七十二Impala的简介与安装部署
Posted 象在舞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了七十二Impala的简介与安装部署相关的知识,希望对你有一定的参考价值。
咱们前面几篇文章穿插了些CDH的内容,因为咱们的Impala的安装是基于CDH的,所以提前将如何部署安装CDH讲解了一下。本文我们来看一下Impala的相关知识。关注专栏《破茧成蝶——大数据篇》,查看更多相关的内容~
目录
一、Impala概述
1.1 Impala是什么

Impala是由Cloudera公司推出,提供对HDFS、HBase数据的高性能、低延迟的交互式SQL查询。它基于Hive,使用内存计算,兼顾数据仓库、具有实时、批处理、多并发等优点,是CDH平台首选的PB级大数据实时查询分析引擎。
1.2 Impala的优缺点
1.2.1 优点
1、基于内存运算,不需要把中间结果写入磁盘,省掉了大量的I/O开销。
2、无需转换为MapReduce,直接访问存储在HDFS,HBase中的数据进行作业调度,速度快。
3、使用了支持Data locality的I/O调度机制,尽可能地将数据和计算分配在同一台机器上进行,减少了网络开销。
4、支持各种文件格式,如TEXTFILE 、SEQUENCEFILE 、RCFile、Parquet。
5、可以访问Hive的metastore,对Hive数据直接做数据分析。
1.2.2 缺点
1、对内存的依赖大,且完全依赖于Hive。
2、当分区超过1万,性能严重下降。
3、只能读取文本文件,而不能直接读取自定义二进制文件。
4、每当新的记录/文件被添加到HDFS中的数据目录时,该表需要被刷新。
1.3 Impala的架构
Impala自身包含三个模块:Impalad、Statestore和Catalog,除此之外它还依赖Hive Metastore和HDFS。

1、Impalad:
(1)接收client的请求、Query执行并返回给中心协调节点。
(2)子节点上的守护进程,负责向statestore保持通信,汇报工作。
2、Catalog:
(1)分发表的元数据信息到各个impalad中。
(2)接收来自statestore的所有请求。
3、Statestore:
(1)负责收集分布在集群中各个impalad进程的资源信息、各节点健康状况,同步节点信息。
(2)负责query的协调调度。
二、Impala的安装
Impala的安装我们只介绍基于CDH的安装,这种方式相对比较便捷。Impala的官网请点击这里~
2.1 Impala的安装
1、打开cloudera manager的监控界面

2、点击添加服务

3、选择Impala

4、进行角色分配
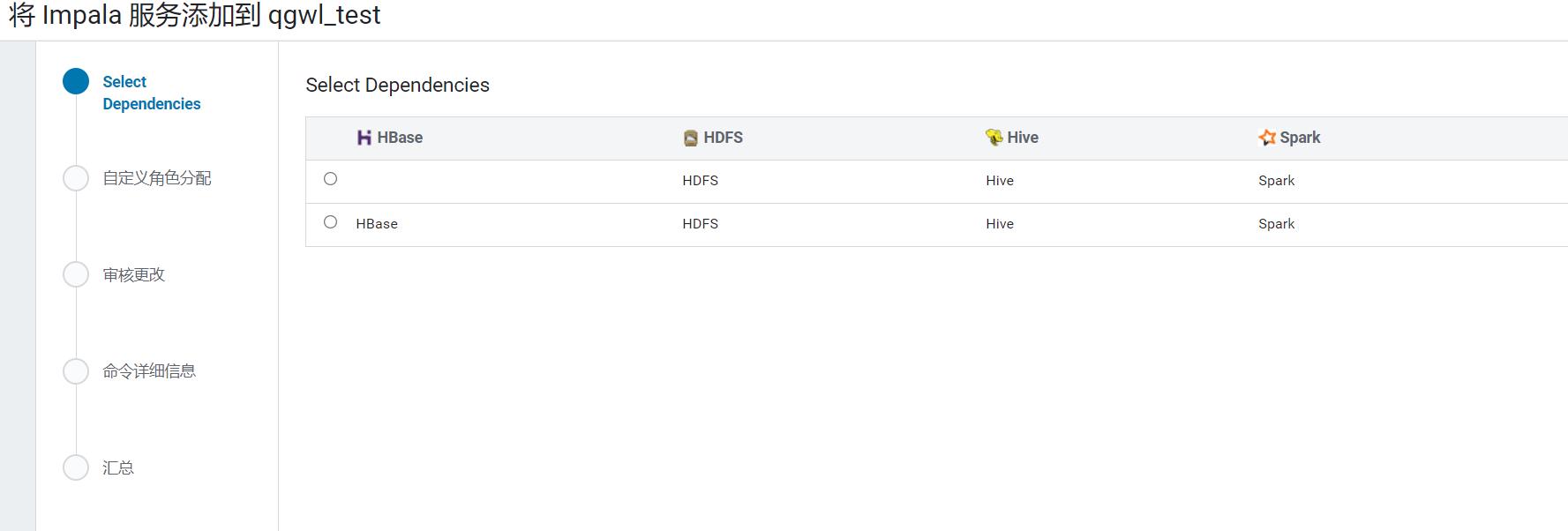
5、启动Impala

至此,说明安装成功。
2.2 Impala的测试
1、启动Impala
[root@cdh-slave03 ~]# impala-shell2、创建数据库并使用

3、创建表

4、加载数据到表

这里需要注意的是,在加载数据的时候,需要对hdfs上的文件目录赋权,如下所示:
hdfs dfs -chmod -R 777 /xzw并且在监控界面需要修改相应的权限,如下图所示:

5、查询
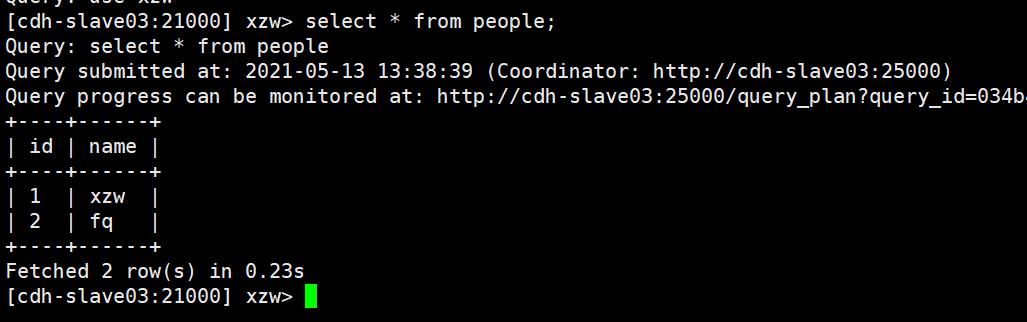
6、退出
quit;
以上就是本文的所有内容,比较简单。你们在此过程中遇到了什么问题,欢迎留言,让我看看你们都遇到了哪些问题~
以上是关于七十二Impala的简介与安装部署的主要内容,如果未能解决你的问题,请参考以下文章