七十三Impala的常用操作
Posted 象在舞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了七十三Impala的常用操作相关的知识,希望对你有一定的参考价值。
上一篇文章我们简单介绍了一下Impala以及如何安装部署Impala,本文我们从Impala的数据类型、DDL、DML、函数等方面来看一下Impala是如何操作的。关注专栏《破茧成蝶——大数据篇》,查看更多相关的内容~
目录
一、Impala的数据类型
Impala与Hive的数据类型对比如下所示:
| Hive数据类型 | Impala数据类型 | 长度 |
| TINYINT | TINYINT | 1byte有符号整数 |
| SMALINT | SMALINT | 2byte有符号整数 |
| INT | INT | 4byte有符号整数 |
| BIGINT | BIGINT | 8byte有符号整数 |
| BOOLEAN | BOOLEAN | 布尔类型,true或者false |
| FLOAT | FLOAT | 单精度浮点数 |
| DOUBLE | DOUBLE | 双精度浮点数 |
| STRING | STRING | 字符系列。可以指定字符集。可以使用单引号或者双引号。 |
| TIMESTAMP | TIMESTAMP | 时间类型 |
| BINARY | 不支持 | 字节数组 |
这里需要注意的是,Impala虽然支持array,map,struct复杂数据类型,但是支持并不完全。
二、Impala的操作命令
2.1 Impala的外部shell
| 选项 | 描述 |
| -h, --help | 显示帮助信息 |
| -v or --version | 显示版本信息 |
| -i hostname, --impalad=hostname | 指定连接运行 impalad 守护进程的主机。默认端口是 21000。 |
| -q query, --query=query | 从命令行中传递一个shell 命令。执行完这一语句后 shell 会立即退出。 |
| -f query_file, --query_file= query_file | 传递一个文件中的 SQL 查询。文件内容必须以分号分隔 |
| -o filename or --output_file filename | 保存所有查询结果到指定的文件。通常用于保存在命令行使用 -q 选项执行单个查询时的查询结果。 |
| -c | 查询执行失败时继续执行 |
| -d default_db or --database=default_db | 指定启动后使用的数据库,与建立连接后使用use语句选择数据库作用相同,如果没有指定,那么使用default数据库 |
| -r or --refresh_after_connect | 建立连接后刷新 Impala 元数据 |
| -p, --show_profiles | 对 shell 中执行的每一个查询,显示其查询执行计划 |
| -B(--delimited) | 去格式化输出 |
| --output_delimiter=character | 指定分隔符 |
| --print_header | 打印列名 |
2.2 Impala的内部shell
| 选项 | 描述 |
| help | 显示帮助信息 |
| explain <sql> | 显示执行计划 |
| profile | (查询完成后执行) 查询最近一次查询的底层信息 |
| shell <shell> | 不退出impala-shell执行shell命令 |
| version | 显示版本信息(同于impala-shell -v) |
| connect | 连接impalad主机,默认端口21000(同于impala-shell -i) |
| refresh <tablename> | 增量刷新元数据库 |
| invalidate metadata | 全量刷新元数据库(慎用)(同于 impala-shell -r) |
| history | 历史命令 |
三、Impala的DDL数据定义语言
3.1 数据库操作
3.1.1 创建数据库
CREATE DATABASE [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path];
这里需要注意的是,Impala不支持WITH DBPROPERTIE语法。

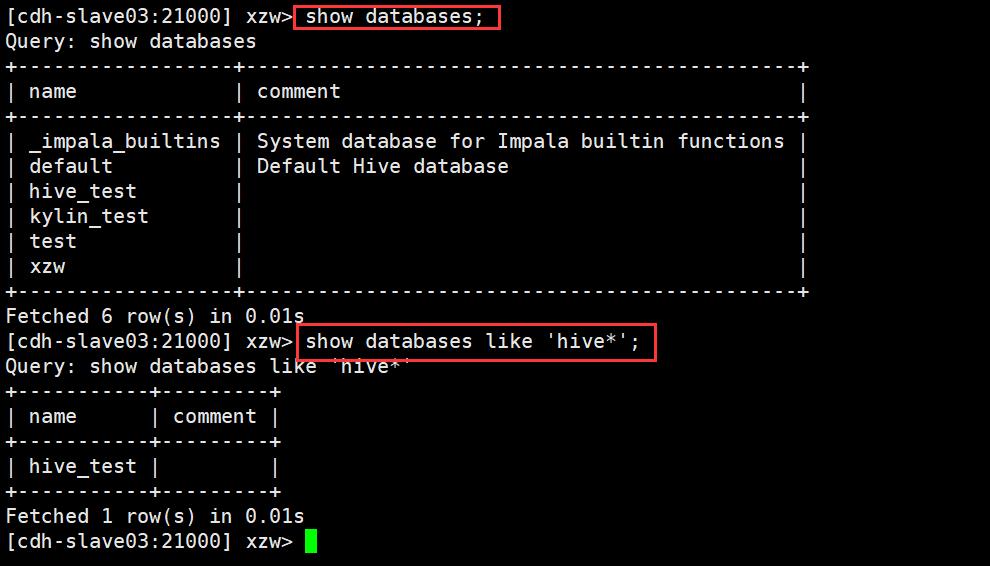
3.1.2 显示数据库
3.1.3 删除数据库
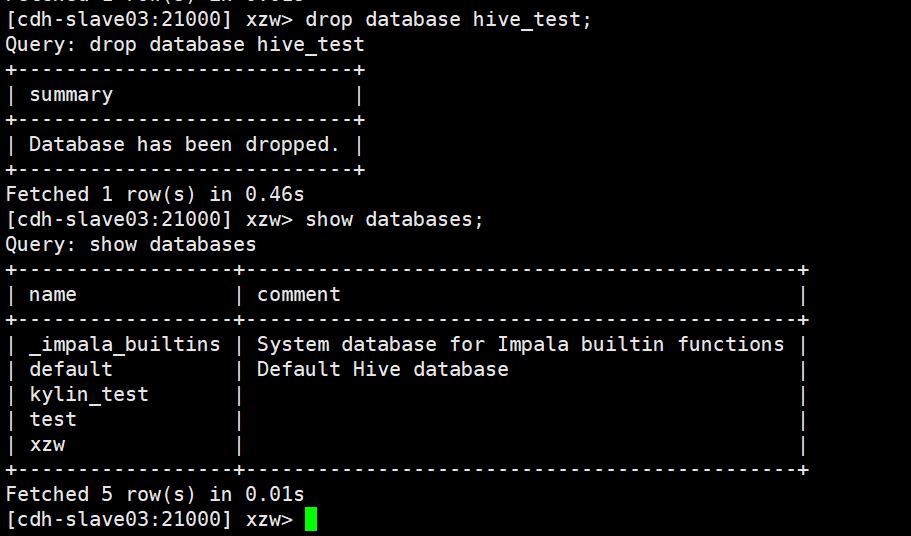
这里需要注意的是,当数据库在使用时是无法drop掉的。
3.2 表操作
3.2.1 内部表
create table if not exists people(
id int,
name string
)
row format delimited fields terminated by '\\t'
stored as textfile
location '/user/hive/warehouse/people';3.2.2 外部表
create external table external_people(
id int,
name string)
row format delimited fields terminated by '\\t' ;3.2.3 分区表
1、创建表
create table stu_par(id int, name string)
partitioned by (month string)
row format delimited
fields terminated by '\\t';2、插入数据
alter table stu_par add partition (month='201810');
load data inpath '/student.txt' into table stu_par partition(month='201810');
insert into table stu_par partition (month = '201811');
这里需要注意的是,如果分区没有,load data导入数据时,不能自动创建分区。
3、增加分区
alter table stu_par add partition (month='201812') partition (month='201813');4、删除分区
alter table stu_par drop partition (month='201812');5、查看分区
show partitions stu_par;四、Impala的DML数据操作语言
4.1 数据导入
数据导入跟Hive的大同小异,可以参考Hive数据导入的操作,请点击这里。不过,同样需要注意的是,impala不支持load data local inpath,即它只能加载HDFS上面的文件。
4.2 数据导出
Impala不支持export和import命令,Impala数据导出一般使用impala -o命令。
impala-shell -q 'select * from student' -B --output_delimiter="\\t" -o output.txt4.3 查询
Impala的查询语法跟Hive的查询语句大体一样,可以参考Hive的查询语句。Impala不支持CLUSTER BY、DISTRIBUTE BY、SORT BY,Impala中不支持分桶表,不支持COLLECT_SET(col)和explode(col)函数,但是Impala支持开窗函数。
五、函数
5.1 自定义函数
1、添加依赖
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-exec -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
</dependencies>
2、创建一个自定义函数类
package com.xzw.hive;
import org.apache.hadoop.hive.ql.exec.UDF;
/**
* @author: xzw
* @create_date: 2020/12/20 11:05
* @desc: 将字符串转换为小写
* @modifier:
* @modified_date:
* @desc:
*/
public class Lower extends UDF
/**
* 执行计算的方法
* @param orig 原始字符串
* @return 返回转换为小写的字符串
*/
public String evaluate(String orig)
if (null == orig)
return null;
return orig.toLowerCase();
public static void main(String[] args)
3、打包并上传到HDFS指定的目录
hdfs dfs -put impala_udf.jar /xzw/4、创建函数
create function udf_lower(string) returns string location '/xzw/impala_udf.jar' symbol='com.xzw.hive.Lower';5、使用自定义函数
select ename, udf_lower(ename) from emp;六、压缩和存储
| 文件格式 | 压缩编码 | Impala是否可直接创建 | 是否可直接插入 |
| Parquet | Snappy(默认), GZIP; | Yes | 支持:CREATE TABLE, INSERT, 查询 |
| TextFile | LZO,gzip,bzip2,snappy | Yes. 不指定 STORED AS 子句的 CREATE TABLE 语句,默认的文件格式就是未压缩文本 | 支持:CREATE TABLE, INSERT, 查询。如果使用 LZO 压缩,则必须在 Hive 中创建表和加载数据 |
| RCFile | Snappy, GZIP, deflate, BZIP2 | Yes. | 支持CREATE,查询,在 Hive 中加载数据 |
| SequenceFile | Snappy, GZIP, deflate, BZIP2 | Yes. | 支持:CREATE TABLE, INSERT, 查询。需设置 |
这里需要注意的是,Impala不支持ORC格式。
七、Impala的优化
1、尽量将StateStore和Catalog单独部署到同一个节点,保证他们正常通信。
2、通过对Impala Daemon内存限制(默认256M)及StateStore工作线程数,来提高Impala的执行效率。
3、SQL优化,使用之前调用执行计划。
4、选择合适的文件格式进行存储,提高查询效率。
5、避免产生很多小文件(如果有其他程序产生的小文件,可以使用中间表,将小文件数据存放到中间表。然后通过insert…select…方式中间表的数据插入到最终表中)。
6、使用合适的分区技术,根据分区粒度测算。
7、使用compute stats进行表信息搜集,当一个内容表或分区明显变化,重新计算统计相关数据表或分区。因为行和不同值的数量差异可能导致Impala选择不同的连接顺序时进行查询。
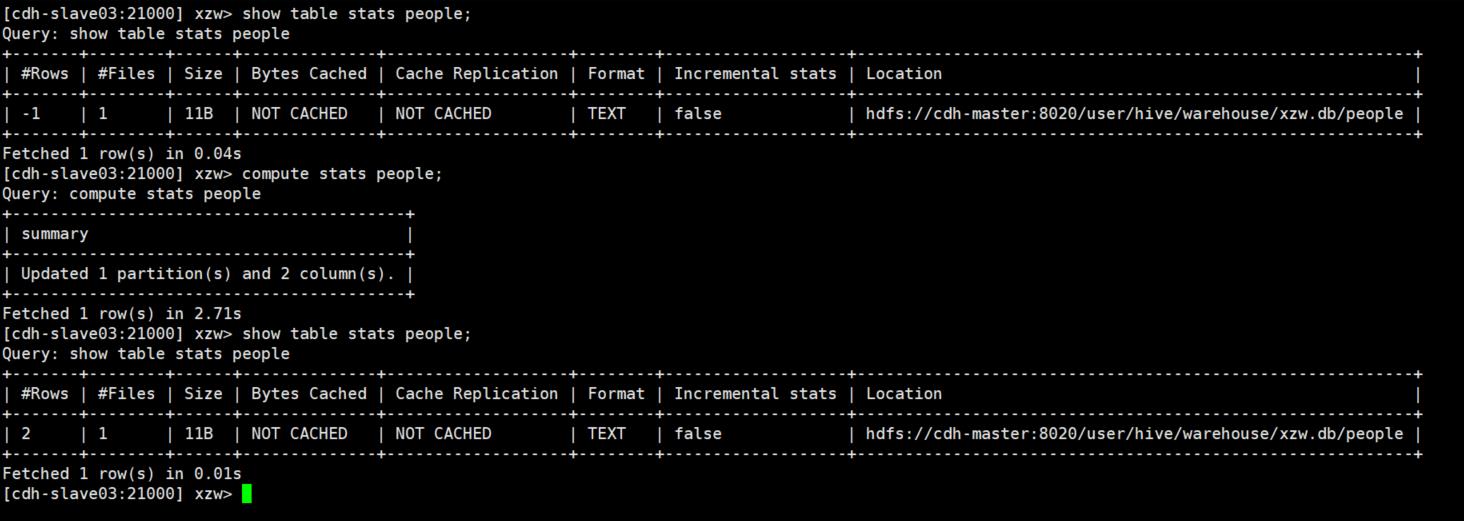
8、网络io的优化:避免把整个数据发送到客户端;尽可能的做条件过滤;使用limit字句;输出文件时,避免使用美化输出;尽量少用全量元数据的刷新。
9、使用profile输出底层信息计划,在做相应环境优化。
以上就是本文的所有内容,比较简单。你们在此过程中遇到了什么问题,欢迎留言,让我看看你们都遇到了哪些问题~
以上是关于七十三Impala的常用操作的主要内容,如果未能解决你的问题,请参考以下文章