:将挑选出来的有用数据保存在某一文件/数据库中。
2-2、爬虫工作原理
(1)获取数据:爬虫程序会根据我们提供的网址,向服务器发起请求,然后返回数据;
(2)解析数据:爬虫程序会把服务器返回的数据解析成我们能读懂的格式;
(3)提取数据:爬虫程序再从中提取出我们需要的数据;
(4)储存数据:爬虫程序把这些有用的数据保存起来,便于你日后的使用和分析。
requests实战(基础爬虫)
1.豆瓣电影爬取
2.肯德基餐厅查询
3.破解百度翻译
4.搜狗首页
5.网页采集器
6.药监总局相关数据爬取
爬虫数据分析(bs4,xpath,正则表达式)
1.bs4解析基础
2.bs4案例
3.xpath解析基础
4.xpath解析案例-4k图片解析爬取
5.xpath解析案例-58二手房
6.xpath解析案例-爬取站长素材中免费简历模板
7.xpath解析案例-全国城市名称爬取
8.正则解析
9.正则解析-分页爬取
10.爬取图片
自动识别验证码
1.古诗文网验证码识别
fateadm_api.py(识别需要的配置,建议放在同一文件夹下)
调用api接口

request模块高级(模拟登录)
1.代理操作
2.模拟登陆人人网
3.模拟登陆人人网
高性能异步爬虫(线程池,协程)
1.aiohttp实现多任务异步爬虫
2.flask服务
3.多任务协程
4.多任务异步爬虫
5.示例
6.同步爬虫
7.线程池基本使用
8.线程池在爬虫案例中的应用
9.协程
动态加载数据处理(selenium模块应用,模拟登录12306)
1.selenium基础用法
2.selenium其他自动操作
3.12306登录示例代码
4.动作链与iframe的处理
5.谷歌无头浏览器+反检测
6.基于selenium实现1236模拟登录
7.模拟登录qq空间
scrapy框架
1.各种项目实战,scrapy各种配置修
2.bossPro示例
3.bossPro示例
4.数据库示例
还有相关python资料分享需要的可以添加 ssmp8858 备注【python】
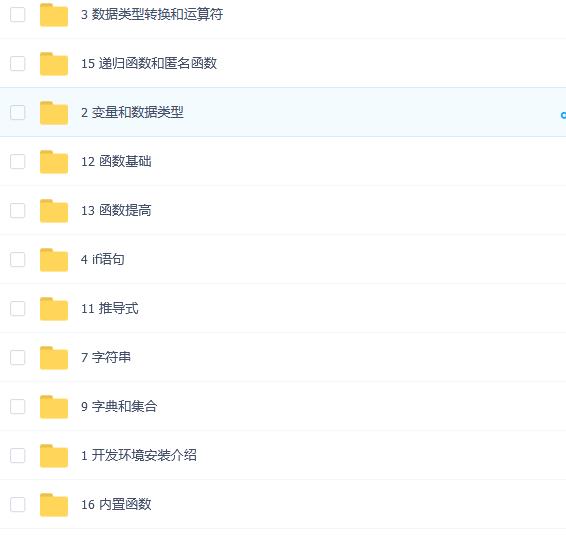
requests实战(基础爬虫)
1.豆瓣电影爬取
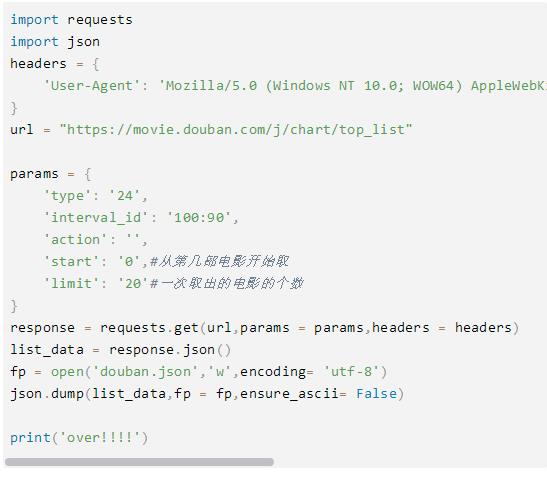
2.肯德基餐厅查询
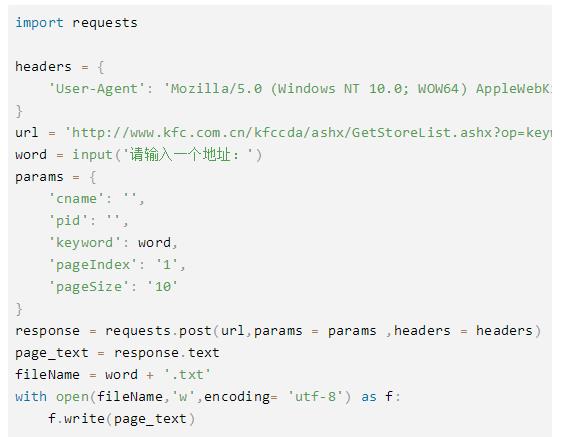
爬虫数据分析(bs4,xpath,正则表达式)
1.bs4解析基础
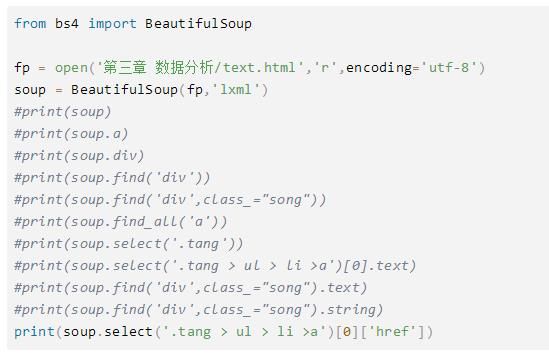
2.bs4案例
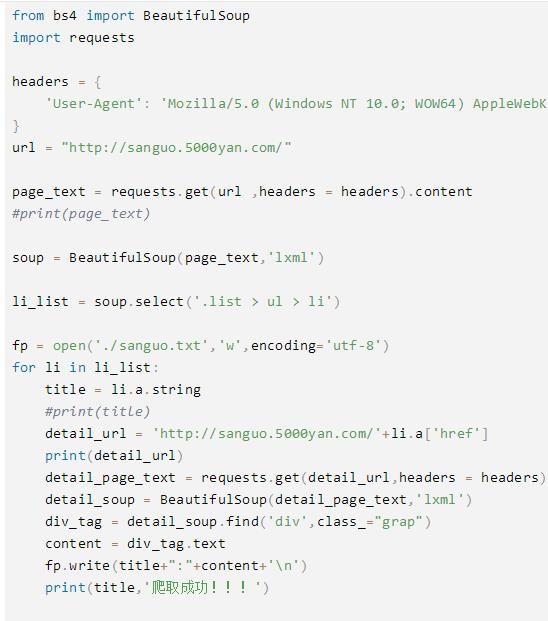
爬取图片

今天就分享到这里了哈,需要相关python资料的可以扫一下本站【python资料】

以上是关于全网最python爬虫系统入门到进阶学习学完可就业(附带源码)的主要内容,如果未能解决你的问题,请参考以下文章
全网最全python爬虫精进(体系学习)学完可就业(附源代码)
全网最全python练手项目,练完可就业(附源代码),持续更新中